

勋章








我关注的人







粉丝



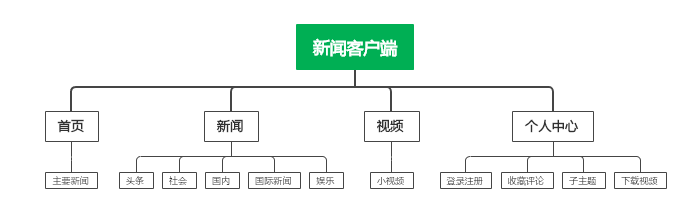

技术能力
-
-
 云数据库Clouder认证:云数据库RDS快速入门
获得于2023-11-06 18:04:25
云数据库Clouder认证:云数据库RDS快速入门
获得于2023-11-06 18:04:25 -
云存储Clouder认证:基于存储产品快速搭建网盘
获得于2023-09-25 15:28:11
-
弹性计算Clouder认证:ECS基础运维管理
获得于2023-08-31 14:40:47
-
暂无个人介绍
2024年05月
-
12.07 09:58:51
 发表了文章
2023-12-07 09:58:51
发表了文章
2023-12-07 09:58:51
特征提取
特征提取 -
12.07 09:56:54发表了文章
2023-12-07 09:56:54
人脸检测
人脸检测 -
12.07 09:53:47发表了文章
2023-12-07 09:53:47
人脸识别
人脸识别 -
12.06 10:57:25发表了文章
2023-12-06 10:57:25
oss储存数据
oss储存数据 -
12.06 10:56:17发表了文章
2023-12-06 10:56:17
ecs实例备份
ecs实例备份ecs实例备份 -
12.06 10:53:14发表了文章
2023-12-06 10:53:14
rds实例如何备份
rds实例如何备份 -
12.05 09:56:53发表了文章
2023-12-05 09:56:53
部分自动化
部分自动化 -
12.05 09:47:45发表了文章
2023-12-05 09:47:45
驾驶辅助
驾驶辅助 -
12.05 09:43:29发表了文章
2023-12-05 09:43:29
无自动化
无自动化 -
12.05 09:37:04发表了文章
2023-12-05 09:37:04
自动驾驶技术
自动驾驶技术 -
12.04 09:59:55发表了文章
2023-12-04 09:59:55
数学中的函数
数学中的函数 -
12.04 09:58:14发表了文章
2023-12-04 09:58:14
函数介绍
函数介绍 -
12.04 09:56:28发表了文章
2023-12-04 09:56:28
Flink CDC中MySQL 进行cdc的用户需要什么权限?
Flink CDC中MySQL 进行cdc的用户需要什么权限?
2023年12月
-
12.05 10:57:40
 回答了问题
2023-12-05 10:57:40
回答了问题
2023-12-05 10:57:40
函数计算3.0,你的体验如何?
赞2 踩0 评论0 -
12.05 10:07:33回答了问题
2023-12-05 10:07:33
微服务还是单体架构?
赞3 踩0 评论0 -
12.04 10:29:47回答了问题
2023-12-04 10:29:47
技术人上下班通勤时间会做些什么?
赞3 踩0 评论0 -
12.01 09:54:45发表了文章
2023-12-01 09:54:45
选择排序
选择排序 -
12.01 09:48:27发表了文章
2023-12-01 09:48:27
冒泡排序
冒泡排序 -
12.01 09:42:16发表了文章
2023-12-01 09:42:16
排序算法
排序算法 -
11.30 09:52:24发表了文章
2023-11-30 09:52:24
高级技术综述
高级技术综述 -
11.30 09:49:41发表了文章
2023-11-30 09:49:41
概念理解
概念理解 -
11.30 09:42:52发表了文章
2023-11-30 09:42:52
编程基础
编程基础 -
11.29 11:07:26发表了文章
2023-11-29 11:07:26
绩效考核系统
绩效考核系统 -
11.29 11:04:25发表了文章
2023-11-29 11:04:25
酒店管理系统
酒店管理系统 -
11.29 11:03:10发表了文章
2023-11-29 11:03:10
员工管理系统
员工管理系统 -
11.28 09:10:21发表了文章
2023-11-28 09:10:21
用python写图书管理系统
用python写图书管理系统 -
11.28 09:09:27发表了文章
2023-11-28 09:09:27
用shell写图书管理系统
用shell写图书管理系统 -
11.28 09:04:41发表了文章
2023-11-28 09:04:41
图书管理系统的基本框架,可以用 Shell 脚本来实现
图书管理系统的基本框架,可以用 Shell 脚本来实现: -
11.27 10:12:07发表了文章
2023-11-27 10:12:07
怎么能快速注册商标和域名联系
怎么能快速注册商标和域名联系 -
11.27 10:10:01发表了文章
2023-11-27 10:10:01
备案的时候为什么显示未可用ip地址
备案的时候为什么显示未可用ip地址 -
11.27 10:08:21发表了文章
2023-11-27 10:08:21
虚拟节点是什么?
虚拟节点是什么? -
11.24 10:12:09发表了文章
2023-11-24 10:12:09
大数据对生活的影响
大数据对生活的影响 -
11.24 10:09:17发表了文章
2023-11-24 10:09:17
大数据应用
大数据应用 -
11.24 10:07:31发表了文章
2023-11-24 10:07:31
大数据介绍
大数据介绍 -
11.23 09:21:05发表了文章
2023-11-23 09:21:05
shell脚本三剑客之sed
shell脚本三剑客之sed -
11.23 09:18:00发表了文章
2023-11-23 09:18:00
shell脚本里的三剑客之一awk
shell脚本里的三剑客之一awk -
11.23 09:12:20发表了文章
2023-11-23 09:12:20
shell函数介绍
shell函数介绍 -
11.22 09:07:22发表了文章
2023-11-22 09:07:22
Java获取未来60天的天气预报
Java获取未来60天的天气预报, -
11.22 09:02:14发表了文章
2023-11-22 09:02:14
python脚本获取未来60天的天气预报
python脚本获取未来60天的天气预报 -
11.22 08:57:17发表了文章
2023-11-22 08:57:17
shell脚本获取未来60天的天气预报
shell脚本获取未来60天的天气预报
2023年11月
-
11.27 10:21:36回答了问题
2023-11-27 10:21:36
我对云服务器ECS选型有话说
赞6 踩0 评论0 -
11.23 11:32:57回答了问题
2023-11-23 11:32:57
你有哪些低成本又能保持扩展性的套路?
赞3 踩0 评论0 -
11.21 09:04:56回答了问题
2023-11-21 09:04:56
如何看待AI的版权问题?
赞11 踩0 评论0 -
11.21 09:01:10回答了问题
2023-11-21 09:01:10
下一代软件架构,如何构建微服务核心能力?
赞2 踩0 评论0 -
11.21 08:58:49发表了文章
2023-11-21 08:58:49
如何更好的学习一门计算机语言
如何更好的学习一门计算机语言 -
11.21 08:57:41发表了文章
2023-11-21 08:57:41
阿里云的ascm上如何使用api接口
阿里云的ascm上如何使用api接口 -
11.21 08:55:45发表了文章
2023-11-21 08:55:45
DataWorks我想获取节点的这些信息,好像并没有API提供,我看了getnode,listnodes都只有部分?
DataWorks我想获取节点的这些信息,好像并没有API提供,我看了getnode,listnodes都只有部分? -
11.20 09:08:23回答了问题
2023-11-20 09:08:23
个人开发者能否靠开源获利?
赞37 踩0 评论0 -
11.16 10:31:31发表了文章
2023-11-16 10:31:31
shell监控脚本告警通过微信外发
shell监控脚本告警通过微信外发 -
11.16 10:27:55发表了文章
2023-11-16 10:27:55
shell监控脚本钉钉外发
shell监控脚本钉钉外发
-
发表了文章
2024-07-06
中间件数据传输与集成
-
发表了文章
2024-07-06
中间件流程协调与调度
-
发表了文章
2024-07-06
中间件数据转换与处理
-
发表了文章
2024-07-05
中间件在实时数据处理流式处理框架
-
发表了文章
2024-07-05
中间件在实时数据处理和高性能消息队列
-
发表了文章
2024-07-05
中间件在实时数据处理内存数据网格和缓存
-
发表了文章
2024-07-04
中间件在实时数据处理和高吞吐量
-
发表了文章
2024-07-04
中间件在实时数据处理中低延迟
-
发表了文章
2024-07-04
中间件在实时数据处理事件驱动架构
-
发表了文章
2024-07-03
中间件实时数据处理的关键特性可拓展性
-
发表了文章
2024-07-03
中间件实时数据处理的关键特性容错性
-
发表了文章
2024-07-03
中间件实时数据处理的关键特性实时性
-
发表了文章
2024-07-02
中间件发布订阅实时数据处理
-
发表了文章
2024-07-02
中间件发布订阅消息队列与任务分发
-
发表了文章
2024-07-02
中间件发布订阅事件驱动架构
-
发表了文章
2024-07-01
中间件发布-订阅模式(Pub/Sub)
-
发表了文章
2024-07-01
中间件注册与订阅
-
发表了文章
2024-07-01
中间件事件模型
-
发表了文章
2024-06-28
中间件事件总线实现机制
-
发表了文章
2024-06-28
中间件事件总线技术选型

-
回答了问题
2024-07-05
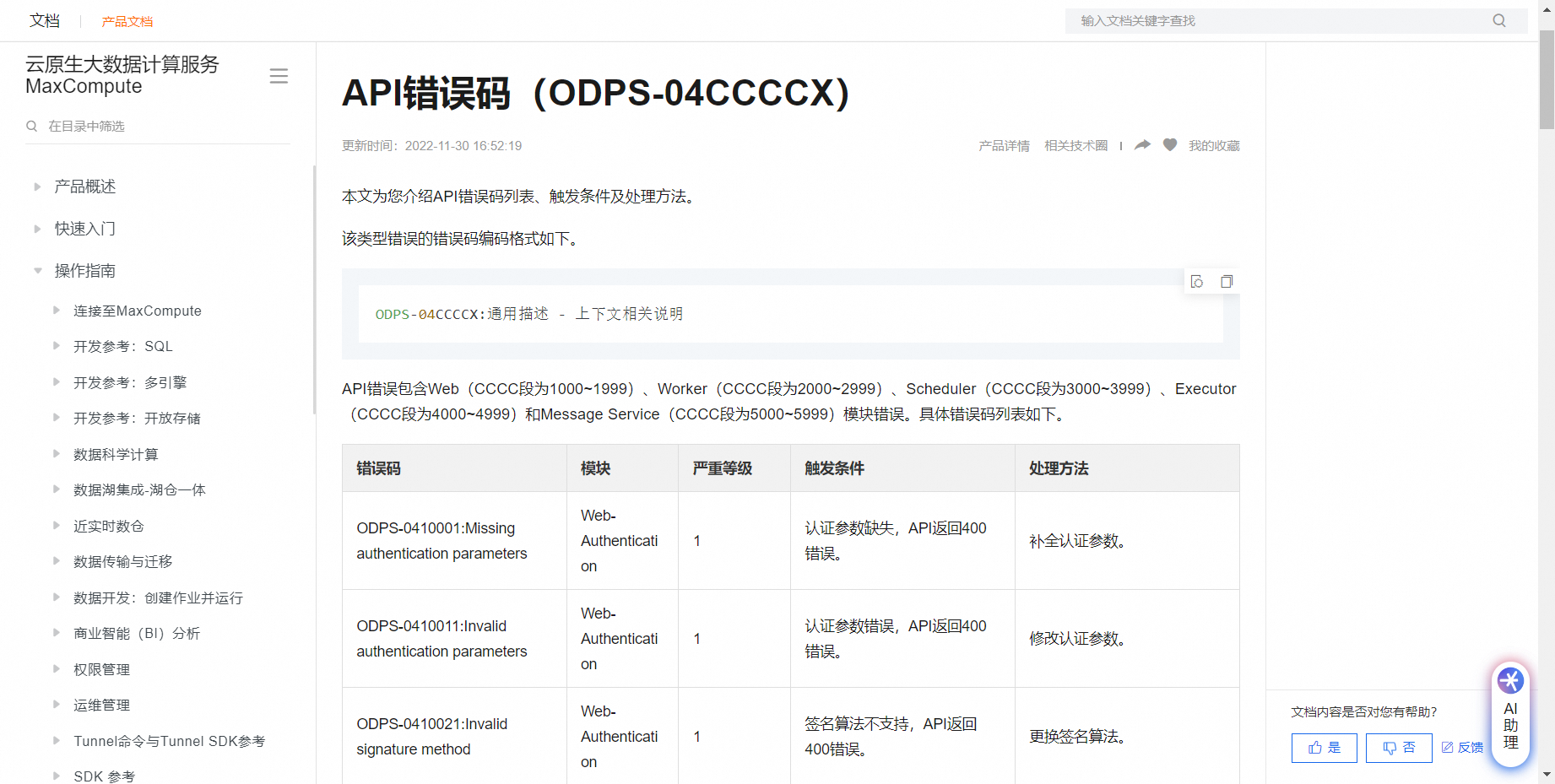
大数据计算MaxCompute这种报错是什么意思啊?
这个错误码500160表示API请求超时。这可能是由于网络延迟或服务端处理繁忙导致的。建议您稍后重试该操作,如果问题持续存在,可以检查网络环境.
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
大数据计算MaxCompute 可以一次性获取两个分区吗?
MaxCompute的DataFrame操作无法一次性通过get_partition获取多个分区。如果您需要获取多个分区的数据,您需要分别指定每个分区来执行get_partition,然后将结果合并。例如:
pt_df1 = DataFrame(o.get_table('partitioned_table').get_partition('pt=20171111')) pt_df2 = DataFrame(o.get_table('partitioned_table').get_partition('pt=20171112'))合并两个分区的数据
merged_df = pd.concat([pt_df1, pt_df2])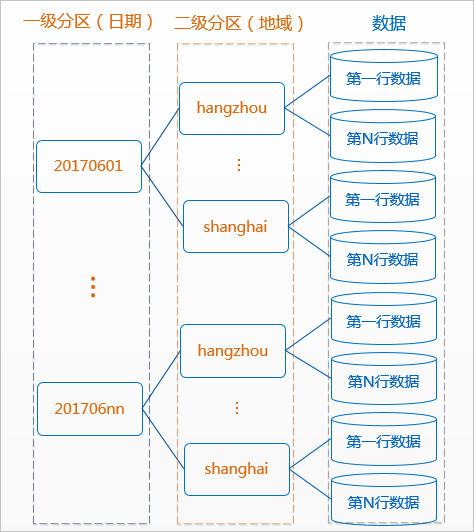 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
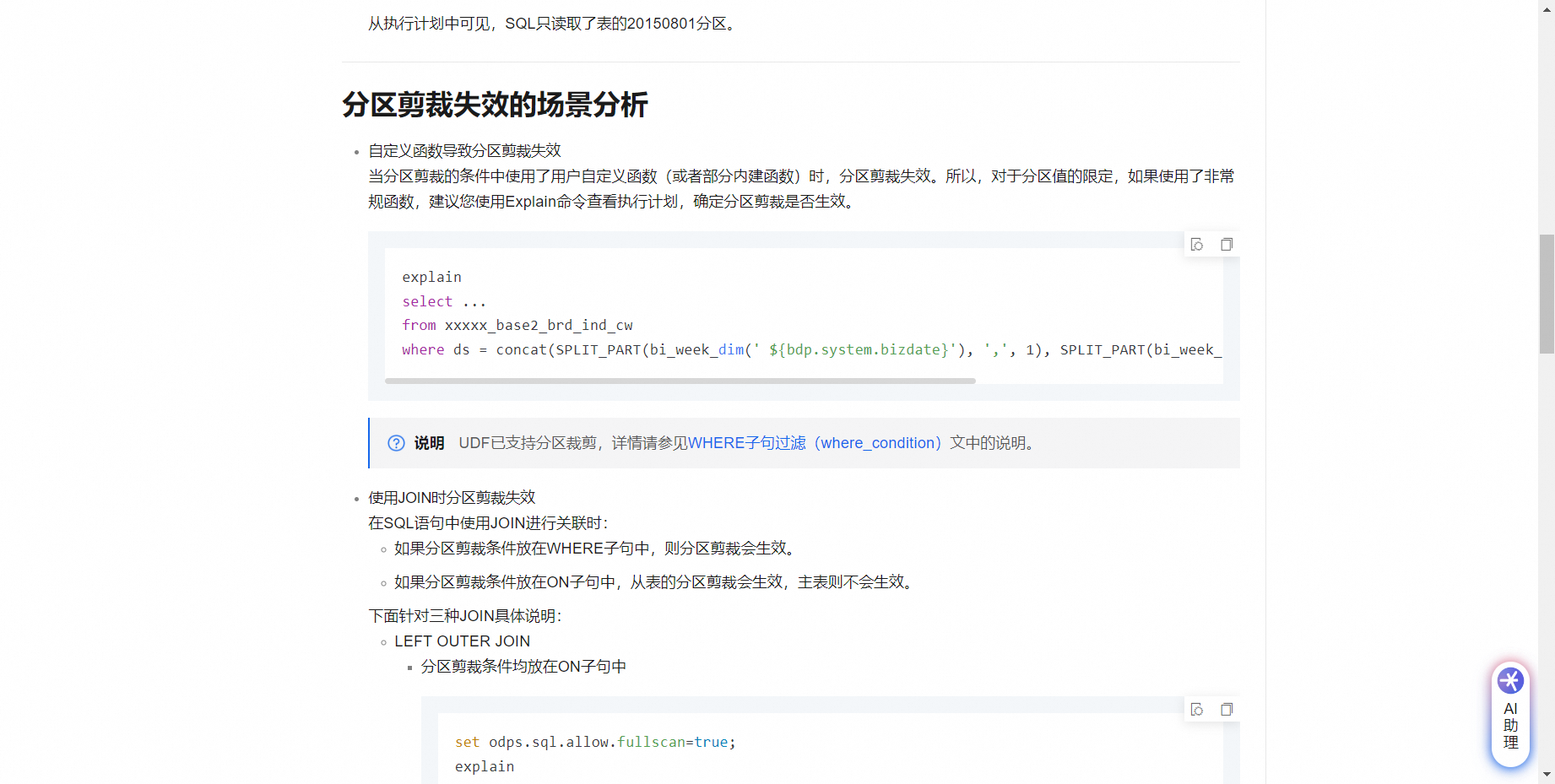
大数据计算MaxCompute里面使用分区字段关联会和hive里面一样提升效率吗?
MaxCompute中的分区设计与Hive类似,目的都是为了优化查询性能。通过使用分区字段,可以减少在执行查询时扫描的数据量,从而提高查询效率。当查询涉及的分区字段是JOIN操作的一部分时,确实能够提升JOIN的效率,因为它允许MaxCompute在JOIN之前过滤掉不相关的数据分区。
MaxCompute的优化策略与Hive可能会有所不同,具体提升的效率取决于数据分布、查询复杂性和MaxCompute的执行引擎优化。为了获得最佳性能,建议遵循最佳实践,如使用适当的分区策略,确保热点数据分散在不同分区,以及利用索引来进一步加速查询。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
大数据计算MaxCompute有什么方式可以 快速计算 一个表 每个分区的count(*)数吗?
可以使用MaxCompute的SQL语句来统计每个分区的行数。您可以执行如下命令:
SELECT partition_column1, partition_column2, ..., COUNT(*) FROM table_name GROUP BY partition_column1, partition_column2, ...这里partition_column1, partition_column2, ...是您的分区列名,table_name是表名。执行这个查询会返回每个不同分区组合的行数。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
大数据计算MaxCompute怎么生成连续的日期?
您可以在MaxCompute中使用generate_series函数来生成连续日期。假设开始日期是start_date,结束日期是end_date,可以构造如下SQL:
SELECT date_add('day', i, start_date) as date FROM ( SELECT generate_series(0, datediff(end_date, start_date)) as i ) t这里的date_add('day', i, start_date)用于将开始日期逐天增加,generate_series生成从0到结束日期与开始日期差值的整数序列。
参考MaxCompute SQL最佳实践了解更多日期时间操作。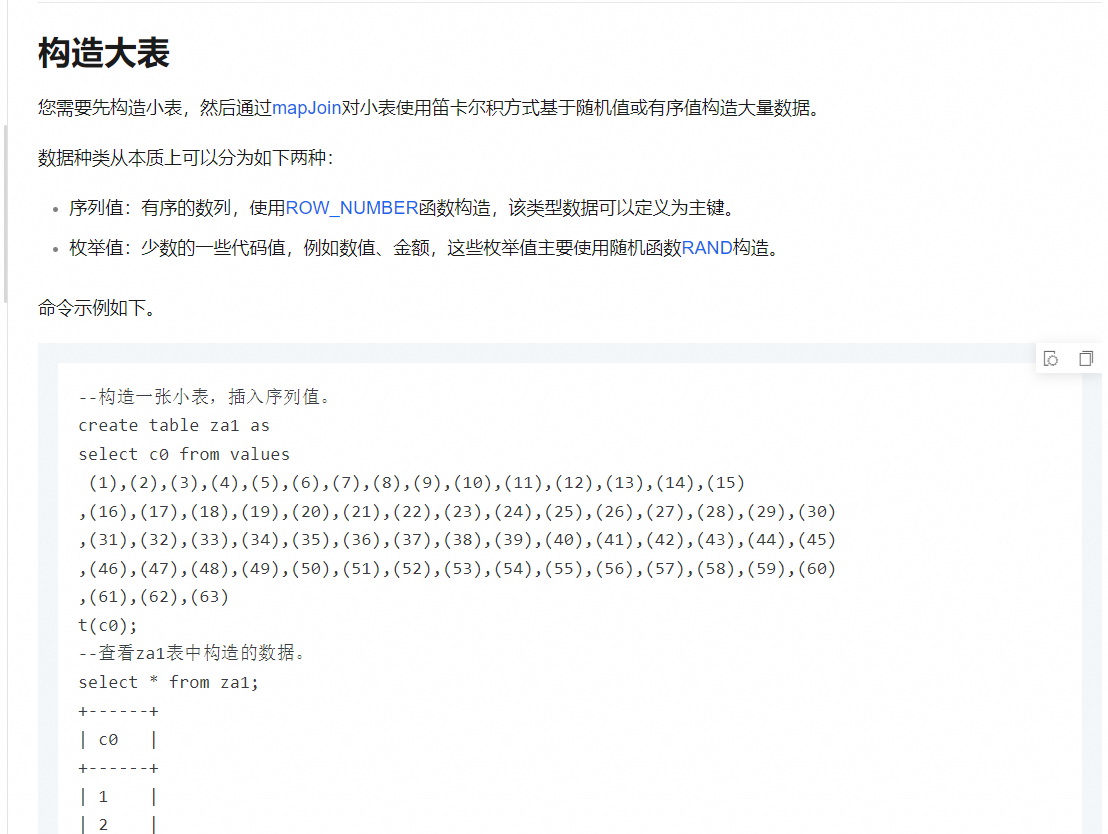 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
问下大数据计算MaxCompute odpssql 抽取样本数据会有重复数据是怎么回事啊?
MaxCompute SQL的ORDER BY RAND()在执行时可能会导致重复数据,因为这不是真正的随机抽样。要无重复地抽取样本数据,可以使用SAMPLE关键字,如SAMPLE 0.01来获取1%的无偏样本。若需要特定数量的样本,可能需要多次采样并去重。如果需要确保无重复,您可以在外部应用中处理,例如通过UDF去重。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
大数据计算MaxCompute该如何实现?
要在MaxCompute中找到最早的aa字段值,您可以使用自连接和ARG_MIN函数。假设表a的结构是aa, oldaa, id,可以这样查询:
SELECT a1.id, a1.aa AS earliest_aa FROM a AS a1 JOIN ( SELECT id, MIN(aa) AS min_aa FROM a GROUP BY id ) AS a2 ON a1.aa = a2.min_aa;这个查询首先找到每个id的最小aa值(a2),然后通过自连接找到对应最早的aa值的记录(a1)。
MaxCompute不支持循环节点,通常处理大数据时我们使用SQL来完成这种逻辑。如果需要多次迭代更新,可以构建一系列的SQL任务或者使用工作流(DataWorks中的Workflow)来按顺序执行这些任务。请根据具体业务需求调整上述SQL,确保处理所有的复杂逻辑。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
大数据计算MaxCompute想用循环节点,改怎么实现?
使用DataWorks的do-while节点可以实现MaxCompute中的循环逻辑。您需要创建一个业务流程,然后配置do-while节点,内部编写循环执行的逻辑,比如统计订单数据。通过设置循环判断条件,如根据每月第1天动态计算分区范围,结合SQL节点计算近1月、近2月、近3月的数据。记得设置好循环次数或退出条件,以满足12个月的统计需求。详情可参考使用do-while节点实现复杂的数据分析。记得在调度配置中设置节点依赖和重跑属性。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
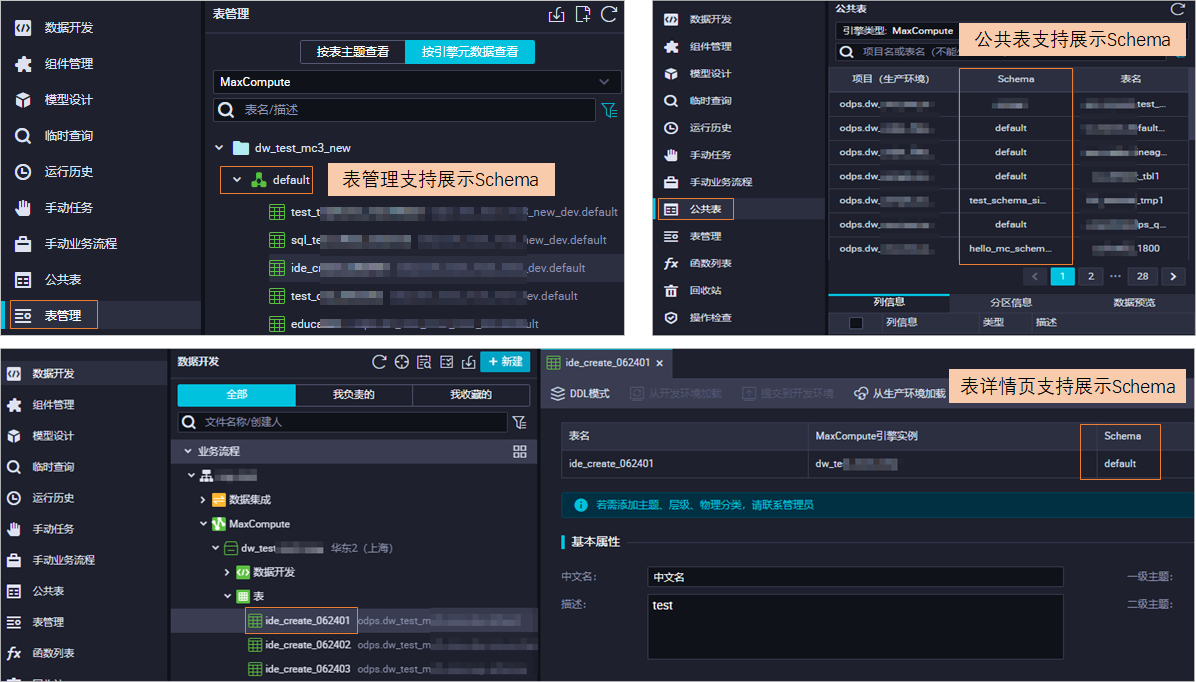
大数据计算MaxCompute Dataworks有租户级别Schema语法开关怎么打开?
开启MaxCompute Schema需要提交工单申请,开启后整个租户下的所有地域都会使用三层模型,且不可关闭。若已开启,表操作需指定Schema。若仍显示"default",可能MaxCompute Schema未开启或配置未生效。建议检查是否已成功开启此功能.
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
请问大数据计算MaxCompute 查出来的数跟我count出来的数不一致,是什么原因呢?
元数据表Information_Schema.tables通常用于获取数据库中的表信息,它不包含实际数据行数。如果你是用COUNT()对某个表进行计数,这会统计表中的实际行数。两者不一致可能是因为表在你查询元数据后又有数据的增减,或者COUNT()包含了一些元数据不记录的信息,如临时表或视图。请确保在无数据写入时比较,以获取一致结果。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
在定义应用交付模式时,需要考虑哪些关键要素?
在定义应用交付模式时,主要考虑以下几个关键要素:
环境类型:区分线上环境(如ECS、ACK)和线下环境(如私有化部署的Linux主机),选择合适的部署目标。
部署流程:确保流程涵盖从编排到验证的全过程,包括必要的参数定义和自动化部署脚本的生成。
资源准备:确认目标环境的资源状态,如云服务器的配置、网络连接、存储空间等。
安装方式:对于线下环境,可能需要通过线上出包下载或配置跳板机进行离线部署。
安全与合规:确保交付过程符合安全标准和客户的数据保护政策。
回滚策略:考虑部署失败时的回滚计划,以保证业务连续性。
可参考交付阶段的主体流程赞0 踩0 评论0 -
回答了问题
2024-07-05
变更请求在研发流程中扮演什么角色?
变更请求在研发流程中主要用来管理对现有应用程序或系统的修改。它们是流程中的一个阶段,用于提议、审批和跟踪任何变更,确保变更符合安全标准、不影响稳定性,并按照既定的规则和流程进行。变更可能包括代码更新、配置修改等。在云效中,您可以配置变更研发流程模板,来规范变更请求的处理方式,包括变更集成、准入规则等,以保证研发过程的高效和合规。更多详情可参考变更持续交付模式
赞0 踩0 评论0 -
回答了问题
2024-07-05
在基于云效平台落地工程交付实践之前,应该先做什么准备工作?
在使用云效平台落地工程交付实践之前,您需要做以下准备工作:
新建一个SpringBoot代码库,参考示例代码库。
在部署目标机器上安装Java运行环境。
在云效流水线中构建出制品,确保包含target/application.jar和deploy.sh。
在主机部署配置中:下载路径:设置为
/home/admin/app/package.tgz,这是制品被下载到主机的路径。
执行用户:填写如admin这样的用户执行部署脚本。
部署脚本:示例如下:mkdir -p /home/admin/application tar zxvf /home/admin/app/package.tgz -C /home/admin/application/ sh /home/admin/application/deploy.sh restart赞0 踩0 评论0 -
回答了问题
2024-07-05
生产部署阶段的流水线有哪些特别之处?
生产部署阶段的流水线通常涉及严格的控制和安全性措施。这一阶段可能包含以下特点:
安全性检查:在部署前执行安全扫描和代码审查,确保代码质量与安全标准相符。
环境隔离:使用隔离的生产环境,确保测试和开发不会影响生产服务。
灰度发布/蓝绿部署:逐步将流量切换到新版本,允许回滚至旧版本以降低风险。
自动/手动审批:可能需要人工审批步骤,确保所有变更都经过审查。
监控与警报:部署后密切监控系统性能,如有异常快速触发警报。
回滚策略:自动或手动的回滚机制,以防部署后出现问题。
版本控制:记录每次部署的详细信息,便于跟踪和审计。
可参考此文档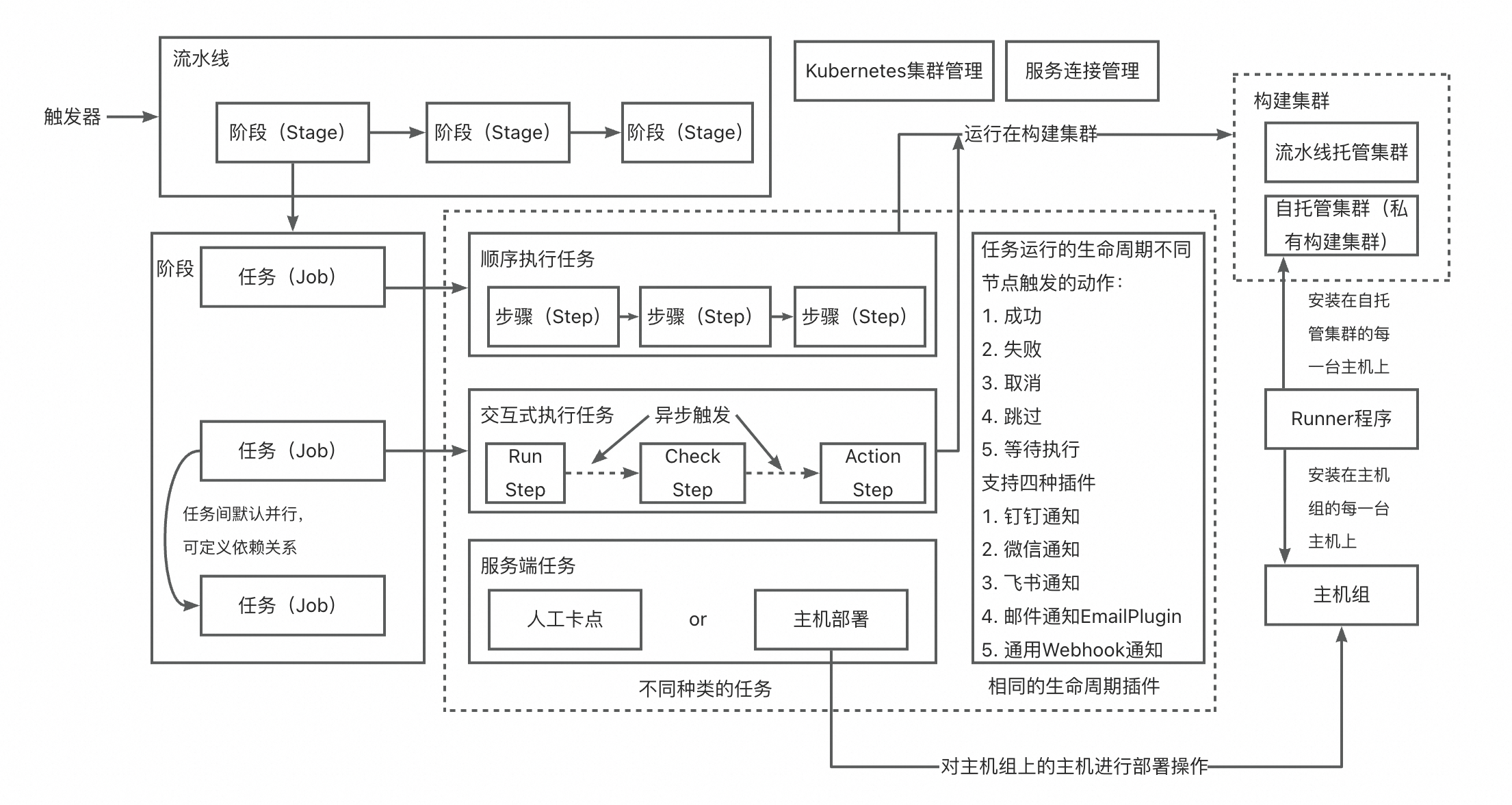 赞1 踩0 评论0
赞1 踩0 评论0 -
回答了问题
2024-07-05
什么是Ganos?
Ganos是阿里云开发的时空数据库引擎,它整合在云原生数据库PolarDB等产品中,提供对空间和时空数据的高效处理。Ganos支持矢量、栅格、移动对象、地理网格等多种数据类型,适用于城市管理、交通物流等领域。它解决了传统时空大数据的复杂性问题,提供免费的一体化存储、查询和分析功能。如需了解更多详情,可参考Ganos时空引擎简介。
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-07-05
Ganos H3地理网格是什么 ? 它有什么特点?
Ganos H3是一个基于二十面体投影的地理网格系统,由Uber开发。它将全球表面划分为六边形网格,支持递归细分,能有效地进行空间索引和数据分析。H3的特点包括:
空间高效表示:通过六边形结构,H3能以紧凑的方式表示地球表面,每个网格都有唯一的63位编码。
多分辨率:支持7级细分,从全球范围到厘米级精度。
空间关系:内置函数支持网格间的关系判断,如相交和包含。
空间分析:适合网格聚合和路径规划,尤其适合大规模时空数据处理。
详情可参考链接标题。赞0 踩0 评论0 -
回答了问题
2024-07-05
如何使用Ganos H3地理网格进行空间点数据的处理?
使用Ganos H3地理网格处理空间点数据,您可以按照以下步骤操作:
将空间点转换为H3网格编码:使用ST_H3函数将几何点(如geometry类型)转换为H3网格码。
获取特定精度的网格:可以使用ST_H3Index指定精度,获取与点对应的H3网格码。
进行网格操作:使用H3相关的函数,如h3_to_children、h3_to_parent等,进行子网格、父网格的获取。
查询与网格的关系:使用ST_Contains或ST_Overlaps等函数,判断点是否在某个H3网格内。
创建索引:为H3网格列创建GiST或GridGin索引以加速查询。
执行查询:利用索引进行高效的点与网格的关系查询。
例如,创建一个包含H3网格的表并插入数据:
CREATE TABLE points ( id SERIAL PRIMARY KEY, point geometry, grid H3INDEX ); INSERT INTO points (point, grid) VALUES (ST_GeomFromText('POINT(-122.084 37.422)', 4326), ST_H3Index(ST_GeomFromText('POINT(-122.084 37.422)', 4326)));创建H3索引:
CREATE INDEX ON points USING GIST(grid);查询点在特定网格内:
SELECT * FROM points WHERE ST_Contains(ST_GeomFromText('POLYGON((x1 y1, x2 y2, x3 y3, x1 y1))', 4326), point);可参见H3地理网格
赞0 踩0 评论0 -
回答了问题
2024-07-05
Ganos H3地理网格支持哪些功能?
Ganos的地理网格引擎支持H3网格剖分规则,提供空间对象编码,支持对象与编码之间的互查操作,还能够进行基于空间网格的聚合与分析。它具备网格退化能力,帮助用户进行多维空间数据处理。了解更多
赞1 踩0 评论0 -
回答了问题
2024-07-05
FOIL文件是什么格式 ? 如何上传到OSS?
FOIL文件格式似乎没有明确的标准定义,可能是指特定情境下的文件类型。上传文件到阿里云OSS通常涉及以下步骤:
登录OSS管理控制台。
选择对应的Bucket。
点击“上传文件”按钮。
选择本地的FOIL文件,或拖拽文件到上传区域。
可以设置访问权限、标签等元数据。
点击“上传”完成操作。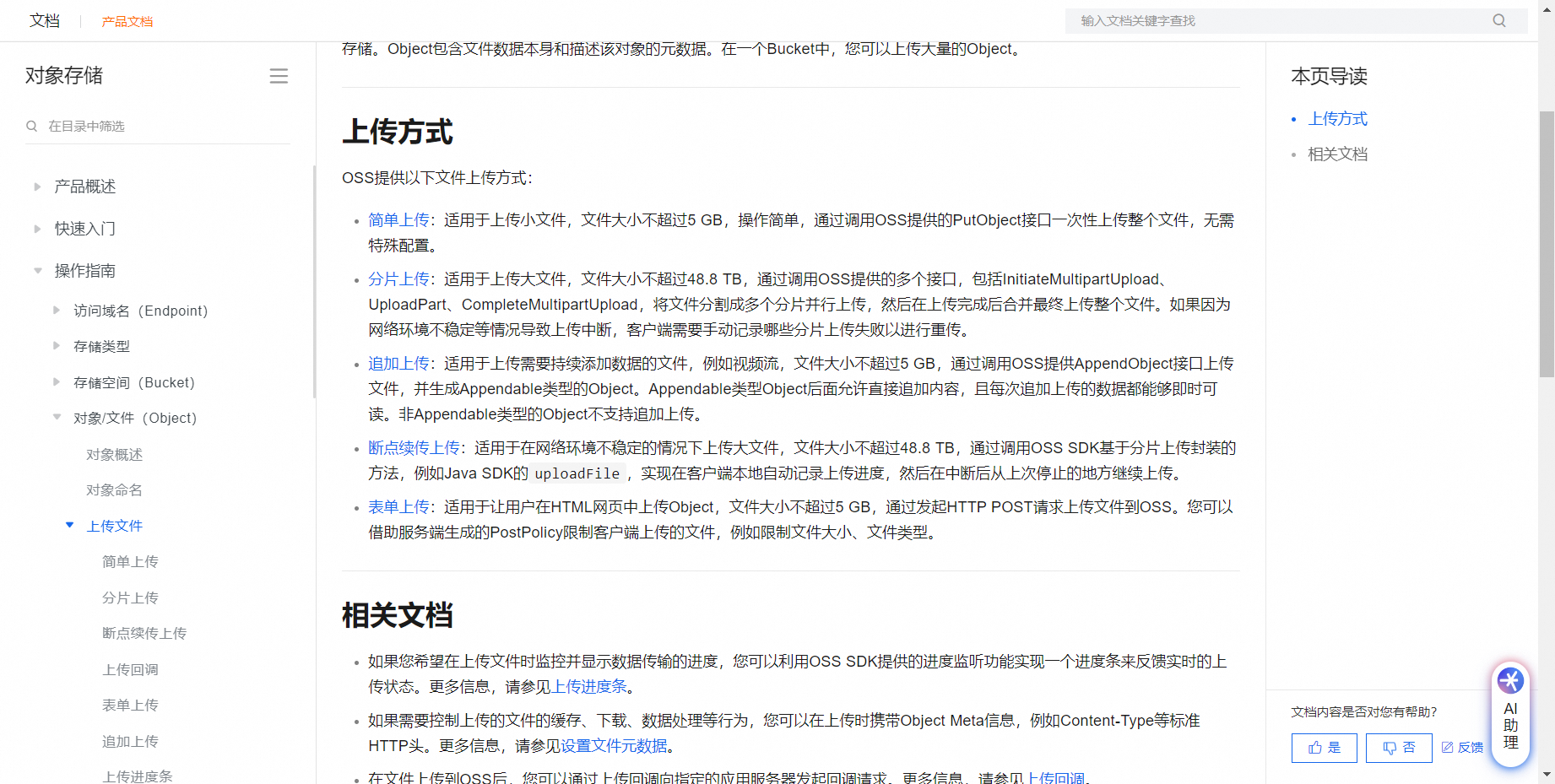 赞1 踩0 评论0
赞1 踩0 评论0