大数据流动

已加入开发者社区1263天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
游客x6a5ef4hf3kkm
游客x6a5ef4hf3kkm
游客5lt33esx4gaju
游客5lt33esx4gaju
游客ajrbius3wsxdw
游客ajrbius3wsxdw
游客kdevhqlov27ta
游客kdevhqlov27ta
游客il55xurjldpvm
游客il55xurjldpvm
游客6arx3de47jeye
游客6arx3de47jeye
7tqoedic7fxkc
7tqoedic7fxkc
游客khqai7ahvj67k
游客khqai7ahvj67k
ke7iay6ws5tac
ke7iay6ws5tac
少年郎与江湖梦-43536
少年郎与江湖梦-43536
游客ycztzhsgjcgs4
游客ycztzhsgjcgs4
游客f3oiysfpqpk2e
游客f3oiysfpqpk2e
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年05月
-
05.28 09:01:14
 发表了文章
2022-05-28 09:01:14
发表了文章
2022-05-28 09:01:14
超详细,Windows系统搭建Flink官方练习环境
如何快速的投入到Flink的学习当中,很多人在搭建环境过程中浪费了太多的时间。一套一劳永逸的本机Flink开发环境可以让我们快速的投入到Flink的学习中去,将精力用在Flink的原理,实战。这也对于工作和面试有着巨大帮助。 本文将利用Flink的官方练习环境,在本地Windows系统中快速的搭建Flink环境,并详细的记录整个搭建过程。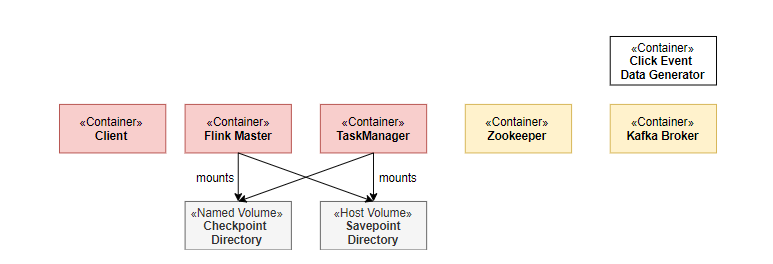
-
05.27 23:17:18发表了文章
2022-05-27 23:17:18
大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce。 虽然现在通过框架的不断发展,MapReduce已经渐渐的淡出人们的视野,越来越多的框架提供了简单的SQL语法来进行大数据计算。但是,MapReduce所提供的编程模型为这一切奠定了基础,所以Google的这篇MapReduce 论文值得我们去认真的研读。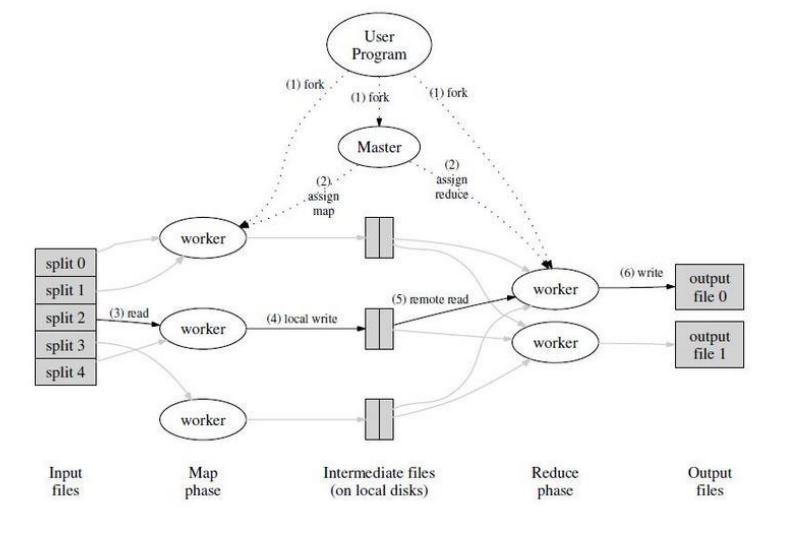
-
05.27 23:13:17发表了文章
2022-05-27 23:13:17
大数据理论篇HDFS的基石——Google File System(二)
Google File System 但凡是要开始讲大数据的,都绕不开最初的Google三驾马车:Google File System(GFS), MapReduce,BigTable。 为这一切的基础的Google File System,不但没有任何倒台的迹象,还在不断的演化,事实上支撑着Google这个庞大的互联网公司的一切计算。 以下是原文内容,内容较长,建议详细阅读。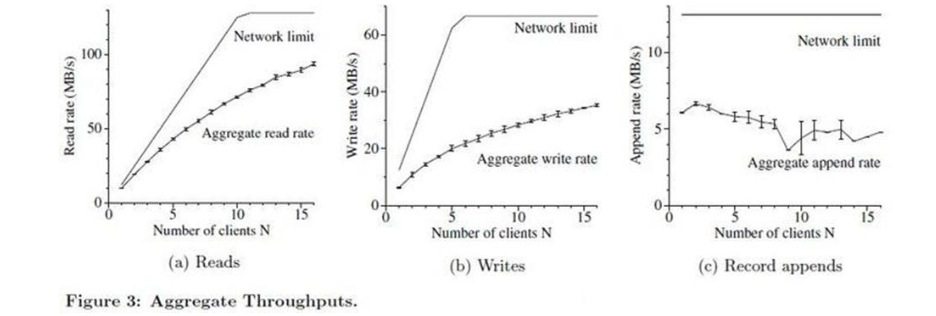
-
05.27 23:13:09发表了文章
2022-05-27 23:13:09
大数据理论篇HDFS的基石——Google File System(一)
Google File System 但凡是要开始讲大数据的,都绕不开最初的Google三驾马车:Google File System(GFS), MapReduce,BigTable。 为这一切的基础的Google File System,不但没有任何倒台的迹象,还在不断的演化,事实上支撑着Google这个庞大的互联网公司的一切计算。 以下是原文内容,内容较长,建议详细阅读。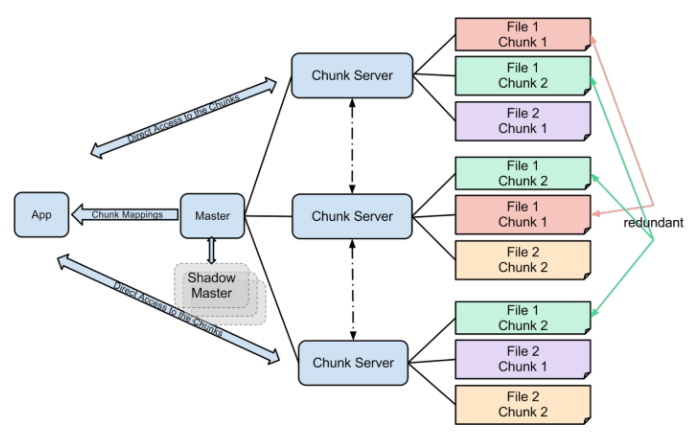
-
05.27 22:59:48发表了文章
2022-05-27 22:59:48
Kafka2.6.0发布——性能大幅提升
Kafka2.6.0发布——性能大幅提升 -
05.27 22:57:43发表了文章
2022-05-27 22:57:43
Spark Streaming——Spark第一代实时计算引擎
虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreaming。SparkStreaming对于时间窗口,事件时间虽然支撑较少,但还是可以满足部分的实时计算场景的,SparkStreaming资料较多,这里也做一个简单介绍。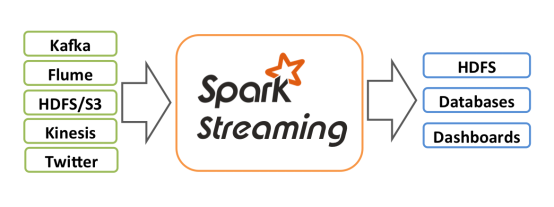
-
05.27 22:53:01发表了文章
2022-05-27 22:53:01
用Spark进行实时流计算
用Spark进行实时流计算
-
05.27 22:48:54发表了文章
2022-05-27 22:48:54
什么是流处理
流处理正变得像数据处理一样流行。流处理已经超出了其原来的实时数据处理的范畴,它正在成为一种提供数据处理(包括批处理),实时应用乃至分布式事务的新方法的技术。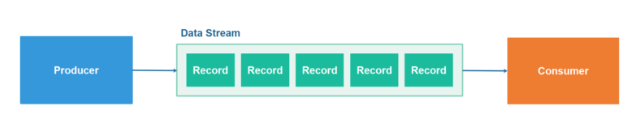
-
05.27 22:42:56发表了文章
2022-05-27 22:42:56
Plink v0.1.0 发布——基于Flink的流处理平台
Plink是一个基于Flink的流处理平台,旨在基于 [Apache Flink]封装构建上层平台。提供常见的作业管理功能。如作业的创建,删除,编辑,更新,保存,启动,停止,重启,管理,多作业模板配置等。Flink SQL 编辑提交功能。如 SQL 的在线开发,智能提示,格式化,语法校验,保存,采样,运行,测试,集成 Kafka 等。 由于项目刚刚启动,未来还有很长的路要走,让我们拭目以待。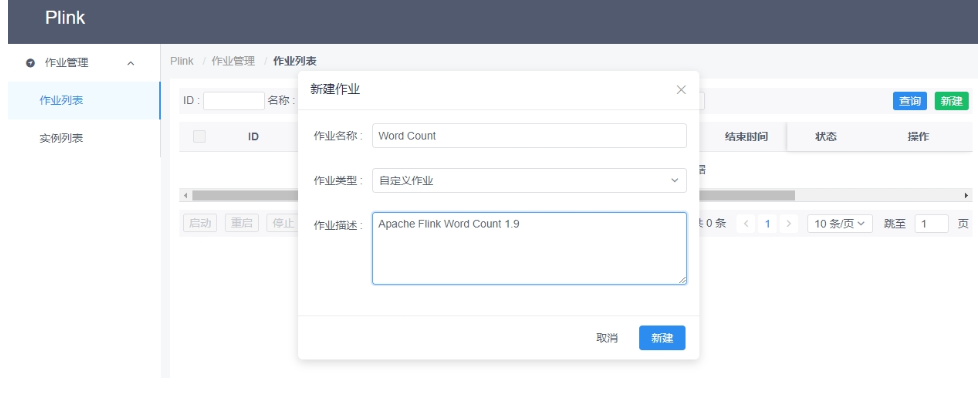
-
05.27 22:37:12发表了文章
2022-05-27 22:37:12
用户画像产品化——从零开始搭建实时用户画像(六)
在开发好用户标签以后,如何将标签应用到实际其实是一个很重要的问题。只有做好产品的设计才能让标签发挥真正的价值,本文将介绍用户画像的产品化过程。
-
05.27 22:32:20发表了文章
2022-05-27 22:32:20
用Python进行实时计算——PyFlink快速入门
Flink 1.9.0及更高版本支持Python,也就是PyFlink。 在最新版本的Flink 1.10中,PyFlink支持Python用户定义的函数,使您能够在Table API和SQL中注册和使用这些函数。但是,听完所有这些后,您可能仍然想知道PyFlink的架构到底是什么?作为PyFlink的快速指南,本文将回答这些问题。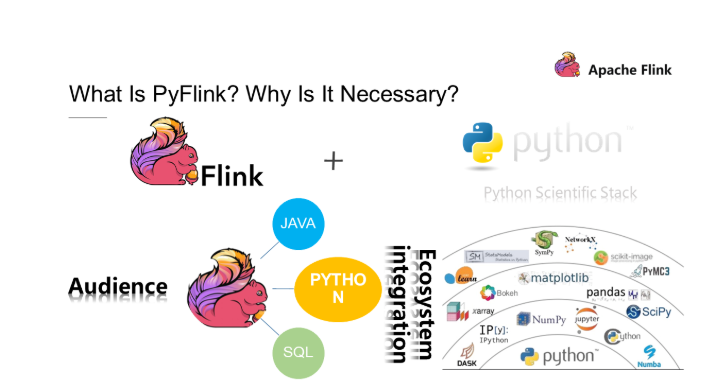
-
05.27 21:55:35发表了文章
2022-05-27 21:55:35
Spark3.0分布,Structured Streaming UI登场
Spark3.0分布,Structured Streaming UI登场
-
05.27 21:52:38发表了文章
2022-05-27 21:52:38
实时标签开发——从零开始搭建实时用户画像(五)
实时标签开发——从零开始搭建实时用户画像(五)
-
05.27 21:48:42发表了文章
2022-05-27 21:48:42
Spark Streaming,Flink,Storm,Kafka Streams,Samza:如何选择流处理框架
根据最新的统计显示,仅在过去的两年中,当今世界上90%的数据都是在新产生的,每天创建2.5万亿字节的数据,并且随着新设备,传感器和技术的出现,数据增长速度可能会进一步加快。从技术上讲,这意味着我们的大数据处理将变得更加复杂且更具挑战性。而且,许多用例(例如,移动应用广告,欺诈检测,出租车预订,病人监护等)都需要在数据到达时进行实时数据处理,以便做出快速可行的决策。这就是为什么分布式流处理在大数据世界中变得非常流行的原因。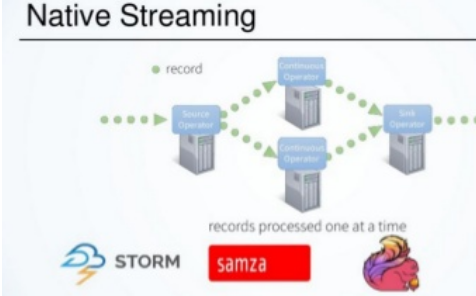
-
05.27 21:46:04发表了文章
2022-05-27 21:46:04
用户画像大数据环境搭建——从零开始搭建实时用户画像(四)
本章我们开始正式搭建大数据环境,目标是构建一个稳定的可以运维监控的大数据环境。我们将采用Ambari搭建底层的Hadoop环境,使用原生的方式搭建Flink,Druid,Superset等实时计算环境。使用大数据构建工具与原生安装相结合的方式,共同完成大数据环境的安装。
-
05.27 21:37:05发表了文章
2022-05-27 21:37:05
用户画像标签体系——从零开始搭建实时用户画像(三)
用户画像标签体系——从零开始搭建实时用户画像(三)
-
05.27 21:31:02发表了文章
2022-05-27 21:31:02
用户画像系统架构——从零开始搭建实时用户画像(二)
在《什么是用户画像》一文中,我们已经知道用户画像对于企业的巨大意义,当然也有着非常大实时难度。那么在用户画像的系统架构中都有哪些难度和重点要考虑的问题呢?
-
05.27 20:14:58发表了文章
2022-05-27 20:14:58
什么是用户画像——从零开始搭建实时用户画像(一)
什么是用户画像——从零开始搭建实时用户画像(一)
-
05.27 20:08:16发表了文章
2022-05-27 20:08:16
一站式Kafka平台解决方案——KafkaCenter
一站式Kafka平台解决方案——KafkaCenter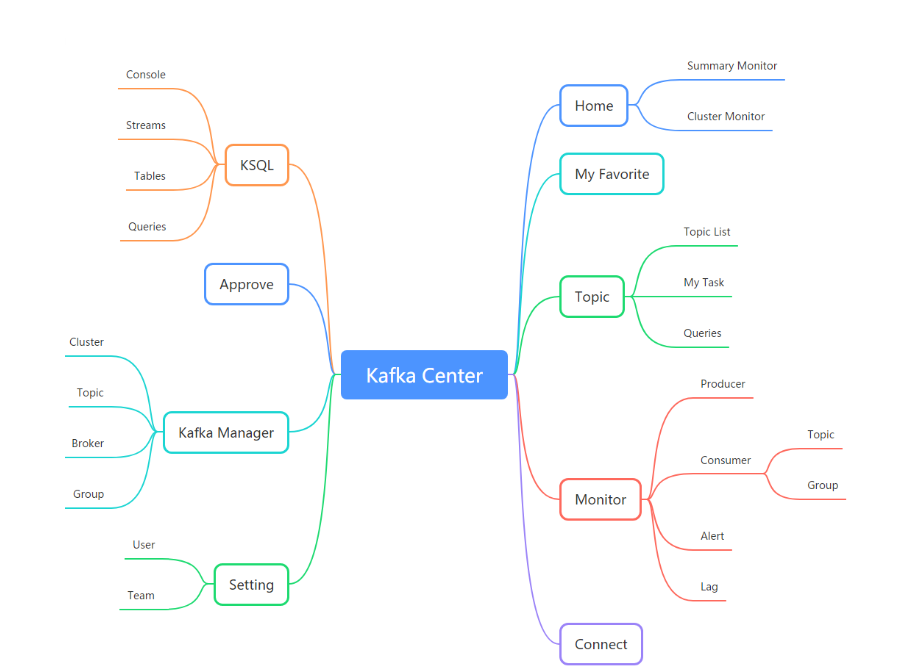
-
05.27 19:58:02发表了文章
2022-05-27 19:58:02
Druid 0.17入门(4)—— 数据查询方式大全
本文介绍Druid查询数据的方式,首先我们保证数据已经成功载入。 Druid查询基于HTTP,Druid提供了查询视图,并对结果进行了格式化。 Druid提供了三种查询方式,SQL,原生JSON,CURL。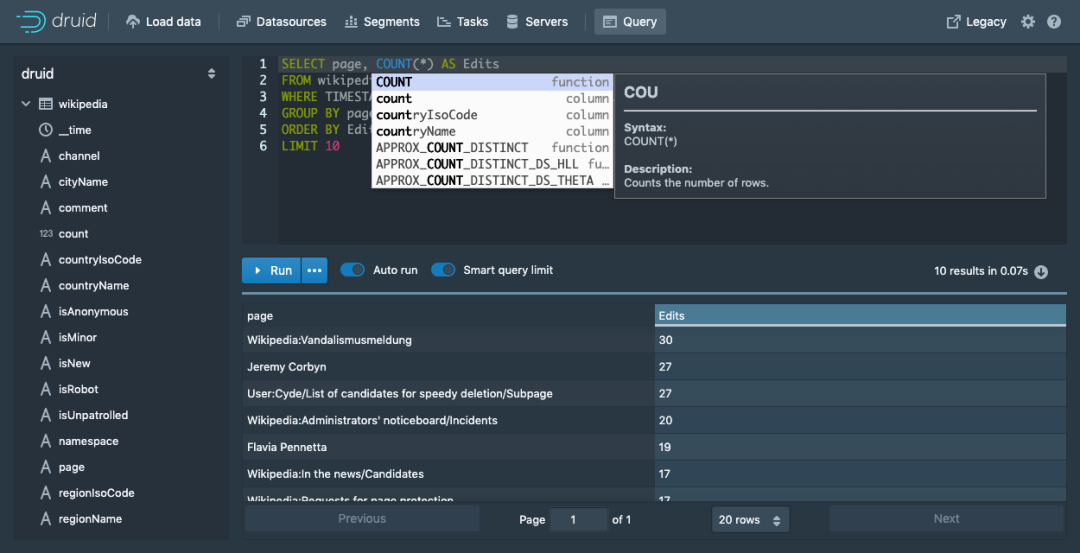
-
05.27 17:45:52发表了文章
2022-05-27 17:45:52
流媒体与实时计算,Netflix公司Druid应用实践
流媒体与实时计算,Netflix公司Druid应用实践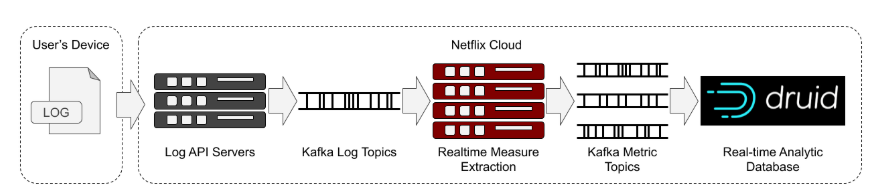
-
05.27 17:35:09发表了文章
2022-05-27 17:35:09
实时流式计算系统中的几个陷阱
随着诸如Apache Flink,Apache Spark,Apache Storm之类的开源框架以及诸如Google Dataflow之类的云框架的增多,创建实时数据处理作业变得非常容易。这些API定义明确,并且诸如Map-Reduce之类的标准概念在所有框架中都遵循几乎相似的语义。 但是,直到今天,实时数据处理领域的开发人员都在为该领域的某些特性而苦苦挣扎。因此,他们在不知不觉中创建了一条路径,该路径导致了应用程序中相当常见的错误。 让我们看一下在设计实时应用程序时可能需要克服的一些陷阱。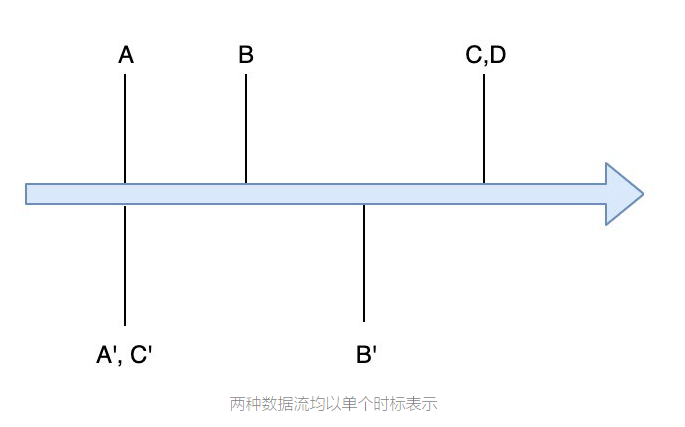
-
05.27 17:32:10发表了文章
2022-05-27 17:32:10
DataHub——实时数据治理平台
DataHub——实时数据治理平台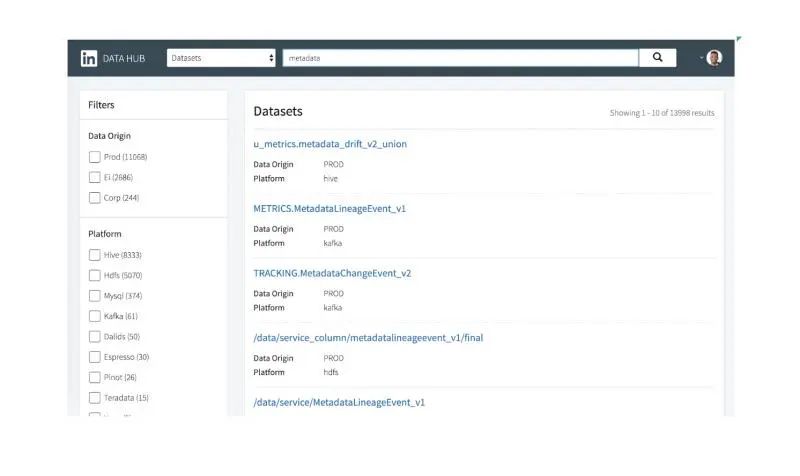
-
05.27 17:27:30发表了文章
2022-05-27 17:27:30
一小时搭建实时数据分析平台
实时数据分析门槛较高,我们如何用极少的开发工作就完成实时数据平台的搭建,做出炫酷的图表呢?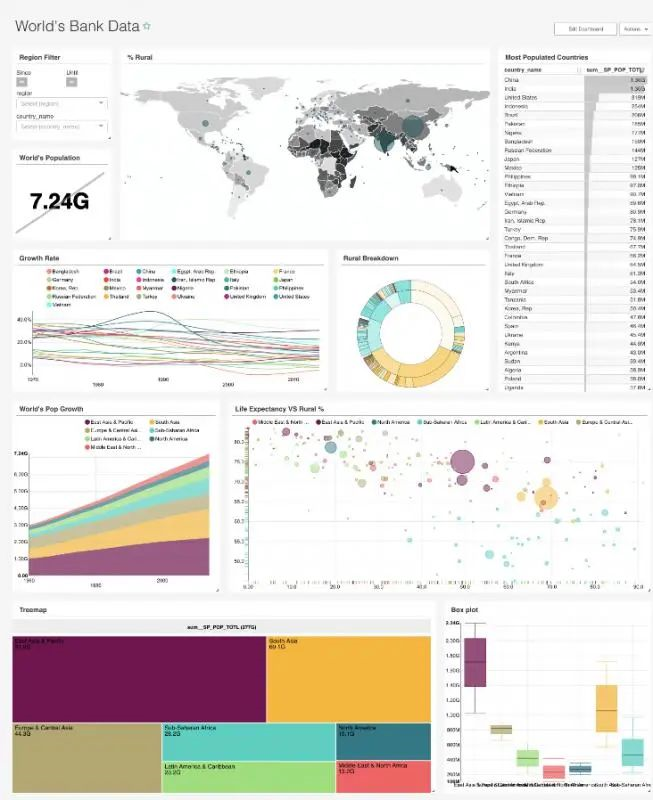
-
05.27 11:20:32发表了文章
2022-05-27 11:20:32
重大更新!Druid 0.18.0 发布—Join登场,支持Java11
Apache Druid本质就是一个分布式支持实时数据分析的数据存储系统。 能够快速的实现查询与数据分析,高可用,高扩展能力。 距离上一次更新刚过了二十多天,距离0.17版本刚过了三个多月,Druid再次迎来重大更新,Druid也越来越强大了。 Apache Druid 0.18.0 本次更新了 42位贡献者的200多个新功能,性能增强,BUG修复以及文档改进。 -
05.26 23:31:25发表了文章
2022-05-26 23:31:25
Scala学习系列(三)——入门与基础
Scala学习系列(三)——入门与基础
-
05.26 23:23:11发表了文章
2022-05-26 23:23:11
Kafka 2.5.0发布——弃用对Scala2.11的支持
Kafka 2.5.0发布——弃用对Scala2.11的支持 -
05.26 23:22:41发表了文章
2022-05-26 23:22:41
超200万?约翰斯·霍普金大学数据错误!——谈谈如何保证实时计算数据准确性
超200万?约翰斯·霍普金大学数据错误!——谈谈如何保证实时计算数据准确性
-
05.26 23:12:59发表了文章
2022-05-26 23:12:59
Scala学习系列(二)——环境安装配置
Scala学习系列(二)——环境安装配置
-
05.26 23:00:47发表了文章
2022-05-26 23:00:47
Scala学习系列(一)——Scala为什么是大数据第一高薪语言
Scala学习系列(一)——Scala为什么是大数据第一高薪语言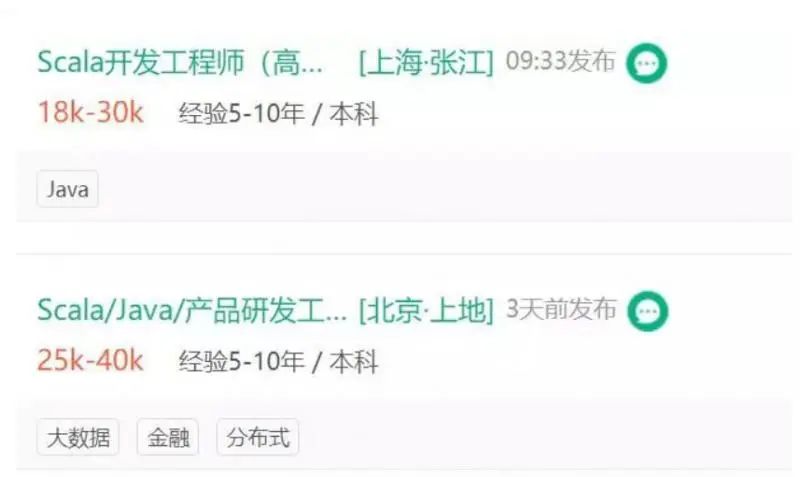
-
05.26 22:56:41发表了文章
2022-05-26 22:56:41
全球疫情实时监控——约翰斯·霍普金斯大学数据大屏实现方案
全球疫情实时监控——约翰斯·霍普金斯大学数据大屏实现方案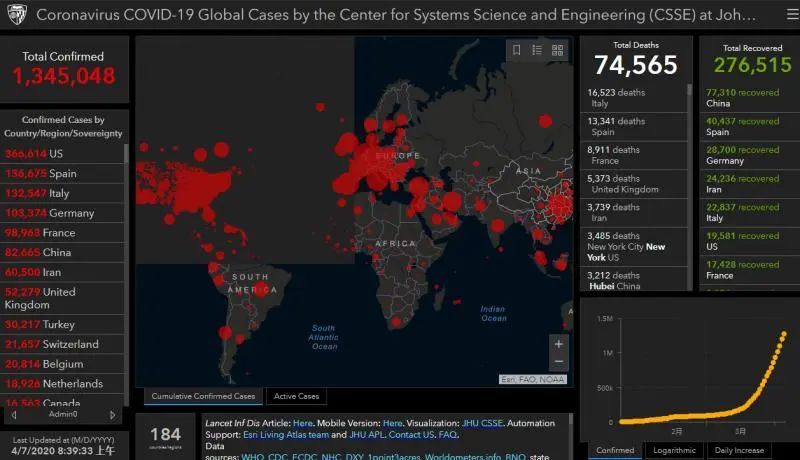
-
05.26 22:52:09发表了文章
2022-05-26 22:52:09
Druid 0.17 入门(3)—— 数据接入指南
在快速开始中,我们演示了接入本地示例数据方式,但Druid其实支持非常丰富的数据接入方式。比如批处理数据的接入和实时流数据的接入。本文我们将介绍这几种数据接入方式。 • 文件数据接入:从文件中加载批处理数据 • 从Kafka中接入流数据:从Kafka中加载流数据 • Hadoop数据接入:从Hadoop中加载批处理数据 • 编写自己的数据接入规范:自定义新的接入规范 本文主要介绍前两种最常用的数据接入方式。
-
05.26 22:42:18发表了文章
2022-05-26 22:42:18
Druid 0.17 入门(2)—— 安装与部署
在Druid快速入门其实已经简单的介绍过最简化配置的单节点部署,本文我们将详细描述Druid的多种部署方式,对于测试开发环境可以选用轻量的单机部署方式,而生产环境我们最好选用集群部署的方式,确保系统的高可用性。
-
05.26 22:39:44发表了文章
2022-05-26 22:39:44
Flink 1.10 正式发布!——与Blink集成完成,集成Hive,K8S
Apache Flink社区宣布Flink 1.10.0正式发布! 本次Release版本修复1.2K个问题,对Flink作业的整体性能和稳定性做了重大改进,同时增加了对K8S,Python的支持。 这个版本标志着与Blink集成的完成,并且强化了流式SQL与Hive的集成,本文将详细介绍新功能和主要的改进。
-
05.26 22:34:51发表了文章
2022-05-26 22:34:51
Druid入门(1)—— 快速入门实时分析利器-Druid_0.17
Druid入门(1)—— 快速入门实时分析利器-Druid_0.17
-
05.26 21:40:44发表了文章
2022-05-26 21:40:44
什么是Druid
什么是Druid
-
05.26 21:36:52发表了文章
2022-05-26 21:36:52
Flink入门——DataSet Api编程指南
Flink入门——DataSet Api编程指南
-
05.26 21:30:53发表了文章
2022-05-26 21:30:53
Vmvare扩展虚拟机磁盘大小
Vmvare扩展虚拟机磁盘大小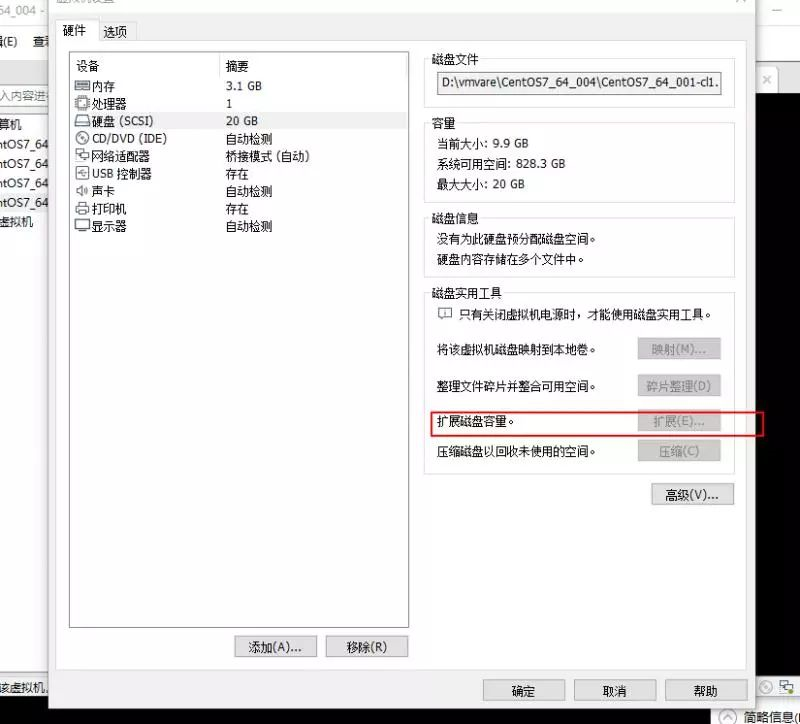
-
05.26 21:28:49发表了文章
2022-05-26 21:28:49
Ambari 2.7.3.0安装新组件
Ambari 2.7.3.0安装新组件和之前版本略有不同,本文将简述安装新组件的简单过程。 前提是大家已经安装好Ambari 2.7.3.0 这时候由于有一些组件没有添加,就需要安装新的组件。
-
05.26 21:21:21发表了文章
2022-05-26 21:21:21
Flink入门——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性、高吞吐、低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群环境。另外介绍Flink的开发工程的构建。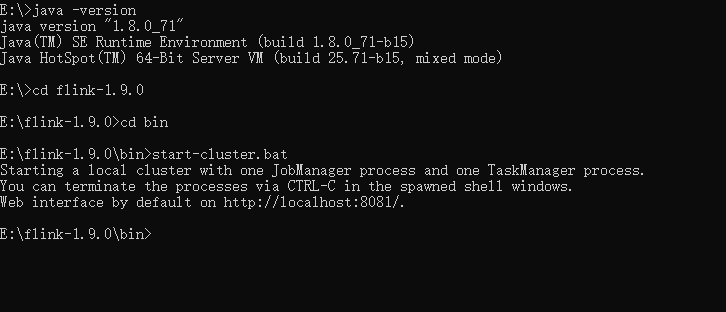
-
05.26 21:10:37发表了文章
2022-05-26 21:10:37
数据治理的王者——Apache Atlas
数据治理的王者——Apache Atlas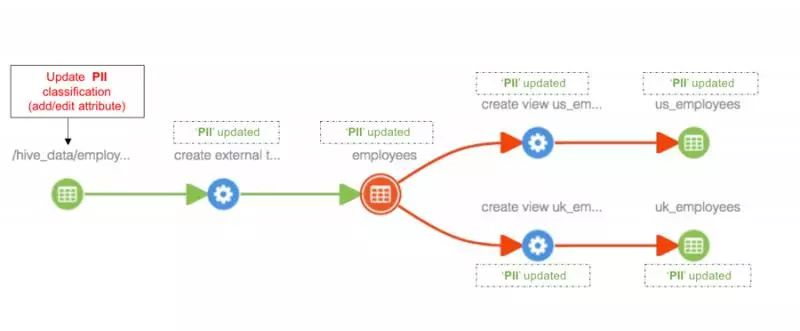
-
05.26 21:06:57发表了文章
2022-05-26 21:06:57
什么是全文检索
全文检索技术被广泛的应用于搜索引擎,查询检索等领域。我们在网络上的大部分搜索服务都用到了全文检索技术。 对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
-
05.26 20:58:16发表了文章
2022-05-26 20:58:16
Hbase入门(五)——客户端(Java,Shell,Thrift,Rest,MR,WebUI)
Hbase的客户端有原生java客户端,Hbase Shell,Thrift,Rest,Mapreduce,WebUI等等。 下面是这几种客户端的常见用法。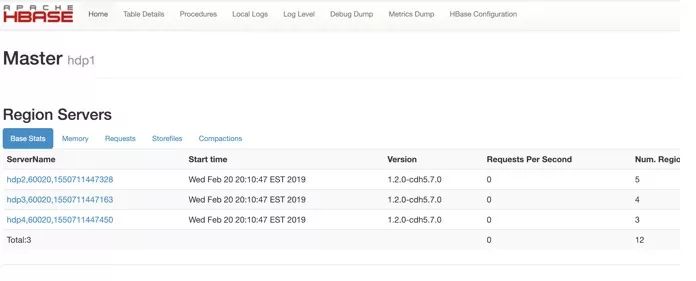
-
05.26 20:54:44发表了文章
2022-05-26 20:54:44
Hbase入门(四)——表结构设计-RowKey
Hbase的表结构设计与关系型数据库有很多不同,主要是Hbase有Rowkey和列族、timestamp这几个全新的概念,如何设计表结构就非常的重要。
-
05.26 20:29:44发表了文章
2022-05-26 20:29:44
Hbase入门(三)——数据模型
Hbase最核心但也是最难理解的就是数据模型,由于与传统的关系型数据库不同,虽然Hbase也有表(Table),也有行(Row)和列(Column),但是与关系型数据库不同的是Hbase有一个列族(Column Family)的概念,它将一列或者多列组织在一起,HBase必须属于某一个列族。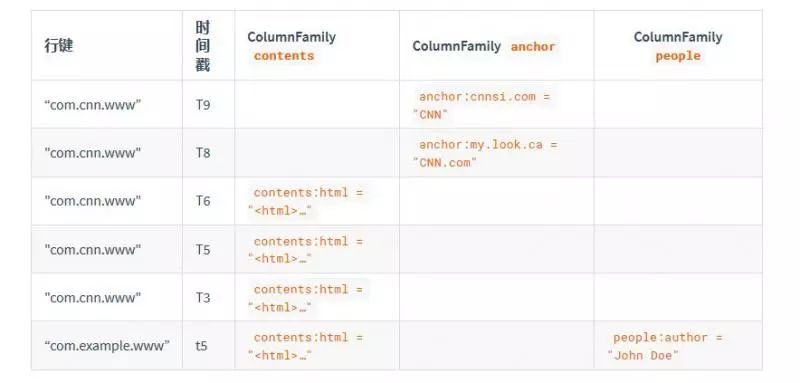
-
05.26 20:25:18发表了文章
2022-05-26 20:25:18
Hbase入门(二)——安装与配置
本文讲述如何安装,部署,启停HBase集群,如何通过命令行对Hbase进行基本操作。 并介绍Hbase的配置文件。 在安装前需要将所有先决条件安装完成。
-
05.26 20:17:28发表了文章
2022-05-26 20:17:28
Hbase入门(一)——初识Hbase
本文将介绍大数据的知识和Hbase的基本概念,作为大数据体系中重要的一员,Hbase弥补了Hadoop只能离线批处理的不足,支持存储小文件,随机检索。而这种特性使得Hbase对于实时计算体系的事件存储有天然的较好的支持。这使得Hbase在实时流式计算中也扮演者重要的角色。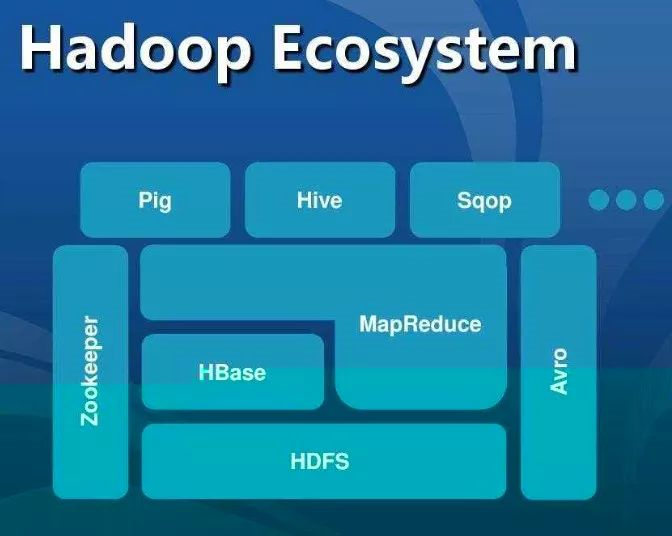
-
05.26 20:14:18发表了文章
2022-05-26 20:14:18
Flink1.9整合Kafka
本文基于Flink1.9版本简述如何连接Kafka。
-
05.26 20:11:51发表了文章
2022-05-26 20:11:51
Flink入门宝典(详细截图版)
本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本。需要安装Netcat进行简单调试。 这里简述安装过程,并使用IDEA进行开发一个简单流处理程序,本地调试或者提交到Flink上运行,Maven与JDK安装这里不做说明。
-
05.26 20:05:12发表了文章
2022-05-26 20:05:12
Kafka常见错误整理
Kafka常见错误整理
-
发表了文章
2024-05-15
深度实践 | 自如基于Apache StreamPark 的实时计算平台实践
-
发表了文章
2024-05-15
阿里云实时计算企业级状态存储引擎 Gemini 技术解读
-
发表了文章
2024-05-15
数据资产新规!《关于加强数据资产管理的指导意见》发布(附全文)
-
发表了文章
2024-05-15
元数据管理平台对比预研 Atlas VS Datahub VS Openmetadata
-
发表了文章
2024-05-15
Apache Paimon 表模式最佳实践
-
发表了文章
2024-05-15
【开源项目推荐】Great Expectations—开源的数据质量工具
-
发表了文章
2024-05-15
最新版本——Hadoop3.3.6单机版完全部署指南
-
发表了文章
2024-05-15
Apache Paimon 在网易传媒推荐场景实践
-
发表了文章
2024-05-15
【开源项目】轻量元数据管理解决方案——Marquez
-
发表了文章
2024-05-15
使用GPT4进行数据分析,竟然被他骗了
-
发表了文章
2024-05-15
Apache DolphinScheduler VS WhaleScheduler
-
发表了文章
2024-05-15
Apache Paimon:Streaming Lakehouse is Coming
-
发表了文章
2024-05-15
大厂 5 年实时数据开发经验总结,Flink SQL 看这篇就够了!
-
发表了文章
2024-05-15
【开源项目推荐】8.9K纯中文本地GPT知识库搭建项目
-
发表了文章
2024-05-15
《数据资产管理实践》方法论梳理
-
发表了文章
2024-05-15
【开源项目推荐】Apache Superset——最优秀的开源数据可视化与数据探索平台
-
发表了文章
2024-05-15
【开源项目推荐】OpenMetadata——基于开放元数据的一体化数据治理平台
-
发表了文章
2024-05-15
Paimon 实践 | 基于 Flink SQL 和 Paimon 构建流式湖仓新方案
-
发表了文章
2024-05-15
Flink + Paimon 数据 CDC 入湖最佳实践
-
发表了文章
2024-05-15
Apache Paimon流式湖仓学习交流群成立
滑动查看更多
暂无更多信息
暂无更多信息