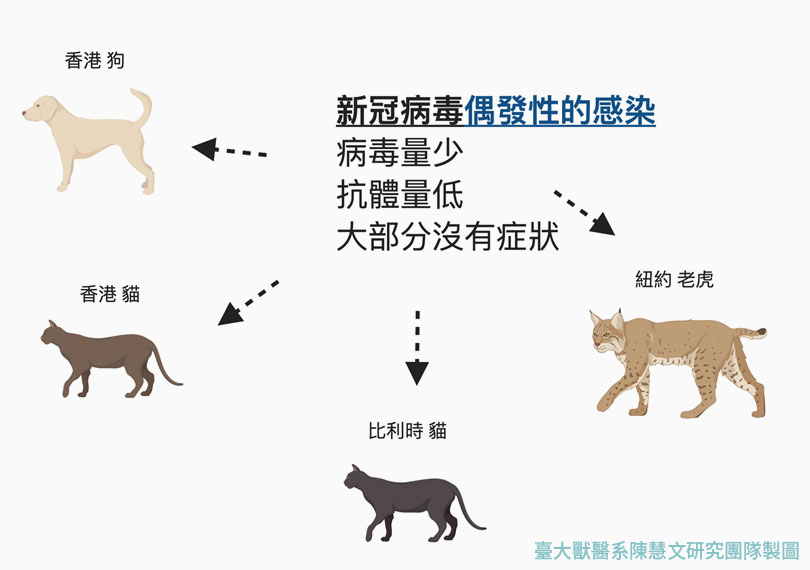
云原生容器Clouder认证:容器应用与集群管理
云原生Clouder认证:函数计算的功能与使用入门
云原生数据库Clouder认证:PolarDB 快速入门
云数据库Clouder认证:SQL基础开发与应用
弹性计算Clouder认证:服务器迁移上云
云原生容器Clouder认证:容器应用与集群管理
云原生Clouder认证:函数计算的功能与使用入门
云原生数据库Clouder认证:PolarDB 快速入门
云数据库Clouder认证:SQL基础开发与应用
弹性计算Clouder认证:服务器迁移上云
暂无个人介绍
2025年04月
 回答了问题
2025-04-26 16:20:10
回答了问题
2025-04-25 10:57:16
回答了问题
2025-04-15 09:42:43
回答了问题
2025-04-14 20:23:07
回答了问题
2025-04-14 20:16:08
回答了问题
2025-04-26 16:20:10
回答了问题
2025-04-25 10:57:16
回答了问题
2025-04-15 09:42:43
回答了问题
2025-04-14 20:23:07
回答了问题
2025-04-14 20:16:08
2025年03月
回答了问题
2025-03-12 19:18:42
回答了问题
2025-03-06 20:11:33
回答了问题
2025-03-06 20:09:47
回答了问题
2025-03-06 20:06:47
回答了问题
2025-03-06 20:05:10
回答了问题
2025-03-06 20:03:33
回答了问题
2025-03-06 20:02:00
2025年01月
回答了问题
2025-01-14 14:05:43
回答了问题
2025-01-14 14:01:12
回答了问题
2025-01-14 13:57:08
回答了问题
2025-01-14 11:55:00
回答了问题
2025-01-14 11:52:11
回答了问题
2025-01-14 11:43:35
2024年12月
回答了问题
2024-12-17 15:09:48
2024年11月
回答了问题
2024-11-21 17:44:52
回答了问题
2024-11-19 11:25:18
回答了问题
2024-11-19 11:22:49
回答了问题
2024-11-19 11:19:19
回答了问题
2024-11-19 11:14:29
2024年06月
回答了问题
2024-06-13 14:38:11
回答了问题
2024-06-11 16:11:05
回答了问题
2024-06-11 16:05:22
回答了问题
2024-06-11 16:04:15
回答了问题
2024-06-11 16:03:00
回答了问题
2024-06-11 16:01:46
2024年05月
回答了问题
2024-05-30 14:04:58
回答了问题
2024-05-30 13:51:47
回答了问题
2024-05-24 15:56:19
 发表了文章
2024-05-21 17:24:11
回答了问题
2024-05-15 19:49:58
发表了文章
2024-03-08 15:13:57
发表了文章
2024-05-21 17:24:11
回答了问题
2024-05-15 19:49:58
发表了文章
2024-03-08 15:13:57
2024年04月
回答了问题
2024-04-23 14:37:50
回答了问题
2024-04-23 14:35:53
2024年03月
回答了问题
2024-03-27 13:47:36
回答了问题
2024-03-27 13:43:10
回答了问题
2024-03-27 12:00:28
回答了问题
2024-03-27 11:53:35
回答了问题
2024-03-21 14:20:07
回答了问题
2024-03-21 14:17:19
回答了问题
2024-03-21 14:16:09
回答了问题
2024-03-13 11:25:33
回答了问题
2024-03-13 11:24:32
回答了问题
2024-03-13 11:23:09
回答了问题
2024-03-13 11:14:07
发表了文章
2024-05-21
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
 回答了问题
2025-04-26
回答了问题
2025-04-25
回答了问题
2025-04-15
回答了问题
2025-04-14
回答了问题
2025-04-14
回答了问题
2025-03-12
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2024-12-17
回答了问题
2024-11-21
回答了问题
2025-04-26
回答了问题
2025-04-25
回答了问题
2025-04-15
回答了问题
2025-04-14
回答了问题
2025-04-14
回答了问题
2025-03-12
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-03-06
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2025-01-14
回答了问题
2024-12-17
回答了问题
2024-11-21