





快速切换多种画风!FlexIP:腾讯开源双适配器图像生成框架,精准平衡身份保持与个性化编辑
本文解析腾讯最新开源的FlexIP图像框架,其通过双适配器架构与动态门控机制实现身份保持与个性化编辑的精准平衡,在CLIP-I指标上取得0.873的高分验证了技术突破。

Cloudflare推出托管式RAG服务!AutoRAG:从数据上传到索引更新全程托管,文档变动自动同步
AutoRAG是Cloudflare推出的全托管检索增强生成服务,基于自动索引和向量化技术,帮助开发者快速构建上下文感知的AI应用,无需管理底层基础设施。

TxGemma:谷歌DeepMind革命药物研发!270亿参数AI药理学家24小时在线
谷歌推出专为药物研发设计的TxGemma大模型,具备药物特性预测、生物文献筛选、多步推理等核心能力,提供20亿至270亿参数版本,显著提升治疗开发效率。

Video-T1:视频生成实时手术刀!清华腾讯「帧树算法」终结闪烁抖动
清华大学与腾讯联合推出的Video-T1技术,通过测试时扩展(TTS)和Tree-of-Frames方法,显著提升视频生成的连贯性与文本匹配度,为影视制作、游戏开发等领域带来突破性解决方案。
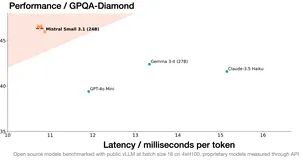
Mistral Small 3.1:240亿参数多模态黑马!128k长文本+图像分析,推理速度150token/秒
Mistral Small 3.1 是 Mistral AI 开源的多模态人工智能模型,具备 240 亿参数,支持文本和图像处理,推理速度快,适合多种应用场景。
热门论文推荐:TPDiff、Block Diffusion、Reangle-A-Video、GTR
由新加坡国立大学Show Lab的Lingmin Ran和Mike Zheng Shou提出,TPDiff是一个创新的视频扩散模型框架,针对视频生成的高计算需求问题,通过分阶段逐步提高帧率优化了训练和推理效率。核心贡献包括提出“时间金字塔”方法和阶段式扩散训练策略,实验表明训练成本降低50%,推理效率提升1.5倍。
TrajectoryCrafter:腾讯黑科技!单目视频运镜自由重构,4D生成效果媲美实拍
TrajectoryCrafter 是腾讯与香港中文大学联合推出的单目视频相机轨迹重定向技术,支持后期自由调整视频的相机位置和角度,生成高质量的新型轨迹视频,广泛应用于沉浸式娱乐、创意视频制作等领域。
IMAGPose:南理工突破性人体生成框架!多姿态适配+细节语义融合,刷新图像生成范式
IMAGPose 是南京理工大学推出的用于人体姿态引导图像生成的统一条件框架,解决了传统方法在姿态引导的人物图像生成中的局限性,支持多场景适应、细节与语义融合、灵活的图像与姿态对齐以及全局与局部一致性。

SpatialVLA:上海AI Lab联合上科大推出的空间具身通用操作模型
SpatialVLA 是由上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,赋予机器人强大的3D空间理解能力,支持跨平台泛化控制。
打造跨语言智能工具与应用,“万卷·丝路”专项课题开放申请
随着共建“一带一路”进入高质量发展阶段,全球开发者对于多语言模型训练的需求不断增长,上海AI实验室联合大模型语料数据联盟成员发布了“万卷·丝路”多语言预训练语料库,为多语言大模型训练提供高质量数据支撑,助力全球开发者构建跨语言智能工具与应用。
FlashMLA:DeepSeek最新开源!MLA解码内核让NVIDIA Hopper开启性能狂暴模式,推理速度飙升至3000GB/s
FlashMLA 是 DeepSeek 开源的高效 MLA 解码内核,专为 NVIDIA Hopper 架构 GPU 优化,支持 BF16 精度和页式 KV 缓存,适用于大语言模型推理和自然语言处理任务。

仅7B的模型数学推理能力完虐70B?MIT哈佛推出行动思维链COAT让LLM实现自我反思并探索新策略
Satori 是由 MIT 和哈佛大学等机构联合推出的 7B 参数大型语言模型,专注于提升推理能力,具备强大的自回归搜索和自我纠错功能。
ssm020基于ssm的人才招聘网站(文档+源码)_kaic
网络和科技的进步以及人们生活条件的提高都让计算机技术越来越平民化,深入日常生活中。网络更是成为生活的必备条件,大到国家单位、科研项目,小到大街小巷都充斥着网络的身影。在日常办公中,计算机起到了文字编辑、打印、信息检索、统计等的作用。使用计算机可以使日常繁杂的信息进行科学的加工,使信息变得更加的有序、可利用。计算机技术已成为热门。 正是因为网络、科技、计算机技术使现代人的生活和工作变得便利、轻松,给实体行业带来了巨大的冲击。人才招聘的日常工作也遇到了前所未有的挑战。现如今,对于招聘的管理有很多的局限性,究其原因是因为招聘管理的根本是信息的运动。在新时代的环境下,传统的管理方式不再满足用户的需求,
阿里通义等提出Chronos:慢思考RAG技术助力新闻时间线总结
在数字化时代,新闻信息的指数级增长使得从海量文本中提取和整理历史事件的时间线变得至关重要。为了应对这一挑战,阿里巴巴通义实验室与上海交通大学的中断者提出了一种基于Agent的新闻时间线摘要新框架——CH RONOS,源自希腊神话中的时间之神柯罗诺斯,该框架通过迭代多轮的自我提问方式,结合检索增强生成技术,从互联网上检索相关事件信息,并生成时间顺序的新闻摘要,为新闻时间线摘要生成提供了一种全新的解决方案。
OpenCSG开源SmolTalk Chinese数据集
近年来,人工智能(AI)领域尤其是自然语言处理(NLP)技术的迅猛发展,正在深刻改变着各行各业的运作模式。从智能客服到内容生成,从自动翻译到智能搜索,NLP技术的广泛应用使得语言模型在全球范围内的重要性日益凸显。与此密切相关的预训练模型(Pre-trained Models),凭借在海量数据上的训练积累了丰富的知识,成为NLP技术进步的核心支柱。然而,预训练模型的成功在很大程度上依赖于其背后数据集的质量。
OpenCSG开源最大中文合成数据集Chinese Cosmopedia
近年来,生成式语言模型(GLM)的飞速发展正在重塑人工智能领域,尤其是在自然语言处理、内容创作和智能客服等领域展现出巨大潜力。

ParGo:字节与中山大学联合推出的多模态大模型连接器,高效对齐视觉与语言模态
ParGo 是字节与中山大学联合推出的多模态大模型连接器,通过全局与局部视角联合,提升视觉与语言模态的对齐效果,支持高效连接、细节感知与自监督学习。

MarS:微软开源金融市场模拟预测引擎,支持策略测试、风险管理和市场分析
MarS 是微软亚洲研究院推出的金融市场模拟预测引擎,基于生成型基础模型 LMM,支持无风险环境下的交易策略测试、风险管理和市场分析。

TangoFlux:高速生成高质量音频,仅用3.7秒生成长达30秒的音频,支持文本到音频转换
TangoFlux 是由英伟达与新加坡科技设计大学联合开发的文本到音频生成模型,能够在3.7秒内生成30秒的高质量音频,支持文本到音频的直接转换和用户偏好优化。
社区供稿 | Para-Former:DUAT理论指导下的CV神经网络并行化,提速多层模型推理
神经网络正越来越多地朝着使用大数据训练大型模型的方向发展,这种解决方案在许多任务中展现出了卓越的性能。然而,这种方法也引入了一个迫切需要解决的问题:当前的深度学习模型基于串行计算,这意味着随着网络层数的增加,训练和推理时间也会随之增长。


Granite 3.1:IBM 开源新一代可商用大语言模型,支持 128K 上下文长度、多语言和复杂任务处理
IBM 推出的 Granite 3.1 是一款新一代语言模型,具备强大的性能和更长的上下文处理能力,支持多语言和复杂任务处理。


CLEAR:新加坡国立大学推出线性注意力机制,使8K图像的生成速度提升6.3倍,显著减少了计算量和时间延迟
新加坡国立大学推出的CLEAR线性注意力机制,通过局部注意力窗口设计,显著提升了预训练扩散变换器生成高分辨率图像的效率,生成8K图像时提速6.3倍。

LeviTor:蚂蚁集团开源3D目标轨迹控制视频合成技术,能够控制视频中3D物体的运动轨迹
LeviTor是由南京大学、蚂蚁集团等机构联合推出的3D目标轨迹控制视频合成技术,通过结合深度信息和K-means聚类点控制视频中3D物体的轨迹,无需显式的3D轨迹跟踪。
CodeFuse「编码挑战季」:冲刺最后1个月!MelGeek磁轴键盘、Beats耳机等你来拿~
从1024程序员节起至12月底,CodeFuse「编码挑战季」火热进行中!参与muAgent、MFTCoder、ModelCache、CodeFuse-IDE四个项目的编码挑战,不仅能够深化对CodeFuse项目及开源社区的理解,还能赢取定制周边及高端奖品,如MelGeekMADE68 PRO磁轴键盘、Beats Studio Pro无线蓝牙耳机等。活动期间,开发者可根据任务难度获取积分,兑换丰富奖品。立即加入,让我们一起探索技术的无限可能!

ClotheDreamer:上海大学联合腾讯等高校推出的3D服装生成技术
ClotheDreamer是由上海大学、上海交通大学、复旦大学和腾讯优图实验室联合推出的3D服装生成技术,能够根据文本描述生成高保真、可穿戴的3D服装资产,适用于虚拟试穿和物理精确动画。

Micro LLAMA:教学版 LLAMA 3模型实现,用于学习大模型的核心原理
Micro LLAMA是一个精简的教学版LLAMA 3模型实现,旨在帮助学习者理解大型语言模型的核心原理。该项目仅约180行代码,便于理解和学习。Micro LLAMA基于LLAMA 3中最小的8B参数模型,适合对深度学习和模型架构感兴趣的研究者和学生。

360Zhinao2-7B:360推出自研360智脑大模型的升级版
360Zhinao2-7B是360自研的AI大模型360智脑7B参数升级版,涵盖基础模型及多种上下文长度的聊天模型。该模型在语言理解与生成、聊天能力、数学逻辑推理等方面表现出色,支持多语言和多上下文长度,适用于多种商业应用场景。

GLM-Edge:智谱开源的端侧大语言和多模态系列模型
GLM-Edge是智谱开源的一系列端侧部署优化的大语言对话模型和多模态理解模型,旨在实现模型性能、实机推理效果和落地便利性之间的最佳平衡。该系列模型支持在手机、车机和PC等端侧设备上高效运行,适用于智能助手、聊天机器人、图像标注等多种应用场景。

Promptriever:信息检索模型,支持自然语言提示响应用户搜索需求
Promptriever 是一种新型信息检索模型,由约翰斯·霍普金斯大学和 Samaya AI 联合推出。该模型能够接受自然语言提示,并以直观的方式响应用户的搜索需求。通过在 MS MARCO 数据集上的训练,Promptriever 在标准检索任务上表现出色,能够更有效地遵循详细指令,提高查询的鲁棒性和检索性能。

ShowUI:新加坡国立联合微软推出用于 GUI 自动化的视觉-语言-操作模型
ShowUI是由新加坡国立大学Show Lab和微软联合推出的视觉-语言-行动模型,旨在提升图形用户界面(GUI)助手的效率。该模型通过UI引导的视觉令牌选择和交错视觉-语言-行动流,有效减少计算成本并提高训练效率。ShowUI在小规模高质量数据集上表现出色,展现出在GUI自动化领域的潜力。

ModelScope模型即服务
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352




