








阿里开源AI视频生成大模型 Wan2.1:14B性能超越Sora、Luma等模型,一键生成复杂运动视频
Wan2.1是阿里云开源的一款AI视频生成大模型,支持文生视频和图生视频任务,具备强大的视觉生成能力,性能超越Sora、Luma等国内外模型。
统一多模态Embedding, 通义实验室开源GME系列模型
随着多媒体应用的迅猛发展,用户产生的数据类型日益多样化,不再局限于文本,还包含大量图像、音频和视频等多模态信息。这为信息检索带来了前所未有的挑战与机遇。传统的信息检索模型多关注单一模态,如仅对文本或图像进行分析和搜索。

CosyVoice 2.0:阿里开源升级版语音生成大模型,支持多语言和跨语言语音合成,提升发音和音色等的准确性
CosyVoice 2.0 是阿里巴巴通义实验室推出的语音生成大模型升级版,通过有限标量量化技术和块感知因果流匹配模型,显著提升了发音准确性、音色一致性和音质,支持多语言和流式推理,适合实时语音合成场景。
用Qwen3+MCPs实现AI自动发布小红书笔记!支持图文和视频
魔搭自动发布小红书MCP,是魔搭开发者小伙伴实现的小红书笔记自动发布器,可以通过这个MCP自动完成小红书标题、内容和图片的发布。
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。

自然语言生成代码一键搞定!Codex CLI:OpenAI开源终端AI编程助手,代码重构+测试全自动
Codex CLI是OpenAI推出的轻量级AI编程智能体,基于自然语言指令帮助开发者高效生成代码、执行文件操作和进行版本控制,支持代码生成、重构、测试及数据库迁移等功能。

多模态模型卷王诞生!InternVL3:上海AI Lab开源78B多模态大模型,支持图文视频全解析!
上海人工智能实验室开源的InternVL3系列多模态大语言模型,通过原生多模态预训练方法实现文本、图像、视频的统一处理,支持从1B到78B共7种参数规模。

MNN:阿里开源的轻量级深度学习推理框架,支持在移动端等多种终端上运行,兼容主流的模型格式
MNN 是阿里巴巴开源的轻量级深度学习推理框架,支持多种设备和主流模型格式,具备高性能和易用性,适用于移动端、服务器和嵌入式设备。

MarkItDown:微软开源的多格式转Markdown工具,支持将PDF、Word、图像和音频等文件转换为Markdown格式
MarkItDown 是微软开源的多功能文档转换工具,支持将 PDF、PPT、Word、Excel、图像、音频等多种格式的文件转换为 Markdown 格式,具备 OCR 文字识别、语音转文字和元数据提取等功能。

EchoMimicV2:阿里推出的开源数字人项目,能生成完整数字人半身动画
EchoMimicV2是阿里蚂蚁集团推出的开源数字人项目,能够生成完整的数字人半身动画。该项目基于参考图片、音频剪辑和手部姿势序列,通过音频-姿势动态协调策略生成高质量动画视频,确保音频内容与半身动作的一致性。EchoMimicV2不仅支持中文和英文驱动,还简化了动画生成过程中的复杂条件,适用于虚拟主播、在线教育、娱乐和游戏等多个应用场景。

FLUX.1 Tools 全家桶开源!文末附一键ComfyUI启动链接
Black Forest Labs 发布了 FLUX.1 Tools,一套增强 FLUX.1 文本转图像模型的工具集,包括 FLUX.1 Fill、FLUX.1 Depth、FLUX.1 Canny 和 FLUX.1 Redux,分别用于图像修复、深度引导、边缘检测和图像重组。提供详细的安装指南和模型下载链接,支持用户快速上手并优化图像处理流程。
分享一个开源的MCP工具使用的AI Agent 支持常用的AI搜索/地图/金融/浏览器等工具
介绍一个开源可用的 MCP Tool Use 通用工具使用的 AI Agent (GitHub: https://github.com/AI-Agent-Hub/mcp-marketplace ,Web App https://agent.deepnlp.org/agent/mcp_tool_use,支持大模型从Open MCP Marketplace (http://deepnlp.org/store/ai-agent/mcp-server) 的1w+ 的 MCP Server的描述和 Tool Schema 里面,根据用户问题 query 和 工具 Tool描述的 相关性,选择出来可以满足

Browser Use:40.7K Star!一句话让AI完全接管浏览器!自动规划完成任务,多标签页同时管理
Browser Use 是一款专为大语言模型设计的智能浏览器自动化工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。

通古大模型:古籍研究者狂喜!华南理工开源文言文GPT:AI自动断句+写诗翻译,24亿语料喂出来的学术神器
通古大模型由华南理工大学开发,专注于古籍文言文处理,具备强大的古文句读、文白翻译和诗词创作功能。
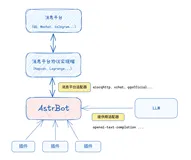
AstrBot:轻松将大模型接入QQ、微信等消息平台,打造多功能AI聊天机器人的开发框架,附详细教程
AstrBot 是一个开源的多平台聊天机器人及开发框架,支持多种大语言模型和消息平台,具备多轮对话、语音转文字等功能。

InvSR:开源图像超分辨率生成模型,提升分辨率,修复老旧照片为超清图像
InvSR 是一个创新的图像超分辨率模型,基于扩散模型的逆过程恢复高分辨率图像。它通过深度噪声预测器和灵活的采样机制,能够高效地提升图像分辨率,适用于老旧照片修复、视频监控、医疗成像等多个领域。

FastExcel:开源的 JAVA 解析 Excel 工具,集成 AI 通过自然语言处理 Excel 文件,完全兼容 EasyExcel
FastExcel 是一款基于 Java 的高性能 Excel 处理工具,专注于优化大规模数据处理,提供简洁易用的 API 和流式操作能力,支持从 EasyExcel 无缝迁移。

video-analyzer:开源视频分析工具,支持提取视频关键帧、音频转录,自动生成视频详细描述
video-analyzer 是一款开源视频分析工具,结合 Llama 的 11B 视觉模型和 OpenAI 的 Whisper 模型,能够提取视频关键帧、转录音频并生成详细描述,支持本地运行和多种应用场景
通义灵码 + 魔搭MCP:全流程构建创空间应用
最近,通义灵码上线 MCP(ModelScope Cloud Platform)功能,从之前代码生成及修改的基础功能,到可以使用MCP服务连接更多功能,开发者可以实现从 代码爬取、模型推理到应用部署

AutoAgent:无需编程!接入DeepSeek用自然语言创建和部署AI智能体!港大开源框架让AI智能体开发变成填空题
香港大学推出的AutoAgent框架通过自然语言交互实现零代码创建AI智能体,支持多模型接入与自动化工作流编排,在GAIA基准测试中表现优异。
4G显存部署Flux,2分钟Wan2.1-14B视频生成,DiffSynth-Engine引擎开源!
魔搭社区的开源项目 DiffSynth-Studio 自推出以来,凭借其前沿的技术探索和卓越的创新能力,持续受到开源社区的高度关注与广泛好评。截至目前,该项目已在 GitHub 上斩获超过 8,000 颗星,成为备受瞩目的开源项目之一。作为以技术探索为核心理念的实践平台,DiffSynth-Studio 基于扩散模型(Diffusion Model),在图像生成和视频生成领域孵化出了一系列富有创意且实用的技术成果,其中包括 ExVideo、ArtAug、EliGen 等代表性模块。


Agno:18.7K Star!快速构建多模态智能体的轻量级框架,运行速度比LangGraph快5000倍!
Agno 是一个用于构建多模态智能体的轻量级框架,支持文本、图像、音频和视频等多种数据模态,能够快速创建智能体并实现高效协作。

三行代码实现实时语音转文本,支持自动断句和语音唤醒,用 RealtimeSTT 轻松创建高效语音 AI 助手
RealtimeSTT 是一款开源的实时语音转文本库,支持低延迟应用,具备语音活动检测、唤醒词激活等功能,适用于语音助手、实时字幕等场景。

斯坦福黑科技让笔记本GPU也能玩转AI视频生成!FramePack:压缩输入帧上下文长度!仅需6GB显存即可生成高清动画
斯坦福大学推出的FramePack技术通过压缩输入帧上下文长度,解决视频生成中的"遗忘"和"漂移"问题,仅需6GB显存即可在普通笔记本上实时生成高清视频。
线上共学 | Mac本地玩转大模型
本文介绍如何在Mac本地部署和使用大模型,包括基础运行、多模态扩展、交互优化、知识增强、定制进化等技术链路,并提供Ollama、Stable Diffusion、LM-Studio等工具的详细操作指南。
微信小程序数据缓存与本地存储:优化用户体验
本文深入探讨微信小程序的数据缓存与本地存储,介绍其意义、机制及应用场景。通过合理使用内存和本地缓存,可减少网络请求、提升加载速度和用户体验。文中详细讲解了常用缓存API的使用方法,并通过一个新闻列表案例展示了缓存的实际应用。最后提醒开发者注意缓存大小限制、时效性和清理,以确保最佳性能。

手把手教你使用 Ollama 和 LobeChat 快速本地部署 DeepSeek R1 模型,创建个性化 AI 助手
DeepSeek R1 + LobeChat + Ollama:快速本地部署模型,创建个性化 AI 助手

用自然语言控制电脑,字节跳动开源 UI-TARS 的桌面版应用!内附详细的安装和配置教程
UI-TARS Desktop 是一款基于视觉语言模型的 GUI 代理应用,支持通过自然语言控制电脑操作,提供跨平台支持、实时反馈和精准的鼠标键盘控制。
linux 全局搜索文件
在 Linux 系统中,全局搜索文件常用 `find`、`locate` 和 `grep` 命令。`find` 根据文件名、类型、大小、时间戳等条件搜索;`locate` 通过预构建的数据库快速查找文件;`grep` 在文件中搜索特定文本,常与 `find` 结合使用。选择合适的命令取决于具体需求。

让AI听懂你的建模需求!BlenderMCP:自然语言指令直接操控 Blender,一句话生成复杂3D场景
BlenderMCP通过MCP协议实现Blender与Claude AI的无缝集成,支持通过自然语言指令完成3D建模、材质调整等复杂操作,显著提升创作效率。
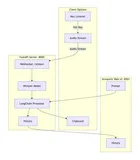
WhisperChain:开源 AI 实时语音转文字工具!自动消噪优化文本,效率翻倍
WhisperChain 是一款基于 Whisper.cpp 和 LangChain 的开源语音识别工具,能够实时将语音转换为文本,并自动清理和优化文本内容,适用于会议记录、写作辅助等多种场景。

Step-Audio:开源语音交互新标杆!这个国产AI能说方言会rap,1个模型搞定ASR+TTS+角色扮演
Step-Audio 是由阶跃星辰团队推出的开源语音交互模型,支持多语言、方言和情感表达,能够实现高质量的语音识别、对话和合成。本文将详细介绍其核心功能和技术原理。
Qwen2.5-VL Cookbook来啦!手把手教你怎么用好视觉理解模型!
今天,Qwen团队发布了一系列展示 Qwen2.5-VL 用例的Notebook,包含本地模型和 API 的使用。
IROS 2025 |从数字智能走向物理智能,“桃源”与真实世界机器人学习挑战赛启动,2大赛道等你来战
2025年10月,IROS (智能机器人与系统国际会议)期间,上海人工智能实验室(上海AI实验室)将举办物理世界中的多模态机器人学习研讨会,IROS 2025“桃源”与真实世界机器人学习挑战赛(机器人学习挑战赛)现已启动报名,欢迎全球创新者与挑战者参加。

音乐人必看!OpenUtau:开源AI歌声合成神器,快速打造专业级虚拟歌手,中文日文无缝切换
OpenUtau是一款开源的歌声合成工具,兼容UTAU音源库和重采样器,支持多语言界面及预渲染功能,让音乐创作更加高效便捷。

共学 | 2025年,更加有效地搭建Agent
2024年末,Anthropic写了一篇叫做“Building effective Agents”的文章,针对如何有效的搭建Agent,常见Agent工作流程的几种范式,以及对现在的Code Agent工作模式做了详细的解读。本文结合cookbook+ModelScope的免费Qwen API做了一些中文示例的实践,来更好的理解这篇文章。

JoyCaption:开源的图像转提示词生成工具,支持多种风格和场景,性能与 GPT4o 相当
JoyCaption 是一款开源的图像提示词生成工具,支持多种生成模式和灵活的提示选项,适用于社交媒体、图像标注、内容创作等场景,帮助用户快速生成高质量图像描述。

Midscene.js:AI 驱动的 UI 自动化测试框架,支持自然语言交互,生成可视化报告
Midscene.js 是一款基于 AI 技术的 UI 自动化测试框架,通过自然语言交互简化测试流程,支持动作执行、数据查询和页面断言,提供可视化报告,适用于多种应用场景。

Browser Use:开源 AI 浏览器助手,自动完成网页交互任务,支持多标签页管理、视觉识别和内容提取等功能
Browser Use 是一款专为大语言模型设计的智能浏览器工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。

WeaveFox:蚂蚁集团推出 AI 前端智能研发平台,能够根据设计图直接生成源代码,支持多种客户端和技术栈
蚂蚁团队推出的AI前端研发平台WeaveFox,能够根据设计图直接生成前端源代码,支持多种应用类型和技术栈,提升开发效率和质量。本文将详细介绍WeaveFox的功能、技术原理及应用场景。

Resume Matcher:增加面试机会!开源AI简历优化工具,一键解析简历和职位描述并优化
Resume Matcher 是一款开源AI简历优化工具,通过解析简历和职位描述,提取关键词并计算文本相似性,帮助求职者优化简历内容,提升通过自动化筛选系统(ATS)的概率,增加面试机会。

LangGraph:构建多代理动态工作流的开源框架,支持人工干预、循环、持久性等复杂工作流自动化
LangGraph 是一个基于图结构的开源框架,专为构建状态化、多代理系统设计,支持循环、持久性和人工干预,适用于复杂的工作流自动化。
Nanonets-OCR-s开源!复杂文档转Markdown SoTA,颠覆复杂文档工作流
Nanonets团队开源了 Nanonets-OCR-s,该模型基于Qwen2.5-VL-3B微调,9G显存就能跑。
Qwen3开源发布:Think Deeper, Act Faster!社区推理、部署、微调、MCP调用实战教程来啦!
Qwen3开源发布:Think Deeper, Act Faster!社区推理、部署、微调、MCP调用实战教程来啦!


