




趣丸千音MCP首发上线魔搭社区,多重技术引擎,解锁AI语音无限可能
近日,趣丸千音(All Voice Lab)MCP正式首发上线魔搭社区。用户只需简单文本输入,即可调用视频翻译、TTS语音合成、智能变声、人声分离、多语种配音、语音转文本、字幕擦除等多项能力。
B站开源SOTA动画视频生成模型 Index-AniSora!
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成!

测试工程师要失业?Magnitude:开源AI Agent驱动的端到端测试框架,让Web测试更智能,自动完善测试用例!
Magnitude是一个基于视觉AI代理的开源端到端测试框架,通过自然语言构建测试用例,结合推理代理和视觉代理实现智能化的Web应用测试,支持本地运行和CI/CD集成。

音乐人狂喜!AbletonMCP:让AI帮你写歌,一句话生成专业编曲,Demo级作品秒出
AbletonMCP 是一个开源项目,通过模型上下文协议(MCP)将 Ableton Live 与 Claude AI 连接,实现 AI 辅助音乐制作,支持创建、修改 MIDI 和音频轨道等操作。

Amazon Nova Act:网页操作全自动!亚马逊黑科技把浏览器变AI机器人,请假/订餐/写邮件一键搞定
Amazon Nova Act是亚马逊AGI实验室推出的通用AI代理系统,通过原子化分解网页操作任务并配合Playwright实现高可靠性浏览器自动化,其配套SDK支持开发者快速构建智能体应用原型。

Hi3DGen:2D照片秒变高精度模型,毛孔级细节完爆Blender!港中文×字节×清华联手打造3D生成黑科技
Hi3DGen是由香港中文大学、字节跳动和清华大学联合研发的高保真3D几何生成框架,通过法线图中间表示实现细节丰富的3D模型生成,其双阶段生成流程显著提升了几何保真度。

TaoAvatar:手机拍出电影级虚拟人!阿里3D高斯黑科技让动捕设备下岗
阿里巴巴最新推出的TaoAvatar技术,通过3D高斯溅射实现照片级虚拟人实时渲染,支持多信号驱动与90FPS流畅运行,将彻底改变电商直播与远程会议体验。

Qwen2.5-VL-32B:阿里开源多模态核弹!32B模型吊打自家72B,数学推理封神
阿里巴巴最新开源的Qwen2.5-VL-32B多模态模型,在数学推理、视觉问答等任务中超越前代72B版本,支持图像细粒度理解和复杂逻辑分析,已在HuggingFace开源。
Gemma3:Google开源多模态神器,轻量高效,精通140+语言,解锁文本与图像任务
在当今快速发展的 AI 领域,多模态模型正逐渐成为推动技术革新的重要力量。Google 最新推出的 Gemma 3 模型,凭借其轻量级、多模态的特性,为文本生成和图像理解任务带来了全新的可能性。它不仅支持文本和图像输入,还具备强大的语言处理能力,覆盖超过 140 种语言,并且能够在资源有限的设备上高效运行。从问答到摘要,从推理到图像分析,Gemma 3 正在重新定义 AI 模型的边界,为开发者和研究人员提供了一个极具潜力的工具。

Shandu:开源AI研究黑科技!自动挖掘多层级信息,智能生成结构化报告
Shandu 是一款开源的 AI 研究自动化工具,结合 LangChain 和 LangGraph 技术,能够自动化地进行多层次信息挖掘和分析,生成结构化的研究报告,适用于学术研究、市场分析和技术探索等多种场景。

DeepSeek开源周第五弹之二!Smallpond:构建于3FS之上的轻量级数据处理框架,高效处理PB级数据
Smallpond 是 DeepSeek 开源的轻量级数据处理框架,基于 DuckDB 和 3FS 构建,支持 PB 级数据处理,提供高性能的数据加载、查询和转换功能,适合大规模数据预处理和实时分析。

VideoGrain:零样本多粒度视频编辑神器,用AI完成换装改场景,精准控制每一帧!
VideoGrain 是悉尼科技大学和浙江大学推出的零样本多粒度视频编辑框架,基于调节时空交叉注意力和自注意力机制,实现类别级、实例级和部件级的精细视频修改,保持时间一致性,显著优于现有方法。
王炸组合,阶跃星辰SOTA模型Step-Video和Step-Audio模型开源
2025 年 2 月 18 号,阶跃星辰宣布开源了两款 Step 系列多模态模型——Step-Video-T2V 视频生成模型和 Step-Audio 语音交互模型。
Tarsier2:字节跳动开源专注于图像和视频内容理解的视觉语言大模型
Tarsier2 是字节跳动推出的大规模视觉语言模型,支持高质量视频描述、问答与定位,在多个视频理解任务中表现优异。
微软开源课程!21节课程教你开发生成式 AI 应用所需了解的一切
微软推出的生成式 AI 入门课程,涵盖 21 节课程,帮助开发者快速掌握生成式 AI 应用开发,支持 Python 和 TypeScript 代码示例。

Sky-T1:开源版"OpenAI o1-preview",训练成本竟不到450美元
Sky-T1是NovaSky发布的开源推理AI模型,支持低成本训练,性能优异,适用于数学问题解决、编程评估和科学研究。

OmAgent:轻松构建在终端设备上运行的 AI 应用,赋能手机、穿戴设备、摄像头等多种设备
OmAgent 是 Om AI 与浙江大学联合开源的多模态语言代理框架,支持多设备连接、高效模型集成,助力开发者快速构建复杂的多模态代理应用。

SVFR:全能视频人脸修复框架,支持提升清晰度、色彩填充和缺失补全等图像修复任务
SVFR 是一个通用视频人脸修复框架,支持人脸修复、着色和修复任务,基于 Stable Video Diffusion 技术,提供高质量的视频修复效果。

StereoCrafter:腾讯开源将任意2D视频转换为立体3D视频的框架,适用于Apple Vision Pro等多种显示设备
StereoCrafter 是腾讯开源的框架,能够将单目2D视频转换为高保真度的立体3D视频,适用于多种显示设备。

Mathtutor on Groq:AI 数学辅导工具,实时计算并展示解题过程,支持通过语音提出数学问题
Mathtutor on Groq 是一款基于 Groq 架构的 AI 数学辅导工具,支持语音输入数学问题,实时计算并渲染解题过程,适用于代数、微积分等领域的学习和教学辅助。

Qwen开源视觉推理模型QVQ,更睿智地看世界!
在人类的思维中,语言和视觉紧密交织,塑造着我们感知和理解世界的方式。我们的推理能力深深植根于语言思维和视觉记忆之中。那么,当我们将这些能力赋予人工智能时,会发生什么呢?如今的大语言模型已经展现出卓越的推理能力,但我们不禁思考:它们能否通过掌握视觉理解的力量,攀登认知能力的新高峰?
MajorRAG聊天问答系统实现分析(3/3)
一个RAG项目,全文共三个部分:MajorRAG概述、MajorRAG文件内容提取实现分析、MajorRAG聊天问答系统实现分析。 1)第一次做RAG,欢迎带着指导意见评论 2)希望指出不足时可以附带替换方法 博客地址:https://zhangcraigxg.github.io
46_LLM幻觉问题:来源与早期研究_深度解析
大型语言模型(LLM)在自然语言处理领域展现出了令人惊叹的能力,能够生成连贯的文本、回答复杂问题、进行创意写作,甚至在某些专业领域提供见解。然而,这些强大模型的一个根本性缺陷——幻觉问题,正成为限制其在关键应用中广泛部署的主要障碍。幻觉(Hallucination)指的是LLM生成的内容与事实不符、上下文矛盾、逻辑错误,或者完全虚构信息的现象。
2025魔搭MCP&Agent挑战赛正式启动!50万总奖池!
2025魔搭MCP&Agent挑战赛正式拉开帷幕!这是一场聚焦MCP协议生态与Agent应用落地的顶级开发者盛会,旨在推动工具标准化与智能体场景创新,探索AI开发者在终端硬件的创新实践。
Nanonets-OCR-s开源!复杂文档转Markdown SoTA,颠覆复杂文档工作流
Nanonets团队开源了 Nanonets-OCR-s,该模型基于Qwen2.5-VL-3B微调,9G显存就能跑。

开源8B参数全能扩散模型Flex.2-preview:把线稿变商稿,还能边画边改!
Flex.2-preview是Ostris开源的80亿参数文本到图像扩散模型,支持512token长文本输入和多类型控制引导,内置修复功能并兼容主流AI绘画工具链。

AI竟能独立完成顶会论文!The AI Scientist-v2:开源端到端AI自主科研系统,自动探索科学假设生成论文
The AI Scientist-v2 是由 Sakana AI 等机构开发的端到端自主科研系统,通过树搜索算法与视觉语言模型反馈实现科学假设生成、实验执行及论文撰写全流程自动化,其生成论文已通过国际顶会同行评审。

开源学习神器把2小时网课压成5分钟脑图!BiliNote:一键转录哔哩哔哩视频,生成结构化学习文档
本文介绍基于FastAPI与React构建的开源视频笔记工具BiliNote,其整合多模态AI技术实现视频内容结构化解析,支持跨平台视频源处理与本地化部署方案,提供从语音转写到智能摘要的全流程自动化能力。

用AI精准定位问题代码,调试时间直接砍半!LocAgent:斯坦福开源代码调试神器,多跳推理锁定问题代码
LocAgent是由斯坦福大学、耶鲁大学等顶尖机构联合开发的代码定位框架,通过将代码库转化为图结构并利用大语言模型的多跳推理能力,实现精准的问题代码定位。

AI智能体内战终结者!A2A:谷歌开源的首个标准智能体交互协议,让AI用同一种“语言”交流
A2A是谷歌推出的首个标准化智能体交互协议,通过统一通信规范实现不同框架AI智能体的安全协作,支持多模态交互和长时任务管理,已有50多家企业加入生态。
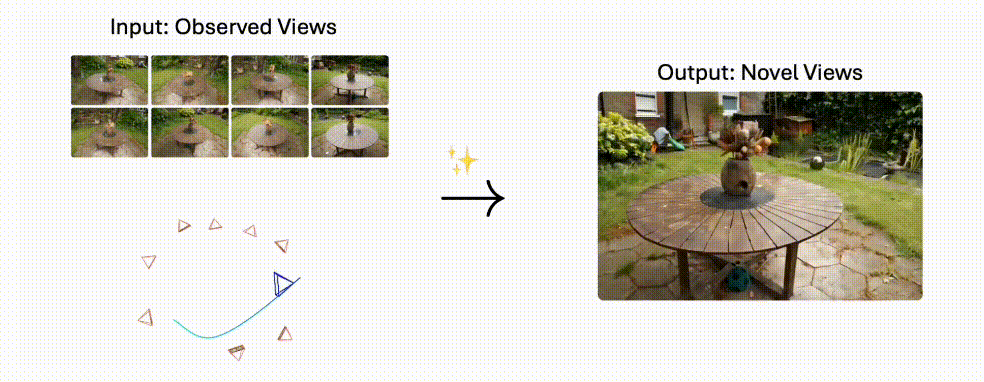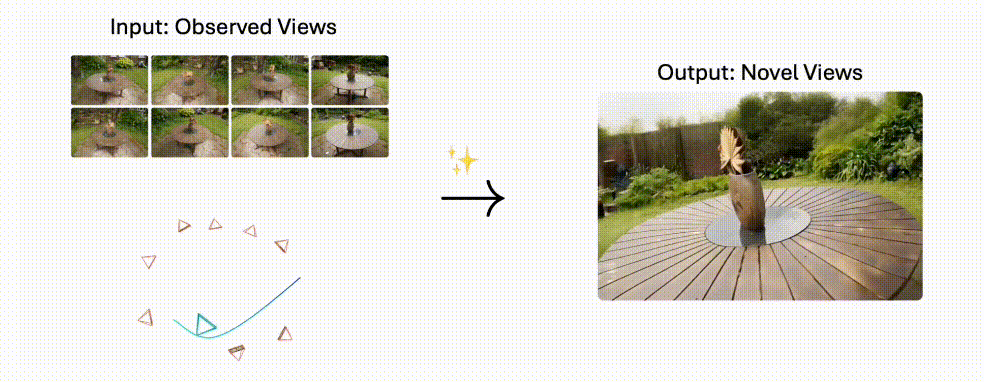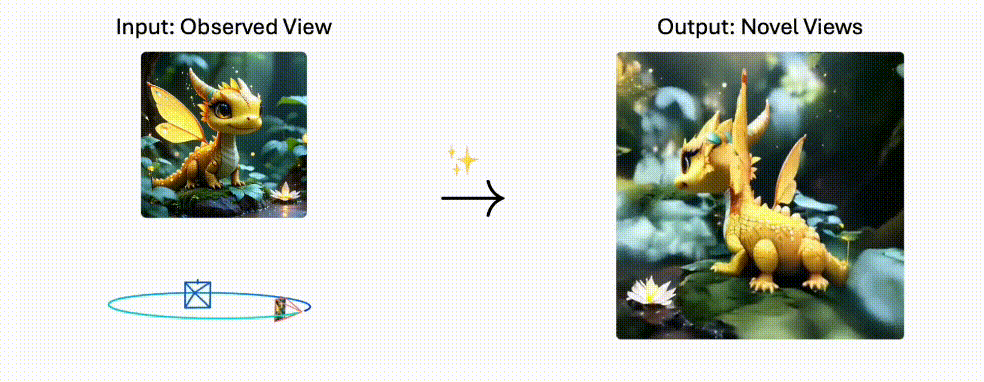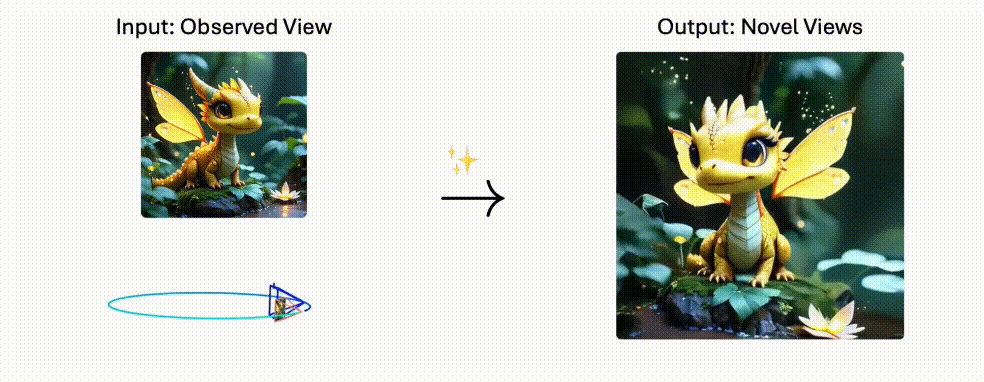
Stable Virtual Camera:2D秒变3D电影!Stability AI黑科技解锁无限运镜,自定义轨迹一键生成
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能够将 2D 图像转换为具有真实深度和透视感的 3D 视频,支持自定义相机轨迹和多种动态路径,生成高质量且时间平滑的视频。

MT-TransformerEngine:国产训练核弹!FP8+算子融合黑科技,Transformer训练速度飙升300%
MT-TransformerEngine 是摩尔线程开源的高效训练与推理优化框架,专为 Transformer 模型设计,通过算子融合、并行加速等技术显著提升训练效率,支持 FP8 混合精度训练,适用于 BERT、GPT 等大型模型。
COMET:字节跳动开源MoE训练加速神器,单层1.96倍性能提升,节省百万GPU小时
COMET是字节跳动推出的针对Mixture-of-Experts(MoE)模型的优化系统,通过细粒度的计算-通信重叠技术,显著提升分布式训练效率,支持多种并行策略和大规模集群部署。

还在蹲Manus的邀请码?别等了!开源版Manus为你快速创建AI工位,给AI一台电脑,然后你就玩去吧!
OpenManus 是 MetaGPT 的开源 AI 平台,支持多语言模型和工具链,执行代码、处理文件等任务,具备实时反馈。OWL 基于 CAMEL-AI,支持角色分配、任务分解和记忆功能,实现高效任务自动化。

Proxy Lite:仅3B参数的开源视觉模型!快速实现网页自动化,支持在消费级GPU上运行
Proxy Lite 是一款开源的轻量级视觉语言模型,支持自动化网页任务,能够像人类一样操作浏览器,完成网页交互、数据抓取、表单填写等重复性工作,显著降低自动化成本。
BioMedGPT-R1:生物医药ChatGPT诞生!蒸馏DeepSeek R1突破人类专家水平,分子解析+靶点预测一键搞定
BioMedGPT-R1 是清华大学与水木分子联合开发的多模态生物医药大模型,支持跨模态问答、药物分子理解与靶点挖掘,性能显著提升。

HiveChat:告别模型选择困难!开源ChatGPT聚合神器上线:一键切换10+模型,权限管控全免费
HiveChat 是一款专为中小团队设计的开源 AI 聊天应用,支持多种主流 AI 模型,提供高效的团队沟通和智能辅助功能。
VideoLLaMA3:阿里达摩院开源专注于视觉理解的多模态基础模型,具备多语言视频理解能力
VideoLLaMA3 是阿里巴巴开源的多模态基础模型,专注于图像和视频理解,支持多语言生成、视频内容分析和视觉问答任务,适用于多种应用场景。

GLM-Realtime:智谱推出多模态交互AI模型,融入清唱功能,支持视频和语音交互
GLM-Realtime 是智谱推出的端到端多模态模型,具备低延迟的视频理解与语音交互能力,支持清唱功能、2分钟内容记忆及灵活调用外部工具,适用于多种智能场景。

Titans:谷歌新型神经记忆架构,突破 Transformer 长序列处理的瓶颈
Titans 是谷歌推出的新型神经网络架构,通过神经长期记忆模块突破 Transformer 在处理长序列数据时的瓶颈,支持并行计算,显著提升训练效率。

SmartEraser:中科大推出图像对象移除技术,轻松移除照片中的不想要元素,保留完美瞬间
SmartEraser 是由中科大与微软亚洲研究院联合开发的图像编辑技术,能够精准移除图像中的指定对象,同时保留周围环境的细节和结构,适用于复杂场景的图像处理。

DeepSeek Artifacts:在线实时预览的前端 AI 编程工具,基于DeepSeek V3快速生成React App
DeepSeek Artifacts是Hugging Face推出的免费AI编程工具,基于DeepSeek V3,支持快速生成React和Tailwind CSS代码,适合快速原型开发和前端组件构建。

Gemini Coder:基于 Google Gemini API 的开源 Web 应用生成工具,支持实时编辑和预览
Gemini Coder 是一款基于 Google Gemini API 的 AI 应用生成工具,支持通过文本描述快速生成代码,并提供实时代码编辑和预览功能,简化开发流程。

SEMIKONG:专为半导体领域设计的大型语言模型,支持制造优化、辅助 IC 设计等半导体制造任务
SEMIKONG 是专为半导体行业定制的大型语言模型,能够优化制造过程、辅助 IC 设计,并整合专家知识,推动领域特定 AI 模型的研究与应用。
短难误判率仅2%,新一代网关路由SHG,在P95不升前提下完胜RouteLLM。
在和 RouteLLM 的两档式对比中 RouteLLM 将约百分之 69.3 的短难请求路由至轻量模型,而本文提出的网关系统将短难请求中落入轻档的比例压缩到约 2.4%,整体 P95 几乎不变。实验表明,短难请求构成了一类独立且在实践中高度相关的 LLM 路由稳健性问题,而针对性的、常数级开销的守护机制可以在不增加整体成本和尾部延迟的前提下,大幅缓解这一问题。
113_数据收集:Common Crawl过滤与高质量LLM训练数据构建
在大型语言模型(LLM)的训练过程中,数据质量直接决定了模型的性能上限。即使拥有最先进的模型架构和训练算法,如果没有高质量的训练数据,也难以训练出优秀的语言模型。Common Crawl作为目前互联网上最大的公开网络爬虫数据集之一,为LLM训练提供了宝贵的资源。然而,从原始的Common Crawl数据中提取高质量的训练素材并非易事,需要经过严格的过滤和清洗。本文将全面探讨Common Crawl数据集的特性、过滤策略的设计原则、以及2025年最新的过滤技术,为构建高质量的LLM训练语料提供系统指导。
48_动态架构模型:NAS在LLM中的应用
大型语言模型(LLM)在自然语言处理领域的突破性进展,很大程度上归功于其庞大的参数量和复杂的网络架构。然而,随着模型规模的不断增长,计算资源消耗、推理延迟和部署成本等问题日益凸显。如何在保持模型性能的同时,优化模型架构以提高效率,成为2025年大模型研究的核心方向之一。神经架构搜索(Neural Architecture Search, NAS)作为一种自动化的网络设计方法,正在为这一挑战提供创新性解决方案。本文将深入探讨NAS技术如何应用于LLM的架构优化,特别是在层数与维度调整方面的最新进展,并通过代码实现展示简单的NAS实验。
81_Few-Shot提示:少样本学习的技巧
在大型语言模型(LLM)时代,提示工程(Prompt Engineering)已成为释放模型潜力的关键技能。其中,Few-Shot Prompting作为一种强大的技术,通过提供少量高质量的示例,显著提升模型在复杂任务上的性能。2025年,随着模型规模和能力的持续增长,Few-Shot Prompting技术也在不断演进,从简单的示例提供发展到更加精细化的优化策略。
腾讯混元 3D 世界模型家族又添新成员Voyager:支持超长距离漫游
9 月 2 日,腾讯混元宣布,其3D世界模型系列最新成员——HunyuanWorld-Voyager(简称混元Voyager)发布并开源,这将推动AI在空间智能领域的应用扩展,为虚拟现实、物理仿真、游戏开发等领域提供高保真3D场景漫游能力,加速行业应用落地。
轻量高效,8B 性能强劲书生科学多模态模型Intern-S1-mini开源
继 7 月 26 日开源『书生』科学多模态大模型 Intern-S1 之后,上海人工智能实验室(上海AI实验室)在8月23日推出了轻量化版本 Intern-S1-mini。

ModelScope模型即服务
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352


