

通义灵码进阶指南:解锁智能编程的高效玩法
本文深入解析通义灵码的高阶功能,从智能补全、注释生成、代码解释到调试辅助,助开发者提升200%编码效率。涵盖六大实战技巧:精准生成、上下文对话优化、测试矩阵生成、私有知识库接入、快捷键使用及多语言支持。同时提供企业级应用方案、避坑指南与未来功能展望,帮助用户实现需求到原型开发时间缩短60%,代码审查工作量降低40%,技术债务识别率提升75%。通过实战练习,掌握“增强式编程”新范式。
通义灵码进阶指南:解锁智能编程的深度技巧与高阶场景实战
本文深入探讨了通义灵码从基础代码补全到全流程研发加速器的升级路径,揭秘企业级深度集成方案。内容涵盖核心能力再认知(如智能维度拆解与硬件级优化)、精准控制技术(如结构化指令模板与上下文锁定)、企业级应用(私有知识库构建与研发流水线增强)以及高阶场景实战(架构可视化重构与多模态交互)。同时提供避坑指南、效能度量体系,并展望研发智能体的未来影响,助你实现编码效率300%提升。
WordPress 开发入门:代码详解与使用指南
本文详细介绍了WordPress开发入门知识,涵盖基础概念、环境搭建、主题与插件开发及常用技巧。首先讲解了WordPress的核心功能与开发环境配置,接着深入探讨主题开发,包括创建主题文件夹、核心文件(style.css和functions.php)以及模板文件的使用。随后介绍插件开发的基本步骤,如创建插件文件、添加功能并激活插件。最后推荐了开发资源,如官方文档、在线教程和优质市场。通过实践与学习,读者可掌握WordPress开发技术,构建个性化网站。

阿里云AI辅助编码探索与实践
2025 年 4 月 20 日宁波,通义灵码在首届中国计算机学会(CCF)算法大会现场亮相,与领域学者、企业专家、学生开发者共话大模型与 AI 辅助编程对算法创新和开发效率带来的改变。随着大模型技术的快速发展,AI 辅助编程和算法设计成为新的研究热点。专题分论坛上,通义灵码解决方案架构师解浩分享了阿里云在 AI 编程领域的探索,及基于通义灵码的企业研发智能化落地实践。
通义灵码:AI编程助手如何重塑开发者的效率革命?
通义灵码是阿里云推出的一款基于通义大模型的智能编程助手,支持Java、Python、Go等主流语言,并深度适配VSCode、JetBrains等开发环境。其核心功能包括自然语言转代码、跨文件上下文理解、行级/函数级实时补全、自动生成单元测试及性能优化建议等。此外,还提供知识问答引擎、文档智能生成和研发大数据分析等进阶功能,助力开发者提升效率。通过重构生产关系,将重复劳动转化为创造性工作,使技术债务可视化,推动人机协同编程新时代的到来。
通义灵码进阶指南:解锁智能编程的隐藏技能
通义灵码是阿里云推出的智能编程助手,已突破简单代码补全功能,成为全栈开发导航仪、架构思维催化剂、代码质量监督员和知识检索加速器。本文从基础到进阶,详细介绍了其高效操作技巧,包括精准生成、对话式编程、代码重构及技术文档交互等功能。同时提供团队级最佳实践、专家级配置指南及避坑建议,并展望未来实验性功能。通过将其视为“编程伙伴”,开发者可实现更高效的人机协作,优化工作流并提升生产力。
通义灵码:AI赋能编程,开启智能开发新时代
通义灵码是阿里云推出的一款专为开发者设计的智能编程助手,基于自主研发的大模型打造。它不仅具备代码生成、智能补全、代码优化和实时调试等功能,还通过垂直领域深度训练、多语言全栈支持以及与主流IDE无缝集成,大幅提升开发效率。真实案例显示,通义灵码可显著减少编码时间和错误率,助力开发者专注于业务逻辑。未来,它还将进一步理解业务需求、参与代码评审和跨团队协作,重新定义软件开发范式。立即体验,让AI赋能每一行代码!
通义灵码:以AI重塑开发者生产力,解锁智能编程新范式
通义灵码是阿里云推出的一款AI智能编程助手,基于通义大模型打造,深度集成于主流IDE。它不仅提供全场景智能代码生成、对话式开发体验和工程化智能重构等功能,还通过百亿级参数大模型底座、企业级环境适配、私有化部署等优势,重新定义人机协作边界。在真实开发场景中,通义灵码显著提升API开发与算法优化效率,助力开发者从机械劳动转向创造性对话,开启人机协同的新时代。
AI 时代,为什么编程能力≠ 开发门槛
在 2.0 阶段,我们目标是实现面向任务的协同编码模式,人的主要职责转变为任务的下发、干预以及最后结果的审查。在这个过程中,人的实际工作量开始减轻,AI 工作的占比显著提升。目前的 2.0 版本是我们最近上线的。
通义灵码:AI重构编码范式,开发者如何迎接“人机共生”时代?
本文探讨了以通义灵码为代表的AI编码助手如何推动软件开发从“人驱动工具”向“人机协同创造”演进。文章分析了其技术突破,如意图理解、上下文感知和可解释性,并讨论了开发者价值链条的重构,包括需求抽象、架构设计与代码审查能力的提升。同时,文章展望了行业变革对开发者身份、云生态竞争及技术伦理的影响,强调在AI驱动的“寒武纪大爆发”前夜,唯有持续进化才能适应未来软件工程的“人机共生”文明。
通义灵码 vs. GitHub Copilot:中国AI编码工具的破局之道
全球AI编码工具形成“双极格局”,GitHub Copilot凭借先发优势主导市场,而通义灵码通过差异化路径突围。技术层面,通义灵码在中文语境理解、云原生绑定上展现优势;生态方面,Copilot依托GitHub开源生态,通义灵码则深耕阿里云企业协同场景;开发者心智战中,通义灵码以数据合规、本土化服务及定制化能力取胜。这场较量不仅是技术的比拼,更是生态逻辑与开发者需求的全面博弈,彰显中国AI编码工具“换道超车”的潜力。
中国AI编码工具崛起:技术突围、生态重构与开发者新范式
中国AI编码工具如通义灵码、百度Comate等,正从西方产品的主导中突围。通过大模型精调、中文友好型理解及云原生赋能,构建差异化优势。这些工具不仅提升效率,还推动中国软件产业从使用者向标准制定者转变。然而,技术原创性、生态碎片化和开发者信任危机仍是挑战。未来目标不是取代现有工具,而是定义适合中国开发者的智能编码新范式。
通义灵码 Rules 库合集来了,覆盖Java、TypeScript、Python、Go、JavaScript 等
通义灵码新上的外挂 Project Rules 获得了开发者的一致好评:最小成本适配我的开发风格、相当把团队经验沉淀下来,是个很好功能……

harmonyOS基础- 快速弄懂HarmonyOS ArkTs基础组件、布局容器(前端视角篇)
本文由黑臂麒麟(6年前端经验)撰写,介绍ArkTS开发中的常用基础组件与布局组件。基础组件包括Text、Image、Button等,支持样式设置如字体颜色、大小和加粗等,并可通过Resource资源引用统一管理样式。布局组件涵盖Column、Row、List、Grid和Tabs等,支持灵活的主轴与交叉轴对齐方式、分割线设置及滚动事件监听。同时,Tabs组件可实现自定义样式与页签切换功能。内容结合代码示例,适合初学者快速上手ArkTS开发。参考华为开发者联盟官网基础课程。
AI引爆全美失业潮?通义灵码助你开发路上不孤单!
达沃斯调查显示,超4成老板计划2025-2030年因AI自动化削减员工。首当其冲的是软件工程行业,Anthropic CEO称AI可能在12个月内接管几乎所有代码编写工作。面对这一变革,程序员应如何应对?通义灵码作为基于通义大模型的AI研发辅助工具,提供代码生成、智能问答等功能,助力开发者适应AI原生研发新范式。现可直接参与项目,完成未实现功能!
通义灵码 Rules 来了:个性化代码生成,对抗模型幻觉
通义灵码又上新外挂啦,Project Rules来了。当模型生成代码不精准,试下通义灵码 Rules,对抗模型幻觉,硬控 AI 根据你的代码风格和偏好生成代码和回复。

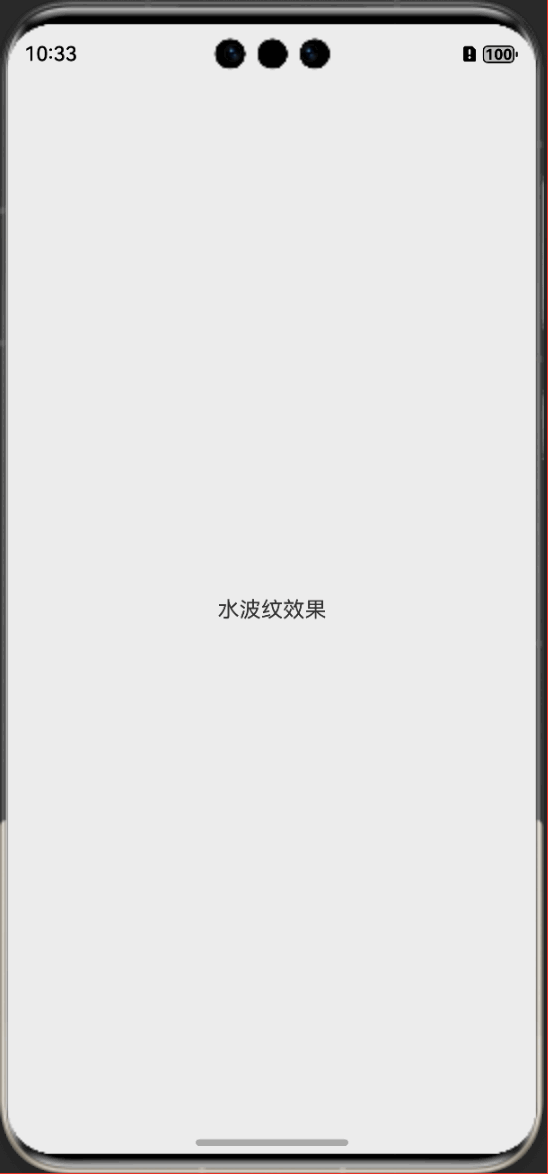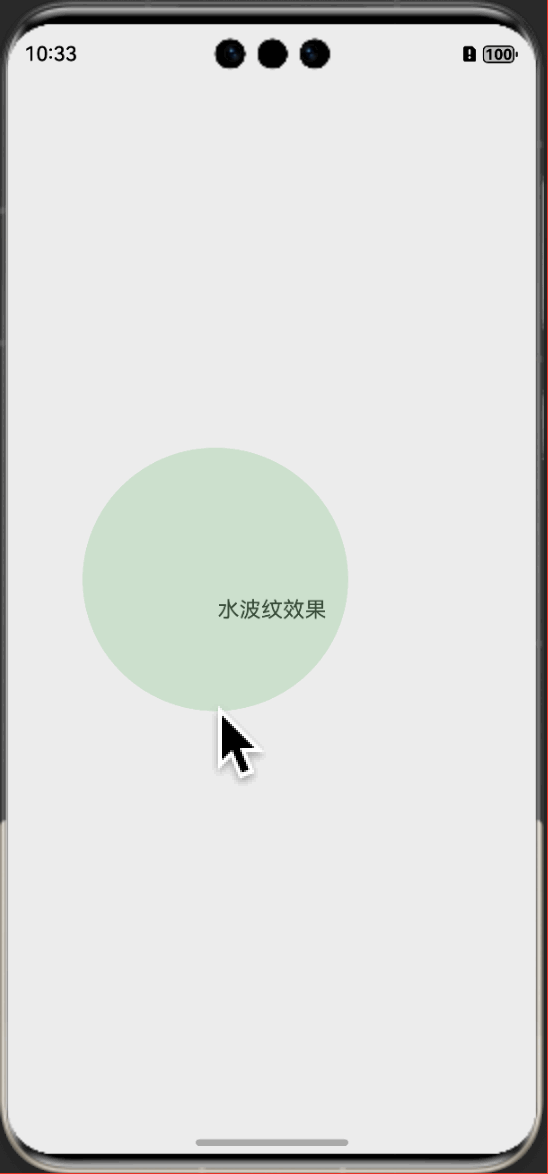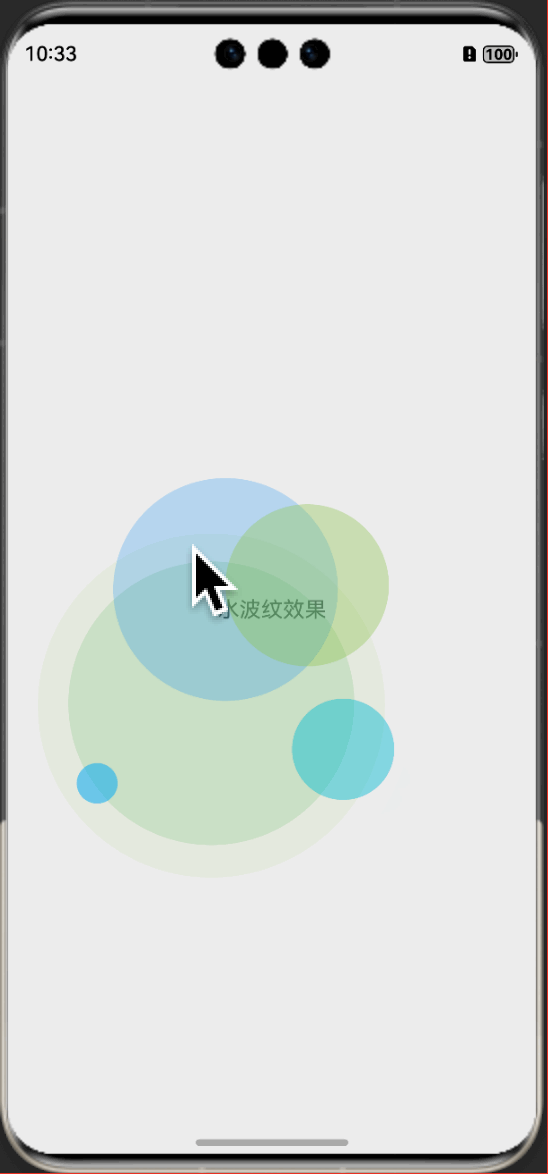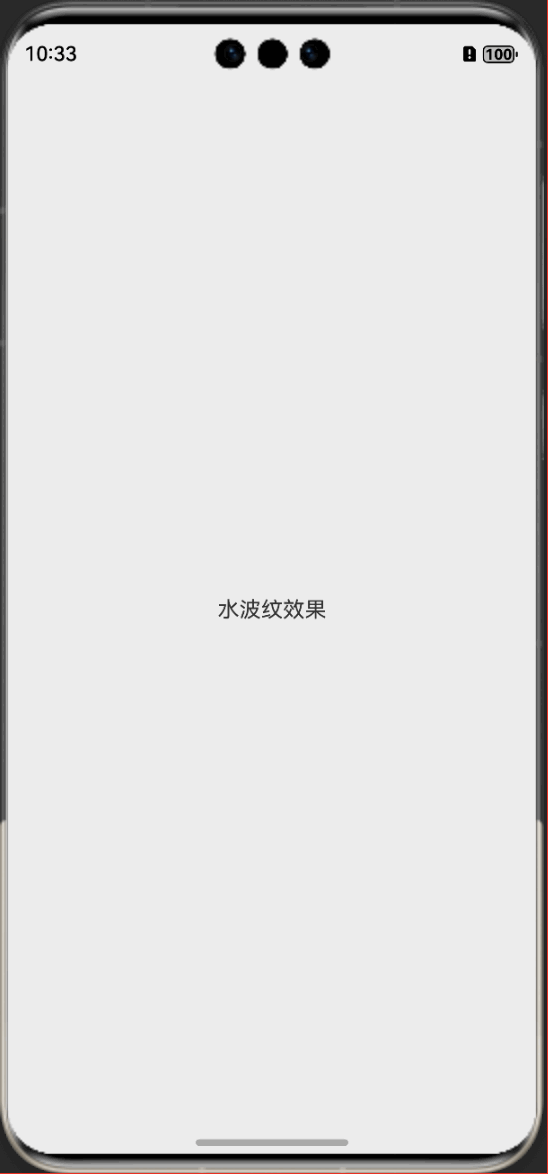

鸿蒙特效教程04-直播点赞动画效果实现教程
本教程适合HarmonyOS初学者,通过简单到复杂的步骤,通过HarmonyOS的Canvas组件,一步步实现时下流行的点赞动画效果。
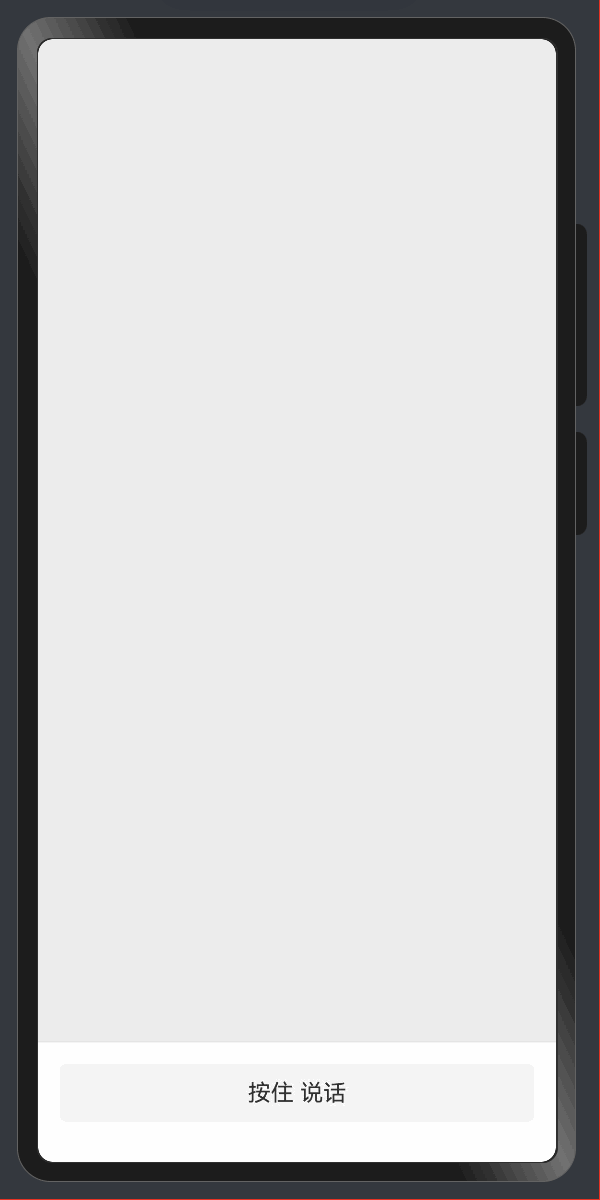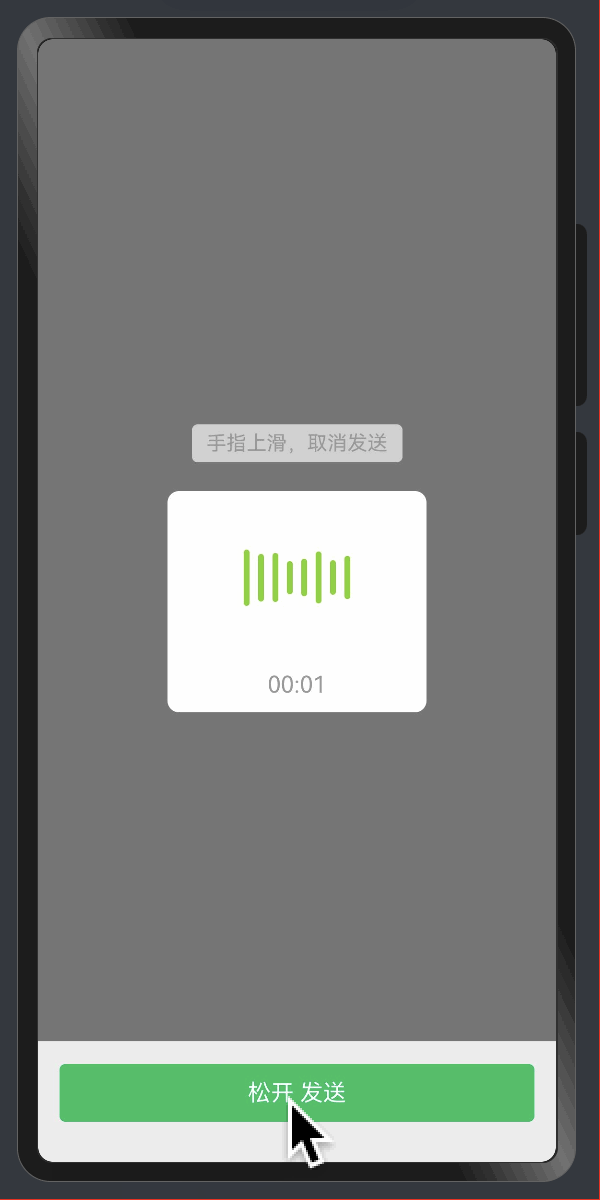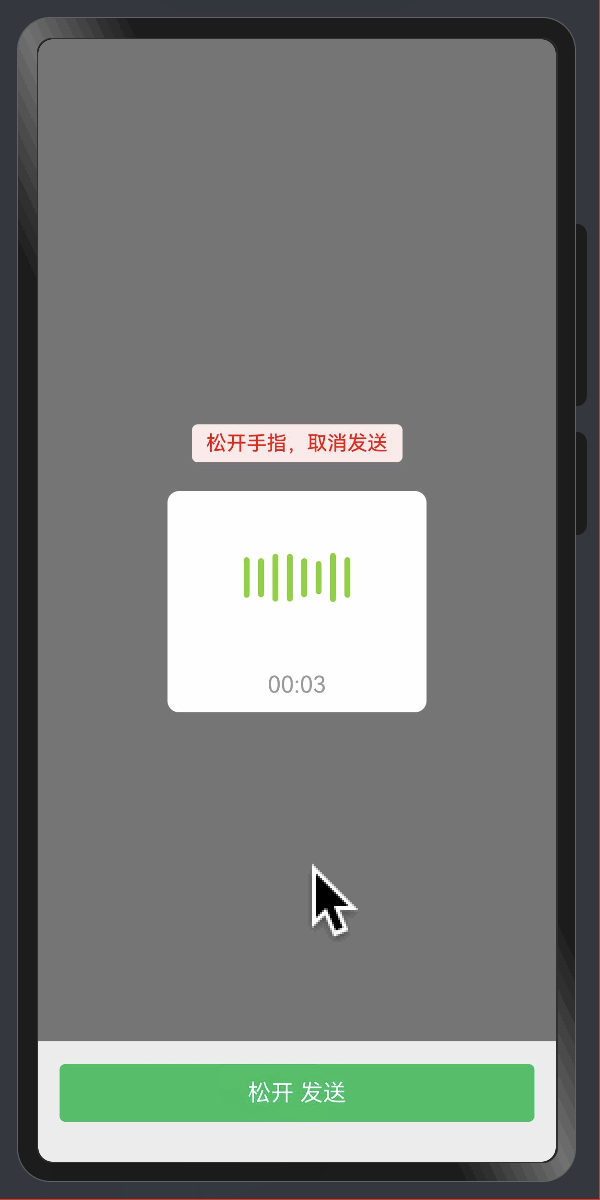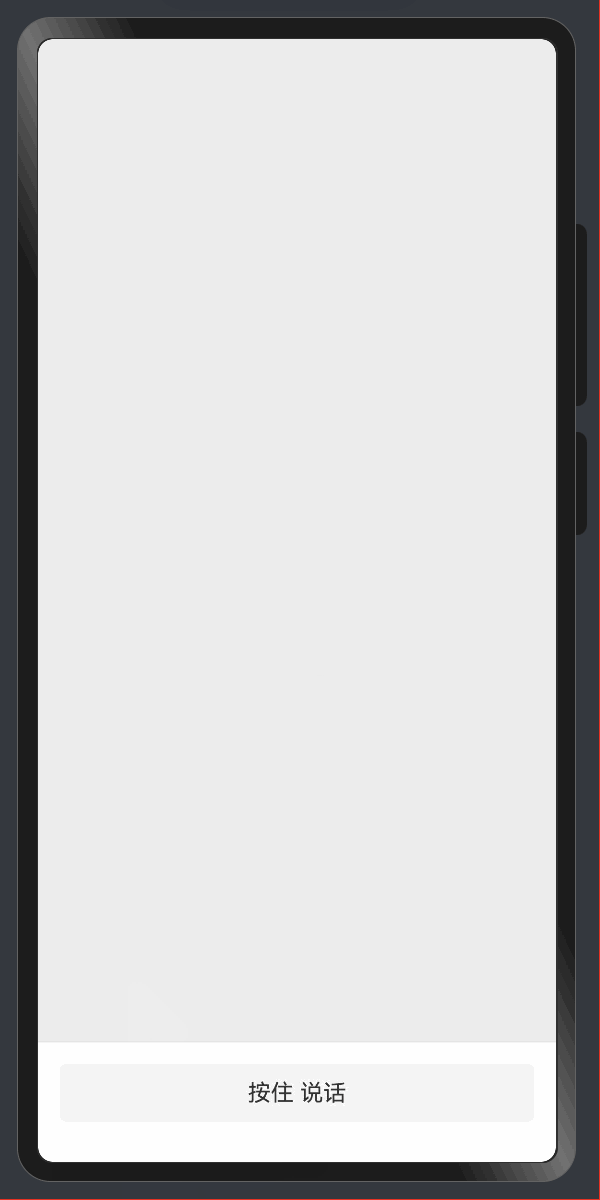

给Web开发者的HarmonyOS指南01-文本样式
本系列教程适合 HarmonyOS 初学者,为那些熟悉用 HTML 与 CSS 语法的 Web 前端开发者准备的。
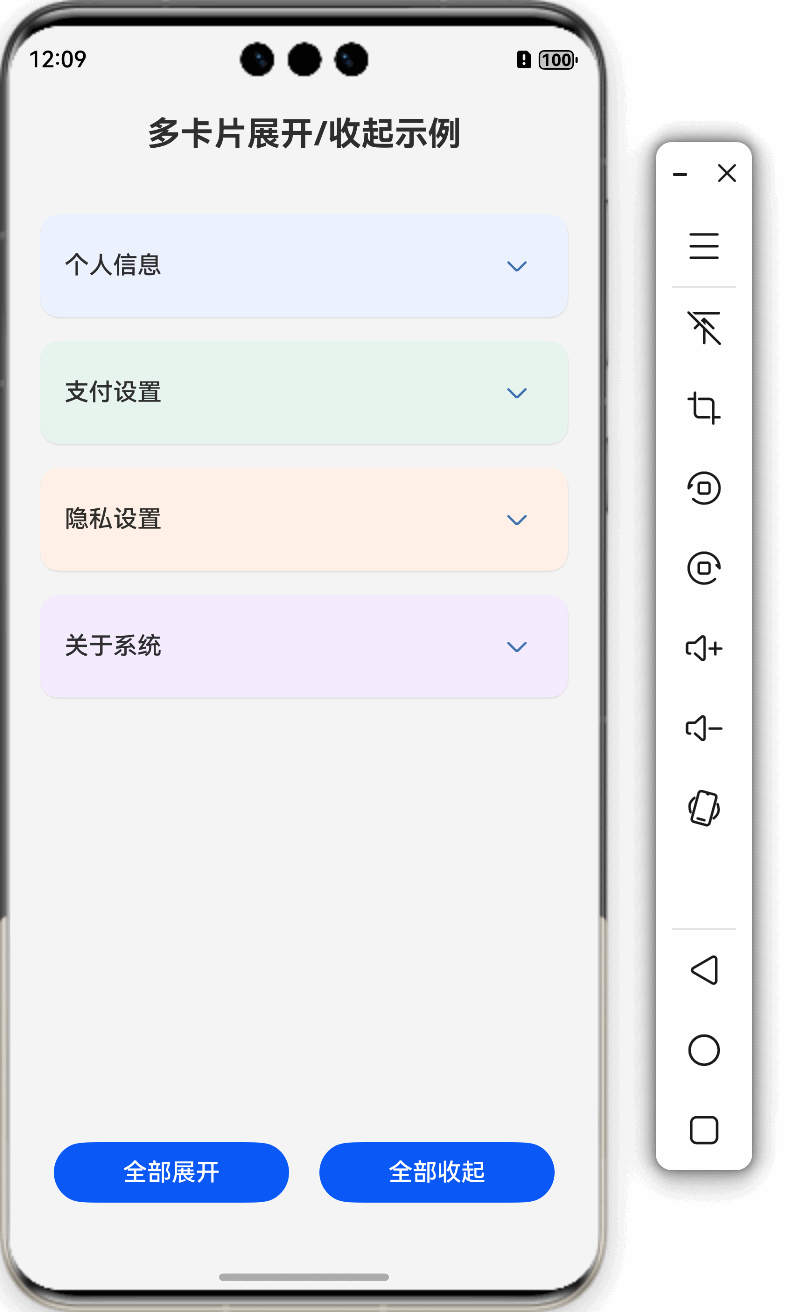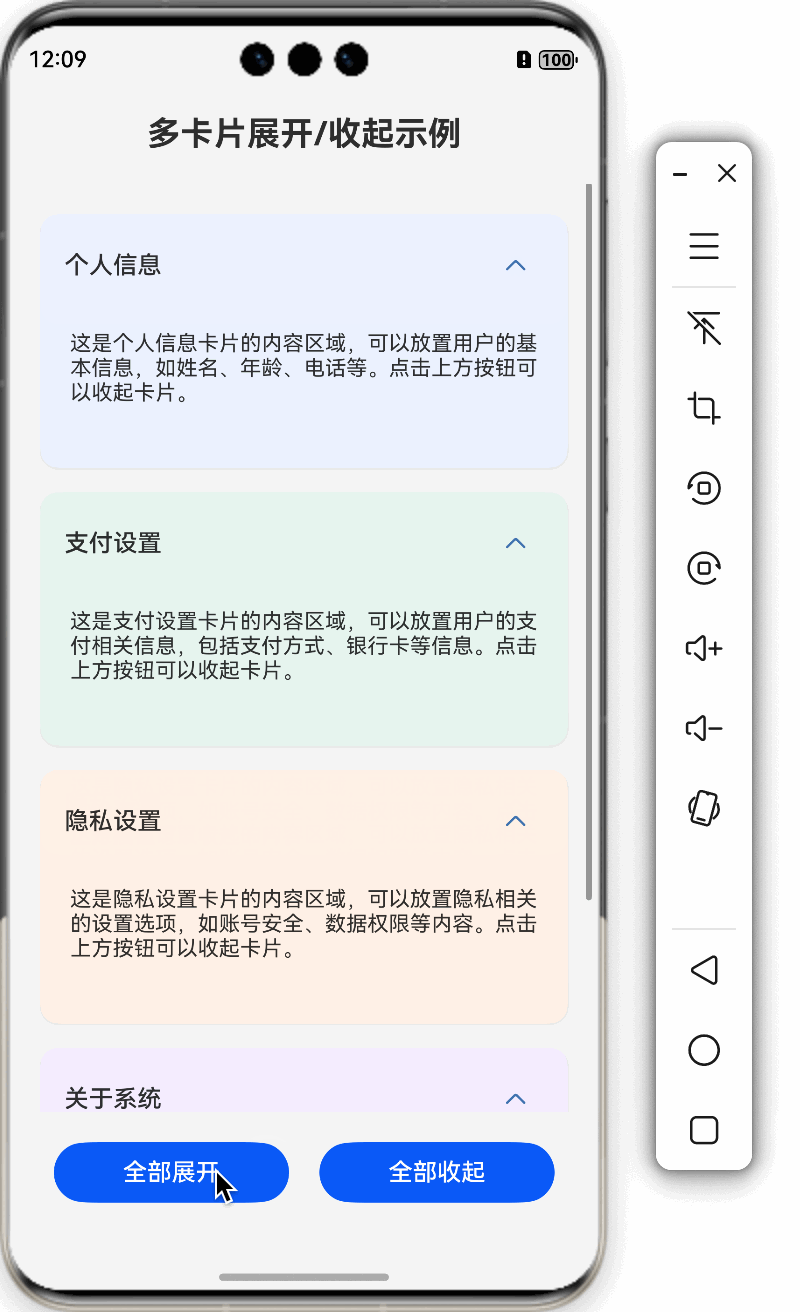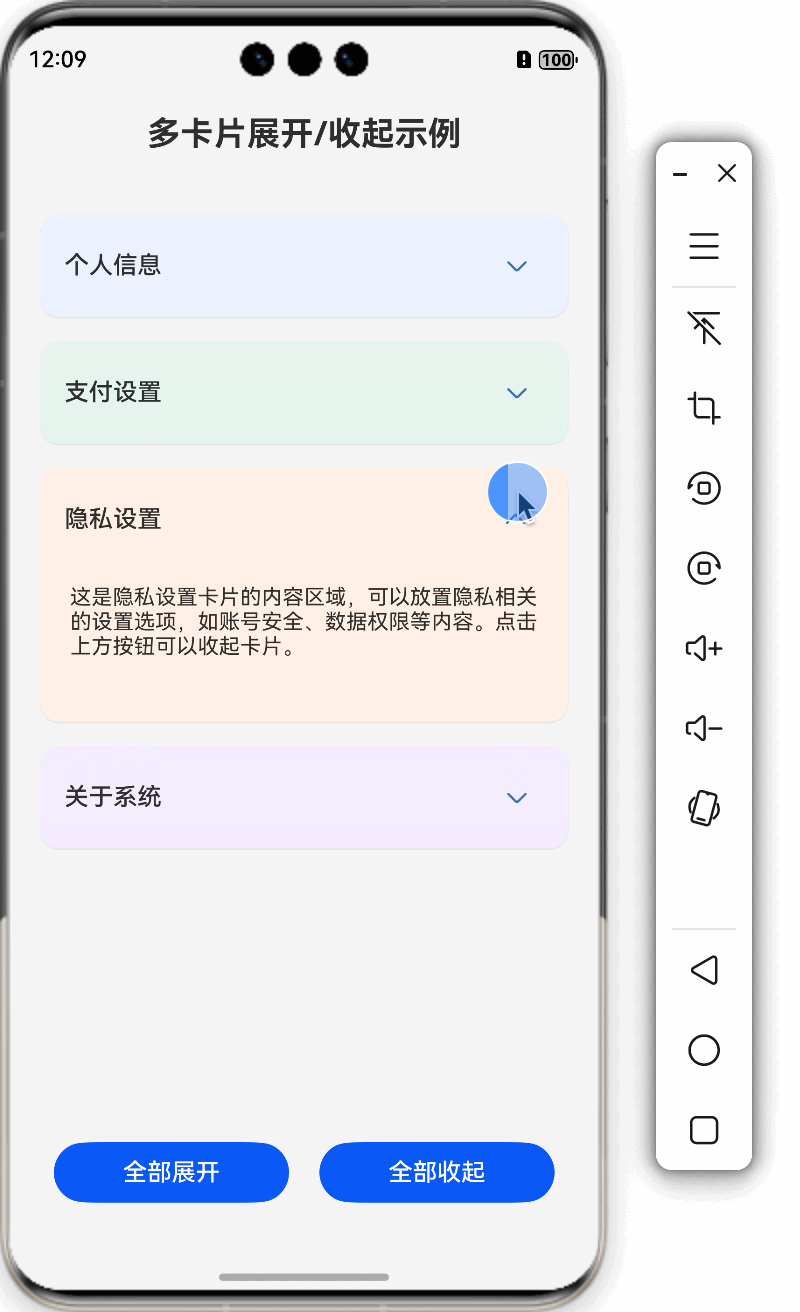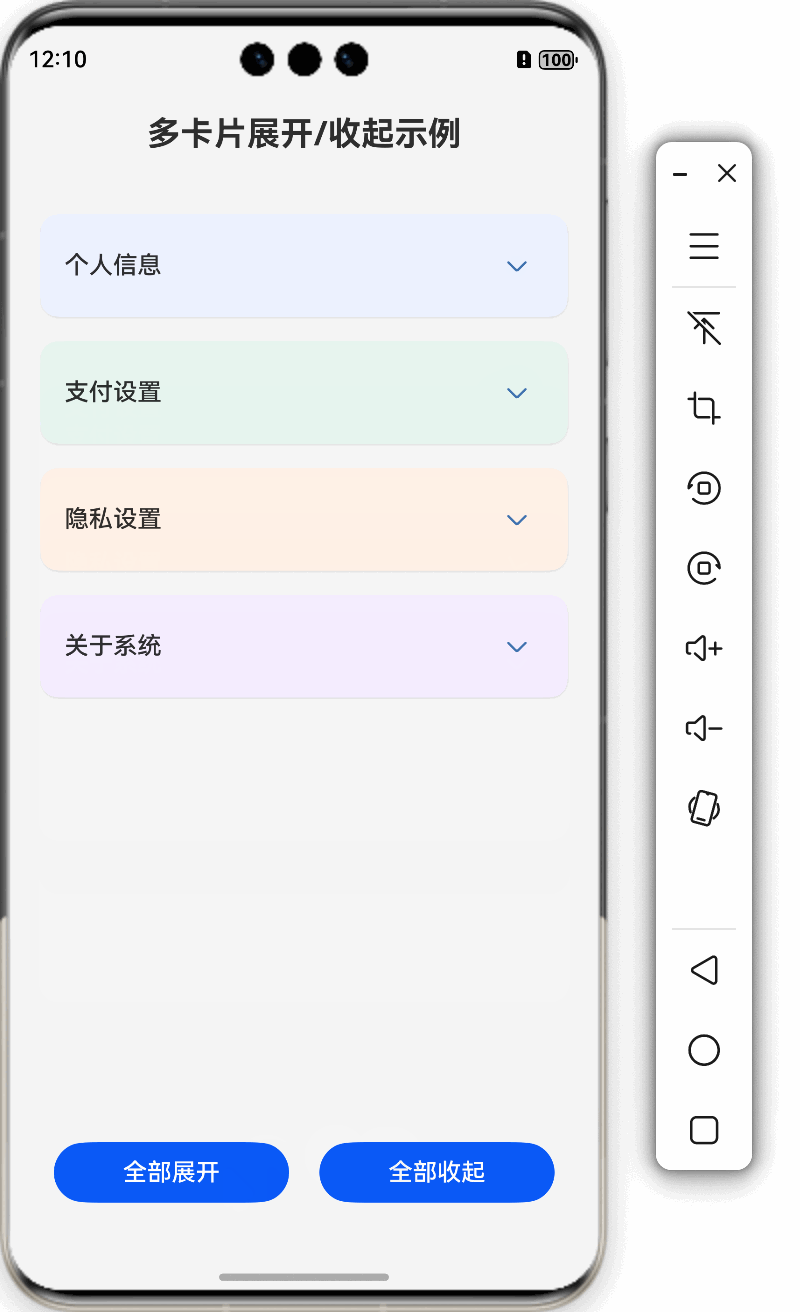
鸿蒙特效教程10-卡片展开/收起效果
本教程将详细讲解如何在HarmonyOS中实现卡片的展开/收起效果,通过这个实例,你将掌握ArkUI中状态管理和动画实现的核心技巧。

通义灵码
通义灵码是基于通义大模型的 AI 研发辅助工具,提供代码生成、研发问答、任务执行等能力,为开发者带来智能化研发体验,引领 AI 原生研发新范式。通义灵码兼容 Visual Studio Code、Visual Studio、JetBrains IDEs 等主流编程工具,并提供 Lingma IDE,开发者可以自由选择。 更多信息欢迎加入通义灵码用户交流群(钉钉群号53770000738)



