# 实时计算 Flink版 #
1
关注
33667内容


Flink on YARN(下):常见问题与排查思路
上篇分享了基于 FLIP-6 重构后的资源调度模型介绍 Flink on YARN 应用启动全流程,本文将根据社区大群反馈,解答客户端和 Flink Cluster 的常见问题,分享相关问题的排查思路。
|
2684亿!阿里CTO张建锋:不是任何一朵云都撑得住双11 | 11月12号栖夜读
今天的首篇文章,讲述了:“不是任何一朵云都能撑住这个流量。中国有两朵云,一朵是阿里云,一朵叫其他云。”11月11日晚,阿里巴巴集团CTO张建锋表示,“阿里云不一样,10年前我们从第一行代码写起,构建了中国唯一自研的云操作系统飞天。
重磅揭晓!Flink Forward Asia 2019 议程完整出炉
60 年前,人工智能的诞生刷新了人类对技术的期待;过去 10 年,大数据、云计算等核心技术的发展,推动了整个社会的重构与革新;5 年时间,移动互联网从诞生到逐步实现万物互联,数据在现实中的边界正在不断被拓展;技术迭变的进程不断加快,新兴技术的涌现昼夜不停。
直击 KubeCon 现场 | 阿里云 Hands-on Workshop 亮点回顾
相关文章链接【合集】规模化落地云原生,阿里云亮相 KubeCon China沉淀九年,一文看清阿里云原生大事件
2019 年 6 月 24 日至 26 日,KubeCon + CloudNativeCon + Open Source Summit(上海 )在中国上海盛装启幕。
|
LocalFlinkMiniCluster启动DataStream任务的流程
LocalFlinkMiniCluster 集群的actor 模型
---
- 相关的主要类图如下:
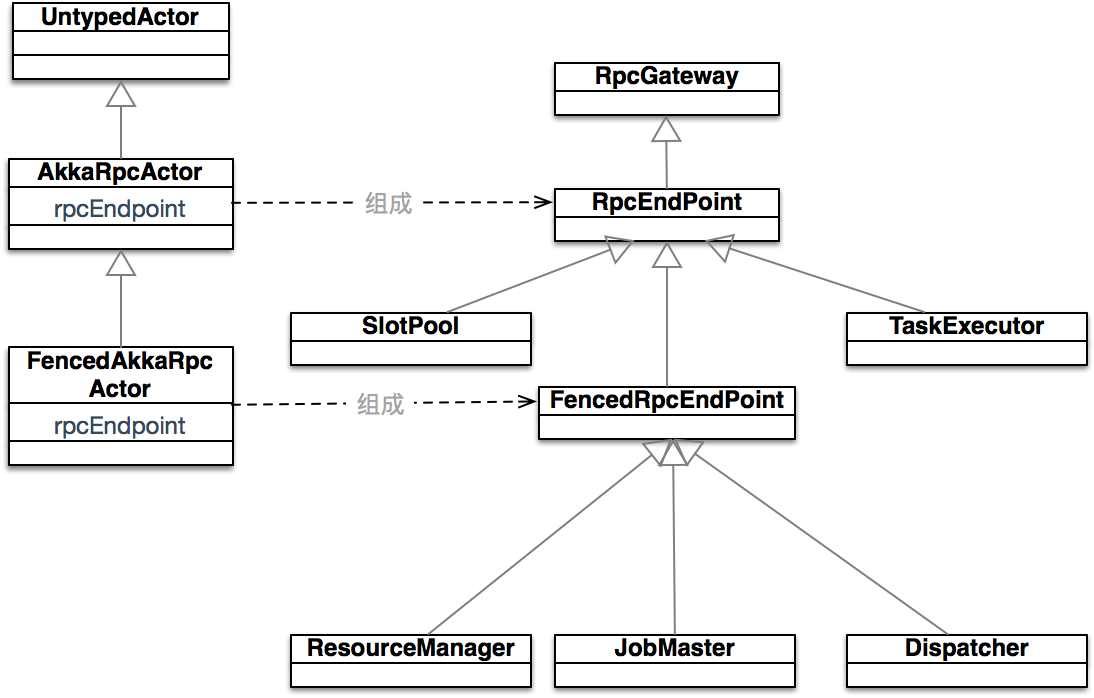
- AkkaRpcA
日志服务Flink Connector《支持Exactly Once》
Flink log connector是阿里云日志服务推出的,用于对接Flink的工具,包含两块,分别是消费者和生产者,消费者用于从日志服务中读数据,支持exactly once语义,生产者用于将数据写到日志服务中,该Connector隐藏了日志服务的一些概念,比如Shard的分裂合并等,用户在使用时只需要专注在自己的业务逻辑即可。
Flink on YARN(上):一张图轻松掌握基础架构与启动流程
本文基于FLIP-6重构后的资源调度模型介绍Flink on YARN应用启动全流程,解答客户端和Flink Cluster的常见问题,分享相关问题的排查思路。
Kubernetes集群中基于 CRD 实现分批发布
分批发布是一种通用的发布方式,但是在Kubernetes集群中,要实现分批发布,需要控制各种状态,维护service流量,以及各种label配置,十分麻烦。阿里云容器服务提供一种基于 CRD 的分批发布方式,大大方便发布流程。
|
结构化数据存储,如何设计才能满足需求?
阿里妹导读:任何应用系统都离不开对数据的处理,数据也是驱动业务创新以及向智能化发展最核心的东西。数据处理的技术已经是核心竞争力。在一个完备的技术架构中,通常也会由应用系统以及数据系统构成。应用系统负责处理业务逻辑,而数据系统负责处理数据。
阿里云与Apache Flink商业公司DataArtisans于2017杭州云栖大会达成战略合作并发布
10月12日,Apache Flink商业公司DataArtisans CEO、联合创始人Kostas Tzoumas在云栖大会上宣布和阿里集团达成战略合作伙伴关系,希望能够借助全球最大的云计算公司之一阿里云,服务更多的大数据实时流计算的客户。
免费试用