分享阿里云全球技术服务部(GTS)团队最佳实践、经典案例与故障排查。
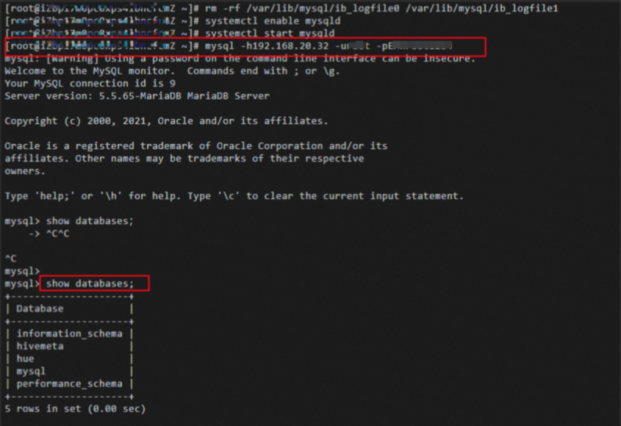
获取记录的BINLOG时间,如下读取变更时间的方式获取。
CREATE TABLE mysql_orders (
db_name STRING METADATA FROM 'database_name' VIRTUAL, -- 读取库名。
table_name STRING METADATA FROM 'table_name' VIRTUAL, -- 读取表名。
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, -- 读取变更时间。
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
)
详情参见MySQL的CDC源表
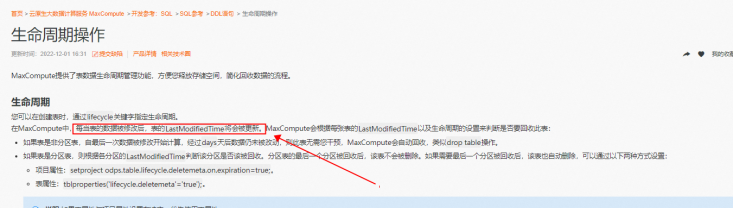
● 调度参数:调度参数是根据任务调度的业务时间及调度参数的取值格式自动替换为具体的值,实现在任务调度时间内参数的动态替换。详情参见配置并使用调度参数
● 流程参数:当整个业务流程需要对同一个变量统一赋值或替换其参数值时,可以使用流程参数功能。详情参见流程参数
注意:
流程参数的优先级高于节点参数中参数的优先级
流程参数仅支持ODPS SQL、EMR Hive、EMR MR、EMR Shell、EMR Spark、EMR Spark Shell、EMR Spark SQL、EMR Spark Streaming、EMR Streaming SQL、EMR Presto节点使用。
ElasticSearch可以进行自动备份与恢复。在Kibana控制台上,执行如下命令,从快照中恢复索引数据:
POST _snapshot/aliyun_auto_snapshot//_restore
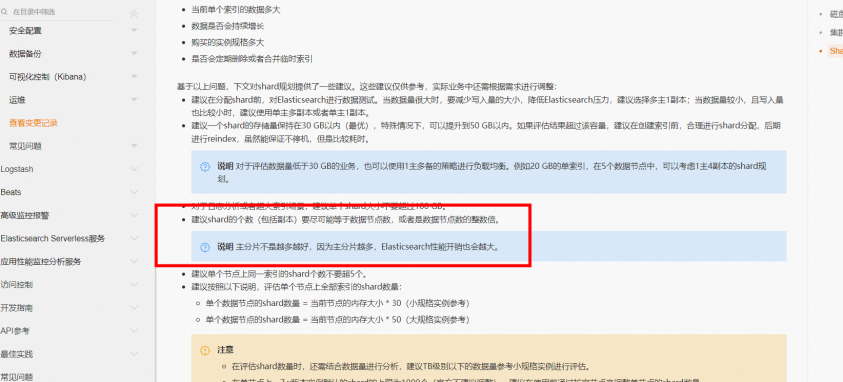
注意下列条件:
● 集群的第一个快照是集群数据的完整拷贝,后续所有的快照保留的是已存快照和新快照之间的增量,因此首次快照耗时较长(具体时长与数据量相关),后续快照备份会比较快。
● 快照仅保存索引数据,不保存Elasticsearch实例自身的监控数据(例如以.monitoring和.security_audit为前缀的索引)、元数据、Translog、实例配置数据、Elasticsearch的软件包、自带和自定义的插件、Elasticsearch的日志等。
● 自动备份只保留最近7天的快照数据。
● 自动备份数据只能用于恢复到原集群,如果需要跨集群恢复,请参见手动备份与恢复或设置跨集群OSS仓库恢复
凝聚阿里云多年服务经验,携手合作伙伴与业界专家,匠心打造云服务技术共享!