
实时计算 Flink
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

Flink CDC 3.6.0:支持 Flink 1.20/2.2, MySQL/PostgreSQL入湖入流支持Schema Evolution
Apache Flink CDC 3.6.0 正式发布!支持 Flink 1.20.x/2.2.x 与 JDK 11,增强端到端 Schema Evolution(MySQL/PostgreSQL 入湖入流),新增 Oracle Source 与 Hudi Sink 连接器,全面覆盖主流数据湖生态,并优化 Transform 框架、YAML 路由及多连接器能力。(239字)

Apache Flink Agents 0.2.1 发布公告
Apache Flink Agents 0.2.1发布!修复3个关键缺陷(含MCP连接与Jackson反序列化问题),优化事件日志JSON输出、减小wheel包体积,并增强CI可观测性。推荐所有用户升级。支持OpenAI、Anthropic等多模型集成,附Demo演示智能运维能力。(239字)

(二)走进阿里云实时计算Flink版-场景案例篇
阿里云实时计算Flink版产品负责人黄鹏程(马格)介绍:基于Apache Flink打造的企业级全托管实时计算平台,支持批流一体、湖仓融合、实时风控与AI推理等场景,助力满帮、车企等客户降本增效35%,SLA达99.9%。

(一)走进阿里云实时计算Flink版-产品能力篇
阿里云实时计算Flink版是企业级高性能实时大数据处理平台,由Flink创始团队打造。提供VVR+Flash双引擎,性能达开源Flink的3-4倍;支持动态扩缩容、SQL开发、CEP规则热更新、湖流一体(Fluss+Paimon)、大模型集成等能力,全面兼容开源生态。(239字)

Flink 实时计算 x SLS 存储下推:阿里云 OpenAPI 网关监控平台实践
本文由潘伟龙(阿里云可观测)、阮孝振(阿里云开放平台)撰写,介绍阿里云OpenAPI网关实时监控体系的构建实践。面对TB级日志、多维分析、秒级告警等挑战,采用Flink+SLS云原生方案,创新分层聚合+Source端谓词下推,实现60+地域、300+产品、200TB/日的高可用实时监控,故障发现从分钟级降至秒级。

基于Flink CDC的企业级日志实时入湖入流解决方案
本文由阿里云Flink CDC负责人徐榜江与高级产品经理李昊哲联合撰写,详解企业级日志实时入湖入流方案:基于YAML的零代码开发、Schema自动推导、脏数据处理、多表路由及湖流一体(Fluss+Paimon)架构,显著提升时效性与易用性。

Apache Flink Agents 0.2.0 发布公告
Apache Flink Agents 0.2.0发布!该预览版统一流处理与AI智能体,支持Java/Python双API、Exactly-Once一致性、多级记忆(感官/短期/长期)、持久化执行及跨语言资源调用,兼容Flink 1.20–2.2,助力构建高可靠、低延迟的事件驱动AI应用。
StarRocks + Paimon: 构建 Lakehouse Native 数据引擎
12月10日,Streaming Lakehouse Meetup Online EP.2重磅回归,聚焦StarRocks与Apache Paimon深度集成,探讨Lakehouse Native数据引擎的构建。活动涵盖架构统一、多源联邦分析、性能优化及可观测性提升,助力企业打造高效实时湖仓一体平台。

在 OpenAI 打造流处理平台:超大规模实时计算的实践与思考
本文介绍OpenAI构建流处理平台的实践与挑战。面对Kafka高可用、Python生态兼容、云环境限制等问题,团队基于PyFlink打造跨区域流处理架构,集成Kafka HA组、自研代理与控制平面,支撑实时Embedding生成、特征计算等场景,并推动开源协作与平台自动化演进。

Forrester发布流式数据平台报告:Flink 创始团队跻身领导者行列,实时AI能力获权威认可
Ververica,由Apache Flink创始团队创立、阿里云旗下企业,首次入选Forrester 2025流式数据平台领导者象限,凭借在实时AI与流处理领域的技术创新及全场景部署能力获高度认可,成为全球企业构建实时数据基础设施的核心选择。

Delta Join:为超大规模流处理实现计算与历史数据解耦
Delta Join(FLIP-486)是Flink流式Join的范式革新,通过将历史数据存储与计算解耦,实现按需查询外部存储(如Fluss、Paimon),避免状态无限增长。它解决了传统Join在高基数场景下的状态爆炸问题,显著降低资源消耗:状态减少50TB,成本降10倍,Checkpoint从小时级缩短至秒级,恢复速度提升87%。兼容标准SQL,自动优化转换,适用于海量数据实时关联场景,推动流处理迈向高效、稳定、可扩展的新阶段。
打造可编程可集成的实时计算平台:阿里云实时计算 Flink被集成能力深度解析
本文由阿里云Flink团队李昊哲主讲,系统介绍Flink四层开放架构:通过OpenAPI、Git集成、多语言SDK等能力,实现控制面、数据面、开发面与运维面的全面开放。助力企业构建可编程、可嵌入、可治理的实时计算平台,推动数据开发工程化升级。

流、表与“二元性”的幻象
本文探讨流与表的“二元性”本质,指出实现该特性需具备主键、变更日志语义和物化能力。强调Kafka与Iceberg因缺乏更新语义和主键支持,无法真正实现二元性,唯有统一系统如Flink、Paimon或Fluss才能无缝融合流与表。
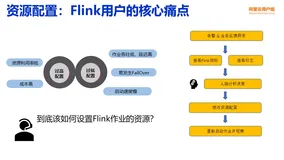
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。

云栖实录|驰骋在数据洪流上:Flink+Hologres驱动零跑科技实时计算的应用与实践
零跑科技基于Flink构建一体化实时计算平台,应对智能网联汽车海量数据挑战。从车机信号实时分析到故障诊断,实现分钟级向秒级跃迁,提升性能3-5倍,降低存储成本。通过Flink+Hologres+MaxCompute技术栈,打造高效、稳定、可扩展的实时数仓,支撑100万台量产车背后的数据驱动决策,并迈向流批一体与AI融合的未来架构。
Flink Agents 0.1.0 发布公告
Apache Flink Agents 0.1.0 首发预览版上线!作为 Flink 新子项目,它在流处理引擎上构建事件驱动的 AI 智能体,融合 LLM、工具、记忆与动态编排,支持高吞吐、低延迟、精确一次语义,实现数据与 AI 无缝集成,助力电商、金融等实时场景智能决策。

阿里云、Ververica、Confluent 与 LinkedIn 携手推进流式创新,共筑基于 Apache Flink Agents 的智能体 AI 未来
Apache Flink Agents 是由阿里云、Ververica、Confluent 与 LinkedIn 联合推出的开源子项目,旨在基于 Flink 构建可扩展、事件驱动的生产级 AI 智能体框架,实现数据与智能的实时融合。

Flink基于Paimon的实时湖仓解决方案的演进
本文源自Apache CommunityOverCode Asia 2025,阿里云专家苏轩楠分享Flink与Paimon构建实时湖仓的演进实践。深度解析Variant数据类型、Lookup Join优化等关键技术,提升半结构化数据处理效率与系统可扩展性,推动实时湖仓在生产环境的高效落地。

Flink Agents:基于Apache Flink的事件驱动AI智能体框架
本文基于Apache Flink PMC成员宋辛童在Community Over Code Asia 2025的演讲,深入解析Flink Agents项目的技术背景、架构设计与应用场景。该项目聚焦事件驱动型AI智能体,结合Flink的实时处理能力,推动AI在工业场景中的工程化落地,涵盖智能运维、直播分析等典型应用,展现其在AI发展第四层次——智能体AI中的重要意义。

淘宝闪购基于Flink&Paimon的Lakehouse生产实践:从实时数仓到湖仓一体化的演进之路
本文整理自淘宝闪购(饿了么)大数据架构师王沛斌在 Flink Forward Asia 2025 上海站的分享,深度解析其基于 Apache Flink 与 Paimon 的 Lakehouse 架构演进与落地实践,涵盖实时数仓发展、技术选型、平台建设及未来展望。

抖音基于Flink的DataOps能力实践
本文整理自抖音集团数据工程师黄鑫在Flink Forward Asia 2024的分享,围绕抖音实时数据研发的现状与挑战、DataOps能力建设及未来规划展开,涵盖需求管理、开发测试、发布运维等全流程实践,旨在提升数据质量与开发效率,实现高效稳定的数据交付。

Apache Flink错误处理实战手册:2年生产环境调试经验总结
本文由 Ververica 客户成功经理 Naci Simsek 撰写,基于其在多个行业 Flink 项目中的实战经验,总结了 Apache Flink 生产环境中常见的三大典型问题及其解决方案。内容涵盖 Kafka 连接器迁移导致的状态管理问题、任务槽负载不均问题以及 Kryo 序列化引发的性能陷阱,旨在帮助企业开发者避免常见误区,提升实时流处理系统的稳定性与性能。

「48小时极速反馈」阿里云实时计算Flink广招天下英雄
阿里云实时计算Flink团队,全球领先的流计算引擎缔造者,支撑双11万亿级数据处理,推动Apache Flink技术发展。现招募Flink执行引擎、存储引擎、数据通道、平台管控及产品经理人才,地点覆盖北京、杭州、上海。技术深度参与开源核心,打造企业级实时计算解决方案,助力全球企业实现毫秒洞察。

Lazada 如何用实时计算 Flink + Hologres 构建实时商品选品平台
本文整理自 Lazada Group EVP 及供应链技术负责人陈立群在 Flink Forward Asia 2025 新加坡实时分析专场的分享。作为东南亚领先的电商平台,Lazada 面临在六国管理数十亿商品 SKU 的挑战。为实现毫秒级数据驱动决策,Lazada 基于阿里云实时计算 Flink 和 Hologres 打造端到端实时商品选品平台,支撑日常运营与大促期间分钟级响应。本文深入解析该平台如何通过流式处理与实时分析技术重构电商数据架构,实现从“事后分析”到“事中调控”的跃迁。
[VLDB 2025]面向Flink集群巡检的交叉对比学习异常检测
阿里云与华东师范大学合作论文《Noise Matters: Cross Contrastive Learning for Flink Anomaly Detection》被VLDB 2025接收。该研究聚焦Flink集群热点机器异常检测,提出跨对比学习方法,结合先验知识优化模型训练,有效应对噪声数据干扰,提升检测准确率。该技术已应用于Flink集群智能巡检系统,助力运维风险预警。
Flink 2.1 SQL:解锁实时数据与AI集成,实现可扩展流处理
简介:本文整理自阿里云高级技术专家李麟在Flink Forward Asia 2025新加坡站的分享,介绍了Flink 2.1 SQL在实时数据处理与AI融合方面的关键进展,包括AI函数集成、Join优化及未来发展方向,助力构建高效实时AI管道。

从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。

Apache Flink:从实时数据分析到实时AI
Apache Flink 是实时数据处理领域的核心技术,历经十年发展,已从学术项目成长为实时计算的事实标准。它在现代数据架构中发挥着关键作用,支持实时数据分析、湖仓集成及实时 AI 应用。随着 Flink 2.0 的发布,其在流式湖仓、AI 驱动决策等方面展现出强大潜力,正推动企业迈向智能化、实时化的新阶段。
抖音集团基于Paimon的流式数据湖应用实践
本文整理自抖音集团数据工程师在Flink Forward Asia 2024的分享,围绕流式湖仓架构的背景、实践与未来展望展开。内容涵盖实时数仓架构演进、Paimon的应用与优化,以及在长周期指标计算和大流量场景下的落地实践经验。

Flink Forward Asia 2025 城市巡回 · 上海站
Flink Forward Asia 2025 城市巡回上海站重磅来袭!8月16日,顶尖技术专家齐聚,共探实时计算前沿趋势与行业实践。大会涵盖技术分享、实战案例与开源生态共建,支持线上直播预约。立即报名,共赴技术盛宴!

Fluss on 鲲鹏 openEuler 大数据实战
本文介绍了基于华为鲲鹏ARM架构服务器与openEuler操作系统,构建包含HDFS、ZooKeeper、Flink、Fluss及Paimon的实时大数据环境的完整实战过程。涵盖了软硬件配置、组件部署、集群规划、环境变量设置、安全认证及启停脚本编写等内容,适用于企业级实时数据平台搭建与运维场景。

热烈祝贺 Flink 2.0 存算分离入选 VLDB 2025
Apache Flink 2.0架构实现重大突破,论文《Disaggregated State Management in Apache Flink® 2.0》被VLDB 2025收录。该研究提出解耦式状态管理架构,通过异步执行框架与全新存储引擎ForSt,实现状态与计算分离,显著提升扩展性、容错能力与资源效率,推动Flink向云原生演进,开启流计算新时代。

FFA 2025 新加坡站全议程上线|The Future of AI is Real-Time
Flink Forward Asia 2025将于7月3日在新加坡举办,主题为“实时智能的未来”。大会聚焦实时AI、实时湖仓与实时分析,展示Apache Flink及社区项目如Paimon、Fluss的最新成果。来自阿里云、AWS、TikTok等企业专家将分享洞见,现场及直播观众均可参与互动抽奖,共襄技术盛宴。

官宣 | Fluss 0.7 发布公告:稳定性与架构升级
Fluss 0.7 版本正式发布!历经 3 个月开发,完成 250+ 次代码提交,聚焦稳定性、架构升级、性能优化与安全性。新增湖流一体弹性无状态服务、流式分区裁剪功能,大幅提升系统可靠性和查询效率。同时推出 Fluss Java Client 和 DataStream Connector,支持企业级安全认证与鉴权机制。未来将在 Apache 孵化器中继续迭代,探索多模态数据场景,欢迎开发者加入共建!






