人工智能平台PAI
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

PAI:一站式云原生AI平台
本文是《飞天大数据产品价值解读系列》之《一站式云原生AI平台》的视频分享精华总结,主要由阿里云机器学习PAI团队的产品经理高慧玲(花名:玲汐)向大家介绍了阿里巴巴整体的AI情况以及一站式云原生的AI平台PAI,并且做了简单的DEMO演示。

体验机器学习PAI-DSW动手实验室,赢取价值20000大礼包及定制T恤衫
动手体验数据科学,成为PAI-DSW探索者!快来体验机器学习PAI-DSW动手实验室,测一测你的相亲战斗力指数,还能赢取价值20000大礼包及定制T恤衫!



基于PAI 10分钟搭建一个简单推荐系统
阿里巴巴技术专家傲海为大家带来基于PAI10分钟搭建一个简单推荐系统的介绍。内容包括个性化推荐业务流程,协同过滤算法,推荐方案的架构,以及实际操作四个部分。


推荐系统排序算法及架构说明
阿里巴巴技术专家傲海为大家带来推荐系统排序算法及架构说明的介绍。内容包括排序模块在推荐系统中的位置,排序算法的介绍,离线排序模型的训练架构,以及在线排序模型的训练架构。

推荐系统召回算法及架构说明
阿里巴巴技术专家傲海为大家带来推荐系统召回算法及架构说明的介绍。内容包括召回模块在推荐系统中的位置,召回算法的介绍,什么是协同过滤,以及向量召回架构的说明。


阿里巴巴飞天大数据平台机器学习PAI最新特性
本次分享主要围绕以下五个方面: • PAI产品简介 • 自定义算法上传 • 数加智能生态市场 • AutoML2.0自动调参 • AutoLearning自动学习
机器学习PAI 2020-3 月刊
PAI 2020-3月 产品月刊为您带来3月机器学习PAI产品:数据集管理及标注工具发布、自动特征探索算法发布、EAS资源组临时扩容功能上线及印度region支持DSW、PAI-TF组件等最新资讯。

原来GNN这么好上手,OMG!用它!
Graph-Learn(GL) 是阿里巴巴开源的高性能工业级大规模图学习系统,本文将对GL的用户接口做一个概览,并介绍GL丰富的图采样算法,以及GL灵活统一的GNNs模型框架,帮助用户快速上手GL。 项目地址:https://github.com/alibaba/graph-learn 。

阿里巴巴开源GNN框架Graph-Learn
项目地址:https://github.com/alibaba/graph-learn 阿里巴巴近期开源了面向图神经网络(GNN)的框架Graph-Learn(GL,原AliGraph)。框架由阿里内部团队研发,研发同学分别来自计算平台事业部-PAI团队,新零售智能引擎事业群-智能计算实验室,以及安全部-数据与算法团队。

打击黑灰产的利器 —— 图神经网络(GNN)
阿里巴巴安全部数据与算法团队一直致力于与黑灰产进行对抗,保障用户在淘宝、天猫、闲鱼等平台上的使用体验和切身利益。面对狡猾的黑灰产,我们研究出了一系列算法武器,图神经网络(GNN)是其中重要的防控技术。本文结合阿里开源GNN框架Graph-Learn(https://github.com/alibaba/graph-learn)进行介绍。

揭秘工业级大规模GNN图采样
互联网下的图数据纷繁复杂且规模庞大,如何将GNN应用于如此复杂的数据上呢?答案是图采样。结合阿里巴巴开源的GNN框架Graph-Learn(https://github.com/alibaba/graph-learn),本文重点介绍GNN训练过程中的各种图采样和负采样技术。
原来GNN这么好上手,OMG!用它!
GraphLearn(GL)是阿里巴巴开源的一个大规模图神经网络平台,本文将对GL的接口做基本介绍,帮助用户快速上手。项目地址:https://github.com/alibaba/graph-learn 。
推荐召回场景-FM Embedding实现方案
智能推荐分为排序和召回两大模块,在召回模块中通常会采用将 用户User和待推荐的 内容Item 分别以向量表示,然后通过User和Item的向量乘积大小作为User对Item的感兴趣程度的判断。本案例介绍如何基于真实的推荐场景数据,通过使用PAI平台提供的FM算法和Embedding提取算法产生User和Item的描述向量。

基于关系的违规团伙发掘风控方案
目前很多平台方都有团伙作案的情况发生,比如团伙性薅羊毛,比如团伙性的制造一些虚假信息,团伙性发送违法广告。之所以是团伙性作案,因为作案人员之间有某种关系连接。当业务方获取了人员关系之后,能否成功挖掘出违规团伙,关系到平台的安全。
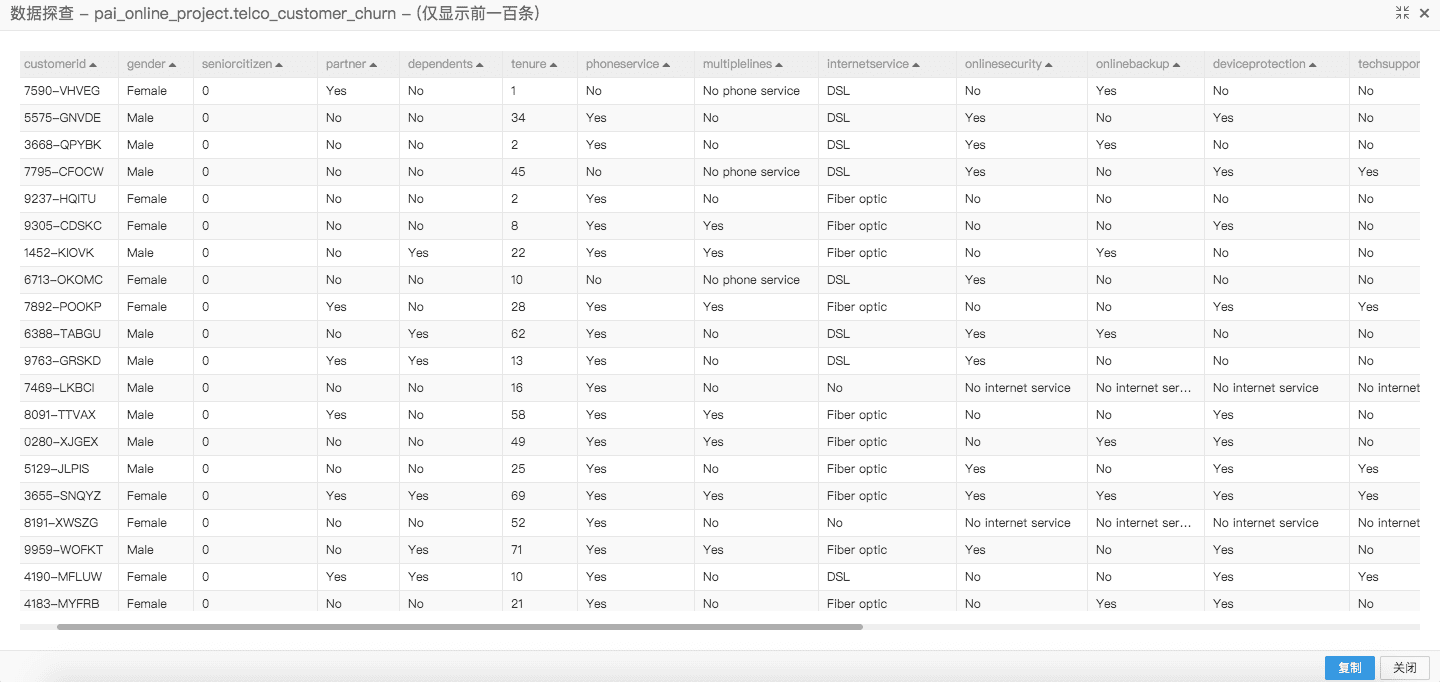
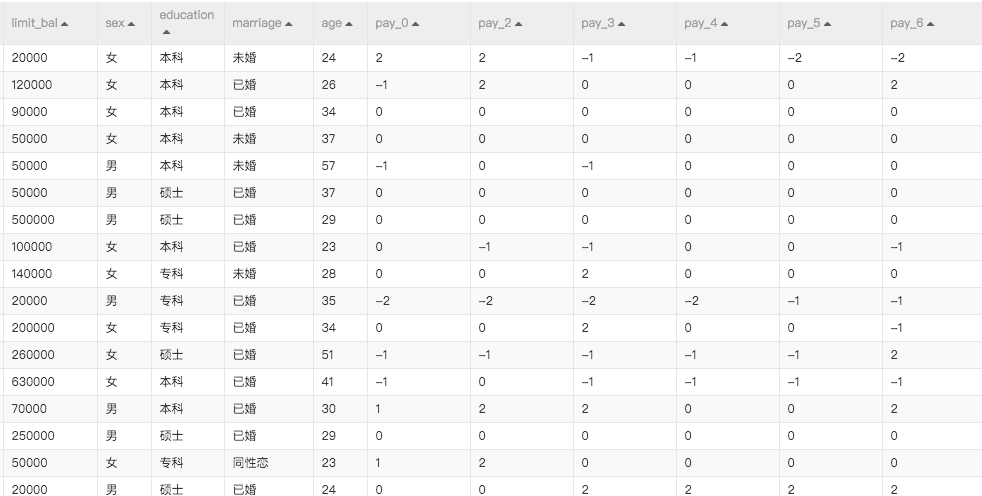
基于消费信用评估的风控
信用评估是被当前社会广泛关注的领域,特别是在金融行业,如果可以通过每个用户的历史交易数据以及用户画像数据确定用户的个人信用,将有助于银行设置个人借贷额度,确定潜在风险。本文将介绍在金融风控领域如何进行用户画像,使用什么样的算法可以计算出每个用户的信用指标。
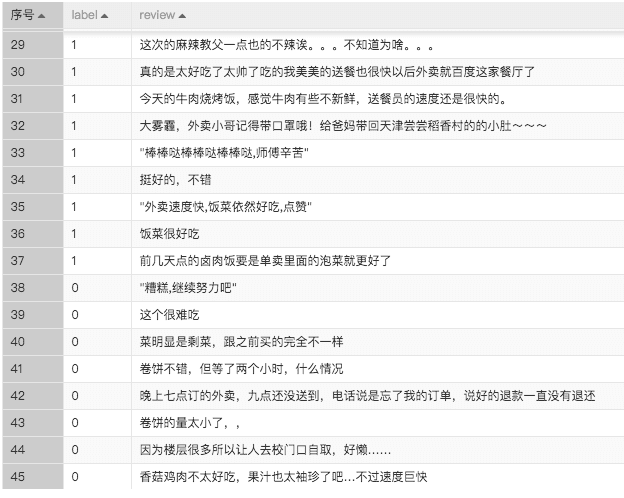
基于外卖评论的舆情风控
目前许多商家都有线上留言或者评论反馈平台,消费者可以在这些平台上通过留言表达自己对于消费商品的反馈。消费者的反馈包括表扬性的正向反馈,也有一些批评性质的负向反馈。商家需要掌握消费者对于产品的整体舆论取向来判断自己的产品质量是否符合消费者需求,同时了解评论内容可以方便商家分析舆论导向,指导下一步产品研发工作。

图神经网络(AliGraph)在阿里巴巴的发展与应用
在大数据的背景下,利用高速计算机去发现数据中的规律似乎是最有效的手段。为了让机器计算的有目的性,需要将人的知识作为输入。我们先后经历了专家系统、经典机器学习、深度学习三个阶段,输入的知识由具体到抽象,由具体规则到特征再到模式,越来越宏观。相对来说,抽象的层次变高了,覆盖面变广了,但我们对底层的感知变弱了,模型的可解释程度变差了。事物发展往往遵循这样的规律,先有客观事实,再有原理支撑,之后是普遍推广。深度学习的应用已经让我们看到了非常可观的价值,但其背后的可解释性工作进展缓慢,也因为如此,当我们用深度学习去解决一些风控、安全等业务场景,那数字效果不足以支撑这项技术的应用,我们更需要知道结果后面的
2684亿销售额背后的阿里AI技术
刚刚结束的双十一,天猫交易额达到 2684 亿元,较去年同比增长 25.7%。这一结果背后,云计算、人工智能等技术以及阿里巴巴工程师们的努力功不可没。在正在召开的 AICon 全球人工智能与机器学习技术大会 现场,阿里云智能计算平台事业部研究员林伟介绍了阿里基于飞天 AI 平台的人工智能技术及能力,揭开双 11 大规模交易场景下,阿里人工智能技术的神秘面纱。
天猫精灵业务如何使用机器学习PAI进行模型推理优化
作者:如切,悟双,楚哲,晓祥,旭林 引言 天猫精灵(TmallGenie)是阿里巴巴人工智能实验室(Alibaba A.I.Labs)于2017年7月5日发布的AI智能语音终端设备。天猫精灵目前是全球销量第三、中国销量第一的智能音箱品牌。
ALS算法实现用户音乐打分预测
很多人在决定是否看一部电影之前都会去豆瓣看下评分作为参考,看完电影也会给一个自己的分数。每个人对每个商品或者电影或是音乐都有一个心理的分数,这个分数标明用户是否对这个内容满意。作为内容的提供方,如果可以预测出每个用户对于内容的心理分数,就能更好的理解用户,并给用户提供好的内容推荐。
PAI-STUDIO通过Tensorflow处理MaxCompute表数据
PAI-STUDIO在支持OSS数据源的基础上,增加了对MaxCompute表的数据支持。用户可以直接使用PAI-STUDIO的Tensorflow组件读写MaxCompute数据,本教程将提供完整数据和代码供大家测试。
【教程】5分钟在PAI算法市场发布自定义算法
概述 在人工智能领域存在这样的现象,很多用户有人工智能的需求,但是没有相关的技术能力。另外有一些人工智能专家空有一身武艺,但是找不到需求方。这意味着在需求和技术之间需要一种连接作为纽带。 今天PAI正式对外发布了“AI市场”以及“PAI自定义算法”两大功能,可以帮助用户5分钟将线下的spark算法或是pyspark算法发布成算法组件,并且支持组件发布到AI市场供更多用户使用。
混合循环发电场输出电力预测
前言 机器学习很多时候在工业场景下也会有非常好的应用。本次实验,我们就会以一个综合循环发电厂的发电数据来展示机器学习是如何应用到工业生产的实际场景中的。 本实验数据采集自 UCI 机器学习数据集中的 混合发电厂数据。
5块钱低成本阿里云大数据生态协同过滤推荐系统实战
前情提要 人工智能千千万,没法落地都白干。自从上次老司机用神经网络训练了热狗识别模型以后,群众们表示想看一波更加接地气,最好是那种能10分钟上手,一辈子受用的模型。这次,我们就通过某著名电商公司的公开数据集,在阿里云大数据生态之下快速构建一个基于协同过滤的推荐系统! 推荐系统大家都不陌生,早就已经和大家的生活息息相关。
【数据科学老司机在线教学第二期】阿里云大数据生态协同过滤推荐系统实战
人工智能千千万,没法落地都白干。 自从上次老司机用神经网络训练了热狗识别模型以后,群众们表示想看一波更加接地气,最好是那种能10分钟上手,一辈子受用的模型。 这次,我们就通过某著名电商公司的公开数据集,在阿里云大数据生态之下快速构建一个基于协同过滤的推荐系统!
数据科学老司机在线开车系列: 如何自己训练一个热狗识别模型
前情提要 美剧《硅谷》大家想必都没怎么看过,大家可能都不知道人工智能识别热狗曾是硅谷最赚钱的技术之一。去年 HBO 发布了官方的 Not Hotdog 应用,支持 iOS 和 Android 平台,据说是用 TensorFlow、Keras 和 React Native 打造的,但是源码没有公开。
【直播】机器学习就用PAI,带你一起现场训练热狗识别模型!
看过美剧《硅谷》的同学都知道人工智能识别热狗曾是硅谷最赚钱的技术之一。去年 HBO 发布了官方的 Not Hotdog 应用,支持 iOS 和 Android 平台,据说是用 TensorFlow、Keras 和 React Native 打造的,但是源码没有公开。
脚把脚教你利用PAI训练出自己的CNN手写识别模型并部署为可用的服务
虽然已经 9102 年了,MNIST手写数据集也早已经被各路神仙玩出了各种花样,比如其中比较秀的有用MINST训练手写日语字体的。但是目前还是很少有整体的将训练完之后的结果部署为一个可使用的服务的。大多数还是停留在最终Print出一个Accuracy。
利用PAI-DSW访问Github, 快速获取最新的学习资源
PAI-DSW(Data science workshop)是专门为数据科学探索者们准备的云端深度学习开发环境,用户可以登录 DSW 进行代码的开发并运行工作。目前 DSW 支持了Github下载,让我们可以更加便捷的访问上面的资源.
PAI实现的深度学习网络可视化编辑功能-FastNeuralNetwork
在深度学习领域流传着这样一句话,“一张好的表示图,胜过一千个公式” 本文会介绍如何通过PAI-DSW中的FastNerualNetwork功能实现深度学习网络的可视化编辑。 神经网络最早诞生于生物领域,用来模仿生物大脑复杂的神经元构成,后来人类为了探索大脑是如何思考,通过一层一层的数学公式来模拟大脑分析事物的过程。
机器学习PAI全新功效——实时新闻热点Online Learning实践
(本实验会用到流式机器学习算法,正处于邀测状态,需要申请开通)PAI地址:https://data.aliyun.com/product/learn流式机器学习算法申请:https://data.aliyun.com/paionlinelearning打开新闻客户端,往往会收到热点新闻推送相关的内容。
农业贷款预测的回归算法实现_0
iip<br />数据源:撒地方<br />数据大小:6.62 KB<br />字段数量:10<br />使用组件:读数据表,线性回归(旧),SQL脚本,过滤与映射,合并列<br />






