
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
AppAgentX:告别重复点击!自我进化式GUI代理自动生成高级操作,效率翻倍
AppAgentX 是西湖大学推出的新型自我进化式 GUI 代理框架,通过记忆和进化机制提升智能手机交互的效率和智能性,支持复杂任务和跨应用操作,显著优于现有方法。
Kiss3DGen:基于图像扩散模型的3D资产生成框架
Kiss3DGen是一个创新的3D资产生成框架,通过重新利用预训练的2D图像扩散模型,高效生成、编辑和增强3D对象,支持文本到3D、图像到3D等多种生成任务。

PodAgent:港中文、微软、小红书联合推出的播客生成框架
PodAgent 是由香港中文大学、微软和小红书联合推出的播客生成框架,基于多智能体协作系统,自动生成高质量对话内容,支持声音角色匹配和语音合成,适用于媒体、教育、企业推广等多个场景。

SpatialVLA:上海AI Lab联合上科大推出的空间具身通用操作模型
SpatialVLA 是由上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,赋予机器人强大的3D空间理解能力,支持跨平台泛化控制。

Proxy Lite:仅3B参数的开源视觉模型!快速实现网页自动化,支持在消费级GPU上运行
Proxy Lite 是一款开源的轻量级视觉语言模型,支持自动化网页任务,能够像人类一样操作浏览器,完成网页交互、数据抓取、表单填写等重复性工作,显著降低自动化成本。

OmniAlign-V:20万高质量多模态数据集开源,让AI模型真正对齐人类偏好
OmniAlign-V 是由上海交通大学、上海AI Lab等机构联合推出的高质量多模态数据集,旨在提升多模态大语言模型与人类偏好的对齐能力。该数据集包含约20万个多模态训练样本,涵盖自然图像和信息图表,结合开放式问答对,支持知识问答、推理任务和创造性任务。

NotaGen:中央音乐学院联合清华推出AI音乐生成模型,古典乐谱一键生成,音乐性接近人类!
NotaGen 是由中央音乐学院、北京航空航天大学、清华大学等机构联合推出的音乐生成模型,基于模仿大型语言模型的训练范式,能够生成高质量的古典乐谱。该模型通过预训练、微调和强化学习相结合的方式,显著提升了符号音乐生成的艺术性和可控性。
Probly:开源 AI Excel表格工具,交互式生成数据分析结果与可视化图表
Probly 是一款结合电子表格功能与 Python 数据分析能力的 AI 工具,支持在浏览器中运行 Python 代码,提供交互式电子表格、数据可视化和智能分析建议,适合需要强大数据分析功能又希望操作简便的用户。

CogView4:智谱开源中文文生图新标杆,中文海报+任意分辨率一键生成
CogView4 是智谱推出的开源文生图模型,支持中英双语输入和任意分辨率图像生成,特别优化了中文文字生成能力,适合广告、创意设计等场景。

ViDoRAG:开源多模态文档检索框架,多智能体推理+图文理解精准解析文档
ViDoRAG 是阿里巴巴通义实验室联合中国科学技术大学和上海交通大学推出的视觉文档检索增强生成框架,基于多智能体协作和动态迭代推理,显著提升复杂视觉文档的检索和生成效率。

SongGen:三秒克隆音色!开源AI一键生成专业级歌曲,创作人必备神器
SongGen是由上海AI Lab、北京航空航天大学和香港中文大学联合推出的单阶段自回归Transformer模型,能够通过文本生成高质量歌曲,支持混合模式和双轨模式,显著提升生成歌曲的自然度和人声清晰度。

AIMv2:苹果开源多模态视觉模型,自回归预训练革新图像理解
AIMv2 是苹果公司开源的多模态自回归预训练视觉模型,通过图像和文本的深度融合提升视觉模型的性能,适用于多种视觉和多模态任务。
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平台,安装简便,适合开发者快速上手。

R1-Onevision:开源多模态推理之王!复杂视觉难题一键解析,超越GPT-4V
R1-Onevision 是一款开源的多模态视觉推理模型,基于 Qwen2.5-VL 微调,专注于复杂视觉推理任务。它通过整合视觉和文本数据,能够在数学、科学、深度图像理解和逻辑推理等领域表现出色,并在多项基准测试中超越了 Qwen2.5-VL-7B 和 GPT-4V 等模型。

video-subtitle-master:开源字幕生成神器!批量生成+AI翻译全自动,5分钟解放双手
video-subtitle-master 是一款开源AI字幕生成工具,支持批量为视频或音频生成字幕,并可将字幕翻译成多种语言。它集成了多种翻译服务和语音识别技术,适合视频创作者、教育领域和个人娱乐使用。
Flame:开源AI设计图转代码模型!生成React组件,精准还原UI+动态交互效果
Flame 是一款开源的多模态 AI 模型,能够将 UI 设计图转换为高质量的现代前端代码,支持 React 等主流框架,具备动态交互、组件化开发等功能,显著提升前端开发效率。

阿里开源AI视频生成大模型 Wan2.1:14B性能超越Sora、Luma等模型,一键生成复杂运动视频
Wan2.1是阿里云开源的一款AI视频生成大模型,支持文生视频和图生视频任务,具备强大的视觉生成能力,性能超越Sora、Luma等国内外模型。

PhotoDoodle:设计师必备!AI一键生成装饰元素,30+样本复刻风格+无缝融合的开源艺术编辑框架
PhotoDoodle 是由字节跳动、新加坡国立大学等联合推出的艺术化图像编辑框架,能够通过少量样本学习艺术家的独特风格,实现照片涂鸦和装饰性元素生成。
结合DeepSeek-R1强化学习方法的视觉模型!VLM-R1:输入描述就能精确定位图像目标
VLM-R1 是基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像目标,支持复杂场景推理与高效训练。
MME-CoT:多模态模型推理能力终极评测!六大领域细粒度评估,港中大等机构联合推出
MME-CoT 是由港中文等机构推出的用于评估大型多模态模型链式思维推理能力的基准测试框架,涵盖数学、科学、OCR、逻辑、时空和一般场景等六个领域,提供细粒度的推理质量、鲁棒性和效率评估。
MeteoRA:多任务AI框架革新!动态切换+MoE架构,推理效率提升200%
MeteoRA 是南京大学推出的多任务嵌入框架,基于 LoRA 和 MoE 架构,支持动态任务切换与高效推理。
LazyLLM:还在为AI应用开发掉头发?商汤开源智能体低代码开发工具,三行代码部署聊天机器人
LazyLLM 是一个低代码开发平台,可帮助开发者快速构建多智能体大语言模型应用,支持一键部署、跨平台操作和多种复杂功能。
MoneyPrinterTurbo:23.9K Star!这个AI把写文案+找素材+剪视频全包了,日更10条不是梦
MoneyPrinterTurbo 是一款功能强大的 AI 工具,支持通过主题或关键词自动生成视频文案、素材、字幕与背景音乐,并合成高清短视频,适合批量生成与多语言支持。
AgentSociety:告别纸上谈兵!AI社会模拟器预判政策漏洞:输入新规秒看30年后社会形态
AgentSociety 是清华大学推出的基于大语言模型的社会模拟器,通过构建类人心智的智能体模拟复杂社会行为,适用于政策沙盒测试、危机预警等场景。

HealthGPT:你的AI医疗助手上线了:支持X光到病理切片,诊断建议+报告生成全自动
HealthGPT 是浙江大学联合阿里巴巴等机构开发的先进医学视觉语言模型,具备医学图像分析、诊断辅助和个性化治疗方案建议等功能。
Aider:27.6K Star!这个终端AI编程神器能用语音改代码,自动生成Git记录并提交,接入DeepSeek斩获编程基准最高分
Aider 是一款基于命令行的开源 AI 编程助手,支持多种编程语言和主流 LLM,可自动完成代码修改、Git 提交及语音交互。

ToddlerBot:告别百万经费!6000刀就能造人形机器人,斯坦福开源全套方案普及机器人研究
ToddlerBot 是斯坦福大学推出的低成本开源人形机器人平台,支持强化学习、模仿学习和零样本模拟到现实转移,适用于运动操作研究和多场景应用。
Magma:微软放大招!新型多模态AI能看懂视频+浏览网页+UI交互+控制机器人,数字世界到物理现实无缝衔接
Magma 是微软研究院开发的多模态AI基础模型,结合语言、空间和时间智能,能够处理图像、视频和文本等多模态输入,适用于UI导航、机器人操作和复杂任务规划。

CLaMP 3:音乐搜索AI革命!多模态AI能听懂乐谱/MIDI/音频,用27国语言搜索全球音乐
CLaMP 3是由清华大学团队开发的多模态、多语言音乐信息检索框架,支持27种语言,能够进行跨模态音乐检索、零样本分类和音乐推荐等任务。

Omnitool:开发者桌面革命!开源神器一键整合ChatGPT+Stable Diffusion等主流AI平台,本地运行不联网
Omnitool 是一款开源的 AI 桌面环境,支持本地运行,提供统一交互界面,快速接入 OpenAI、Stable Diffusion、Hugging Face 等主流 AI 平台,具备高度扩展性。

VideoCaptioner:北大推出视频字幕处理神器,AI自动生成+断句+翻译,1小时工作量5分钟搞定
VideoCaptioner 是一款基于大语言模型的智能视频字幕处理工具,支持语音识别、字幕断句、优化、翻译全流程处理,并提供多种字幕样式和格式导出。

PDF to Podcast:英伟达开源黑科技!PDF 秒转播客/有声书,告别阅读疲劳轻松学习!
NVIDIA推出的PDF to Podcast工具,基于大型语言模型和文本到语音技术,将PDF文档转换为生动的音频内容。

Data Formulator:微软开源的数据可视化 AI 工具,通过自然语言交互快速创建复杂的数据图表
Data Formulator 是微软研究院推出的开源 AI 数据可视化工具,结合图形化界面和自然语言输入,帮助用户快速创建复杂的可视化图表。
Airweave:快速集成应用数据打造AI知识库的开源平台,支持多源整合和自动同步数据
Airweave 是一个开源工具,能够将应用程序的数据同步到图数据库和向量数据库中,实现智能代理检索。它支持无代码集成、多租户支持和自动同步等功能。

MedRAX:专注于胸部X光检查的AI医学推理智能体,帮助医生快速解读胸部X光片
MedRAX 是一款专门用于胸部X光检查的医学推理AI智能体,整合了多种最先进的分析工具,支持多模态推理和动态任务分解。

Agno:18.7K Star!快速构建多模态智能体的轻量级框架,运行速度比LangGraph快5000倍!
Agno 是一个用于构建多模态智能体的轻量级框架,支持文本、图像、音频和视频等多种数据模态,能够快速创建智能体并实现高效协作。
Ola:清华联合腾讯等推出的全模态语言模型!实现对文本、图像、视频和音频的全面理解
Ola 是由清华大学、腾讯 Hunyuan 研究团队和新加坡国立大学 S-Lab 合作开发的全模态语言模型,支持文本、图像、视频和音频输入,并具备实时流式解码功能。
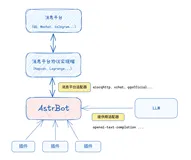
AstrBot:轻松将大模型接入QQ、微信等消息平台,打造多功能AI聊天机器人的开发框架,附详细教程
AstrBot 是一个开源的多平台聊天机器人及开发框架,支持多种大语言模型和消息平台,具备多轮对话、语音转文字等功能。
AnythingLLM:34K Star!一键上传文件轻松打造个人知识库,构建只属于你的AI助手,附详细部署教程
AnythingLLM 是一个全栈应用程序,能够将文档、资源转换为上下文,支持多种大语言模型和向量数据库,提供智能聊天功能。
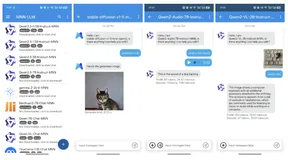
MNN-LLM App:在手机上离线运行大模型,阿里巴巴开源基于 MNN-LLM 框架开发的手机 AI 助手应用
MNN-LLM App 是阿里巴巴基于 MNN-LLM 框架开发的 Android 应用,支持多模态交互、多种主流模型选择、离线运行及性能优化。

OCRmyPDF:16.5K Star!快速将 PDF 文件转换为可搜索、可复制的文档的命令行工具
OCRmyPDF 是一款开源命令行工具,专为将扫描的 PDF 文件转换为可搜索、可复制的文档。支持多语言、图像优化和多核处理。

Oumi:开源的AI模型一站式开发平台,涵盖训练、评估和部署模型的综合性平台
Oumi 是一个完全开源的 AI 平台,支持从 1000 万到 4050 亿参数的模型训练,涵盖文本和多模态模型,提供零样板代码开发体验。
VARGPT:将视觉理解与生成统一在一个模型中,北大推出支持混合模态输入与输出的多模态统一模型
VARGPT是北京大学推出的多模态大语言模型,专注于视觉理解和生成任务,支持混合模态输入和高质量图像生成。

YuE:开源AI音乐生成模型,能够将歌词转化为完整的歌曲,支持多种语言和多种音乐风格
YuE 是香港科技大学和 M-A-P 联合开发的开源 AI 音乐生成模型,能够将歌词转化为完整的歌曲,支持多种音乐风格和多语言。

Janus-Pro:DeepSeek 开源的多模态模型,支持图像理解和生成
Janus-Pro是DeepSeek推出的一款开源多模态AI模型,支持图像理解和生成,提供1B和7B两种规模,适配多元应用场景。通过改进的训练策略、扩展的数据集和更大规模的模型,显著提升了文本到图像的生成能力和指令跟随性能。

Baichuan-Omni-1.5:百川智能开源全模态理解与生成模型,支持文本、图像、音频和视频的多模态输入和输出
Baichuan-Omni-1.5 是百川智能开源的全模态理解模型,支持文本、图像、音频和视频的多模态输入和输出,显著提升多模态交互体验。

FilmAgent:多智能体共同协作制作电影,哈工大联合清华推出 AI 驱动的自动化电影制作工具
FilmAgent 是由哈工大与清华联合推出的AI电影自动化制作工具,通过多智能体协作实现从剧本生成到虚拟拍摄的全流程自动化。






