

ParGo:字节与中山大学联合推出的多模态大模型连接器,高效对齐视觉与语言模态
ParGo 是字节与中山大学联合推出的多模态大模型连接器,通过全局与局部视角联合,提升视觉与语言模态的对齐效果,支持高效连接、细节感知与自监督学习。

EDTalk:只需上传图片、音频和视频,就能使图片中的人物说话,情感表情与音频情绪高度统一
EDTalk 是上海交通大学与网易联合研发的高效解耦情感说话头像合成模型,能够独立控制嘴型、头部姿态和情感表情,适用于多种应用场景。

CogAgent-9B:智谱 AI 开源 GLM-PC 的基座模型,专注于预测和执行 GUI 操作,可应用于自动化交互任务
CogAgent-9B 是智谱AI基于 GLM-4V-9B 训练的专用Agent任务模型,支持高分辨率图像处理和双语交互,能够预测并执行GUI操作,广泛应用于自动化任务。

快速切换多种画风!FlexIP:腾讯开源双适配器图像生成框架,精准平衡身份保持与个性化编辑
本文解析腾讯最新开源的FlexIP图像框架,其通过双适配器架构与动态门控机制实现身份保持与个性化编辑的精准平衡,在CLIP-I指标上取得0.873的高分验证了技术突破。
VARGPT:将视觉理解与生成统一在一个模型中,北大推出支持混合模态输入与输出的多模态统一模型
VARGPT是北京大学推出的多模态大语言模型,专注于视觉理解和生成任务,支持混合模态输入和高质量图像生成。

TITAN:哈佛医学院推出多模态全切片病理基础模型,支持病理报告生成、跨模态检索
TITAN 是哈佛医学院研究团队开发的多模态全切片病理基础模型,通过视觉自监督学习和视觉-语言对齐预训练,能够在无需微调或临床标签的情况下提取通用切片表示,生成病理报告。
MV-MATH:中科院开源多模态数学推理基准,多视觉场景评估新标杆
MV-MATH 是中科院自动化所推出的多模态数学推理基准数据集,旨在评估多模态大语言模型在多视觉场景中的数学推理能力。该数据集包含2009个高质量的数学问题,涵盖11个数学领域和3个难度级别,适用于智能辅导系统和多模态学习研究。

LlamaV-o1:全能多模态视觉推理模型,推理得分超越其他开源模型,推理速度翻5倍
LlamaV-o1 是一款多模态视觉推理模型,通过逐步推理学习方法解决复杂任务,支持透明推理过程,适用于医疗、金融等领域。

Apollo:Meta 联合斯坦福大学推出专注于视频理解的多模态模型,能够理解长达数小时的视频
Apollo是由Meta和斯坦福大学合作推出的大型多模态模型,专注于视频理解。该模型通过“Scaling Consistency”现象,在较小模型上的设计决策能够有效扩展至大型模型,显著提升了视频理解能力。

SpatialVLA:上海AI Lab联合上科大推出的空间具身通用操作模型
SpatialVLA 是由上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,赋予机器人强大的3D空间理解能力,支持跨平台泛化控制。

CogView4:智谱开源中文文生图新标杆,中文海报+任意分辨率一键生成
CogView4 是智谱推出的开源文生图模型,支持中英双语输入和任意分辨率图像生成,特别优化了中文文字生成能力,适合广告、创意设计等场景。
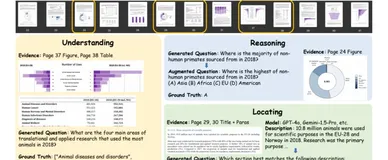
LongDocURL:中科院联合阿里推出多模态长文档理解基准数据集,用于评估模型对复杂文档分析与推理的能力
LongDocURL 是由中科院与淘天集团联合推出的多模态长文档理解基准数据集,涵盖 2,325 个问答对,支持复杂文档的理解、推理和定位任务。

OpenEMMA:德克萨斯开源端到端的自动驾驶多模态模型框架,基于预训练的 MLLMs,处理复杂的视觉数据,推理驾驶场景
OpenEMMA 是德州农工大学、密歇根大学和多伦多大学共同开源的端到端自动驾驶多模态模型框架,基于预训练的多模态大型语言模型处理视觉数据和复杂驾驶场景的推理。

RDT:清华开源全球最大的双臂机器人操作任务扩散基础模型、代码与训练集,基于模仿能力机器人能够自主完成复杂任务
RDT(Robotics Diffusion Transformer)是由清华大学AI研究院TSAIL团队推出的全球最大的双臂机器人操作任务扩散基础模型。RDT具备十亿参数量,能够在无需人类操控的情况下自主完成复杂任务,如调酒和遛狗。

AGUVIS:指导模型实现 GUI 自动化训练框架,结合视觉-语言模型进行训练,实现跨平台自主 GUI 交互
AGUVIS 是香港大学与 Salesforce 联合推出的纯视觉 GUI 自动化框架,能够在多种平台上实现自主 GUI 交互,结合显式规划和推理,提升复杂数字环境中的导航和交互能力。

GeneralDyG:南洋理工推出通用动态图异常检测方法,支持社交网络、电商和网络安全
GeneralDyG 是南洋理工大学推出的通用动态图异常检测方法,通过时间 ego-graph 采样、图神经网络和时间感知 Transformer 模块,有效应对数据多样性、动态特征捕捉和计算成本高等挑战。

Uni-AdaFocus:清华大学开源高效视频理解框架,根据视频内容动态分配计算资源
Uni-AdaFocus 是清华大学推出的高效视频理解框架,通过自适应聚焦机制动态调整计算资源分配,显著提升视频处理效率。






