

Pipecat实战:5步快速构建语音与AI整合项目,创建你的第一个多模态语音 AI 助手
Pipecat 是一个开源的 Python 框架,专注于构建语音和多模态对话代理,支持与多种 AI 服务集成,提供实时处理能力,适用于语音助手、企业服务等场景。

AI生成视频告别剪辑拼接!MAGI-1:开源自回归视频生成模型,支持一镜到底的长视频生成
MAGI-1是Sand AI开源的全球首个自回归视频生成大模型,采用创新架构实现高分辨率流畅视频生成,支持无限扩展和精细控制,在物理行为预测方面表现突出。
Probly:开源 AI Excel表格工具,交互式生成数据分析结果与可视化图表
Probly 是一款结合电子表格功能与 Python 数据分析能力的 AI 工具,支持在浏览器中运行 Python 代码,提供交互式电子表格、数据可视化和智能分析建议,适合需要强大数据分析功能又希望操作简便的用户。

FlowiseAI:34K Star!集成多种模型和100+组件的 LLM 应用低代码开发平台,拖拽组件轻松构建程序
FlowiseAI 是一款开源的低代码工具,通过拖拽可视化组件,用户可以快速构建自定义的 LLM 应用程序,支持多模型集成和记忆功能。

Janus-Pro:DeepSeek 开源的多模态模型,支持图像理解和生成
Janus-Pro是DeepSeek推出的一款开源多模态AI模型,支持图像理解和生成,提供1B和7B两种规模,适配多元应用场景。通过改进的训练策略、扩展的数据集和更大规模的模型,显著提升了文本到图像的生成能力和指令跟随性能。

Agent Laboratory:AI自动撰写论文,AMD开源自动完成科研全流程的多智能体框架
Agent Laboratory 是由 AMD 和约翰·霍普金斯大学联合推出的自主科研框架,基于大型语言模型,能够加速科学发现、降低成本并提高研究质量。

NotaGen:中央音乐学院联合清华推出AI音乐生成模型,古典乐谱一键生成,音乐性接近人类!
NotaGen 是由中央音乐学院、北京航空航天大学、清华大学等机构联合推出的音乐生成模型,基于模仿大型语言模型的训练范式,能够生成高质量的古典乐谱。该模型通过预训练、微调和强化学习相结合的方式,显著提升了符号音乐生成的艺术性和可控性。

Eko:一句话就能快速构建复杂工作流的 AI 代理开发框架!快速实现自动操作电脑和浏览器完成任务
Eko 是 Fellou AI 推出的开源 AI 代理开发框架,支持自然语言驱动,帮助开发者快速构建从简单指令到复杂工作流的智能代理。

AgiBot World:智元机器人开源百万真机数据集,数据集涵盖了日常生活所需的绝大多数动作
AgiBot World 是智元机器人开源的百万真机数据集,旨在推动具身智能的发展,覆盖家居、餐饮、工业等五大核心场景。

重定义数字人交互!OmniTalker:阿里推出实时多模态说话头像生成框架,音视频实现唇语级同步
阿里巴巴推出的OmniTalker框架通过Thinker-Talker架构实现文本驱动的实时说话头像生成,创新性采用TMRoPE技术确保音视频同步,支持流式多模态输入处理。

AigcPanel:开源的 AI 虚拟数字人系统,一键安装开箱即用,支持视频合成、声音合成和声音克隆
AigcPanel 是一款开源的 AI 虚拟数字人系统,支持视频合成、声音克隆等功能,适用于影视制作、虚拟主播、教育培训等多种场景。

StockMixer:上海交大推出预测股票价格的 MLP 架构,通过捕捉指标、时间和股票间的复杂相关性,预测下一个交易日的收盘价
StockMixer 是上海交通大学推出的基于多层感知器的股票价格预测架构,通过指标、时间和股票混合实现高效预测。

MedRAG:医学AI革命!知识图谱+四层诊断,临床准确率飙升11.32%
MedRAG是南洋理工大学推出的医学诊断模型,结合知识图谱与大语言模型,提升诊断准确率11.32%,支持多模态输入与智能提问,适用于急诊、慢性病管理等多种场景。
结合DeepSeek-R1强化学习方法的视觉模型!VLM-R1:输入描述就能精确定位图像目标
VLM-R1 是基于强化学习技术的视觉语言模型,通过自然语言指令精确定位图像目标,支持复杂场景推理与高效训练。

Data Formulator:微软开源的数据可视化 AI 工具,通过自然语言交互快速创建复杂的数据图表
Data Formulator 是微软研究院推出的开源 AI 数据可视化工具,结合图形化界面和自然语言输入,帮助用户快速创建复杂的可视化图表。

Mini-InternVL:轻量级多模态大模型,4B 参数量媲美 InternVL2-76B
Mini-InternVL 是上海AI Lab联合清华等机构推出的轻量级多模态大模型,支持高效推理、跨领域适应和动态分辨率输入,适用于多种场景。

阿里通义开源全模态大语言模型 R1-Omni:情感分析成绩新标杆!推理过程全程透明,准确率飙升200%
R1-Omni 是阿里通义开源的全模态大语言模型,专注于情感识别任务,结合视觉和音频信息,提供可解释的推理过程,显著提升情感识别的准确性和泛化能力。

PhotoDoodle:设计师必备!AI一键生成装饰元素,30+样本复刻风格+无缝融合的开源艺术编辑框架
PhotoDoodle 是由字节跳动、新加坡国立大学等联合推出的艺术化图像编辑框架,能够通过少量样本学习艺术家的独特风格,实现照片涂鸦和装饰性元素生成。

ToddlerBot:告别百万经费!6000刀就能造人形机器人,斯坦福开源全套方案普及机器人研究
ToddlerBot 是斯坦福大学推出的低成本开源人形机器人平台,支持强化学习、模仿学习和零样本模拟到现实转移,适用于运动操作研究和多场景应用。

Baichuan-Omni-1.5:百川智能开源全模态理解与生成模型,支持文本、图像、音频和视频的多模态输入和输出
Baichuan-Omni-1.5 是百川智能开源的全模态理解模型,支持文本、图像、音频和视频的多模态输入和输出,显著提升多模态交互体验。

FinRobot:开源的金融专业 AI Agent,提供市场预测、报告分析和交易策略等金融解决方案
FinRobot 是一个开源的 AI Agent 平台,专注于金融领域的应用,通过大型语言模型(LLMs)构建复杂的金融分析和决策工具,提供市场预测、文档分析和交易策略等多种功能。
Magma:微软放大招!新型多模态AI能看懂视频+浏览网页+UI交互+控制机器人,数字世界到物理现实无缝衔接
Magma 是微软研究院开发的多模态AI基础模型,结合语言、空间和时间智能,能够处理图像、视频和文本等多模态输入,适用于UI导航、机器人操作和复杂任务规划。

Omnitool:开发者桌面革命!开源神器一键整合ChatGPT+Stable Diffusion等主流AI平台,本地运行不联网
Omnitool 是一款开源的 AI 桌面环境,支持本地运行,提供统一交互界面,快速接入 OpenAI、Stable Diffusion、Hugging Face 等主流 AI 平台,具备高度扩展性。
VideoLLaMA3:阿里达摩院开源专注于视觉理解的多模态基础模型,具备多语言视频理解能力
VideoLLaMA3 是阿里巴巴开源的多模态基础模型,专注于图像和视频理解,支持多语言生成、视频内容分析和视觉问答任务,适用于多种应用场景。

24.7K Star!用 KHOJ 打造你的AI第二大脑,自动整合和更新多源知识,轻松构建个人知识库
KHOJ 是一款开源的个人化 AI 助手,支持多源知识整合、语义搜索、个性化图像生成等功能,帮助用户高效管理知识库。

Riona-AI-Agent:自媒体 AI 代理!自动点赞、评论、个性化内容生成和发布等交互任务
Riona-AI-Agent 是一款基于 Node.js 和 TypeScript 的 AI 自动化工具,支持 Instagram、Twitter 等平台的自动化交互,生成高质量内容,提升社交媒体管理效率。

NodeTool:AI 工作流可视化构建器,通过拖放节点设计复杂的工作流,集成 OpenAI 等多个平台
NodeTool 是一个开源的 AI 工作流可视化构建器,通过拖放节点的方式设计复杂的工作流,无需编码即可快速原型设计和测试。它支持本地 GPU 运行 AI 模型,并与 Hugging Face、OpenAI 等平台集成,提供模型访问能力。

傅利叶开源人形机器人,提供完整的开源套件!Fourier N1:具备23个自由度和3.5米/秒运动能力
傅利叶推出的开源人形机器人N1搭载自研动力系统与多模态交互模块,具备23个自由度和3.5米/秒运动能力,提供完整开源套件助力开发者验证算法。

AIMv2:苹果开源多模态视觉模型,自回归预训练革新图像理解
AIMv2 是苹果公司开源的多模态自回归预训练视觉模型,通过图像和文本的深度融合提升视觉模型的性能,适用于多种视觉和多模态任务。
LazyLLM:还在为AI应用开发掉头发?商汤开源智能体低代码开发工具,三行代码部署聊天机器人
LazyLLM 是一个低代码开发平台,可帮助开发者快速构建多智能体大语言模型应用,支持一键部署、跨平台操作和多种复杂功能。

开源学习神器把2小时网课压成5分钟脑图!BiliNote:一键转录哔哩哔哩视频,生成结构化学习文档
本文介绍基于FastAPI与React构建的开源视频笔记工具BiliNote,其整合多模态AI技术实现视频内容结构化解析,支持跨平台视频源处理与本地化部署方案,提供从语音转写到智能摘要的全流程自动化能力。

QVQ-Max:阿里通义新一代视觉推理模型!再造多模态「全能眼」秒解图文难题
QVQ-Max是阿里通义推出的新一代视觉推理模型,不仅能解析图像视频内容,还能进行深度推理和创意生成,在数学解题、数据分析、穿搭建议等场景展现强大能力。
MME-CoT:多模态模型推理能力终极评测!六大领域细粒度评估,港中大等机构联合推出
MME-CoT 是由港中文等机构推出的用于评估大型多模态模型链式思维推理能力的基准测试框架,涵盖数学、科学、OCR、逻辑、时空和一般场景等六个领域,提供细粒度的推理质量、鲁棒性和效率评估。

Cosmos-Reason1:物理常识觉醒!NVIDIA 56B模型让AI懂重力+时空法则
Cosmos-Reason1是NVIDIA推出的多模态大语言模型系列,具备物理常识理解和具身推理能力,支持视频输入和长链思考,可应用于机器人、自动驾驶等场景。

MedRAX:专注于胸部X光检查的AI医学推理智能体,帮助医生快速解读胸部X光片
MedRAX 是一款专门用于胸部X光检查的医学推理AI智能体,整合了多种最先进的分析工具,支持多模态推理和动态任务分解。
行业实践 | 基于Qwen2-VL实现医疗表单结构化输出
本项目针对不同医院检查报告单样式差异大、手机拍摄质量差等问题,传统OCR识别效果不佳的情况,探索并选定了Qwen2-vl系列视觉语言模型。通过微调和优化,模型在识别准确率上显著提升,能够精准识别并结构化输出报告单信息,支持整张报告单及特定项目的识别。系统采用FastAPI封装接口,Gradio构建展示界面,具备高效、灵活的应用特性。未来该方案可扩展至多种文本识别场景,助力行业数字化转型。

OmniAlign-V:20万高质量多模态数据集开源,让AI模型真正对齐人类偏好
OmniAlign-V 是由上海交通大学、上海AI Lab等机构联合推出的高质量多模态数据集,旨在提升多模态大语言模型与人类偏好的对齐能力。该数据集包含约20万个多模态训练样本,涵盖自然图像和信息图表,结合开放式问答对,支持知识问答、推理任务和创造性任务。

OCRmyPDF:16.5K Star!快速将 PDF 文件转换为可搜索、可复制的文档的命令行工具
OCRmyPDF 是一款开源命令行工具,专为将扫描的 PDF 文件转换为可搜索、可复制的文档。支持多语言、图像优化和多核处理。

Cosmos:英伟达生成式世界基础模型平台,加速自动驾驶与机器人开发
Cosmos 是英伟达推出的生成式世界基础模型平台,旨在加速物理人工智能系统的发展,特别是在自动驾驶和机器人领域。

月之暗面开源16B轻量级多模态视觉语言模型!Kimi-VL:推理仅需激活2.8B,支持128K上下文与高分辨率输入
月之暗面开源的Kimi-VL采用混合专家架构,总参数量16B推理时仅激活2.8B,支持128K上下文窗口与高分辨率视觉输入,通过长链推理微调和强化学习实现复杂任务处理能力。
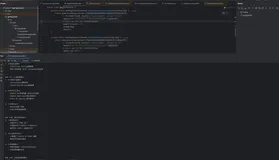
JAVA接入DeepSeek大模型接口开发---阿里云的百炼模型
随着大模型的越来越盛行,现在很多企业开始接入大模型的接口,今天我从java开发角度来写一个demo的示例,用于接入DeepSeek大模型,国内的大模型有很多的接入渠道,今天主要介绍下阿里云的百炼模型,因为这个模型是免费的,只要注册一个账户,就会免费送百万的token进行学习,今天就从一个简单的可以执行的示例开始进行介绍,希望可以分享给各位正在学习的同学们。
MeteoRA:多任务AI框架革新!动态切换+MoE架构,推理效率提升200%
MeteoRA 是南京大学推出的多任务嵌入框架,基于 LoRA 和 MoE 架构,支持动态任务切换与高效推理。

Emotion-LLaMA:用 AI 读懂、听懂、看懂情绪,精准捕捉文本、音频和视频中的复杂情绪
Emotion-LLaMA 是一款多模态情绪识别与推理模型,融合音频、视觉和文本输入,通过特定情绪编码器整合信息,广泛应用于人机交互、教育、心理健康等领域。
AI Dev Gallery:微软开源 Windows AI 模型本地运行工具包和示例库,助理开发者快速集成 AI 功能
微软推出的AI Dev Gallery,为Windows开发者提供开源AI工具包和示例库,支持本地运行AI模型,提升开发效率。

VSI-Bench:李飞飞谢赛宁团队推出视觉空间智能基准测试集,旨在评估多模态大语言模型在空间认知和理解方面的能力
VSI-Bench是由李飞飞和谢赛宁团队推出的视觉空间智能基准测试集,旨在评估多模态大型语言模型(MLLMs)在空间认知和理解方面的能力。该基准测试集包含超过5000个问题-答案对,覆盖近290个真实室内场景视频,涉及多种环境,能够系统地测试和提高MLLMs在视觉空间智能方面的表现。

VMB:中科院联合多所高校推出多模态音乐生成框架,能够通过文本、图像和视频等多种输入生成音乐
VMB(Visuals Music Bridge)是由中科院联合多所高校机构推出的多模态音乐生成框架,能够从文本、图像和视频等多种输入模态生成音乐。该框架通过文本桥接和音乐桥接解决了数据稀缺、跨模态对齐弱和可控性有限的问题。
Ola:清华联合腾讯等推出的全模态语言模型!实现对文本、图像、视频和音频的全面理解
Ola 是由清华大学、腾讯 Hunyuan 研究团队和新加坡国立大学 S-Lab 合作开发的全模态语言模型,支持文本、图像、视频和音频输入,并具备实时流式解码功能。

GLM-Realtime:智谱推出多模态交互AI模型,融入清唱功能,支持视频和语音交互
GLM-Realtime 是智谱推出的端到端多模态模型,具备低延迟的视频理解与语音交互能力,支持清唱功能、2分钟内容记忆及灵活调用外部工具,适用于多种智能场景。

导演失业预警!Seaweed-7B:字节7B参数模型让剧本自动变电影!20秒长镜头丝滑生成
Seaweed-7B是字节跳动推出的70亿参数视频生成模型,支持从文本、图像或音频生成高质量视频内容,具备长镜头生成、实时渲染等先进特性,通过优化架构显著降低计算成本。






