

AgentScope:阿里开源多智能体低代码开发平台,支持一键导出源码、多种模型API和本地模型部署
AgentScope是阿里巴巴集团开源的多智能体开发平台,旨在帮助开发者轻松构建和部署多智能体应用。该平台提供分布式支持,内置多种模型API和本地模型部署选项,支持多模态数据处理。
MNN-LLM App:在手机上离线运行大模型,阿里巴巴开源基于 MNN-LLM 框架开发的手机 AI 助手应用
MNN-LLM App 是阿里巴巴基于 MNN-LLM 框架开发的 Android 应用,支持多模态交互、多种主流模型选择、离线运行及性能优化。

Mobile-Agent:通过视觉感知实现自动化手机操作,支持多应用跨平台
Mobile-Agent 是一款基于多模态大语言模型的智能代理,能够通过视觉感知自主完成复杂的移动设备操作任务,支持跨应用操作和纯视觉解决方案。
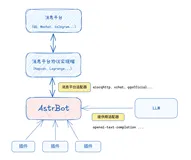
AstrBot:轻松将大模型接入QQ、微信等消息平台,打造多功能AI聊天机器人的开发框架,附详细教程
AstrBot 是一个开源的多平台聊天机器人及开发框架,支持多种大语言模型和消息平台,具备多轮对话、语音转文字等功能。
AnythingLLM:34K Star!一键上传文件轻松打造个人知识库,构建只属于你的AI助手,附详细部署教程
AnythingLLM 是一个全栈应用程序,能够将文档、资源转换为上下文,支持多种大语言模型和向量数据库,提供智能聊天功能。

音乐人必看!OpenUtau:开源AI歌声合成神器,快速打造专业级虚拟歌手,中文日文无缝切换
OpenUtau是一款开源的歌声合成工具,兼容UTAU音源库和重采样器,支持多语言界面及预渲染功能,让音乐创作更加高效便捷。

阿里开源AI视频生成大模型 Wan2.1:14B性能超越Sora、Luma等模型,一键生成复杂运动视频
Wan2.1是阿里云开源的一款AI视频生成大模型,支持文生视频和图生视频任务,具备强大的视觉生成能力,性能超越Sora、Luma等国内外模型。

VideoCaptioner:北大推出视频字幕处理神器,AI自动生成+断句+翻译,1小时工作量5分钟搞定
VideoCaptioner 是一款基于大语言模型的智能视频字幕处理工具,支持语音识别、字幕断句、优化、翻译全流程处理,并提供多种字幕样式和格式导出。

Agno:18.7K Star!快速构建多模态智能体的轻量级框架,运行速度比LangGraph快5000倍!
Agno 是一个用于构建多模态智能体的轻量级框架,支持文本、图像、音频和视频等多种数据模态,能够快速创建智能体并实现高效协作。

用自然语言控制电脑,字节跳动开源 UI-TARS 的桌面版应用!内附详细的安装和配置教程
UI-TARS Desktop 是一款基于视觉语言模型的 GUI 代理应用,支持通过自然语言控制电脑操作,提供跨平台支持、实时反馈和精准的鼠标键盘控制。

MarkItDown:微软开源的多格式转Markdown工具,支持将PDF、Word、图像和音频等文件转换为Markdown格式
MarkItDown 是微软开源的多功能文档转换工具,支持将 PDF、PPT、Word、Excel、图像、音频等多种格式的文件转换为 Markdown 格式,具备 OCR 文字识别、语音转文字和元数据提取等功能。

Open Notebook:开源 AI 笔记工具,支持多种文件格式,自动转播客和生成总结,集成搜索引擎等功能
Open Notebook 是一款开源的 AI 笔记工具,支持多格式笔记管理,并能自动将笔记转换为博客或播客,适用于学术研究、教育、企业知识管理等多个场景。

斯坦福黑科技让笔记本GPU也能玩转AI视频生成!FramePack:压缩输入帧上下文长度!仅需6GB显存即可生成高清动画
斯坦福大学推出的FramePack技术通过压缩输入帧上下文长度,解决视频生成中的"遗忘"和"漂移"问题,仅需6GB显存即可在普通笔记本上实时生成高清视频。
Aider:27.6K Star!这个终端AI编程神器能用语音改代码,自动生成Git记录并提交,接入DeepSeek斩获编程基准最高分
Aider 是一款基于命令行的开源 AI 编程助手,支持多种编程语言和主流 LLM,可自动完成代码修改、Git 提交及语音交互。

PC Agent:开源 AI 电脑智能体,自动收集人机交互数据,模拟认知过程实现办公自动化
PC Agent 是上海交通大学与 GAIR 实验室联合推出的智能 AI 系统,能够模拟人类认知过程,自动化执行复杂的数字任务,如组织研究材料、起草报告等,展现了卓越的数据效率和实际应用潜力。

PPO最强,DPO一般?一文带你了解常见三种强化学习方法,文末推荐大模型微调神器!
大模型如何更懂人类?关键在于“对齐”。PPO、DPO、KTO是三大主流对齐方法:PPO效果强但复杂,DPO平衡高效,KTO低成本易上手。不同团队可根据资源选择路径。LLaMA-Factory Online让微调像浏览器操作一样简单,助力人人皆可训练专属模型。

AutoGLM沉思:智谱AI推出首个能"边想边干"的自主智能体!深度研究+多模态交互,颠覆传统AI工作模式
AutoGLM沉思是由智谱AI推出的一款开创性AI智能体,它突破性地将深度研究能力与实际操作能力融为一体,实现了AI从被动响应到主动执行的跨越式发展。
Flame:开源AI设计图转代码模型!生成React组件,精准还原UI+动态交互效果
Flame 是一款开源的多模态 AI 模型,能够将 UI 设计图转换为高质量的现代前端代码,支持 React 等主流框架,具备动态交互、组件化开发等功能,显著提升前端开发效率。

moonshot-v1-vision-preview:月之暗面Kimi推出多模态视觉理解模型,支持图像识别、OCR文字识别、数据提取
moonshot-v1-vision-preview 是月之暗面推出的多模态图片理解模型,具备强大的图像识别、OCR文字识别和数据提取能力,支持API调用,适用于多种应用场景。

AI视频生成也能自动补全!Wan2.1 FLF2V:阿里通义开源14B视频生成模型,用首尾两帧生成过渡动画
万相首尾帧模型是阿里通义开源的14B参数规模视频生成模型,基于DiT架构和高效视频压缩VAE,能够根据首尾帧图像自动生成5秒720p高清视频,支持多种风格变换和细节复刻。

Second Me:硅基生命或成现实?如何用AI克隆自己,打造你的AI数字身份!
Second Me 是一个开源AI身份系统,允许用户创建完全私有的个性化AI代理,代表用户的真实自我,支持本地训练和部署,保护用户隐私和数据安全。

WeaveFox:蚂蚁集团推出 AI 前端智能研发平台,能够根据设计图直接生成源代码,支持多种客户端和技术栈
蚂蚁团队推出的AI前端研发平台WeaveFox,能够根据设计图直接生成前端源代码,支持多种应用类型和技术栈,提升开发效率和质量。本文将详细介绍WeaveFox的功能、技术原理及应用场景。

Open-LLM-VTuber:宅男福音!开源AI老婆离线版上线,实时语音+Live2D互动还会脸红心跳
Open-LLM-VTuber 是一个开源的跨平台语音交互 AI 伴侣项目,支持实时语音对话、视觉感知和生动的 Live2D 动态形象,完全离线运行,保护用户隐私。
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平台,安装简便,适合开发者快速上手。

Univer:开源全栈 AI 办公工具,支持 Word、Excel、PPT 等文档处理和多人实时协作
Univer 是一款开源的 AI 办公工具,支持 Word、Excel 等文档处理的全栈解决方案。它具有强大的功能、高度的可扩展性和跨平台兼容性,适用于个人和企业用户,能够显著提高工作效率。

Midscene.js:AI 驱动的 UI 自动化测试框架,支持自然语言交互,生成可视化报告
Midscene.js 是一款基于 AI 技术的 UI 自动化测试框架,通过自然语言交互简化测试流程,支持动作执行、数据查询和页面断言,提供可视化报告,适用于多种应用场景。
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。

Eliza:TypeScript 版开源 AI Agent 开发框架,快速搭建智能、个性的 Agents 系统
Eliza 是一个开源的多代理模拟框架,支持多平台连接、多模型集成,能够快速构建智能、高效的AI系统。

video-subtitle-master:开源字幕生成神器!批量生成+AI翻译全自动,5分钟解放双手
video-subtitle-master 是一款开源AI字幕生成工具,支持批量为视频或音频生成字幕,并可将字幕翻译成多种语言。它集成了多种翻译服务和语音识别技术,适合视频创作者、教育领域和个人娱乐使用。

YuE:开源AI音乐生成模型,能够将歌词转化为完整的歌曲,支持多种语言和多种音乐风格
YuE 是香港科技大学和 M-A-P 联合开发的开源 AI 音乐生成模型,能够将歌词转化为完整的歌曲,支持多种音乐风格和多语言。

Vision Parse:开源的 PDF 转 Markdown 工具,结合视觉语言模型和 OCR,识别文本和表格并保持原格式
Vision Parse 是一款开源的 PDF 转 Markdown 工具,基于视觉语言模型,能够智能识别和提取 PDF 中的文本和表格,并保持原有格式和结构。

Browser Use:开源 AI 浏览器助手,自动完成网页交互任务,支持多标签页管理、视觉识别和内容提取等功能
Browser Use 是一款专为大语言模型设计的智能浏览器工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。

从商业海报到二次元插画多风格通吃!HiDream-I1:智象未来开源文生图模型,17亿参数秒出艺术大作
HiDream-I1是智象未来团队推出的开源图像生成模型,采用扩散模型技术和混合专家架构,在图像质量、提示词遵循能力等方面表现优异,支持多种风格生成。

PDF to Podcast:英伟达开源黑科技!PDF 秒转播客/有声书,告别阅读疲劳轻松学习!
NVIDIA推出的PDF to Podcast工具,基于大型语言模型和文本到语音技术,将PDF文档转换为生动的音频内容。

Zerox:AI驱动的万能OCR工具,精准识别复杂布局并输出Markdown格式,支持PDF、DOCX、图片等多种文件格式
Zerox 是一款开源的本地化高精度OCR工具,基于GPT-4o-mini模型,支持PDF、DOCX、图片等多种格式文件,能够零样本识别复杂布局文档,输出Markdown格式结果。

模型手动绑骨3天,AI花3分钟搞定!UniRig:清华开源通用骨骼自动绑定框架,助力3D动画制作
UniRig是清华大学与VAST联合研发的自动骨骼绑定框架,基于自回归模型与交叉注意力机制,支持多样化3D模型的骨骼生成与蒙皮权重预测,其创新的骨骼树标记化技术显著提升动画制作效率。

StarVector:图像秒变矢量代码!开源多模态模型让SVG生成告别手绘
StarVector是由ServiceNow Research等机构联合开发的开源多模态视觉语言模型,能够将图像和文本转换为可编辑的SVG矢量图形,支持1B和8B两种规模,在SVG生成任务中表现出色。

Hunyuan3D 2.0:腾讯混元开源3D生成大模型!图生/文生秒建高精度模型,细节纹理自动合成
Hunyuan3D 2.0 是腾讯推出的大规模 3D 资产生成系统,专注于从文本和图像生成高分辨率的 3D 模型,支持几何生成和纹理合成。
MoneyPrinterTurbo:23.9K Star!这个AI把写文案+找素材+剪视频全包了,日更10条不是梦
MoneyPrinterTurbo 是一款功能强大的 AI 工具,支持通过主题或关键词自动生成视频文案、素材、字幕与背景音乐,并合成高清短视频,适合批量生成与多语言支持。

HealthGPT:你的AI医疗助手上线了:支持X光到病理切片,诊断建议+报告生成全自动
HealthGPT 是浙江大学联合阿里巴巴等机构开发的先进医学视觉语言模型,具备医学图像分析、诊断辅助和个性化治疗方案建议等功能。

FilmAgent:多智能体共同协作制作电影,哈工大联合清华推出 AI 驱动的自动化电影制作工具
FilmAgent 是由哈工大与清华联合推出的AI电影自动化制作工具,通过多智能体协作实现从剧本生成到虚拟拍摄的全流程自动化。

多模态模型卷王诞生!InternVL3:上海AI Lab开源78B多模态大模型,支持图文视频全解析!
上海人工智能实验室开源的InternVL3系列多模态大语言模型,通过原生多模态预训练方法实现文本、图像、视频的统一处理,支持从1B到78B共7种参数规模。

CLaMP 3:音乐搜索AI革命!多模态AI能听懂乐谱/MIDI/音频,用27国语言搜索全球音乐
CLaMP 3是由清华大学团队开发的多模态、多语言音乐信息检索框架,支持27种语言,能够进行跨模态音乐检索、零样本分类和音乐推荐等任务。

多模态交互3D建模革命!Neural4D 2o:文本+图像一键生成高精度3D内容
Neural4D 2o是DreamTech推出的突破性3D大模型,通过文本、图像、3D和运动数据的联合训练,实现高精度3D生成与智能编辑,为创作者提供全新的多模态交互体验。

Doubao-1.5-pro:字节跳动最新豆包大模型,性能超越GPT-4o和Claude 3.5 Sonnet
豆包大模型1.5是字节跳动推出的最新大模型,采用大规模稀疏MoE架构,支持多模态输入输出,具备低时延语音对话能力,综合性能优于GPT-4o和Claude 3.5 Sonnet。

RAGEN:RL训练LLM推理新范式!开源强化学习框架让Agent学会多轮决策
RAGEN是一个基于StarPO框架的开源强化学习系统,通过马尔可夫决策过程形式化Agent与环境的交互,支持PPO、GRPO等多种优化算法,显著提升多轮推理训练的稳定性。

Dify-Plus:企业级AI管理核弹!开源方案吊打SaaS,额度+密钥+鉴权系统全面集成
Dify-Plus 是基于 Dify 二次开发的企业级增强版项目,新增用户额度、密钥管理、Web 登录鉴权等功能,优化权限管理,适合企业场景使用。

AI生成视频告别剪辑拼接!MAGI-1:开源自回归视频生成模型,支持一镜到底的长视频生成
MAGI-1是Sand AI开源的全球首个自回归视频生成大模型,采用创新架构实现高分辨率流畅视频生成,支持无限扩展和精细控制,在物理行为预测方面表现突出。
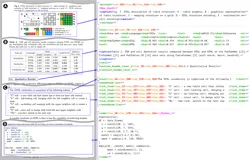
SmolDocling:256M多模态小模型秒转文档!开源OCR效率提升10倍
SmolDocling 是一款轻量级的多模态文档处理模型,能够将图像文档高效转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。






