
计算机视觉
包含图像分类、图像生成、人体人脸识别、动作识别、目标分割、视频生成、卡通画、视觉评价、三维视觉等多个领域

Manga Image Translator:开源的漫画文字翻译工具,支持多语言翻译并嵌入原图,保持漫画的原始风格和布局
Manga Image Translator 是一款开源的漫画图片文字翻译工具,支持多语言翻译并能将翻译后的文本无缝嵌入原图,保持漫画的原始风格和布局。该工具基于OCR技术和深度学习模型,提供批量处理和在线/离线翻译功能。

Qwen2.5-VL:阿里通义千问最新开源视觉语言模型,能够理解超过1小时的长视频
Qwen2.5-VL 是阿里通义千问团队开源的视觉语言模型,具有3B、7B和72B三种不同规模,能够识别常见物体、分析图像中的文本、图表等元素,并具备作为视觉Agent的能力。

video-analyzer:开源视频分析工具,支持提取视频关键帧、音频转录,自动生成视频详细描述
video-analyzer 是一款开源视频分析工具,结合 Llama 的 11B 视觉模型和 OpenAI 的 Whisper 模型,能够提取视频关键帧、转录音频并生成详细描述,支持本地运行和多种应用场景

X-AnyLabeling:开源的 AI 图像标注工具,支持多种标注样式,适于目标检测、图像分割等不同场景
X-AnyLabeling是一款集成了多种深度学习算法的图像标注工具,支持图像和视频的多样化标注样式,适用于多种AI训练场景。本文将详细介绍X-AnyLabeling的功能、技术原理以及如何运行该工具。

RF-DETR:YOLO霸主地位不保?开源 SOTA 实时目标检测模型,比眨眼还快3倍!
RF-DETR是首个在COCO数据集上突破60 mAP的实时检测模型,结合Transformer架构与DINOv2主干网络,支持多分辨率灵活切换,为安防、自动驾驶等场景提供高精度实时检测方案。

LHM:单图生成3D动画人!阿里开源建模核弹,高斯点云重构服装纹理
阿里巴巴通义实验室开源的LHM模型,能够从单张图像快速重建高质量可动画化的3D人体模型,支持实时渲染和姿态控制,适用于AR/VR、游戏开发等多种场景。

InvSR:开源图像超分辨率生成模型,提升分辨率,修复老旧照片为超清图像
InvSR 是一个创新的图像超分辨率模型,基于扩散模型的逆过程恢复高分辨率图像。它通过深度噪声预测器和灵活的采样机制,能够高效地提升图像分辨率,适用于老旧照片修复、视频监控、医疗成像等多个领域。

STAR:南京大学联合字节开源视频超分辨率增强生成框架,视频清晰度一键提升,支持从低分辨率视频生成高分辨率视频
STAR 是由南京大学、字节跳动和西南大学联合推出的视频超分辨率框架,能够将低分辨率视频提升为高分辨率,同时保持细节清晰度和时间一致性。

UI-TARS:字节跳动开源专注于多平台 GUI 自动化交互的视觉语言模型
UI-TARS 是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,支持跨平台自动化交互,具备强大的感知、推理、行动和记忆能力,能够通过自然语言指令完成复杂任务。

PSHuman:开源单图像3D人像重建技术,一张照片就能生成3D人像模型
PSHuman 是一种先进的单图像3D人像重建技术,仅需一张照片即可生成高度逼真的3D模型,支持面部细节、全身姿态和纹理恢复,适用于影视、游戏、虚拟现实等多个领域。

Pippo:Meta放出AI大招!单张照片秒转3D人像多视角视频,AI自动补全身体细节
Pippo 是 Meta 推出的图像到视频生成模型,能够从单张照片生成 1K 分辨率的多视角高清人像视频,支持全身、面部或头部的生成。

AddressCLIP:一张照片就能准确定位!中科院联合阿里云推出街道级图像地理定位模型
AddressCLIP 是由中科院和阿里云联合开发的端到端图像地理定位模型,通过图像-文本对齐和地理匹配技术,实现街道级精度的定位,适用于城市管理、社交媒体、旅游导航等场景。
SkyReels-A1:解放动画师!昆仑开源「数字人制造机」:一张照片生成逼真虚拟主播,表情连眉毛颤动都可控
SkyReels-A1 是昆仑万维开源的首个 SOTA 级别表情动作可控的数字人生成模型,支持高保真肖像动画生成和精确的表情动作控制。

SkyReels-V1:短剧AI革命来了!昆仑开源视频生成AI秒出影视级短剧,比Sora更懂表演!
SkyReels-V1是昆仑万维开源的首个面向AI短剧创作的视频生成模型,支持高质量影视级视频生成、33种细腻表情和400多种自然动作组合。

BEN2:一键快速抠图!自动移除图像和视频中的背景,支持在线使用
BEN2 是由 Prama LLC 开发的深度学习模型,专注于从图像和视频中快速移除背景并提取前景,支持高分辨率处理和GPU加速。

Sa2VA:别再用PS抠图了!字节跳动开源Sa2VA:一句话自动分割视频,连头发丝都精准
Sa2VA 是由字节跳动等机构联合推出的多模态大语言模型,结合 SAM2 和 LLaVA 实现对图像和视频的精确分割和对话功能。

SPAR3D:一张图片就能生成3D模型,每个物体的重建时间仅需0.7秒!
SPAR3D 是由 Stability AI 和伊利诺伊大学香槟分校推出的先进单图生成3D模型方法,支持快速推理与用户交互式编辑,适用于多种3D建模场景。
ACE++:输入想法就能完成图像创作和编辑!阿里通义推出新版自然语言驱动的图像生成与编辑工具
ACE++ 是阿里巴巴通义实验室推出的升级版图像生成与编辑工具,支持多种任务,如高质量人物肖像生成、主题一致性保持和局部图像编辑。

SeedVR:高效视频修复模型,支持任意长度和分辨率,生成真实感细节
SeedVR 是南洋理工大学和字节跳动联合推出的扩散变换器模型,能够高效修复低质量视频,支持任意长度和分辨率,生成真实感细节。
Sitcom-Crafter:动画师失业警告!AI黑科技自动生成3D角色动作,剧情脚本秒变动画
Sitcom-Crafter 是一款基于剧情驱动的 3D 动作生成系统,通过多模块协同工作,支持人类行走、场景交互和多人交互,适用于动画、游戏及虚拟现实等领域。

JoyCaption:开源的图像转提示词生成工具,支持多种风格和场景,性能与 GPT4o 相当
JoyCaption 是一款开源的图像提示词生成工具,支持多种生成模式和灵活的提示选项,适用于社交媒体、图像标注、内容创作等场景,帮助用户快速生成高质量图像描述。

每个人都可以成为虚拟主播,一键创建属于你的虚拟形象,RAIN 为你实时生成逼真动画角色
RAIN 是一款创新的实时动画生成工具,支持在消费级硬件上实现无限视频流的实时动画化,适用于直播、虚拟角色生成等场景。

【Github热门项目】DeepSeek-OCR项目上线即突破7k+星!突破10倍无损压缩,重新定义文本-视觉信息处理
DeepSeek-OCR开源即获7k+星,首创“上下文光学压缩”技术,仅用100视觉token超越传统OCR模型256token性能,压缩比达10-20倍,精度仍超97%。30亿参数实现单卡日处理20万页,显著降低大模型长文本输入成本,重新定义高效文档理解新范式。

Lumina-Image 2.0:上海 AI Lab 开源的统一图像生成模型,支持生成多分辨率、多风格的图像
Lumina-Image 2.0 是上海 AI Lab 开源的高效统一图像生成模型,参数量为26亿,基于扩散模型和Transformer架构,支持多种推理求解器,能生成高质量、多风格的图像。

ColorFlow:腾讯和清华大学联合推出的图像序列着色模型,通过参考图像的颜色对黑白漫画进行着色生成彩色漫画
ColorFlow是由清华大学和腾讯ARC实验室共同推出的图像序列着色模型,通过检索增强、上下文学习和超分辨率技术,确保黑白图像序列的着色与参考图像颜色一致,适用于漫画、动画制作等工业应用。

JoyGen:用音频生成3D说话人脸视频,快速生成逼真的唇部同步视频
JoyGen 是京东和香港大学联合推出的音频驱动的3D说话人脸视频生成框架,支持多语言、高质量视觉效果和精确的唇部与音频同步。
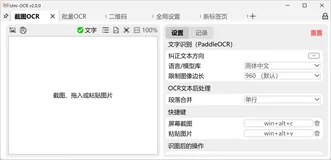
Umi-OCR:31K Star!离线OCR终结者!公式+二维码+多语种,开源免费吊打付费
Umi-OCR 是一款免费开源的离线 OCR 文字识别工具,支持截图、批量图片、PDF 扫描件的文字识别,内置多语言识别库,提供命令行和 HTTP 接口调用功能。

DeepMesh:3D建模革命!清华团队让AI自动优化拓扑,1秒生成工业级网格
DeepMesh 是由清华大学和南洋理工大学联合开发的 3D 网格生成框架,基于强化学习和自回归变换器,能够生成高质量的 3D 网格,适用于虚拟环境构建、动态内容生成、角色动画等多种场景。

Step-Video-TI2V:开源视频生成核弹!300亿参数+102帧电影运镜
Step-Video-TI2V 是阶跃星辰推出的开源图生视频模型,支持根据文本和图像生成高质量视频,具备动态性调节和多种镜头运动控制功能,适用于动画制作、短视频创作等场景。
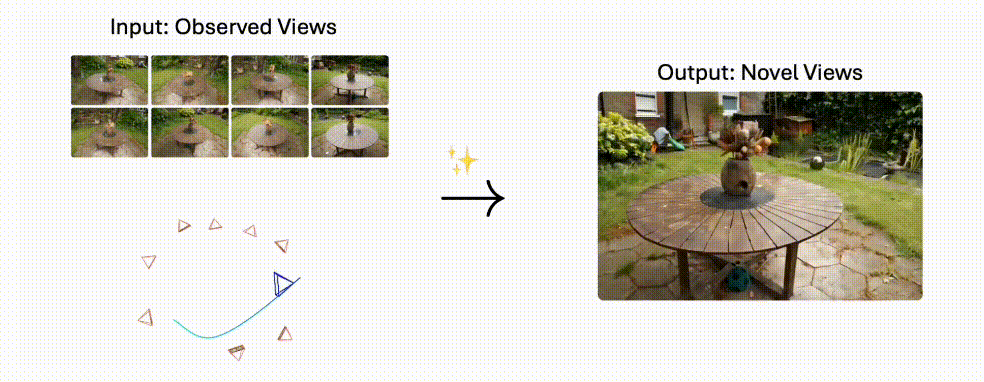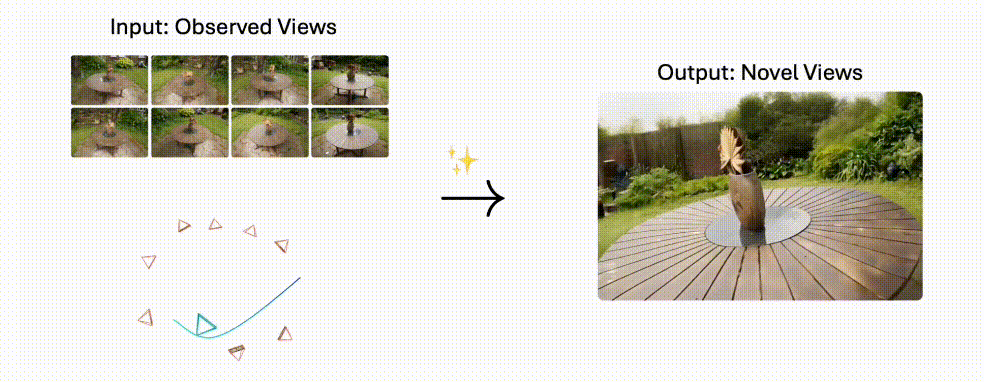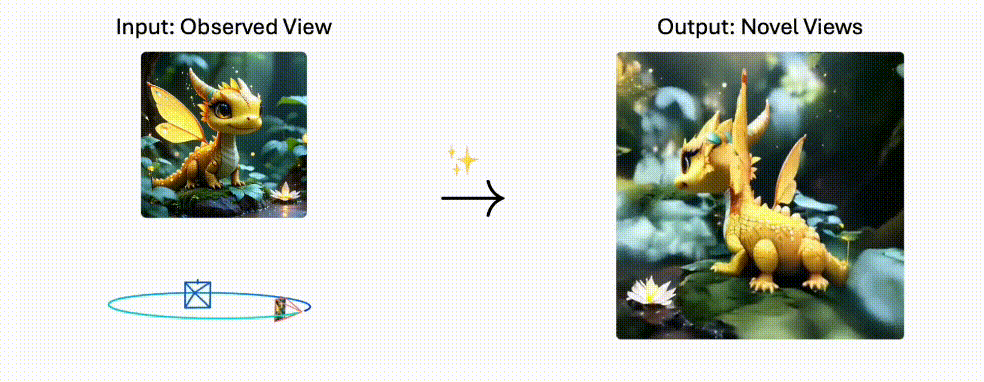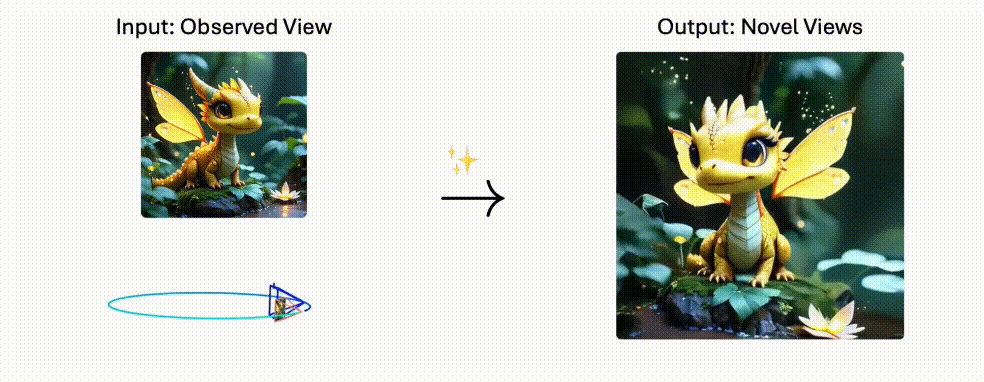
Stable Virtual Camera:2D秒变3D电影!Stability AI黑科技解锁无限运镜,自定义轨迹一键生成
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能够将 2D 图像转换为具有真实深度和透视感的 3D 视频,支持自定义相机轨迹和多种动态路径,生成高质量且时间平滑的视频。
极致的显存管理!6G显存运行混元Video模型
混元 Video 模型自发布以来,已成为目前效果最好的开源文生视频模型,然而,这个模型极为高昂的硬件需求让大多数玩家望而却步。魔搭社区的开源项目 DiffSynth-Studio 近期为混元 Video 模型提供了更高效的显存管理的支持,目前已支持使用24G显存进行无任何质量损失的视频生成,并在极致情况下,用低至 6G 的显存运行混元 Video 模型!

Magic 1-For-1:北大联合英伟达推出的高质量视频生成量化模型,支持在消费级GPU上快速生成
北京大学、Hedra Inc. 和 Nvidia 联合推出的 Magic 1-For-1 模型,优化内存消耗和推理延迟,快速生成高质量视频片段。
Tarsier2:字节跳动开源专注于图像和视频内容理解的视觉语言大模型
Tarsier2 是字节跳动推出的大规模视觉语言模型,支持高质量视频描述、问答与定位,在多个视频理解任务中表现优异。

VideoWorld:字节开源自回归视频生成模型,支持输入视频指导AI生成视频!弥补文本生成视频的短板
VideoWorld 是由字节跳动、北京交通大学和中国科学技术大学联合推出的自回归视频生成模型,能够从未标注的视频数据中学习复杂知识,支持长期推理和规划任务。

VE-Bench:北京大学开源首个针对视频编辑质量的评估指标,从多角度考虑审美并准确地评估视频编辑效果
北京大学开源了首个针对视频编辑质量评估的新指标 VE-Bench,旨在通过人类感知一致的度量标准,更准确地评估视频编辑效果。
ReCamMaster:视频运镜AI革命!单镜头秒变多机位,AI重渲染颠覆创作
ReCamMaster 是由浙江大学与快手科技联合推出的视频重渲染框架,能够根据用户指定的相机轨迹重新生成视频内容,广泛应用于视频创作、后期制作、教育等领域,提升创作自由度和质量。

CogVideoX-Flash:智谱首个免费AI视频生成模型,支持文生视频、图生视频,分辨率最高可达4K
CogVideoX-Flash 是智谱推出的首个免费AI视频生成模型,支持文生视频、图生视频,最高支持4K分辨率,广泛应用于内容创作、教育、广告等领域。

VideoRAG:长视频理解的检索增强生成技术,支持多模态信息提取,能与任何 LVLM 兼容
VideoRAG 是一种用于长视频理解的检索增强生成技术,通过提取视频中的视觉对齐辅助文本,帮助大型视频语言模型更好地理解和处理长视频内容。

VITRON:开源像素级视觉大模型,同时满足图像与视频理解、生成、分割和编辑等视觉任务
VITRON 是由 Skywork AI、新加坡国立大学和南洋理工大学联合推出的像素级视觉大模型,支持图像与视频的理解、生成、分割和编辑,适用于多种视觉任务。

Cobalt:开源的流媒体下载工具,支持解析和下载全平台的视频、音频和图片,支持多种视频质量和格式,自动提取视频字幕
cobalt 是一款开源的流媒体下载工具,支持全平台视频、音频和图片下载,提供纯净、简洁无广告的体验
FacePoke:开源AI实时面部编辑神器!拖拽调整表情/头部朝向,4K画质一键生成
FacePoke是一款基于AI技术的开源实时面部编辑工具,支持通过拖拽操作调整头部朝向和面部表情,适用于多种场景。

MangaNinja:开源线稿着色工具,自动匹配图像风格,一键快速上色
MangaNinja 是一款基于参考图像的线稿着色工具,通过创新的补丁重排模块和点驱动控制方案,实现精准颜色匹配和复杂场景处理,适用于漫画、插画和数字艺术创作。

LatentSync:根据音频生成高分辨率、动态逼真的唇形同步视频
LatentSync 是由字节跳动与北京交通大学联合推出的端到端唇形同步框架,基于音频条件的潜在扩散模型,能够生成高分辨率、动态逼真的唇同步视频,适用于影视、教育、广告等多个领域。

Leffa:Meta AI 开源精确控制人物外观和姿势的图像生成框架,在生成穿着的同时保持人物特征
Leffa 是 Meta 开源的图像生成框架,通过引入流场学习在注意力机制中精确控制人物的外观和姿势。该框架不增加额外参数和推理成本,适用于多种扩散模型,展现了良好的模型无关性和泛化能力。

EasyControl Ghibli:在线体验一键生成宫崎骏动画风,开源AI模型让你的照片秒变吉卜力
EasyControl Ghibli是基于扩散模型的AI工具,通过条件注入技术将普通照片转化为吉卜力动画风格,仅需100张训练样本即可精准还原标志性光影与色调特征。

StereoCrafter:腾讯开源将任意2D视频转换为立体3D视频的框架,适用于Apple Vision Pro等多种显示设备
StereoCrafter 是腾讯开源的框架,能够将单目2D视频转换为高保真度的立体3D视频,适用于多种显示设备。

TRELLIS:微软联合清华和中科大推出的高质量 3D 生成模型,支持局部控制和多种输出格式
TRELLIS 是由微软、清华大学和中国科学技术大学联合推出的高质量 3D 生成模型,能够根据文本或图像提示生成多样化的 3D 资产,支持多种输出格式和灵活编辑。

AI-ClothingTryOn:服装店老板连夜下架试衣间!基于Gemini开发的AI试衣应用,一键生成10种穿搭效果
AI-ClothingTryOn是基于Google Gemini技术的虚拟试衣应用,支持人物与服装照片智能合成,可生成多达10种试穿效果版本,并提供自定义提示词优化功能。

Ruyi:图森未来推出的图生视频大模型,支持多分辨率、多时长视频生成,具备运动幅度和镜头控制等功能
Ruyi是图森未来推出的图生视频大模型,专为消费级显卡设计,支持多分辨率、多时长视频生成,具备首帧、首尾帧控制、运动幅度控制和镜头控制等特性。Ruyi基于DiT架构,能够降低动漫和游戏内容的开发周期和成本,是ACG爱好者和创作者的理想工具。

Hi3DGen:2D照片秒变高精度模型,毛孔级细节完爆Blender!港中文×字节×清华联手打造3D生成黑科技
Hi3DGen是由香港中文大学、字节跳动和清华大学联合研发的高保真3D几何生成框架,通过法线图中间表示实现细节丰富的3D模型生成,其双阶段生成流程显著提升了几何保真度。






