
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
如何建设网站,网站制作的6个步骤
本文围绕企业及单位网站建设展开,详解从域名注册、服务器租用、模板选取、备案,到 SEO 推广与长期维护的完整流程。强调模板等工具可降低建站门槛、缩短周期,建议优先选择源码可控、可扩展的建站平台,同时需注重备案合规、安全维护与用户体验,助力高效打造专业网站,为数字化业务拓展奠定基础。

鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
鹰角网络为应对游戏业务高频活动带来的数据潮汐、资源弹性及稳定性需求,采用阿里云 EMR Serverless Spark 替代原有架构。迁移后实现研发效率提升,支持业务快速发展、计算效率提升,增强SLA保障,稳定性提升,降低运维成本,并支撑全球化数据架构部署。
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
碧桂园服务通过引入 EMR Serverless StarRocks 存算分离架构,解决了海量数据处理中的资源利用率低、并发能力不足等问题,显著降低了硬件和运维成本。实时查询性能提升8倍,查询出错率减少30倍,集群数据 SLA 达99.99%。此次技术升级不仅优化了用户体验,还结合AI打造了“一看”和“—问”智能场景助力精准决策与风险预测。
百观科技基于阿里云 EMR 的数据湖实践分享
百观科技为应对海量复杂数据处理的算力与成本挑战,基于阿里云 EMR 构建数据湖。EMR 依托高可用的 OSS 存储、开箱即用的 Hadoop/Spark/Iceberg 等开源技术生态及弹性调度,实现数据接入、清洗、聚合与分析全流程。通过 DLF 与 Iceberg 的优化、阶梯式弹性调度(资源利用率提升至70%)及倚天 ARM 机型搭配 EMR Trino 方案,兼顾性能与成本,支撑数据分析需求,降低算力成本。
0 基础建站?PageAdmin CMS 10 分钟搞定,源码免费拿!
PageAdmin CMS 为无编程基础用户提供高效建站方案。步骤包括:准备服务器、域名及源码;上传源码并配置数据库;通过安装向导完成基础设置;在后台创建栏目、填充内容;测试功能后上线。全程无需编程,简单操作即可搭建独立网站,支持后续维护与扩展。
EMR StarRocks Stella 内核正式发布,登顶 TPC 榜单全球第一
EMR Serverless StarRocks 重磅发布全新企业级版本内核 Stella (StarRocks Efficient and Lightening-fast Lakehouse),完全兼容开源 StarRocks,为用户提供企业级的产品功能、卓越的性能及稳定性保障。
EMR AI助手开启公测:用AI重塑大数据运维,更简单、更智能
EMR AI 助手开启公测,通过合理利用 EMR AI 助手的各项功能,可以快速查询资源信息、唤起相关操作、诊断组件异常、获取技术支持等,能帮您提升运维效率和操作体验。
StarRocks+Paimon 落地阿里日志采集:万亿级实时数据秒级查询
A+流量分析平台是阿里集团统一的全域流量数据分析平台,致力于通过埋点、采集、计算构建流量数据闭环,助力业务提升流量转化。面对万亿级日志数据带来的写入与查询挑战,平台采用Flink+Paimon+StarRocks技术方案,实现高吞吐写入与秒级查询,优化存储成本与扩展性,提升日志分析效率。
阿里云 EMR 发布托管弹性伸缩功能,支持自动调整集群大小,最高降本60%
阿里云开源大数据平台 E-MapReduce 重磅推出托管弹性伸缩功能,基于 EMR 托管弹性伸缩功能,您可以指定集群的最小和最大计算限制,EMR 会持续对与集群上运行的工作负载相关的关键指标进行采样,自动调整集群大小,以获得最佳性能和资源利用率。
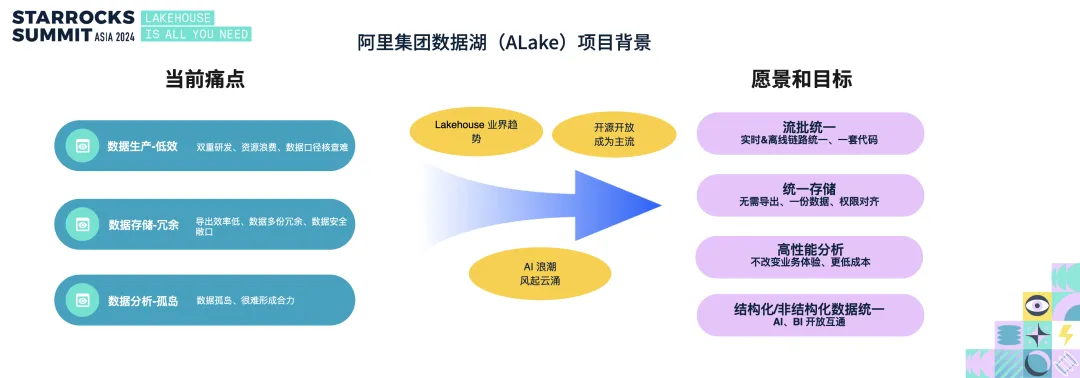
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务借助 Paimon 的准实时入湖,显著降低了存储成本,并引入 StarRocks 提升查询性能。升级后,数据时效提前60分钟,开发效率提升50%;JSON列化存储减少50%,查询性能提升最高达10倍;OLAP分析中,非JOIN查询快1倍,JOIN查询快5倍。 饿了么升级为准实时Lakehouse架构后,在时效性仅损失1-5分钟的前提下,实现Flink资源缩减、StarRocks查询性能提升(仅5%
阿里云 EMR Serverless Spark 在微财机器学习场景下的应用
面对机器学习场景下的训练瓶颈,微财选择基于阿里云 EMR Serverless Spark 建立数据平台。通过 EMR Serverless Spark,微财突破了单机训练使用的数据规模瓶颈,大幅提升了训练效率,解决了存算分离架构下 Shuffle 稳定性和性能困扰,为智能风控等业务提供了强有力的技术支撑。
立马耀:通过阿里云 Serverless Spark 和 Milvus 构建高效向量检索系统,驱动个性化推荐业务
蝉妈妈旗下蝉选通过迁移到阿里云 Serverless Spark 及 Milvus,解决传统架构性能瓶颈与运维复杂性问题。新方案实现离线任务耗时减少40%、失败率降80%,Milvus 向量检索成本降低75%,支持更大规模数据处理,查询响应提速。
美的楼宇科技基于阿里云 EMR Serverless Spark 构建 LakeHouse 湖仓数据平台
美的楼宇科技基于阿里云 EMR Serverless Spark 建设 IoT 数据平台,实现了数据与 AI 技术的有效融合,解决了美的楼宇科技设备数据量庞大且持续增长、数据半结构化、数据价值缺乏深度挖掘的痛点问题。并结合 EMR Serverless StarRocks 搭建了 Lakehouse 平台,最终实现不同场景下整体性能提升50%以上,同时综合成本下降30%。
关于商品详情 API 接口 JSON 格式返回数据解析的示例
本文介绍商品详情API接口返回的JSON数据解析。最外层为`product`对象,包含商品基本信息(如id、name、price)、分类信息(category)、图片(images)、属性(attributes)、用户评价(reviews)、库存(stock)和卖家信息(seller)。每个字段详细描述了商品的不同方面,帮助开发者准确提取和展示数据。具体结构和字段含义需结合实际业务需求和API文档理解。
QuickSSO 与 ECreator 实操应用案例手册
本手册以企业 CRM 搭建与统一身份认证接入为场景,先说明环境要求与模块确认,再讲 ECreator 建 CRM 的应用、数据模型、页面及流程设计,后述 QuickSSO 认证中心配置、权限分配与测试,还提及效果验证与常见问题排查,助用户掌握二者协同应用。
EMR管控平台全面升级:智能化助力客户实现在离线混部和降本增效
本次介绍EMR开源大数据平台2.0的最新特性,基于微服务架构,提供更稳定高效的服务。平台升级主要体现在智能化和Serverless两个方面。智能化功能利用大语言模型提升运维效率,推出一键诊断和根因分析,缩短问题定位时间。全托管弹性伸缩根据业务动态自动调整资源,提高资源利用率。即将推出的EMR on ACS产品形态支持离在线业务混部,进一步优化资源使用,帮助用户实现降本增效。
拍立淘API是基于图像识别技术的服务接口,支持淘宝、1688和义乌购平台。
拍立淘API是基于图像识别技术的服务接口,支持淘宝、1688和义乌购平台。用户上传图片后,系统能快速匹配相似商品,提供精准搜索结果,并根据用户历史推荐个性化商品,简化购物流程。开发者需注册账号并获取API Key,授权权限后调用接口,返回商品详细信息如ID、标题、价格等。使用时需遵守频率限制,确保图片质量,保障数据安全。




