智能搜索推荐
推荐:如何批量根据PDF文件名批量查找PDF文件,复制到指定地方保存,通过文件名批量复制文件,按照文件名批量复制文件,根据文件名批量提取文件
该文介绍了一个批量查找PDF文件(不限于找PDF)的工具,用于在多级文件夹中快速查找并复制特定文件。通过下载提供的软件,用户可以加载PDF库,输入文件名列表,设置操作参数(如保存路径、复制或删除)及搜索模式。软件能高效执行,例如在1.1秒内完成对数千文件中的37个目标文件的复制,显著提升了工作效率,避免了手动逐个查找和复制的繁琐。
【网络安全】新的恶意软件:无文件恶意软件GhostHook正在广泛传播
GhostHook v1.0,一款由Native-One黑客组织开发的无文件浏览器恶意软件,正在网络犯罪论坛快速扩散,对多平台和浏览器构成威胁。这款恶意软件兼容Windows、Android、Linux和macOS,以及Google Chrome、Firefox、Opera和Edge等浏览器。它通过伪装的URL在社交论坛、邮件、即时消息和QR码中传播。无文件恶意软件利用内存驻留、系统工具和隐蔽性高的特点逃避检测,强调了对先进安全策略如EDR系统、网络监控和用户安全教育的需求。

OpenIM Bot: 用LLM构建企业专属的智能客服
OpenIM Bot 通过结合LLM和RAG技术,构建企业专属的智能客服系统。该系统通过优化向量存储、混合检索和查询分析,解决了LLM的幻觉、新鲜度、token长度和数据安全问题,提升了用户体验。向量存储和预处理步骤确保文档高质量,而混合检索结合文本和语义搜索,增强了检索结果的准确性。通过迭代优化,OpenIM Bot 提供了高效、智能的支持服务,减轻了支持团队的负担,提升了问题解决效率。
springsecurity和jwt区别
Spring Security是全面的安全框架,适用于多层认证授权的Web应用,提供丰富的认证授权功能和灵活配置。JWT则是轻量级的认证授权机制,基于JSON标准,常用于API调用中的身份验证。Spring Security侧重于复杂的权限管理,而JWT则以简洁高效著称。两者在使用时,Spring Security涉及用户认证授权和定制身份验证策略,JWT则涉及生成和匹配认证令牌。选择哪个取决于具体需求和应用场景。
linux必学的60个命令
Linux是强大操作系统,提供众多命令行工具,如安装登录(login, shutdown, install)、文件处理(file, mkdir, grep)和系统管理(df, top, kill)。此外,还包括网络操作(ifconfig, ping, telnet)和安全相关(passwd, su, chmod)命令。了解这些基础命令对于有效管理Linux系统至关重要。详细信息和特定用法可能因版本差异而变化,建议查阅相关文档。
linux必学的60个命令
Linux是一个功能强大的操作系统,提供了许多常用的命令行工具,用于管理文件、目录、进程、网络和系统配置等。以下是Linux必学的60个命令的概览,但请注意,这里可能无法列出所有命令的完整语法和选项,仅作为参考
【技术解析 | 实践】部署Kubernetes模式的Havenask集群
本次分享内容为havenask的kubernetes模式部署,由下面2个部分组成(部署Kubernetes模式Havenask集群、 Kubernetes模式相关问题排查),希望可以帮助大家更好了解和使用Havenask。
【一文看懂】Havenask单机模式创建
本次分享内容为Havenask单机模式,由下面3个部分组成(Hape工具介绍、创建单机版Havenask、Hape问题排查),希望可以帮助大家更好了解和使用Havenask。

【一文看懂】Havenask创建表
本次分享内容为Havenask的创建表,共3个部分组成(直写表与全量表、 创建直写表、创建全量表),希望可以帮助大家更好了解和使用Havenask。

【一文解读】阿里自研开源核心搜索引擎 Havenask简介及发展历史
本次分享内容为Havenask的简介及发展历史,由下面五个部分组成(Havenask整体介绍、名词解释、架构、代码结构、编译与部署),希望可以帮助大家更好了解和使用Havenask。
【技术解析 | 实践】Havenask-UDF定制
本节分享 Havenask UDF定制相关的内容,共包含3个部分,分关于 Havenask 的 UDF 相关的介绍、自定义 UDF 的开发及配置方法的介绍,最后将进行 UDF 定制的实际操作演示。
【深入浅出】阿里自研开源搜索引擎Havenask集群扩备份
本次分享内容为Havenask的集群扩备份,共2个部分组成(集群备份简介、 集群备份实践),希望可以帮助大家更好了解和使用Havenask。
【技术解析 | 实践】Havenask文本索引
本次分享内容为Havenask的文本索引,本次课程主要分为两部分内容,首先简要介绍倒排索引的数据结构和文本索引的特性,然后进行对文本索引配置不同分析器的实践,希望通过分享帮助大家更好了解和使用Havenask。
【一文看懂】使用hape部署分布式版Havenask
本次分享内容为使用hape部署分布式版Havenask,共2个部分组成(部署分布式版Havenask集群、 分布式相关问题排查),希望可以帮助大家更好了解和使用Havenask。
【Havenask实践篇】完整的性能测试
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。性能测试的目的在于评估搜索引擎在各种负载和条件下的响应速度、稳定性。通过模拟不同的用户行为和查询模式,我们可以揭示潜在的瓶颈、优化索引策略、调整系统配置,并确保Havenask在用户数量激增或数据量剧增时仍能保持稳定运行。本文举例对Havenask进行召回性能测试的一个简单场景,在搭建好Havenask服务并写入数据后,使用wrk对Havenask进行压测,查看QPS和查询耗时等性能指标。
阿里云OpenSearch RAG混合检索Embedding模型荣获C-MTEB榜单第一
阿里云OpenSearch引擎通过Dense和Sparse混合检索技术,在中文Embedding模型C-MTEB榜单上拿到第一名,超越Baichuan和众多开源模型,尤其在Retrieval任务上大幅提升。
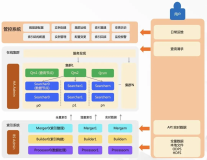
【Havenask实践篇】搭建文本检索服务
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文举例数据库检索加速的一个简单场景,使用Havenask对数据库的文本字段建立倒排索引,通过倒排检索列提高检索性能,缩短检索耗时。
【一文读懂】基于Havenask向量检索+大模型,构建可靠的智能问答服务
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内的几乎整个阿里的搜索业务。本文针对性介绍了Havenask作为一款高性能的召回搜索引擎,应用在向量检索和LLM智能问答场景的解决方案和核心优势。通过Havenask向量检索+大模型可以构建可靠的垂直领域的智能问答方案,同时快速在业务场景中进行实践及应用。

【技术解析 | 实践】Havenask分析器
本次分享内容为Havenask的分析器,本次课程主要分为3部分内容(分析器介绍、解释分析器主要配置、实战演示),希望本次通过分享帮助大家更好了解和使用Havenask。
【技术解析 | 实践】Havenask问题排查
本次分享内容为Havenask的问题排查,由下面4个部分组成(Hape运维脚本问题、集群相关问题、表相关问题、数据写入与查询问题),希望可以帮助大家更好了解和使用Havenask。
【深入浅出】阿里自研开源搜索引擎Havenask日志查询
本次分享内容为Havenask的日志查询,文章包含了具体查询步骤和举例、实操演示,希望可以帮助大家更好的使用Havenask。
【深入浅出】阿里自研开源搜索引擎Havenask变更表结构
本文介绍了Havenask的表结构变更,包括表结构简介、全量构建流程和变更表结构三个部分。表结构由schema配置,字段类型包括INT、FLOAT、STRING等,索引有倒排、正排和摘要索引。全量表变更会触发全量构建,完成后自动切换,但直写表不支持直接变更。变更过程涉及使用hape命令更新schema并触发全量build。最后还有全量构建的流程图和具体操作步骤。
【深入浅出】阿里自研开源搜索引擎Havenask集群扩分片
本次分享内容为Havenask的集群扩分片,共2个部分组成( 集群扩分片简介、 集群扩分片实践),希望可以帮助大家更好了解和使用Havenask。
【前沿技术】 阿里开源搜索引擎Havenask的消息系统
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了Havenask的消息系统--Swift,它是一个设计用于处理大规模的数据流和实时消息传递的高性能、可靠的消息系统。
阿里云向量检索服务:重塑大数据检索的未来
阿里云向量检索服务是一款强大且易于使用的云服务产品,专为大数据检索而设计。通过深度学习模型和高效的索引结构,该服务提供了快速、准确的检索能力,适用于多种业务场景。在评测中,我们对其功能、性能和业务场景适配性进行了全面评估,认为其具有出色的性能和良好的业务场景适配性。未来,阿里云向量检索服务有望持续发展和创新,拓展更多应用领域,为用户带来更加卓越的体验。
阿里云向量检索服务最佳实践测评
随着大数据和人工智能的快速发展,向量检索技术在各个领域的应用越来越广泛。阿里云作为国内领先的云计算服务提供商,也推出了自己的向量检索服务。本文将对阿里云的向量检索服务进行最佳实践测评,探讨其在语义检索、知识库搭建、AI多模态搜索等方面的应用,并与其它向量检索工具进行比较。
《揭秘,阿里开源自研搜索引擎Havenask的在线检索服务》
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了Havenask的在线检索服务,它具备高可用、高时效、低成本的优势,帮助企业和开发者量身定做适合业务发展的智能搜索服务。
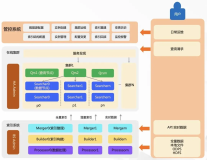
《Havenask分布式索引构建服务--Build Service》
Havenask是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了Havenask分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系统提升竞争力的一大利器。

Havenask进阶系列第4节:分词器开发
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍: 此视频为Havenask进阶系列课程第4课《分词器开发》,视频中共包含以下3部分内容。 分词器插件简介 内置分词器介绍 分词器实战开发 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云OpenSearch官网:https://www.aliyun.com/product/opensearch Havenask官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:

Havenask入门系列第10节:Havenask Kubernetes模式
hape工具参考:https://havenask.net/# /doc/sql/petool/intro kubernetes部署参考: https://havenask.net/# /doc/v1-2-0/sql/petool/startcluster/k8smode k8s模式问题排查:https://havenask.net/# /doc/v1-2-0/sql/petool/problem# k8s%E6%A8%A1%E5%BC%8F%E9%97%AE%E9%A2%98%E6%8E%92%E6%9F%A5 Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍:此视频为Havenask入门教程系列的第9节课《问题排查》,将对Havenask使用中4块内容进行讲解。 ● Hape运维脚本 ● 集群 ● 表创建 ● 数据写入与查询 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch 官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:78c5cfa61c64a55cdeb0655ac7eb2849.png

Havenask进阶系列第3节:UDF定制
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍: 此视频为Havenask进阶系列课程第3课《UDF定制》,视频中共包含以下3部分内容。 UDF介绍 UDF开发及配置讲解 实际操作演示 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云OpenSearch官网:https://www.aliyun.com/product/opensearch Havenask官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:

Havenask进阶系列第1节:文本索引
视频内的参考资料: https://havenask.net/# /doc/v1-1-0/sql/indexes/inverted https://havenask.net/# /doc/v1-1-0/sql/indexes/inverted# text%E7%B4%A2%E5%BC%95 Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍: 此视频为Havenask进阶系列课程第1课《文本检索》,共讲解2部分内容。 文本索引简介 文本索引实践 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云OpenSearch官网:https://www.aliyun.com/product/opensearch Havenask官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:

Havenask进阶系列第2节:分析器
视频内的参考材料: https://github.com/alibaba/havenask/tree/main/aios/plugins/havenask_plugins/analyzer_plugins Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于2022年11月对外正式开源,具有灵活的定制和开发能力,支持算法快速迭代,帮助客户和开发者量身定做适合自身业务的智能搜索服务,助力业务增长。 这次系列课程邀请了负责Havenask研发工作的技术专家们,为大家全面讲解Havenask的相关知识,通过课程可以了解到产品能力、架构原理、安装部署等内容,同时还有详细的操作演示,帮助大家更好了解和使用产品。 课程介绍: 此视频为Havenask进阶系列课程第2课《分析器》,共讲解4部分内容。 分析器介绍 解释分析器主要配置 实战演示 总结 我们期望通过课程可以帮助您更好的使用Havenask,欢迎广大开发者加入项目开发,共建高质量的搜索引擎,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。 此外,对于有使用需求的企业级开发者,我们也已在阿里云上提供了基于 Havenask 打造的全托管、免运维的一站式对话式搜索服务——阿里云 OpenSearch,欢迎企业级开发者们试用体验。 阿里云OpenSearch官网:https://www.aliyun.com/product/opensearch Havenask官网地址:https://havenask.net/ Github:https://github.com/alibaba/havenask 欢迎钉钉扫码加入 Havenask 开源官方技术交流群:

