









Redis应用—6.热key探测设计与实践
热key问题在高并发系统中可能导致数据层和服务层的严重瓶颈,如Redis集群瘫痪和用户体验下降。为解决此问题,京东开发了JdHotkey热key探测框架,具备实时性、准确性、集群一致性和高性能等特点。该框架由etcd集群、Client端jar包、Worker端集群和Dashboard控制台组成,通过分布式计算快速识别热key并推送至应用内存,有效减轻数据层负载,提升服务性能。JdHotkey适用于多种场景,安装部署简便,支持毫秒级热key探测和集群一致性维护。

Dify On DMS + 私有化 DeepSeek 使用样例
本视频介绍了开通Dify on DMS并完成私域的deepseek模型部署以后,如何使用Dify进行模型能力的配置和使用
淘宝APP分类API接口:开发、运用与收益全解析
淘宝APP作为国内领先的购物平台,拥有丰富的商品资源和庞大的用户群体。分类API接口是实现商品分类管理、查询及个性化推荐的关键工具。通过开发和使用该接口,商家可以构建分类树、进行商品查询与搜索、提供个性化推荐,从而提高销售额、增加商品曝光、提升用户体验并降低运营成本。此外,它还能帮助拓展业务范围,满足用户的多样化需求,推动电商业务的发展和创新。
如何通过电商 API 接口实现智能客服与用户互动?
随着电子商务的发展,企业对客户服务的需求激增。传统人工客服在高峰期难以应对大量咨询,导致效率低下和客户满意度下降。为此,越来越多的电商企业采用智能客服系统,通过电商API接口实现高效互动。本文探讨了如何利用电商API接口构建智能客服系统,介绍其技术组成、作用及实现策略,包括多渠道接入、优化交互界面、强化自然语言处理能力、个性化服务、提升自动化水平和监控分析等。同时,也讨论了面临的挑战与解决方案,强调统一API标准、加强数据安全和持续技术投入的重要性。最终,智能客服将为企业带来更高的服务效率和用户体验。
gbase8a centos8(kylinv10)加载报登录 ftp失败报错530 Login incorrect 排查过程及解决办法
centos8(kylinv10)加载报登录 ftp失败报错530 Login incorrect 排查过程及解决办法
足球比赛的镜头如何变成数据:从视频分析到实时数据应用
足球视频分析利用计算机视觉与深度学习技术,将比赛镜头转化为球员位置、动作及赛事事件等结构化数据,助力战术制定、表现评估与观赛体验升级,推动体育智能化发展。
Jetpack Compose中常见的核心概念总结-1
本教程涵盖Jetpack Compose基础布局、修饰符使用、状态管理、样式主题及动画实现,通过Kotlin代码示例讲解Column、Row布局及常用组件样式与交互处理。
mybatisplus一二级缓存
MyBatis-Plus 继承并优化了 MyBatis 的一级与二级缓存机制。一级缓存默认开启,作用于 SqlSession,适用于单次会话内的重复查询;二级缓存需手动开启,跨 SqlSession 共享,适合提升多用户并发性能。支持集成 Redis 等外部存储,增强缓存能力。
Java 从入门到实战完整学习路径与项目实战指南
本文详细介绍了“Java从入门到实战”的学习路径与应用实例,涵盖基础、进阶、框架工具及项目实战四个阶段。内容包括环境搭建、语法基础、面向对象编程,数据结构与算法、多线程并发、JVM原理,以及Spring框架等核心技术。通过学生管理系统、文件下载器和博客系统等实例,帮助读者将理论应用于实践。最后,提供全链路电商系统的开发方案,涉及前后端技术栈与分布式架构。附代码资源链接,助力成为合格的Java开发者。
客户说|保险极客引入阿里云AnalyticDB,多业务场景效率大幅提升
“通过引入AnalyticDB,我们在复杂数据查询和实时同步方面取得了显著突破,其分布式、弹性与云计算的优势得以充分体现,帮助企业快速响应业务变化,实现降本增效。AnalyticDB的卓越表现保障了保险极客数据服务的品质和效率。”

通过 PolarDB for PostgreSQL 实现一体化的 HTAP 能力
阿里云 PolarDB for PostgreSQL作为一款领先的云原生关系型数据库,利用向量化引擎+列存索引等技术实现了 OLTP 和 OLAP 的一体化。本方案为您展示如何通过 PolarDB for PostgreSQL 来实现一体化的 HTAP 能力。
Spring Boot 3.x 在 2.x基础上有什么重大的改进?
Spring Boot 3.x于2022年11月发布,带来了诸多重大更新。主要改进包括:最低要求Java 17,整合Jakarta EE 9,优化实例化和配置支持,基于Spring Framework 6.x,引入AOT编译,增强GraalVM原生映像支持,改进日志管理和集成测试,提供更详细的Actuator监控功能,以及对Spring Cloud的兼容性更新。这些变化为现代云原生应用开发提供了更强支持。
探究获取亚马逊畅销榜API接口及实战应用
亚马逊MWS(商城网络服务)提供了一系列API接口,帮助开发者获取平台数据,其中畅销榜API尤为关键。通过注册开发者账号、创建应用并申请权限,可使用HTTP POST请求获取商品的销售排名、价格等信息。Python代码示例展示了如何构建和发送请求,并处理返回的XML或JSON数据。注意遵守亚马逊的频率限制、数据准确性和合规性要求,以确保安全合法地利用这些数据支持电商业务决策。
【赵渝强老师】MongoDB的Journal日志
MongoDB通过Journal日志保证数据安全,记录检查点后的更新,确保数据库从异常中恢复到有效状态。每个Journal文件100M,存于--dbpath指定的journal子目录。默认已启用Journal日志,可通过--journal参数手动启用。WiredTiger存储引擎使用128KB内存缓冲区,异常关机时可能丢失最多128KB的数据。视频讲解和详细步骤参见附录。
南大通用 GBase 8s JDBC字符集参数详解
本文详细介绍了南大通用GBase 8s V8.8 数据中四个关键的JDBC字符集参数:CLIENT_LOCALE、DB_LOCALE、NEWCODESET和NEWLOCALE,涵盖它们的功能、配置方法及其在数据库操作中的作用,旨在帮助开发者和数据库管理员提升数据处理的效率与准确性。
【Java架构师体系课 | MySQL篇】① 全面理解MySQL架构设计
本文详解MySQL一条SQL查询与更新语句的执行流程,涵盖连接器、分析器、优化器、执行器及存储引擎层协作机制,并深入解析redo log与binlog日志如何通过两阶段提交保障数据一致性与恢复能力。
1688 拍立淘接口实战:从图像优化、工厂排序到供应链匹配(附可跑代码)
深耕B2B电商十余年,亲历1688拍立淘接口20+坑:从图像预处理、权限申请到工厂排序。本文详解核心参数、实战代码及多图验证、定制方案生成等高级技巧,助你实现“看图找厂”精准匹配,附可运行代码,新手也能少走两年弯路。
爬坑 10 年!京东店铺全量商品接口实战开发:从分页优化、SKU 关联到数据完整性闭环
本文详解京东店铺全量商品接口(jd.seller.ware.list.get)实战经验,涵盖权限申请、分页避坑、SKU关联、数据校验等核心难点,附Python代码与反限流策略,助你高效稳定获取完整商品数据,新手可少走两年弯路。

京东商品评论接口(jingdong.ware.comment.get)技术解析:数据拉取与情感分析优化
本文详解京东商品评论接口(jingdong.ware.comment.get)的技术对接全流程,涵盖核心字段解析、签名生成、请求参数配置及数据处理要点。针对签名失败、405错误、空数据等高频问题提供避坑方案,并结合Python代码实现结构化解析与情感分析优化,助力开发者高效集成,降低试错成本。
Java Web 在线商城项目最新技术实操指南帮助开发者高效完成商城项目开发
本项目基于Spring Boot 3.2与Vue 3构建现代化在线商城,涵盖技术选型、核心功能实现、安全控制与容器化部署,助开发者掌握最新Java Web全栈开发实践。
阿里云数据库:构建高性能与安全的数据管理系统
阿里云数据库提供RDS、PolarDB、Tair等核心产品,具备高可用、弹性扩展、安全合规及智能运维等技术优势,广泛应用于电商、游戏、金融等行业,助力企业高效管理数据,提升业务连续性与竞争力。
京东比价项目开发实录:京东API接口(2025)
本文分享了作者在电商开发中对接京东商品详情API的实战经验,涵盖了申请权限、签名算法、限流控制、数据解析等常见问题,并提供了亲测有效的Python代码示例,帮助开发者避坑。

在Dify on DMS上搭建专属版Deep Research Agent
在Dify on DMS上,构建企业专属版Deep Research Agent! 借用一下Dify的核心理念 Do It For Yourself,让我们换个思路:不再是把Deep Research Agent当成一个搞不懂的“黑箱”,而是亲手搭建一个看得懂、管得住、还能自由组合的“白盒”系统!
Lakehouse x AI ,打造智能 BI 新体验
本文整理自瓴羊的王璟尧老师与镜舟科技石强老师的联合分享,围绕 Quick BI 在智能 BI 场景中的落地实践,深入探讨了 StarRocks 如何凭借 MPP 架构、实时分析能力与 AI 原生支持,成为智能分析的理想 Lakehouse 引擎底座,助力 BI 从“被动查询”迈向“主动决策”,开启数据“会说话”的新体验。
服务器数据恢复—光纤存储上oracle数据库数据恢复案例
一台光纤服务器存储上有16块FC硬盘,上层部署了Oracle数据库。服务器存储前面板2个硬盘指示灯显示异常,存储映射到linux操作系统上的卷挂载不上,业务中断。 通过storage manager查看存储状态,发现逻辑卷状态失败。再查看物理磁盘状态,发现其中一块盘报告“警告”,硬盘指示灯显示异常的2块盘报告“失败”。 将当前存储的完整日志状态备份下来,解析备份出来的存储日志并获得了关于逻辑卷结构的部分信息。
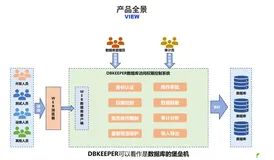
数据库安全管理新范式:DBKEEPER一体化数据库权限管控堡垒机解决方案
在数字化时代,数据库安全至关重要。DBKEEPER提供一站式数据库安全访问与权限管控解决方案,支持多种数据库,具备精细化权限管理、数据脱敏、高危操作拦截、全面审计等功能,助力企业实现智能、安全的数据治理,满足金融、医疗、互联网等行业合规需求。选择DBKEEPER,让数据库安全管理更高效!
瑶池数据库开放日:全新发布Data+AI能力家族,赋能企业全栈智能实践
近日,阿里云瑶池数据库生态工具产品重磅升级,推出“Data+AI能力家族”,并举办了为期3天的全栈智能实践开放日活动。发布会上首次公开了 “Data Agent for Analytics、Data Agent for Meta、DAS Agent”等瑶池数据库Data Agent系列能力,以工具智能化 × 智能化工具的双引擎重构数据与AI的协同边界,揭秘AI时代数据价值释放的全新路径。
客户说|知乎基于阿里云PolarDB,实现最大数据库集群云原生升级
近日,知乎最大的风控业务数据库集群,基于阿里云瑶池数据库完成了云原生技术架构的升级。此次升级不仅显著提升了系统的高可用性和性能上限,还大幅降低了底层资源成本。

可观测性方案怎么选?SelectDB vs Elasticsearch vs ClickHouse
基于 SelectDB 的高性能倒排索引、高吞吐量写入和高压缩存储,用户可以构建出性能高于Elasticsearch 10 倍的可观测性平台,并支持国内外多个云上便捷使用 SelectDB Cloud 的开箱即用服务。
数据管理DMS支持托管Dify正式开始公测啦!
数据管理DMS支持托管Dify正式开始公测啦!实现Data+AI深度集成开发。提供一站式解决方案,通过DMS使用Dify具备无需登录Dify账号、精选模型、一站式服务等优势,简化开发流程,提升效率。
JDK动态代理和CGLIB动态代理
Java动态代理允许在运行时创建代理对象,增强或拦截目标类方法的执行。主要通过两种方式实现:JDK动态代理和CGLIB动态代理。JDK动态代理基于接口,利用`java.lang.reflect.Proxy`类和`InvocationHandler`接口;CGLIB则通过字节码技术生成目标类的子类作为代理,适用于未实现接口的类。两者均用于在方法执行前后添加额外逻辑,如日志记录、权限控制等,广泛应用于AOP框架中。
数据管理服务DMS支持MySQL数据库的无锁结构变更
本文介绍了使用Sysbench准备2000万数据并进行全表字段更新的操作。通过DMS的无锁变更功能,可在不锁定表的情况下完成结构修改,避免了传统方法中可能产生的锁等待问题。具体步骤包括:准备数据、提交审批、执行变更及检查表结构,确保变更过程高效且不影响业务运行。
Go语言的网络编程与TCP_UDP
Go语言由Google开发,旨在简单、高效和可扩展。本文深入探讨Go语言的网络编程,涵盖TCP/UDP的基本概念、核心算法(如滑动窗口、流量控制等)、最佳实践及应用场景。通过代码示例展示了TCP和UDP的实现,并讨论了其在HTTP、DNS等协议中的应用。最后,总结了Go语言网络编程的未来发展趋势与挑战,推荐了相关工具和资源。

数据无界、湖仓无界,Apache Doris 湖仓一体典型场景实战指南(下篇)
Apache Doris 提出“数据无界”和“湖仓无界”理念,提供高效的数据管理方案。本文聚焦三个典型应用场景:湖仓分析加速、多源联邦分析、湖仓数据处理,深入介绍 Apache Doris 的最佳实践,帮助企业快速响应业务需求,提升数据处理和分析效率
ssm064农产品仓库管理系统系统(文档+源码)_kaic
农产品仓库管理系统基于现代经济快速发展和信息化技术的升级,采用SSM框架、Java语言及Mysql数据库开发。系统旨在帮助管理者高效处理大量数据信息,提升事务处理效率,实现数据管理的科学化与规范化。该系统涵盖物资基础数据管理、出入库订单管理等功能,界面简洁美观,符合用户操作习惯,并提供数据安全解决方案,确保信息的安全性和可靠性。通过自动化和集中处理,系统显著提高了仓库管理的效率和准确性。

RDS用多了,你还知道MySQL主从复制底层原理和实现方案吗?
随着数据量增长和业务扩展,单个数据库难以满足需求,需调整为集群模式以实现负载均衡和读写分离。MySQL主从复制是常见的高可用架构,通过binlog日志同步数据,确保主从数据一致性。本文详细介绍MySQL主从复制原理及配置步骤,包括一主二从集群的搭建过程,帮助读者实现稳定可靠的数据库高可用架构。
媒体声音|专访阿里云数据库周文超博士:AI就绪的智能数据平台设计思路
在生成式AI的浪潮中,数据的重要性日益凸显。大模型在实际业务场景的落地过程中,必须有海量数据的支撑:经过训练、推理和分析等一系列复杂的数据处理过程,才能最终产生业务价值。事实上,大模型本身就是数据处理后的产物,以数据驱动的决策与创新需要通过更智能的平台解决数据多模处理、实时分析等问题,这正是以阿里云为代表的企业推动 “Data+AI”融合战略的核心动因。
PolarDB-PG AI最佳实践3 :PolarDB AI多模态相似性搜索最佳实践
本文介绍了如何利用PolarDB结合多模态大模型(如CLIP)实现数据库内的多模态数据分析和查询。通过POLAR_AI插件,可以直接在数据库中调用AI模型服务,无需移动数据或额外的工具,简化了多模态数据的处理流程。具体应用场景包括图像识别与分类、图像到文本检索和基于文本的图像检索。文章详细说明了技术实现、配置建议、实战步骤及多模态检索示例,展示了如何在PolarDB中创建模型、生成embedding并进行相似性检索
阿里云DTS踩坑经验分享系列|DTS SelectDB链路最佳实践
大数据时代背景下,高效的数据流转与实时分析能力对于企业的竞争力至关重要。阿里云数据传输服务DTS与SelectDB联合,为用户提供了简单、实时、极速且低成本的事务数据分析方案。用户可以通过 DTS 数据传输服务,一键将自建 MySQL/PostgreSQL、RDS MySQL/PostgreSQL、PolarDB for MySQL/PostgreSQL 数据库,迁移或同步至阿里云数据库 SelectDB 的实例中,帮助企业在短时间内完成数据迁移或同步,并即时获得深度洞察。
SpringBoot 如何解决跨域问题?
本文深入探讨了Spring Boot解决跨域问题的方法,包括全局配置CORS、使用@CrossOrigin注解和自定义过滤器,提供了详细的代码示例和分析,帮助开发者有效应对Web开发中的跨域挑战。
StarRocks 4.0:基于 Apache Iceberg 的 Catalog 中心化访问控制
StarRocks 4.0 已正式发布!这一版本带来了多项关键升级。接下来,我们将以每周一篇的节奏,逐一解析 4.0 的核心新特性。 在多引擎协同访问同一数据湖的场景下,如何实现安全、统一且可审计的权限管理,是 Lakehouse 架构演进中的一项关键挑战。StarRocks 4.0 联合 Apache Iceberg,借助 REST Catalog 的统一治理能力与 JWT 身份认证、临时凭证机制(Vended Credential),为多引擎湖仓架构提供了一种全新的安全访问方式。

数据库
数据库领域前沿技术分享与交流



