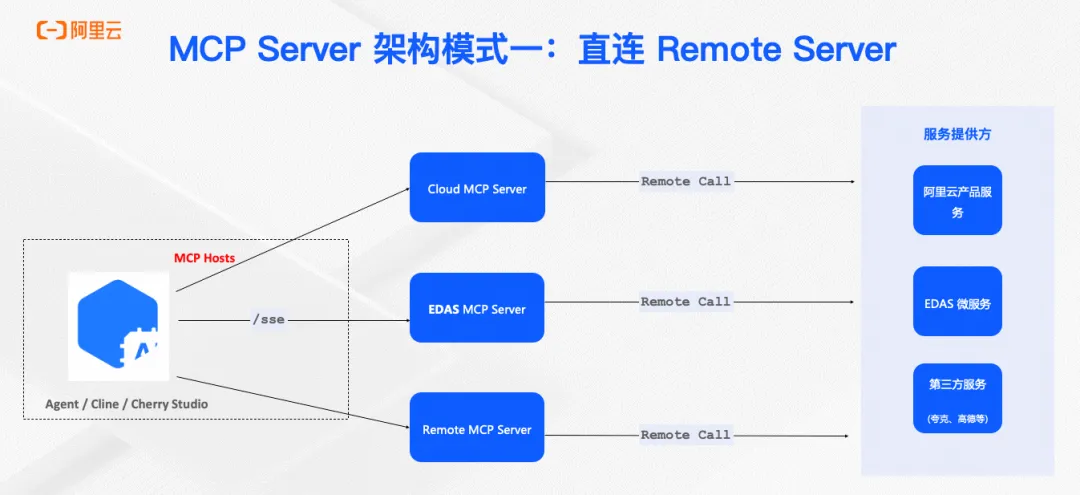
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。
本章我们将介绍如何利用大模型开发一个文档比对小工具,我们将用这个工具来给互联网上两篇内容相近但版本不同的文档找找茬,并且我们提供了一种批处理文档比对的方案
本文介绍了Ganos H3的相关功能,帮助读者快速了解Ganos地理网格的重要特性与应用实践。H3是Uber研发的一种覆盖全球表面的二维地理网格,采用了一种全球统一的、多层次的六边形网格体系来表示地球表面,这种地理网格技术在诸多业务场景中得到广泛应用。Ganos不仅提供了H3网格的全套功能,还支持与其它Ganos时空数据类型进行跨模联合分析,极大程度提升了客户对于时空数据的挖掘分析能力。
Nacos社区推出MCP Router与MCP Registry开源解决方案,助力AI Agent高效调用外部工具。Router可智能筛选匹配的MCP Server,减少Token消耗,提升安全性与部署效率。结合Nacos Registry实现服务自动发现与管理,简化AI Agent集成复杂度。支持协议转换与容器化部署,保障服务隔离与数据安全。提供智能路由与代理模式,优化工具调用性能,助力MCP生态普及。
阿里云OpenSearch LLM版推出DeepSearch技术,实现从RAG 1.0到RAG 2.0的升级。基于多智能体协同架构,支持复杂推理、多源检索与深度搜索,显著提升问答准确率,助力企业智能化升级。
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。

文章探讨了AI Agent的发展趋势,并通过一个实际案例展示了如何基于MCP(Model Context Protocol)开发一个支持私有知识库的问答系统。

本课程是阿里云百炼平台的第二天课程内容,旨在帮助用户了解如何通过阿里云百炼构建和发布自己的AI应用。介绍了如何利用大模型和智能体应用来创建具备强大语言理解和生成能力的AI助手,并通过不同的渠道(如网站、钉钉、微信公众号等)发布这些应用。
