2023年10月31日,杭州·云栖大会,阿里云技术主论坛带来了一场关于阿里云主力产品与技术创新的深度解读,阿里云网络产品线负责人祝顺民带来《云智创新,网络随行》的主题发言,针对阿里云飞天洛神云网络(下文简称洛神网络)领域产品服务创新以及背后的技术积累进行了深度解读,不少背后的创新技术系首次重磅披露。
本文会从浏览器插件应用场景切入,穿插插件基础能力和常见入口的介绍,核心回答如下三个问题:插件可以被使用在哪些场景?不同的使用场景我们的主要代码实现思路是怎样的?我们可以从哪些角度入手自己开发一款可以落地实用的浏览器插件?
作者一年前围绕设计模式与代码重构写了一篇《代码整洁之道 -- 告别码农,做一个有思想的程序员!》的文章。本文作为续篇,从测试角度谈程序员对软件质量的追求。
NSDI‘24于4月16-18日在美国圣塔克拉拉市举办,阿里云飞天洛神云网络首次中稿NSDI,两篇论文入选。其中《LuoShen: A Hyper-Converged Programmable Gateway for Multi-Tenant Multi-Service Edge Clouds》提出超融合网关LuoShen,基于Tofino、FPGA和CPU的新型硬件形态,将公有云VPC设施部署到边缘机柜中,实现小型化、低成本和高性能。该方案使成本降低75%,空间占用减少87%,并提供1.2Tbps吞吐量,展示了强大的技术竞争力。
MCP Specification 在 2025-03-26 发布了最新的版本,本文对主要的改动进行详细介绍和解释
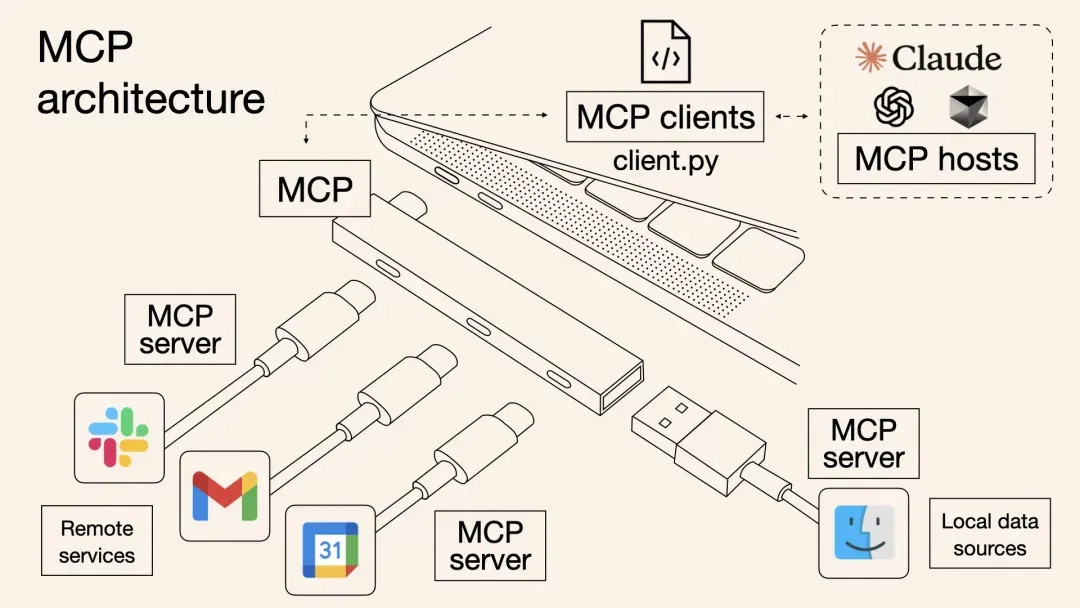
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。
本文介绍了如何使用 llmaz 快速部署基于 vLLM 的大语言模型推理服务,并结合 Higress AI 网关实现流量控制、可观测性、故障转移等能力,构建稳定、高可用的大模型服务平台。
简介:本文整理自阿里云高级技术专家李麟在Flink Forward Asia 2025新加坡站的分享,介绍了Flink 2.1 SQL在实时数据处理与AI融合方面的关键进展,包括AI函数集成、Join优化及未来发展方向,助力构建高效实时AI管道。
