Qwen3-Coder 是通义千问最新开源的 AI 编程大模型正式开源,拥有卓越的代码和 Agent 能力,在多领域取得了开源模型的 SOTA 效果。PAI 已支持最强版本 Qwen3-Coder-480B-A35B-Instruct 的云上一键部署。
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama 3 研究论文。

本文关于如何将非结构化数据(如PDF和Word文档)转换为结构化数据,以便于RAG(Retrieval-Augmented Generation)系统使用。
Hey,小伙伴!你是不是总是下定了学习编程的决心,但又因为枯燥、困难打起了退堂鼓?今天让我们跟着通义灵码边玩边练,只需要简单的几句话,就可以打造一款经典的数字华容道小游戏,即使没有代码基础也能快速上手,也许在这个过程中,你不经意间就掌握了一些编程知识。让我们开始吧!
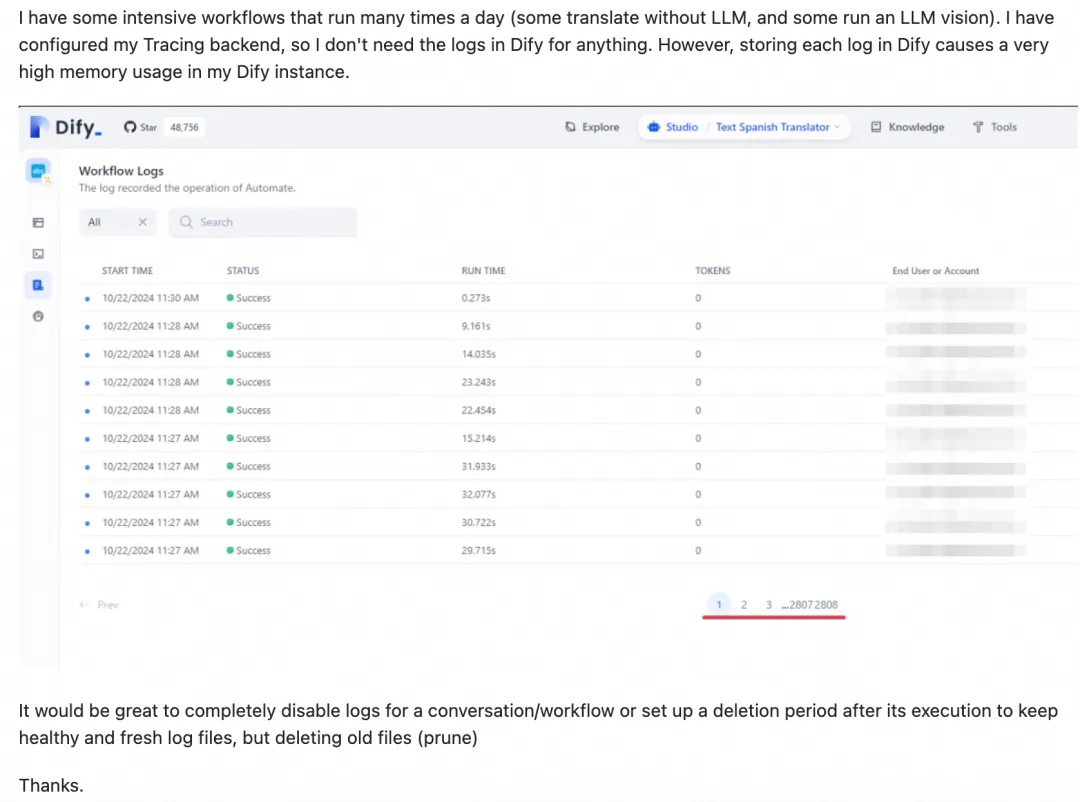
Dify是一款开源的大模型应用开发平台,支持通过可视化界面快速构建AI Agent和工作流。然而,Dify本身缺乏定时调度与监控报警功能,且执行记录过多可能影响性能。为解决这些问题,可采用Dify Schedule或XXL-JOB集成Dify工作流。Dify Schedule基于GitHub Actions实现定时调度,但仅支持公网部署、调度延时较大且配置复杂。相比之下,XXL-JOB提供秒级调度、内网安全防护、限流控制及企业级报警等优势,更适合大规模、高精度的调度需求。两者对比显示,XXL-JOB在功能性和易用性上更具竞争力。

在本文中,我们将详细介绍两种在业务中实践的优化策略:多轮对话间的 KV cache 复用技术和投机采样方法。我们会细致探讨这些策略的应用场景、框架实现,并分享一些实现时的关键技巧。
前言分布式数据库能够解决海量数据存储、超高并发吞吐、大表瓶颈以及复杂计算效率等单机数据库瓶颈难题,当业务体量即将突破单机数据库承载极限和单表过大导致性能、维护问题时,分布式数据库是解决上述问题的高性价比方案。数据库作为分布式改造的最大难点,就是"和使用单机数据库一样使用分布式数据库",这也一直是广大...

写这篇文章的初衷:作为一个AI小白,把我自己学习大模型的学习路径还原出来,包括理解的逻辑、看到的比较好的学习材料,通过一篇文章给串起来,对大模型建立起一个相对体系化的认知,才能够在扑面而来的大模型时代,看出点门道。
