PolarDB-X 是阿里云推出的云原生分布式数据库,自2021年10月开源以来,持续迭代升级,至2024年4月发布的v2.4.1版本,重点增强了企业级运维能力,如无锁变更、物理扩缩容、数据TTL等,提供金融级高可用、透明分布式、HTAP一体化等特性。PolarDB-X 支持集中式和分布式一体化形态,兼容MySQL生态,适用于金融、通信、政务等行业。
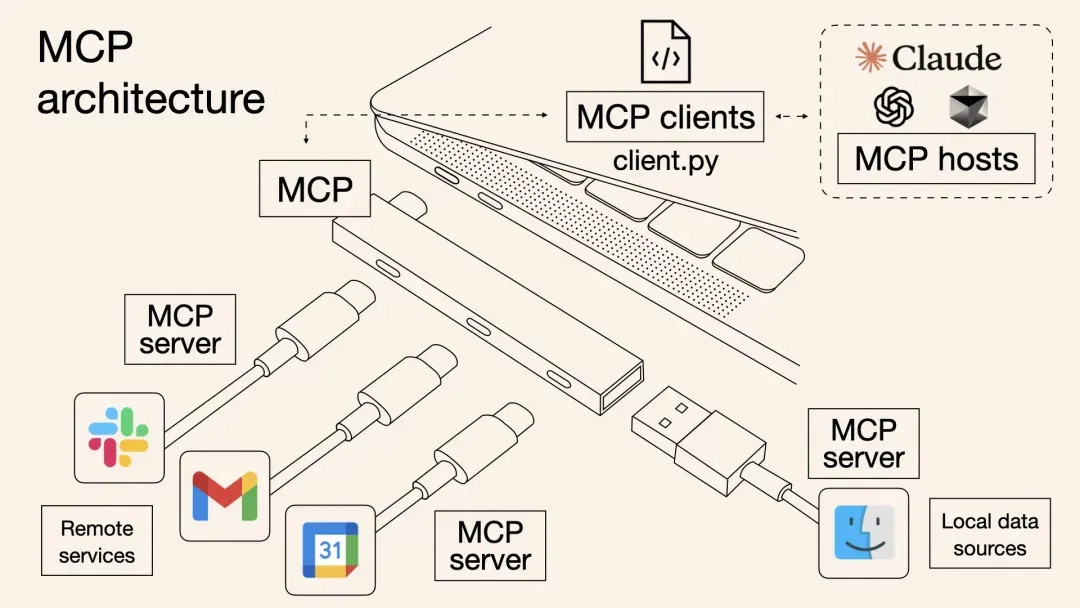
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。
本文主要介绍通过KMS密钥管理服务产生的密钥对敏感的AK等数据进行加密之后可以有效解决泄漏带来的安全风险问题,其次通过KMS凭据托管的能力直接将MSE的主AK进行有效管理,保障全链路无AK的业务体验,真正做到安全、可控。
今天,来自 Qwen1.5 开源家族的新成员,代码专家模型 CodeQwen1.5开源!CodeQwen1.5 基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了优秀的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
阿里云云原生数据仓库AnalyticDB MySQL(ADB-M)与被OpenAI收购的实时分析数据库Rockset对比,两者在架构设计上有诸多相似点,例如存算分离、实时写入等,但ADB-M在多个方面展现出了更为成熟和先进的特性。ADB-M支持更丰富的弹性能力、强一致实时数据读写、全面的索引类型、高吞吐写入、完备的DML和Online DDL操作、智能的数据生命周期管理。在向量检索与分析上,ADB-M提供更高检索精度。ADB-M设计原理包括分布式表、基于Raft协议的同步层、支持DML和DDL的引擎层、高性能低成本的持久化层,这些共同确保了ADB-M在AI时代作为实时数据仓库的高性能与高性价比
PolarDB-X 分布式数据库,采用集中式和分布式一体化的架构,为了能够灵活应对混合负载业务,作为数据存储的 Data Node 节点采用了多种数据结构,其中使用行存的结构来提供在线事务处理能力,作为 100% 兼容 MySQL 生态的数据库,DN 在 InnoDB 的存储结构基础上,进行了深度优化,大幅提高了数据访问的效率。
本次分享意在帮助用户更加全面、深入地了解百炼的核心产品能力,并通过实际操作学会如何快速将大模型与自己的系统及应用相结合。主要包括以下三个方面: 1. 阿里云百炼产品定位和能力简介 2. 知识检索 RAG 智能体应用能力和优势 3. 最佳落地案例实践分享
接下来,人与智能体的交互将变得更为紧密,比如 N 年以后是否可以逐渐过渡。这个逐渐过渡的过程实际上是温和的,从依赖人类到依赖超大规模算力的转变,可能会取代我们的一些职责。这不仅仅是简单的叠加关系。对于AI和超大规模算力,这是否意味着我们可以大幅度提升软件质量,是否可以缩短研发周期并提高效率,还有创造出更优质的软件并持续发展,这无疑是肯定的。
Dify 是面向 AI 时代的开源大语言模型应用开发平台,GitHub Star 数超 10 万,为 LLMOps 领域增长最快项目之一。然而其在 MCP 协议集成、Prompt 敏捷调整及运维配置管理上存在短板。Nacos 3.0 作为阿里巴巴开源的注册配置中心,升级支持 MCP 动态管理、Prompt 实时变更与 Dify 环境变量托管,显著提升 Dify 应用的灵活性与运维效率。通过 Nacos,Dify 可动态发现 MCP 服务、按需路由调用,实现 Prompt 无感更新和配置白屏化运维,大幅降低 AI 应用开发门槛与复杂度。
