本文深入探讨了Agent智能体的概念、技术挑战及实际落地方法,涵盖了从狭义到广义的Agent定义、构建过程中的四大挑战(效果不稳定、规划权衡、领域知识集成、响应速度),并提出了相应的解决方案。文章结合阿里云服务领域的实践经验,总结了Agent构建与调优的完整路径,为推动Agent在To B领域的应用提供了有价值的参考。

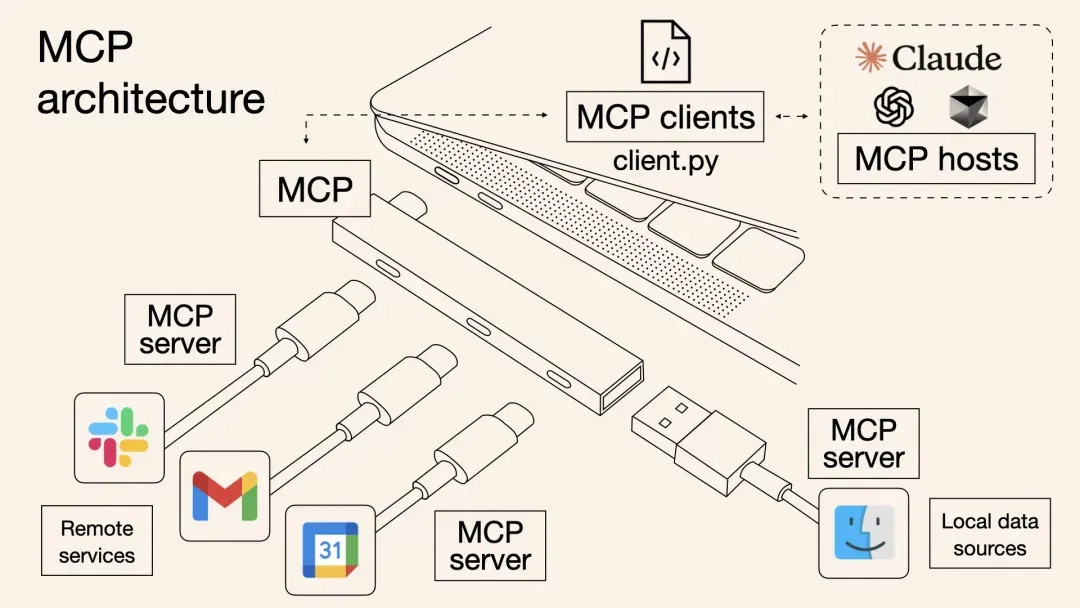
通义灵码现已全面支持Qwen3,新增智能体模式,具备自主决策、环境感知、工具使用等能力,可端到端完成编码任务。支持问答、文件编辑、智能体多模式自由切换,结合MCP工具与记忆功能,提升开发效率。AI IDE重构编程流程,让开发更智能高效。
本文介绍了如何使用通义灵码编程智能体与高德 MCP 2.0 制作北京端午3天旅行攻略页面。首先需下载通义灵码 AI IDE 并获取高德申请的 key,接着通过添加 MCP 服务生成 travel_tips.html 文件,最终在手机端查看已发布上线的攻略。此外还详细说明了利用通义灵码打造专属 MCP 服务的过程,包括开发计划、代码编写、部署及连接服务等步骤,并提供了自由探索的方向及相关资料链接。
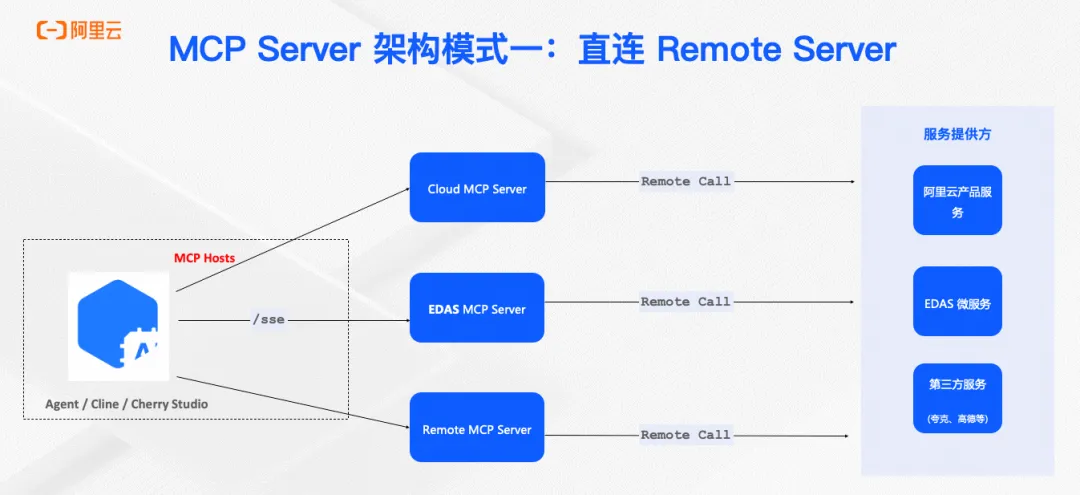
本文将深入剖析 MCP Server 的五种主流架构模式,并结合 Nacos 服务治理框架,为企业级 MCP 部署提供实用指南。
本文深入探讨了Model Context Protocol (MCP) 在企业级环境中的部署与管理挑战,详细解析了五种主流MCP架构模式(直连远程、代理连接远程、直连本地、本地代理连接本地、混合模式)的优缺点及适用场景,并结合Nacos服务治理框架,提供了实用的企业级MCP部署指南。通过Nacos MCP Router,实现MCP服务的统一管理和智能路由,助力金融、互联网、制造等行业根据数据安全、性能需求和扩展性要求选择合适架构。文章还展望了MCP在企业落地的关键方向,包括中心化注册、软件供应链控制和安全访问等完整解决方案。
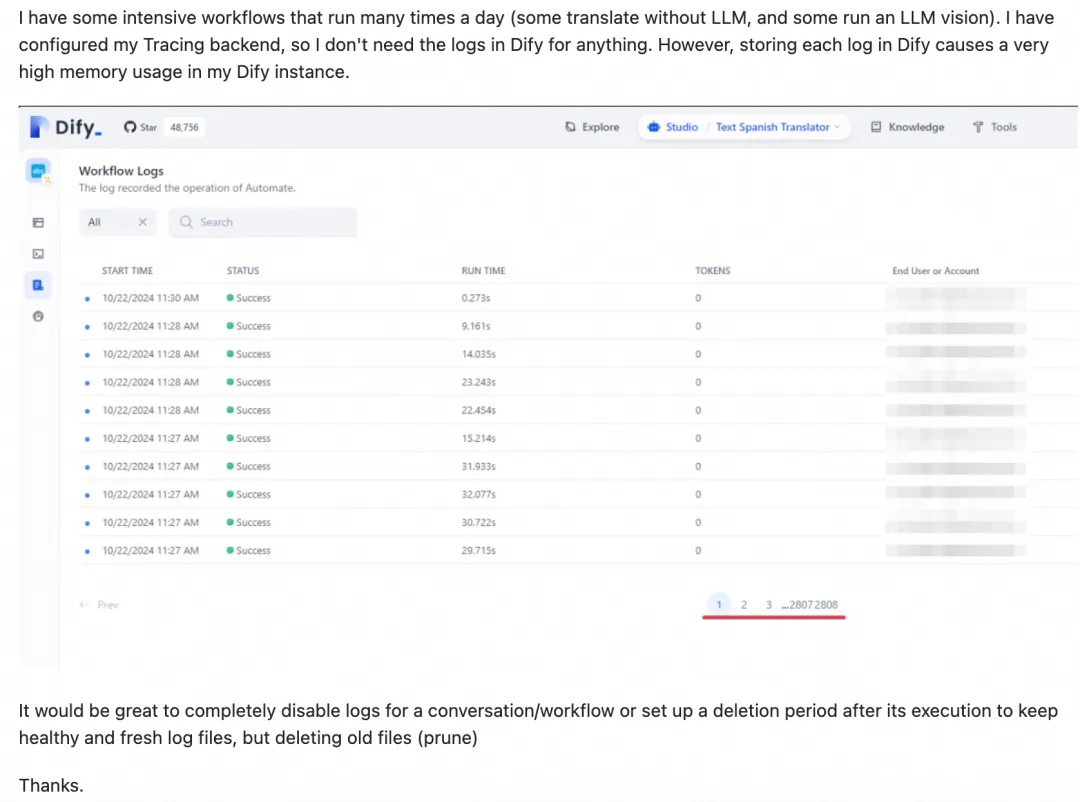
Dify是一款开源的大模型应用开发平台,支持通过可视化界面快速构建AI Agent和工作流。然而,Dify本身缺乏定时调度与监控报警功能,且执行记录过多可能影响性能。为解决这些问题,可采用Dify Schedule或XXL-JOB集成Dify工作流。Dify Schedule基于GitHub Actions实现定时调度,但仅支持公网部署、调度延时较大且配置复杂。相比之下,XXL-JOB提供秒级调度、内网安全防护、限流控制及企业级报警等优势,更适合大规模、高精度的调度需求。两者对比显示,XXL-JOB在功能性和易用性上更具竞争力。
本文介绍了一种基于阿里云计算巢的一站式MCP工具解决方案,解决了传统MCP工具集成中的效率低下、调用方式割裂和动态管理困难等问题。方案通过标准化协议实现多MCP工具批量部署,提高云资源利用率,并支持OpenAPI与MCP双通道调用,使主流AI助手如Dify、Cherry Studio等无缝接入。内容涵盖背景、原理剖析、部署使用实战及问题排查,最后强调MCP协议作为“通用语言”连接数字与物理世界的重要性。