









Flink 流批一体的实践与探索
作为 Dataflow 模型的最早采用者之一,Apache Flink 在流批一体特性的完成度上在开源项目中是十分领先的。本文将基于社区资料和笔者的经验,介绍 Flink 目前(1.10)流批一体的现状以及未来的发展规划。

打击黑灰产的利器 —— 图神经网络(GNN)
阿里巴巴安全部数据与算法团队一直致力于与黑灰产进行对抗,保障用户在淘宝、天猫、闲鱼等平台上的使用体验和切身利益。面对狡猾的黑灰产,我们研究出了一系列算法武器,图神经网络(GNN)是其中重要的防控技术。本文结合阿里开源GNN框架Graph-Learn(https://github.com/alibaba/graph-learn)进行介绍。
日均万亿条数据如何处理?爱奇艺实时计算平台这样做
本文由爱奇艺大数据服务负责人梁建煌分享,介绍爱奇艺如何基于 Apache Flink 技术打造实时计算平台,并通过业务应用案例分享帮助用户了解 Apache Flink 的技术特点及应用场景。

覆盖电商、推荐、ETL、风控等多场景,网易的实时计算平台做了啥?
目前网易流计算规模已经达到了一千多个任务,2 万多个 vcores 以及 80 多 T 的内存,网易流计算覆盖了绝大多数场景,包括广告、电商大屏、ETL、数据分析、推荐、风控、搜索、直播等。

小红书如何实现高效推荐?解密背后的大数据计算平台架构
小红书作为生活分享类社区,目前有8500万用户,年同比增长为300%,大约每天有30亿条笔记在发现首页进行展示。推荐是小红书非常核心且重要的场景之一,本文主要分享在推荐业务场景中小红书的实时计算应用。

日均处理万亿数据!Flink在快手的应用实践与技术演进之路
本次的分享包括以下三个部分: 1. 介绍 Flink 在快手的应用场景以及目前规模; 2. 介绍 Flink 在落地过程的技术演进过程; 3. 讨论 Flink 在快手的未来计划。
HDFS Federation简介
背景 熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下: 从上面可以看出 HDFS 的架构其实大致可以分为两层: Namespace:由目录,文件和数据块组成,支持常见的文件系统操作,例如创建,删除,修改和列出文件和目录。
MaxCompute 费用暴涨之新增SQL分区裁剪失败
现象:因业务需求新增了SQL任务,这SQL扫描的表为分区表,且SQL条件里表只指定了一个分区,按指定的分区来看数据量并不大,但是SQL的费用非常高。费用比预想的结果相差几倍甚至10倍以上。 若只知道总体费用暴涨,但是没明确是什么任务暴涨,可以可以参考查看账单详情-使用记录文档,找出费用异常的记录。
十年磨一剑,阿里巴巴推荐与搜索深度学习服务体系AI·OS在云栖大会正式亮相
2018年9月21~22日,在以“驱动数字科技”为主题的云栖大会上,阿里巴巴搜索事业部特别推出了“搜索推荐专场”,“推荐与搜索引擎AI·OS专场”,深度参与了这场科技盛宴。 阿里巴巴推荐与搜索引擎平台支持了包括淘宝、天猫、菜鸟、优酷以及海外电商在内的整个阿里集团的推荐与搜索业务,引导成交占据了集团GMV的绝大部分份额。
实时计算 Flink SQL 核心功能解密
Flink SQL 是于2017年7月开始面向集团开放流计算服务的。虽然是一个非常年轻的产品,但是到双11期间已经支撑了数千个作业,在双11期间,Blink 作业的处理峰值达到了5+亿每秒,而其中仅 Flink SQL 作业的处理总峰值就达到了3亿/秒。
HAS-插件式Kerberos认证框架
HAS (Hadoop Authentication Service), 致力于解决开源大数据服务和生态系统的认证支持。目前开源大数据(Hadoop/Spark)在安全认证上只内置支持了Kerberos方式,HAS提出了一种新的认证方式, 通过与现有的认证和授权体系进行对接,使得在Hadoop/Spark在上面支持Kerberos以外的认证方式变成可能,并对最终用户简化和隐藏Kerberos的复杂性。
大数据环境下该如何优雅地设计数据分层
发个牢骚,搞大数据的也得建设数据仓库吧。而且不管是传统行业还是现在的互联网公司,都需要对数据仓库有一定的重视,而不是谈一句自己是搞大数据的就很厉害了。数据仓库更多代表的是一种对数据的管理和使用的方式,它是一整套包括了etl、调度、建模在内的完整的理论体系。
大规模数据的分布式机器学习平台
来自阿里云IDST褚崴为大家带来分布式机器学习平台方面的内容,主要从大数据的特点和潜在价值开始讲起,然后介绍阿里的业务场景中常用到的机器学习算法,以及阿里采用的分布式机器学习框架,最后介绍了PAI算法平台,一起来看下吧。
大数据workshop:《云数据·大计算:海量日志数据分析与应用》之《社交数据分析:好友推荐》篇
本手册为云栖大会Workshop《云计算·大数据:海量日志数据分析与应用》的《社交数据分析:好友推荐》篇而准备。主要阐述如何在大数据开发套件中使用MR实现好友推荐。
飞天5K实战经验:大规模分布式系统运维实践
传统的运维人员通常只面对几十或者上百台的服务器,但在大规模分布式集群中,运维人员面临工作任务明显不同。本文分别阐述服务器数量激增,要求提升全局掌控能力,如何实现系统的自我保护和自动化恢复,大规模与精细化平衡,以及需要开发和运维更加紧密合作等方面,通过对真实数据进行分析和预测,将判断失误概率降到最低。

Spark 批处理调优这点事:资源怎么要、Shuffle 怎么省、序列化怎么选?我用这些年踩过的坑告诉你
Spark 批处理调优这点事:资源怎么要、Shuffle 怎么省、序列化怎么选?我用这些年踩过的坑告诉你
金融对话AI:伦敦证券交易所集团携手OpenAI重塑市场数据分析
2025年12月,LSEG与OpenAI达成战略合作,将金融数据接入ChatGPT,通过自然语言实现行情查询、估值分析等功能,推动金融分析民主化。借助MCP技术,用户可直观获取专业研报与实时数据,降低使用门槛。此举标志金融服务向智能化、直觉化转型,但也面临安全与合规挑战。#金融科技 #AI变革
闲鱼商品详情API完整指南
闲鱼商品详情API(goodfish.item_get)通过商品ID获取商品信息,支持GET请求,返回JSON格式数据,包含商品、卖家、图片视频等详情,适用于多场景开发,需遵守调用限制与合规要求。
1688商品详情API完整指南
1688商品详情API是阿里巴巴B2B平台提供的数据接口,支持获取商品ID、标题、图片、价格、库存、销量等核心信息。通过HTTP请求与AppKey认证,开发者可批量获取数据,实现商品同步、价格监控与库存管理,助力企业自动化运营,提升电商效率。
低代码开发启蒙教程
低代码通过拖拽组件与可视化配置快速构建应用,支持数据编排、流程设计与多端发布,适用于OA系统、智能客服等场景,结合少量代码可扩展复杂功能,提升开发效率80%。
京东商品列表API实战:关键词搜索与数据获取全指南
京东商品列表API是京东开放平台的核心接口,支持通过关键词搜索获取商品数据,适用于电商分析、竞品监控等场景。具备分类筛选、价格区间、多维度排序和分页功能,采用HTTPS请求,返回JSON格式数据,包含商品ID、名称、价格、销量等信息,支持高并发与实时更新。
构建AI智能体:十一、语义分析Gensim — 从文本处理到语义理解的奇妙之旅
Gensim是Python中强大的自然语言处理库,擅长从大量中文文本中自动提取主题、生成词向量并计算文档相似度。它支持LDA、Word2Vec等模型,结合jieba分词可有效实现文本预处理、主题建模与语义分析,适用于新闻分类、信息检索等任务,高效且易于扩展。
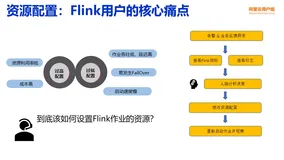
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。

氛围编程陷阱:为什么AI生成代码正在制造大量"伪开发者"
AI兴起催生“氛围编程”——用自然语言生成代码,看似高效实则陷阱。它让人跳过编程基本功,沦为只会提示、不懂原理的“中间商”。真实案例显示,此类项目易崩溃、难维护,安全漏洞频出。AI是技能倍增器,非替代品;真正强大的开发者,永远是那些基础扎实、能独立解决问题的人。
Kubeflow-KServe-架构学习指南
KServe是基于Kubernetes的生产级AI推理平台,支持多框架模型部署与管理。本指南从架构解析、代码结构到实战部署,系统讲解其核心组件如InferenceService、控制器模式及与Knative、Istio集成原理,并提供学习路径与贡献指南,助你快速掌握云原生AI服务技术。

SAPO去中心化训练:多节点协作让LLM训练效率提升94%
SAPO(Swarm Sampling Policy Optimization)提出去中心化异步强化学习框架,通过节点间共享rollouts提升大模型后训练效率。实验显示,在数千节点上可实现94%回报提升,尤其助力中等规模模型突破性能瓶颈。
基于python大数据的招聘数据可视化分析系统
本系统基于Python开发,整合多渠道招聘数据,利用数据分析与可视化技术,助力企业高效决策。核心功能包括数据采集、智能分析、可视化展示及权限管理,提升招聘效率与人才管理水平,推动人力资源管理数字化转型。
基于深度学习的音乐推荐系统
本文探讨了信息过载背景下推荐系统的发展与应用,重点研究基于卷积神经网络的音乐推荐系统设计与实现。内容涵盖推荐系统的发展历程、技术架构及在音乐领域的应用,介绍了系统开发中使用的Python、MySQL与B/S结构等关键技术,并提出了通过输入文字实现音乐推荐的解决方案,旨在提升用户个性化音乐获取效率。

新闻网站的数据采集与更新思路
该方案设计了一个跨站点的增量更新引擎,用于高效采集央视新闻、中国新闻网和环球网等多源新闻数据。通过代理IP和内容哈希签名技术,实现新闻的新增与更新检测,大幅降低冗余抓取和带宽消耗。实验表明,该方法在多源新闻采集中具备高效性和实用性,可拓展为行业级舆情雷达系统,支持事件追踪与趋势分析。
Apache InLong:构建10万亿级数据管道的全场景集成框架
Apache InLong(应龙)是一站式、全场景海量数据集成框架,支持数据接入、同步与订阅,具备自动、安全、可靠和高性能的数据传输能力。源自腾讯大数据团队,现为 Apache 顶级项目,广泛应用于广告、支付、社交等多个领域,助力企业构建高效数据分析与应用体系。
抖音集团基于Paimon的流式数据湖应用实践
本文整理自抖音集团数据工程师在Flink Forward Asia 2024的分享,围绕流式湖仓架构的背景、实践与未来展望展开。内容涵盖实时数仓架构演进、Paimon的应用与优化,以及在长周期指标计算和大流量场景下的落地实践经验。
Java 大视界 -- Java 大数据机器学习模型在游戏用户行为分析与游戏平衡优化中的应用(190)
本文探讨了Java大数据与机器学习模型在游戏用户行为分析及游戏平衡优化中的应用。通过数据采集、预处理与聚类分析,开发者可深入洞察玩家行为特征,构建个性化运营策略。同时,利用回归模型优化游戏数值与付费机制,提升游戏公平性与用户体验。
Java 大视界 -- Java 大数据在智能农业温室环境调控与作物生长模型构建中的应用(189)
本文探讨了Java大数据在智能农业温室环境调控与作物生长模型构建中的关键应用。通过高效采集、传输与处理温室环境数据,结合机器学习算法,实现温度、湿度、光照等参数的智能调控,提升作物产量与品质。同时,融合多源数据构建精准作物生长模型,助力农业智能化、精细化发展,推动农业现代化进程。
借助最新技术构建 Java 邮件发送功能的详细流程与核心要点分享 Java 邮件发送功能
本文介绍了如何使用Spring Boot 3、Jakarta Mail、MailHog及响应式编程技术构建高效的Java邮件发送系统,涵盖环境搭建、异步发送、模板渲染、测试与生产配置,以及性能优化方案,助你实现现代化邮件功能。
Java 学习路线 35 掌握 List 集合从入门到精通的 List 集合核心知识
本文详细解析Java中List集合的原理、常用实现类(如ArrayList、LinkedList)、核心方法及遍历方式,并结合数据去重、排序等实际应用场景,帮助开发者掌握List在不同业务场景下的高效使用,提升Java编程能力。
淘宝关键词搜索商品列表API接入指南(含Python示例)
淘宝关键词搜索商品列表API是淘宝开放平台的核心接口,支持通过关键词检索商品,适用于比价、选品、市场分析等场景。接口提供丰富的筛选与排序功能,返回结构化数据,含商品ID、标题、价格、销量等信息。开发者可使用Python调用,需注意频率限制与错误处理,建议先在沙箱环境测试。
Java 大学期末考试真题与答案 含知识点总结 重难点归纳及题库汇总 Java 期末备考资料
本文汇总了Java大学期末考试相关资料,包含真题与答案、知识点总结、重难点归纳及题库,涵盖Java基础、面向对象编程、异常处理、IO流等内容,并提供完整代码示例与技术方案,助你高效复习备考。
Spark SQL架构及高级用法
Spark SQL基于Catalyst优化器与Tungsten引擎,提供高效的数据处理能力。其架构涵盖SQL解析、逻辑计划优化、物理计划生成及分布式执行,支持复杂数据类型、窗口函数与多样化聚合操作,结合自适应查询与代码生成技术,实现高性能大数据分析。

数据分布不明确?5个方法识别数据分布,快速找到数据的真实规律
本文深入探讨了数据科学中分布识别的重要性及其实践方法。作为数据分析的基础环节,分布识别影响后续模型性能与分析可靠性。文章从直方图的可视化入手,介绍如何通过Python代码实现分布特征的初步观察,并系统化地讲解参数估计、统计检验及distfit库的应用。同时,针对离散数据、非参数方法和Bootstrap验证等专题展开讨论,强调业务逻辑与统计结果结合的重要性。最后指出,正确识别分布有助于异常检测、数据生成及预测分析等领域,为决策提供可靠依据。作者倡导在实践中平衡模型复杂度与实用性,重视对数据本质的理解。

HarmonyOS实战:腾讯IM之消息删除、撤回和重发(三)
本文详细介绍了鸿蒙 IM 聊天中实现消息撤回、删除和重发功能的方法。消息撤回支持在 120 秒内召回自己发送的消息,通过 `revokeMessage` 方法实现;消息删除使用 `deleteMessage` 方法清除本地与云端记录;消息重发则先删除失败消息再重新发送,并处理用户被拉黑的异常情况。结合状态管理,可轻松实现类似微信的功能,建议点赞收藏并动手实践!

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
