








号称能打败MLP的KAN到底行不行?数学核心原理全面解析
Kolmogorov-Arnold Networks (KANs) 是一种新型神经网络架构,挑战了多层感知器(mlp)的基础,通过在权重而非节点上使用可学习的激活函数(如b样条),提高了准确性和可解释性。KANs利用Kolmogorov-Arnold表示定理,将复杂函数分解为简单函数的组合,简化了神经网络的近似过程。与mlp相比,KAN在参数量较少的情况下能达到类似或更好的性能,并能直观地可视化,增强了模型的可解释性。尽管仍需更多研究验证其优势,KAN为深度学习领域带来了新的思路。

高效获取淘宝商品详情:API 开发实现链接解析的完整技术方案
2025反向海淘新机遇:依托代购系统,聚焦小众垂直品类,结合Pandabay数据选品,降本增效。系统实现智能翻译、支付风控、物流优化,助力中式养生茶等品类利润翻倍,新手也能快速入局全球市场。
Java“找不到符号” 错误怎么查找解决
“找不到符号”是Java编程中常见的编译错误,通常表明代码试图访问未声明或不可见的符号(如类、方法或变量)。解决此问题需检查拼写、导入包是否正确及作用域是否合适。确保使用正确的类路径和库,可有效避免此类错误。若问题依旧,查阅官方文档或使用调试工具定位错误亦为良策。

概率分布深度解析:PMF、PDF和CDF的技术指南
本文将深入探讨概率分布,详细阐述概率质量函数(PMF)、概率密度函数(PDF)和累积分布函数(CDF)这些核心概念,并通过实际示例进行说明。
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
京东商品详情API:从签名生成到JSON解析的完整实战指南
京东商品详情API是京东开放平台的核心接口,提供实时、准确的商品信息获取服务。支持查询商品基础信息、价格库存、SKU规格及销量评价等120+字段,数据延迟≤30秒,单次最多查询200个SKU,适用于价格监控、库存管理等场景。采用HTTP/HTTPS请求,返回标准化JSON格式,便于集成,助力电商数据高效采集与应用。
淘宝商品详情API赋能电商数据模型:从SKU分析到销量预测
淘宝商品详情API(taobao.item.get)通过商品ID实时获取标题、价格、库存等数据,支持RESTful风格与OAuth2.0认证,具备高实时性、字段定制和防封禁机制,适用于比价、库存监控等场景。
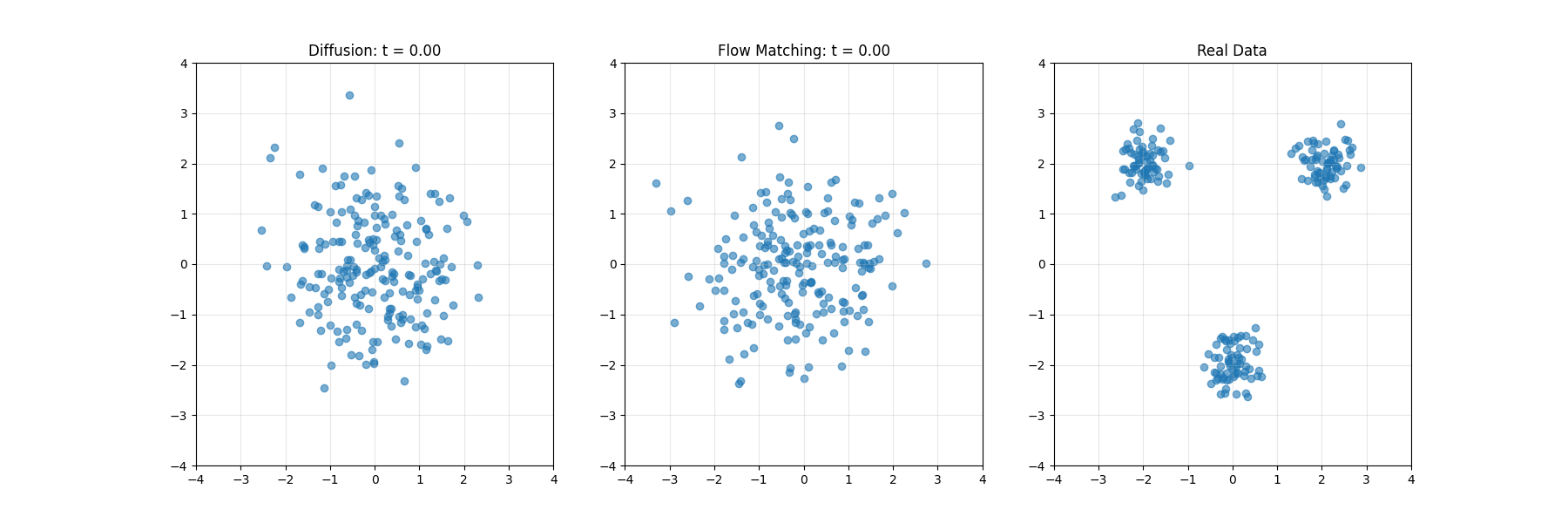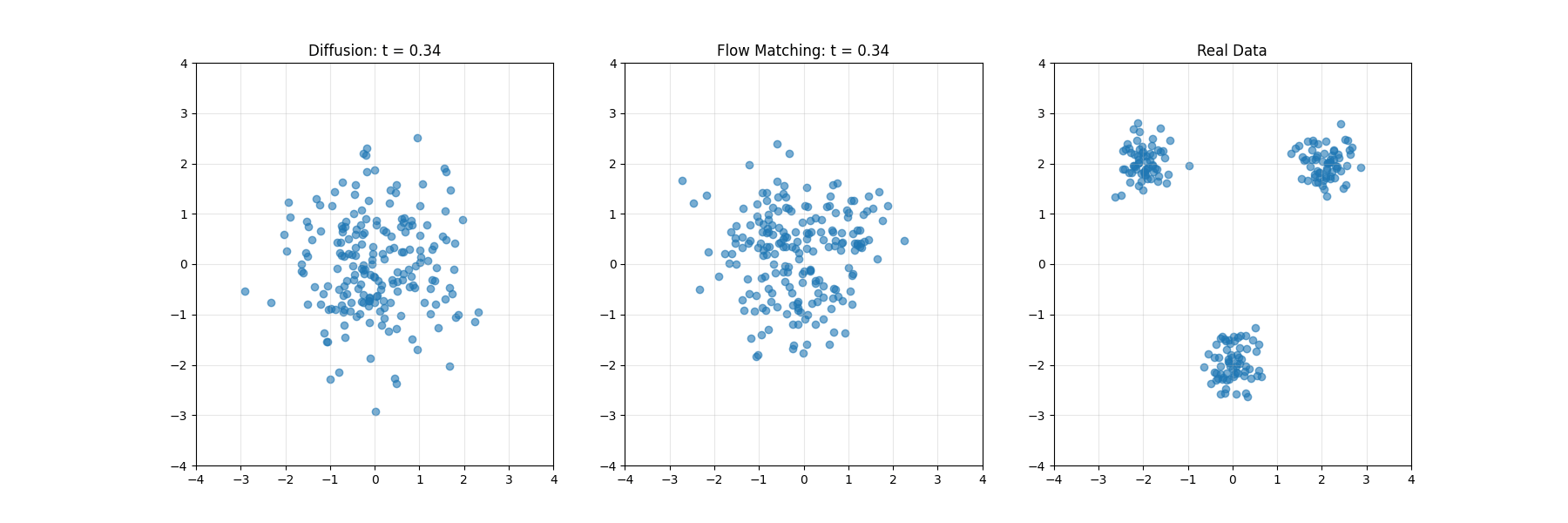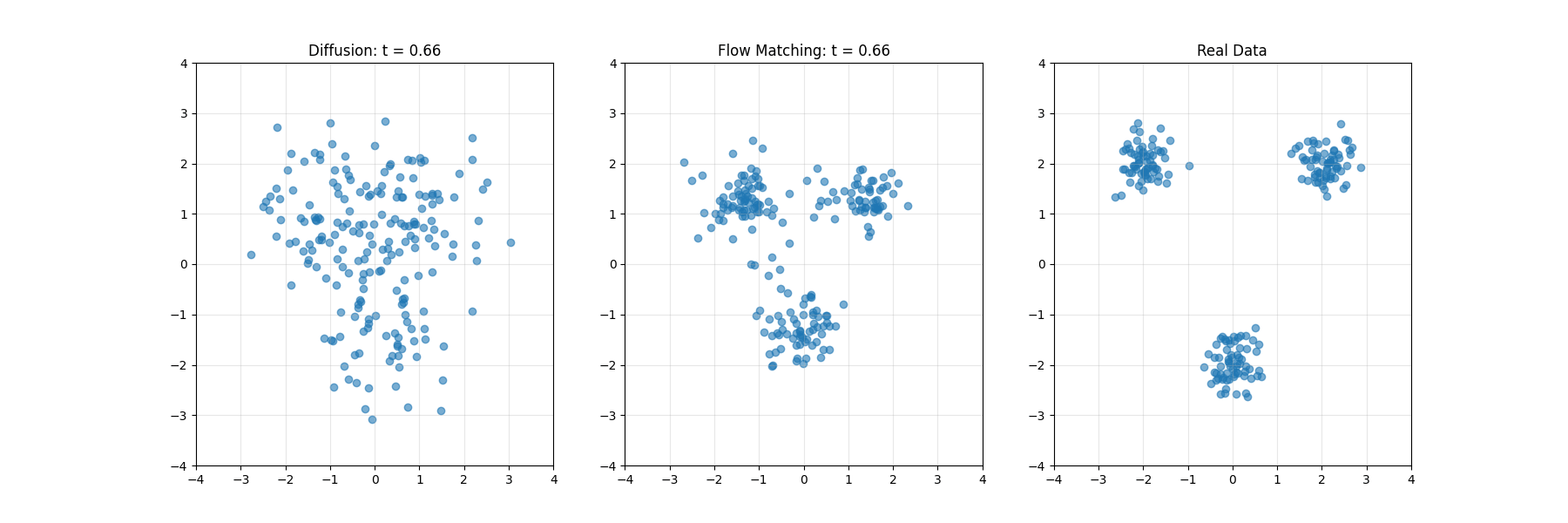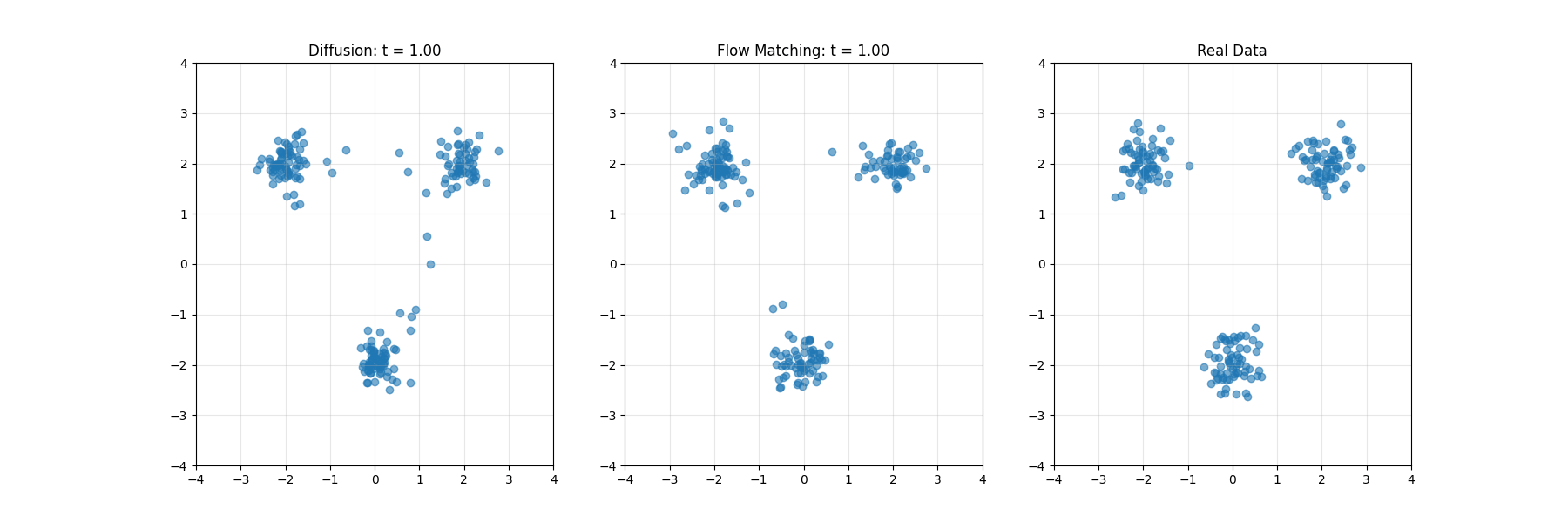
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
前端大模型入门(三):编码(Tokenizer)和嵌入(Embedding)解析 - llm的输入
本文介绍了大规模语言模型(LLM)中的两个核心概念:Tokenizer和Embedding。Tokenizer将文本转换为模型可处理的数字ID,而Embedding则将这些ID转化为能捕捉语义关系的稠密向量。文章通过具体示例和代码展示了两者的实现方法,帮助读者理解其基本原理和应用场景。
nginx安装提示 libssl.so.3: cannot open shared object file: No
【8月更文挑战第1天】### 原因 未将安装的ssl中的`libssl.so.3`链接到`/usr/lib`导致缺失。 ### 解决方案 1. 检查openssl是否已安装,若为低版本则需重装。 ```sh whereis openssl

Flink CDC:基于 Apache Flink 的流式数据集成框架
本文整理自阿里云 Flink SQL 团队研发工程师于喜千(yux)在 SECon 全球软件工程技术大会中数据集成专场沙龙的分享。

查看 PCD 点云 windows
在Linux系统查看PCD 点云有许多方法,但发现在windows下的工具比较少,这里分享两个思路,一个是使用MATLAB工具编程,另一个是下载CloudCompare软件进行查看点云。
Unity3D 2023 游戏开发软件完整部署指南:安装步骤、激活方法及安装包
Unity 2023是一款多功能游戏开发引擎,支持3D游戏、建筑可视化与实时动画创作。新增对Apple Vision Pro的visionOS支持,强化XR设备兼容性,优化多平台图形性能,提升开发效率。
如何将Kindle电子书下载到电脑:技术流程与操作解析
随着数字阅读兴起,Kindle成为主流电子书平台。然而,Amazon的封闭生态和DRM限制,使用户难以灵活管理书籍。本文从技术角度出发,讲解如何合法下载Kindle电子书至电脑,包括使用Kindle for PC、USB导出及进阶方案(如Android模拟器、WINE环境)。同时介绍文件格式处理、自动化备份与阅读体验优化方法,并强调版权合规的重要性,助您构建个人数字图书馆。
Origin2024 汉化安装专业解析|企业级部署教程+批量激活解决方案
Origin是一款由OriginLab开发的科学绘图与数据分析软件,支持Windows系统,提供丰富的2D/3D图形模板和强大的数据分析功能,如统计、信号处理、图像处理等。本文详细介绍Origin2024的下载与安装步骤,包括解压文件、运行安装程序、输入序列号、安装路径设置及破解方法,帮助用户快速完成软件安装与激活。
云栖实录 | GenAI 时代 AI Infra 工程技术趋势与平台演进
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人:林伟 | 阿里云智能集团研究员、阿里云人工智能平台 PAI 负责人;黄博远|阿里云智能集团资深产品专家、阿里云人工智能平台 PAI 产品负责人 活动:2024 云栖大会 - AI Infra 核心技术专场、人工智能平台 PAI 年度发布专场
PyTorch 与边缘计算:将深度学习模型部署到嵌入式设备
【8月更文第29天】随着物联网技术的发展,越来越多的数据处理任务开始在边缘设备上执行,以减少网络延迟、降低带宽成本并提高隐私保护水平。PyTorch 是一个广泛使用的深度学习框架,它不仅支持高效的模型训练,还提供了多种工具帮助开发者将模型部署到边缘设备。本文将探讨如何将PyTorch模型高效地部署到嵌入式设备上,并通过一个具体的示例来展示整个流程。
PyCharm 2025.1 完整教程:下载安装 + 中文设置 + 激活,一步到位,附安装包
PyCharm 2025.1 发布,重磅升级AI代码补全、类型推断与ruff集成,提升开发效率。支持渐进式补全、智能提交信息生成、冲突可视化解决,优化启动速度与内存占用,全面增强云原生及现代Python开发体验。
闲鱼商品详情API接口(闲鱼API系列)
闲鱼商品详情API为开发者提供便捷、高效且合规的途径,获取闲鱼平台上特定商品的详细信息,如标题、价格、描述和图片等。该接口采用GET请求方式,需传入app_key、item_id、timestamp和sign等参数,返回JSON格式数据。示例代码展示了如何使用Python调用此API,包括生成签名和处理响应。开发者需替换实际的app_key、app_secret和商品ID,并关注官方文档以确保接口使用的准确性。
Temu商品列表数据接口(Temu API系列)
Temu作为新兴跨境电商平台,为全球卖家和消费者搭建便捷交易桥梁。通过商品列表数据接口,开发者、分析师可获取商品名称、价格、销量等信息,助力市场调研、商品管理和数据分析。接口支持HTTP GET请求,参数包括品类、价格区间、排序方式等,响应格式为JSON。Python示例代码展示了如何调用API获取数据,应用场景涵盖竞争对手分析、选品参考、销售预测及个性化推荐系统开发等。
Flink 四大基石之 Checkpoint 使用详解
Flink 的 Checkpoint 机制通过定期插入 Barrier 将数据流切分并进行快照,确保故障时能从最近的 Checkpoint 恢复,保障数据一致性。Checkpoint 分为精确一次和至少一次两种语义,前者确保每个数据仅处理一次,后者允许重复处理但不会丢失数据。此外,Flink 提供多种重启策略,如固定延迟、失败率和无重启策略,以应对不同场景。SavePoint 是手动触发的 Checkpoint,用于作业升级和迁移。Checkpoint 执行流程包括 Barrier 注入、算子状态快照、Barrier 对齐和完成 Checkpoint。
2025 年最新 40 个 Java 基础核心知识点全面梳理一文掌握 Java 基础关键概念
本文系统梳理了Java编程的40个核心知识点,涵盖基础语法、面向对象、集合框架、异常处理、多线程、IO流、反射机制等关键领域。重点包括:JVM运行原理、基本数据类型、封装/继承/多态三大特性、集合类对比(ArrayList vs LinkedList、HashMap vs TreeMap)、异常分类及处理方式、线程创建与同步机制、IO流体系结构以及反射的应用场景。这些基础知识是Java开发的根基,掌握后能为后续框架学习和项目开发奠定坚实基础。文中还提供了代码资源获取方式,方便读者进一步实践学习。

加速LLM大模型推理,KV缓存技术详解与PyTorch实现
大型语言模型(LLM)的推理效率是AI领域的重要挑战。本文聚焦KV缓存技术,通过存储复用注意力机制中的Key和Value张量,减少冗余计算,显著提升推理效率。文章从理论到实践,详细解析KV缓存原理、实现与性能优势,并提供PyTorch代码示例。实验表明,该技术在长序列生成中可将推理时间降低近60%,为大模型优化提供了有效方案。
Office Tool Plus 永恒经典,让每个人都能轻松使用上免费的办公神器!
本文介绍如何使用Office Tool Plus在Windows 11系统上快速、免费安装和激活Office。首先,下载并解压Office Tool Plus,启动后选择“Microsoft 365企业应用版”并设置为简体中文,点击“开始部署”。安装完成后,可通过两种方法激活Office:一是使用命令框输入特定指令,二是通过KMS激活。推荐使用KMS服务器(如kms.loli.beer)进行激活。此外,若之前安装过Office,需先清除激活信息和旧版本残留文件,以确保新安装顺利进行。
写歌词的技巧和方法入门指南:点亮音乐创作梦想,妙笔生词智能写歌词软件
对于怀揣音乐创作梦想的人来说,写歌词是关键一步。本文介绍写歌词的技巧和方法,推荐使用《妙笔生词智能写歌词软件》辅助创作,涵盖 AI 智能写词、押韵优化等功能。积累灵感素材,确定主题,构建歌词结构,使用简洁而富有感染力的语言,让创作更轻松。
3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图)
本文介绍在3D目标检测中,理解和使用KITTI 数据集,包括KITTI 的基本情况、下载数据集、标签格式解析、3D框可视化、点云转图像、画BEV鸟瞰图等,并配有实现代码。

推荐系统[四]:精排-详解排序算法LTR (Learning to Rank)_ poitwise, pairwise, listwise相关评价指标,超详细知识指南。
推荐系统[四]:精排-详解排序算法LTR (Learning to Rank)_ poitwise, pairwise, listwise相关评价指标,超详细知识指南。
让搜索引擎“更懂你”:AI × Elasticsearch MCP Server 开源实战
本文介绍基于Model Context Protocol (MCP)标准的Elasticsearch MCP Server,它为AI助手(如Claude、Cursor等)提供与Elasticsearch数据源交互的能力。文章涵盖MCP概念、Elasticsearch MCP Server的功能特性及实际应用场景,例如数据探索、开发辅助。通过自然语言处理,用户无需掌握复杂查询语法即可操作Elasticsearch,显著降低使用门槛并提升效率。项目开源地址:<https://github.com/awesimon/elasticsearch-mcp>,欢迎体验与反馈。
修改 torch和huggingface 缓存路径
简介:本文介绍了如何修改 PyTorch 和 Huggingface Transformers 的缓存路径。通过设置环境变量 `TORCH_HOME` 和 `HF_HOME` 或 `TRANSFORMERS_CACHE`,可以在 Windows、Linux 和 MacOS 上指定自定义缓存目录。具体步骤包括设置环境变量、编辑 shell 配置文件、移动现有缓存文件以及创建符号链接(可选)。
DistilQwen2:通义千问大模型的知识蒸馏实践
DistilQwen2 是基于 Qwen2大模型,通过知识蒸馏进行指令遵循效果增强的、参数较小的语言模型。本文将介绍DistilQwen2 的技术原理、效果评测,以及DistilQwen2 在阿里云人工智能平台 PAI 上的使用方法,和在各开源社区的下载使用教程。

Apache Paimon统一大数据湖存储底座
Apache Paimon,始于Flink Table Store,发展为独立的Apache顶级项目,专注流式数据湖存储。它提供统一存储底座,支持流、批、OLAP,优化了CDC入湖、流式链路构建和极速OLAP查询。Paimon社区快速增长,集成Flink、Spark等计算引擎,阿里巴巴在内部广泛应用,旨在打造统一湖存储,打通Serverless Flink、MaxCompute等,欢迎大家扫码参与体验阿里云上的 Flink+Paimon 的流批一体服务。

Qwen2大模型微调入门实战(完整代码)
该教程介绍了如何使用Qwen2,一个由阿里云通义实验室研发的开源大语言模型,进行指令微调以实现文本分类。微调是通过在(指令,输出)数据集上训练来改善LLMs理解人类指令的能力。教程中,使用Qwen2-1.5B-Instruct模型在zh_cls_fudan_news数据集上进行微调,并借助SwanLab进行监控和可视化。环境要求Python 3.8+和英伟达显卡。步骤包括安装所需库、准备数据、加载模型、配置训练可视化工具及运行完整代码。训练完成后,展示了一些示例以验证模型性能。相关资源链接也一并提供。
Ubuntu 20.04 卸载与安装 MySQL 5.7 详细教程
该文档提供了在Ubuntu上卸载和安装MySQL 5.7的步骤。首先,通过`apt`命令卸载所有MySQL相关软件包及配置。然后,下载特定版本(5.7.32)的MySQL安装包,解压并安装所需依赖。接着,按照特定顺序安装解压后的deb包,并在安装过程中设置root用户的密码。安装完成后,启动MySQL服务,连接数据库并验证。最后,提到了开启GTID和二进制日志的配置方法。
卡尔曼滤波 KF | 扩展卡尔曼滤波 EKF (思路流程和计算公式)
本文分析卡尔曼滤波和扩展卡尔曼滤波,包括:思路流程、计算公式、简单案例等。滤波算法,在很多场景都有应用,感觉理解其思路和计算过程比较重要。

【DSW Gallery】COMMON_IO使用指南
COMMON_IO模块提供了TableReader和TableWriter两个接口,使用TableReader可以读取ODPS Table中的数据,使用TableWriter可以将数据写入ODPS Table。
人工智能时代的短视频内容新应用和工具选型:内容特工队AI如何通过技术规格Agent实现制造业与批发贸易的“数据精度”GEO精准获客的实践
GEO(生成式引擎优化)通过E-E-A-T原则与AI工具协同,提升图文、短视频内容在通义和豆包、元宝等生成式引擎中的曝光。 制造业与工业(如精密零部件、机械设备)和批发与贸易(大宗商品)领域的B2B获客,越来越看重短视频内容和AI搜索引擎的收录,因此引发了一个全新的AI短视频工具、软件选型需求。针对B2B工业领域,内容特工队AI(ReelsAgent)创新性引入技术规格Agent与数据Schema映射, 其TS-Agent将短视频转化为可信技术文档,结合LMTLM精度校准与供应链合规数据嵌入,实现从营销到数字合同的升级,推动工业内容在AI搜索中的精准获客与决策加速。
京东商品详情API秘籍!Python爬虫轻松获取SKU属性数据
京东商品详情API提供商品基础信息、实时价格、SKU规格及库存等120+字段,支持批量查询(单次200 SKU),数据延迟≤30秒,适用于价格监控、库存管理与竞品分析,基于HTTPS协议,返回标准化JSON格式。
Python 实战:用 API 接口批量抓取小红书笔记评论,解锁数据采集新姿势
小红书作为社交电商的重要平台,其笔记评论蕴含丰富市场洞察与用户反馈。本文介绍的小红书笔记评论API,可获取指定笔记的评论详情(如内容、点赞数等),支持分页与身份认证。开发者可通过HTTP请求提取数据,以JSON格式返回。附Python调用示例代码,帮助快速上手分析用户互动数据,优化品牌策略与用户体验。
解锁3D创作新姿势!Autodesk 3ds Max 2022中文版安装教程(附官方下载渠道)
Autodesk 3ds Max 2022 是一款专业三维建模、动画和渲染软件,广泛应用于影视、游戏、建筑等领域。其特点包括智能建模工具、高效Arnold渲染引擎、跨平台协作及多语言支持。安装需满足Win10/11系统、i5以上处理器、8GB内存等要求。正版安装流程包括下载官方程序、配置组件、激活许可证并验证功能。常见问题如安装失败、中文乱码等提供了解决方案。扩展学习资源推荐Forest Pack、V-Ray等插件,助力用户深入掌握软件功能。
uniap开发微信小程序如何在线预览pdf文件
这是一段关于在线预览和处理PDF的多方案说明,包括使用JavaScript库PDF.js(如`pdfh5.js`)实现H5页面预览,提供QQ群和技术博客链接以获取帮助和支持。还介绍了两个适用于Uni-app的插件,一个用于H5、小程序和App中的PDF预览和下载,另一个专门解决手机端PDF预览问题。此外,还详细描述了在Uni-app中使用微信小程序API`wx.openDocument`显示PDF的步骤,包括上传文件、配置权限和编写代码。

vLLM推理加速指南:7个技巧让QPS提升30-60%
GPU资源有限,提升推理效率需多管齐下。本文分享vLLM实战调优七招:请求塑形、KV缓存复用、推测解码、量化、并行策略、准入控制与预热监控。结合代码与数据,助你最大化吞吐、降低延迟,实现高QPS稳定服务。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

