









反爬虫机制深度解析:从基础防御到高级对抗的完整技术实战
本文系统阐述了反爬虫技术的演进与实践,涵盖基础IP限制、User-Agent检测,到验证码、行为分析及AI智能识别等多层防御体系,结合代码实例与架构图,全面解析爬虫攻防博弈,并展望智能化、合规化的发展趋势。

从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。
软件复杂度量化:McCabe度量法及其环路复杂度的计算方法
McCabe度量法(McCabe's Cyclomatic Complexity)是一种经典的方法,用于度量软件程序的复杂度。通过计算程序中独立路径的数量,帮助开发人员评估代码的维护难度和测试覆盖率。本文详细介绍了McCabe度量法的原理、计算方法及其在实际应用中的作用。

【2025云栖大会】AI 搜索引擎如何驱动亿级物流:货拉拉 x 阿里云 Elasticsearch
2025云栖大会 AI搜索与向量化模型专场上,拉拉 Elasticsearch技术负责人——陈敏华先生分享了 Elasticsearch 在全球化高并发业务场景下的深度实践,以及在迁移至阿里云 Elasticsearch Serverless 后的显著收益。货拉拉的案例为业界提供了可复制、可落地的技术范本。
nginx安装部署ssl证书,同时支持http与https方式访问
为了使HTTP服务支持HTTPS访问,需生成并安装SSL证书,并确保Nginx支持SSL模块。首先,在`/usr/local/nginx`目录下生成RSA密钥、证书申请文件及自签名证书。接着,确认Nginx已安装SSL模块,若未安装则重新编译Nginx加入该模块。最后,编辑`nginx.conf`配置文件,启用并配置HTTPS服务器部分,指定证书路径和监听端口(如20000),保存后重启Nginx完成部署。
阿里巴巴的通义千问大模型
阿里巴巴通义千问是基于Transformer的大型语言模型,预训练于多样化数据集,支持18亿至720亿参数规模。在多模态英文任务中表现出色,且具备多语言对话及图片文本识别能力。可应用于搜索引擎、问答系统和对话交互,提供智能体验。然而,模型在逻辑题和指令理解上存在不足,需在特定领域进行优化。

Flink Agents:基于Apache Flink的事件驱动AI智能体框架
本文基于Apache Flink PMC成员宋辛童在Community Over Code Asia 2025的演讲,深入解析Flink Agents项目的技术背景、架构设计与应用场景。该项目聚焦事件驱动型AI智能体,结合Flink的实时处理能力,推动AI在工业场景中的工程化落地,涵盖智能运维、直播分析等典型应用,展现其在AI发展第四层次——智能体AI中的重要意义。
实时计算引擎 Flink:从入门到深入理解
本篇详细介绍了Apache Flink实时计算引擎的基本概念和核心功能。从入门到深入,逐步介绍了Flink的数据源与接收、数据转换与计算、窗口操作以及状态管理等方面的内容,并附带代码示例进行实际操作演示。通过阅读本文,读者可以建立起对Flink实时计算引擎的全面理解,为实际项目中的实时数据处理提供了有力的指导和实践基础。
1688图片搜索API技术文档
1688图片搜索API(拍立淘)是阿里巴巴官方图像搜货工具,支持通过图片URL或Base64编码查找1688平台同款或相似商品。基于深度学习技术,精准匹配商品ID、标题、价格、销量、供应商等全维度信息,命中率超85%,单次响应≤1秒,支持批量调用与分页排序,适用于电商比价、选品采购等场景。
Hive 特殊的数据类型 Array、Map、Struct
在Hive中,`Array`、`Map`和`Struct`是三种特殊的数据类型。`Array`用于存储相同类型的列表,如`select array(1, "1", 2, 3, 4, 5)`会产生一个整数数组。`Map`是键值对集合,键值类型需一致,如`select map(1, 2, 3, "4")`会产生一个整数到整数的映射。`Struct`表示结构体,有固定数量和类型的字段,如`select struct(1, 2, 3, 4)`创建一个无名结构体。这些类型支持嵌套使用,允许更复杂的结构数据存储。例如,可以创建一个包含用户结构体的数组来存储多用户信息

Vector | Graph:蚂蚁首个开源Graph RAG框架设计解读
引入知识图谱技术后,传统RAG链路到Graph RAG链路会有什么样的变化,如何兼容RAG中的向量数据库(Vector Database)和图数据库(Graph Database)基座,以及蚂蚁的Graph RAG开源技术方案和未来优化方向。
ZyperWin++使用教程!让Windows更丝滑!c盘飘红一键搞定!ZyperWin++解决系统优化、Office安装和系统激活
ZyperWin++是一款仅5MB的开源免费Windows优化工具,支持快速优化、自定义设置与垃圾清理,兼具系统加速、隐私保护、Office安装等功能,轻便无广告,小白也能轻松上手,是提升电脑性能的全能管家。

【大模型私有化部署要花多少钱?】一张图看懂你的钱用在哪
本文探讨了高性价比实现DeepSeek大模型私有化部署的方法,分为两部分: 一是定义大模型性能指标,包括系统级(吞吐量、并发数)与用户体验级(首token生成时间、单token生成时间)指标,并通过roofline模型分析性能瓶颈; 二是评估私有化部署成本,对比不同硬件(如H20和4090)及模型选择,结合业务需求优化资源配置。适合关注数据安全与成本效益的企业参考。
HBase Shell-org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet 已解决
在HBase Shell遇到错误时,检查Hadoop非安全模式:`hdfs dfsadmin -safemode get`。问题解决在于`hbase-site.xml`中添加配置:Zookeeper客户端端口设为2181和预写日志提供者设为filesystem。

【最佳实践】esrally:Elasticsearch 官方压测工具及运用详解
由于 Elasticsearch(后文简称 es) 的简单易用及其在大数据处理方面的良好性能,越来越多的公司选用 es 作为自己的业务解决方案。然而在引入新的解决方案前,不免要做一番调研和测试,本文便是介绍官方的一个 es 压测工具 esrally,希望能为大家带来帮助。
从零到一:淘宝店铺订单API接入全流程指南
淘宝订单API通过订单号获取完整交易数据,支持实时查询买家信息、商品明细及物流状态,适用于订单同步、物流监控与数据分析。采用RESTful设计,JSON格式响应,安全高效,助力电商自动化运营。

阿里云开发者分享VMware17 Pro保姆级安装秘籍,详细步骤助你轻松搞定安装!
这是一篇超详细的VMware 17 Pro虚拟机下载与安装教程。VMware 17 Pro支持多操作系统模拟运行,适合开发、测试及教育使用。文章涵盖从下载到安装的全流程,包括解压安装包、接受协议、配置安装路径等步骤,并提供虚拟机优化(如安装VMware Tools、配置快照和共享文件夹)及使用指南。同时,针对常见问题如虚拟化未启用或软件阻止启动,提供了具体解决方案,帮助用户顺利部署和使用虚拟机环境。
Python新手常见问题一:列表、元组、集合、字典区别是什么?
本文针对Python编程新手常遇到的问题,详细阐述了列表(List)、元组(Tuple)、集合(Set)和字典(Dictionary)这四种数据结构的核心区别。列表是一种有序且可变的数据序列,允许元素重复;元组同样有序但不可变,其内容一旦创建就不能修改;集合是无序、不重复的元素集,强调唯一性,主要用于数学意义上的集合操作;而字典则是键值对的映射容器,其中键必须唯一,而值可以任意,它提供了一种通过键查找对应值的有效方式。通过对这些基本概念和特性的对比讲解,旨在帮助初学者更好地理解并运用这些数据类型来解决实际编程问题。
常见的分布式定时任务调度框架
分布式定时任务调度框架用于在分布式系统中管理和调度定时任务,确保任务按预定时间和频率执行。其核心概念包括Job(任务)、Trigger(触发器)、Executor(执行器)和Scheduler(调度器)。这类框架应具备任务管理、任务监控、良好的可扩展性和高可用性等功能。常用的Java生态中的分布式任务调度框架有Quartz Scheduler、ElasticJob和XXL-JOB。

人工智能的三大主义--——行为主义(actionism),连接主义 (connectionism)
这段内容涵盖了人工智能领域的重要概念和历史节点。首先介绍了布鲁克斯的六足行走机器人及Spot机器狗,被视为新一代“控制论动物”。接着解释了感知机作为最简单的人工神经网络,通过特征向量进行二分类。1974年,沃伯斯提出误差反向传播(BP)算法,利用梯度调整权重以优化模型。最后,阐述了符号主义、连接主义和行为主义三大学派的发展与融合,强调它们在持续学习中共同推动人工智能的进步。

概率分布深度解析:PMF、PDF和CDF的技术指南
本文将深入探讨概率分布,详细阐述概率质量函数(PMF)、概率密度函数(PDF)和累积分布函数(CDF)这些核心概念,并通过实际示例进行说明。
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
号称能打败MLP的KAN到底行不行?数学核心原理全面解析
Kolmogorov-Arnold Networks (KANs) 是一种新型神经网络架构,挑战了多层感知器(mlp)的基础,通过在权重而非节点上使用可学习的激活函数(如b样条),提高了准确性和可解释性。KANs利用Kolmogorov-Arnold表示定理,将复杂函数分解为简单函数的组合,简化了神经网络的近似过程。与mlp相比,KAN在参数量较少的情况下能达到类似或更好的性能,并能直观地可视化,增强了模型的可解释性。尽管仍需更多研究验证其优势,KAN为深度学习领域带来了新的思路。
京东商品详情API:从签名生成到JSON解析的完整实战指南
京东商品详情API是京东开放平台的核心接口,提供实时、准确的商品信息获取服务。支持查询商品基础信息、价格库存、SKU规格及销量评价等120+字段,数据延迟≤30秒,单次最多查询200个SKU,适用于价格监控、库存管理等场景。采用HTTP/HTTPS请求,返回标准化JSON格式,便于集成,助力电商数据高效采集与应用。
淘宝商品详情API赋能电商数据模型:从SKU分析到销量预测
淘宝商品详情API(taobao.item.get)通过商品ID实时获取标题、价格、库存等数据,支持RESTful风格与OAuth2.0认证,具备高实时性、字段定制和防封禁机制,适用于比价、库存监控等场景。

高效获取淘宝商品详情:API 开发实现链接解析的完整技术方案
2025反向海淘新机遇:依托代购系统,聚焦小众垂直品类,结合Pandabay数据选品,降本增效。系统实现智能翻译、支付风控、物流优化,助力中式养生茶等品类利润翻倍,新手也能快速入局全球市场。
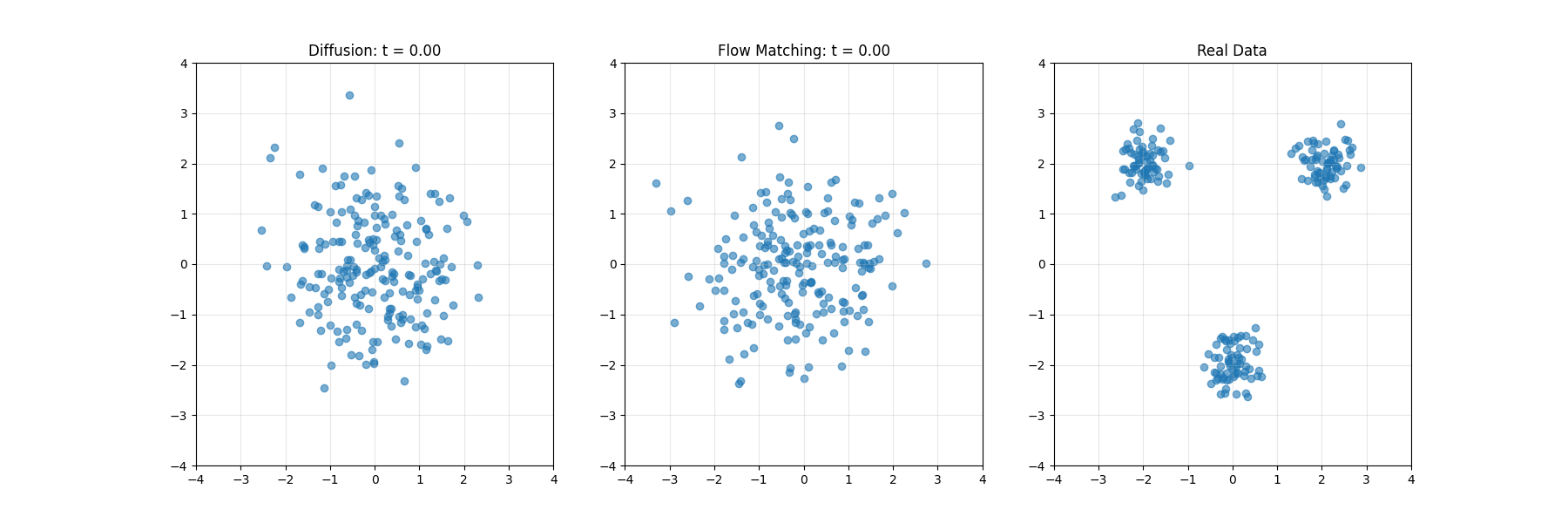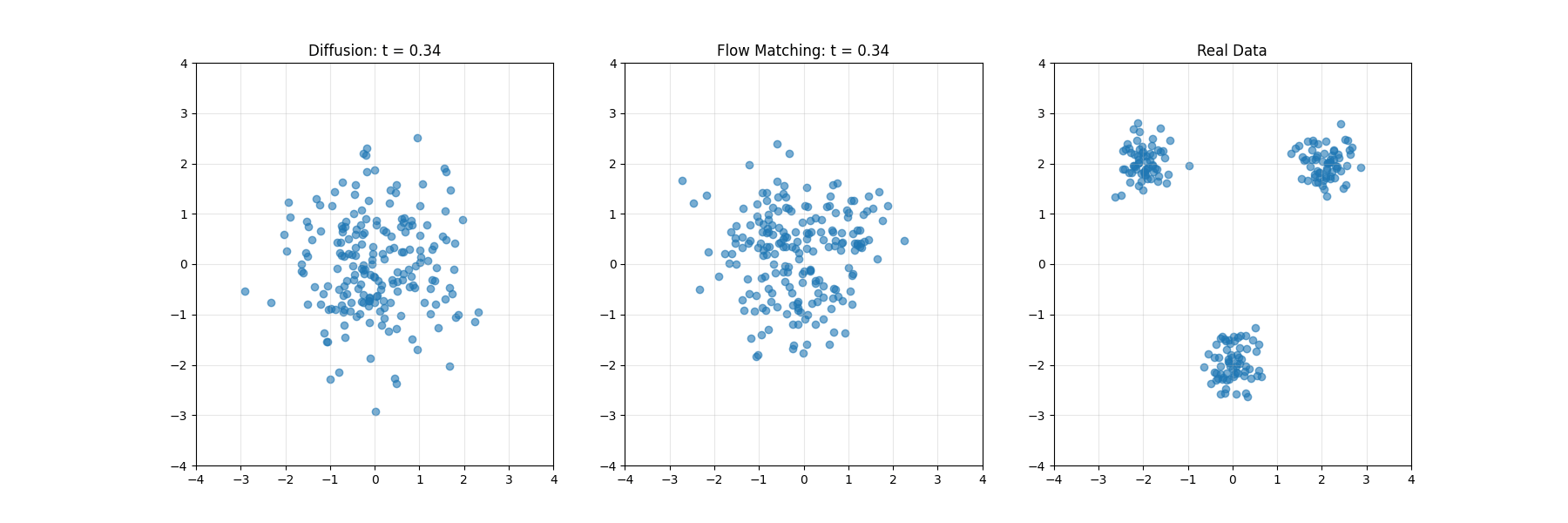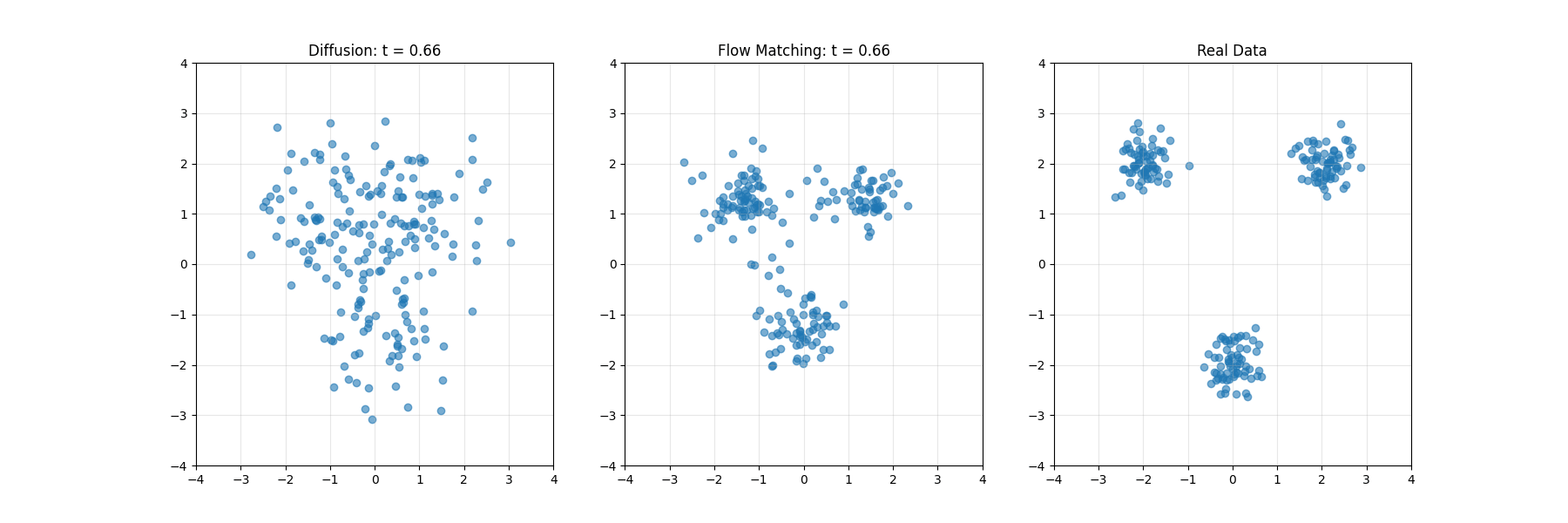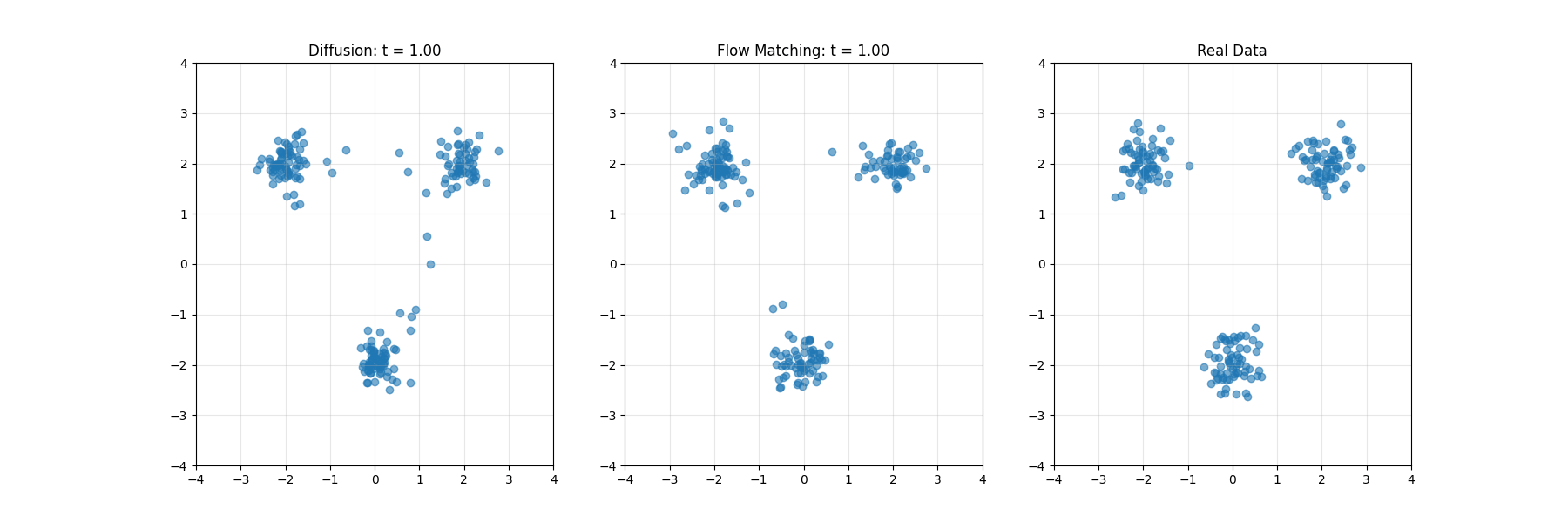
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
前端大模型入门(三):编码(Tokenizer)和嵌入(Embedding)解析 - llm的输入
本文介绍了大规模语言模型(LLM)中的两个核心概念:Tokenizer和Embedding。Tokenizer将文本转换为模型可处理的数字ID,而Embedding则将这些ID转化为能捕捉语义关系的稠密向量。文章通过具体示例和代码展示了两者的实现方法,帮助读者理解其基本原理和应用场景。
nginx安装提示 libssl.so.3: cannot open shared object file: No
【8月更文挑战第1天】### 原因 未将安装的ssl中的`libssl.so.3`链接到`/usr/lib`导致缺失。 ### 解决方案 1. 检查openssl是否已安装,若为低版本则需重装。 ```sh whereis openssl

Flink CDC:基于 Apache Flink 的流式数据集成框架
本文整理自阿里云 Flink SQL 团队研发工程师于喜千(yux)在 SECon 全球软件工程技术大会中数据集成专场沙龙的分享。

查看 PCD 点云 windows
在Linux系统查看PCD 点云有许多方法,但发现在windows下的工具比较少,这里分享两个思路,一个是使用MATLAB工具编程,另一个是下载CloudCompare软件进行查看点云。
Java“找不到符号” 错误怎么查找解决
“找不到符号”是Java编程中常见的编译错误,通常表明代码试图访问未声明或不可见的符号(如类、方法或变量)。解决此问题需检查拼写、导入包是否正确及作用域是否合适。确保使用正确的类路径和库,可有效避免此类错误。若问题依旧,查阅官方文档或使用调试工具定位错误亦为良策。
Unity3D 2023 游戏开发软件完整部署指南:安装步骤、激活方法及安装包
Unity 2023是一款多功能游戏开发引擎,支持3D游戏、建筑可视化与实时动画创作。新增对Apple Vision Pro的visionOS支持,强化XR设备兼容性,优化多平台图形性能,提升开发效率。
如何将Kindle电子书下载到电脑:技术流程与操作解析
随着数字阅读兴起,Kindle成为主流电子书平台。然而,Amazon的封闭生态和DRM限制,使用户难以灵活管理书籍。本文从技术角度出发,讲解如何合法下载Kindle电子书至电脑,包括使用Kindle for PC、USB导出及进阶方案(如Android模拟器、WINE环境)。同时介绍文件格式处理、自动化备份与阅读体验优化方法,并强调版权合规的重要性,助您构建个人数字图书馆。
PyTorch 与边缘计算:将深度学习模型部署到嵌入式设备
【8月更文第29天】随着物联网技术的发展,越来越多的数据处理任务开始在边缘设备上执行,以减少网络延迟、降低带宽成本并提高隐私保护水平。PyTorch 是一个广泛使用的深度学习框架,它不仅支持高效的模型训练,还提供了多种工具帮助开发者将模型部署到边缘设备。本文将探讨如何将PyTorch模型高效地部署到嵌入式设备上,并通过一个具体的示例来展示整个流程。
PyCharm 2025.1 完整教程:下载安装 + 中文设置 + 激活,一步到位,附安装包
PyCharm 2025.1 发布,重磅升级AI代码补全、类型推断与ruff集成,提升开发效率。支持渐进式补全、智能提交信息生成、冲突可视化解决,优化启动速度与内存占用,全面增强云原生及现代Python开发体验。
云栖实录 | GenAI 时代 AI Infra 工程技术趋势与平台演进
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人:林伟 | 阿里云智能集团研究员、阿里云人工智能平台 PAI 负责人;黄博远|阿里云智能集团资深产品专家、阿里云人工智能平台 PAI 产品负责人 活动:2024 云栖大会 - AI Infra 核心技术专场、人工智能平台 PAI 年度发布专场
2025 年最新 40 个 Java 基础核心知识点全面梳理一文掌握 Java 基础关键概念
本文系统梳理了Java编程的40个核心知识点,涵盖基础语法、面向对象、集合框架、异常处理、多线程、IO流、反射机制等关键领域。重点包括:JVM运行原理、基本数据类型、封装/继承/多态三大特性、集合类对比(ArrayList vs LinkedList、HashMap vs TreeMap)、异常分类及处理方式、线程创建与同步机制、IO流体系结构以及反射的应用场景。这些基础知识是Java开发的根基,掌握后能为后续框架学习和项目开发奠定坚实基础。文中还提供了代码资源获取方式,方便读者进一步实践学习。
闲鱼商品详情API接口(闲鱼API系列)
闲鱼商品详情API为开发者提供便捷、高效且合规的途径,获取闲鱼平台上特定商品的详细信息,如标题、价格、描述和图片等。该接口采用GET请求方式,需传入app_key、item_id、timestamp和sign等参数,返回JSON格式数据。示例代码展示了如何使用Python调用此API,包括生成签名和处理响应。开发者需替换实际的app_key、app_secret和商品ID,并关注官方文档以确保接口使用的准确性。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

