








MCP与A2A协议比较:人工智能系统互联与协作的技术基础架构
本文深入解析了人工智能领域的两项关键基础设施协议:模型上下文协议(MCP)与代理对代理协议(A2A)。MCP由Anthropic开发,专注于标准化AI模型与外部工具和数据源的连接,降低系统集成复杂度;A2A由Google发布,旨在实现不同AI代理间的跨平台协作。两者虽有相似之处,但在设计目标与应用场景上互为补充。文章通过具体示例分析了两种协议的技术差异及适用场景,并探讨了其在企业工作流自动化、医疗信息系统和软件工程中的应用。最后,文章强调了整合MCP与A2A构建协同AI系统架构的重要性,为未来AI技术生态系统的演进提供了方向。
让小程序拥有“视觉之眼“:DeepSeek图像识别实战指南
本文介绍如何通过DeepSeek计算机视觉技术,赋予小程序“看懂世界”的能力。从构建视觉感知系统、训练专属视觉词典到创造会思考的界面,详细讲解了实现智能相册、植物识别器和老旧照片修复等功能的步骤。最后探讨性能优化与安全合规要点,展望未来视觉智能应用的无限可能。

十大主流联邦学习框架:技术特性、架构分析与对比研究
联邦学习(FL)是保障数据隐私的分布式模型训练关键技术。业界开发了多种开源和商业框架,如TensorFlow Federated、PySyft、NVFlare、FATE、Flower等,支持模型训练、数据安全、通信协议等功能。这些框架在灵活性、易用性、安全性和扩展性方面各有特色,适用于不同应用场景。选择合适的框架需综合考虑开源与商业、数据分区支持、安全性、易用性和技术生态集成等因素。联邦学习已在医疗、金融等领域广泛应用,选择适配具体需求的框架对实现最优模型性能至关重要。
京东商品SKU价格接口(Jd.item_get)丨京东API接口指南
京东商品SKU价格接口(Jd.item_get)是京东开放平台提供的API,用于获取商品详细信息及价格。开发者需先注册账号、申请权限并获取密钥,随后通过HTTP请求调用API,传入商品ID等参数,返回JSON格式的商品信息,包括价格、原价等。接口支持GET/POST方式,适用于Python等语言的开发环境。
Milvus x n8n :自动化拆解Github文档,零代码构建领域知识智能问答
本文介绍了在构建特定技术领域问答机器人时面临的四大挑战:知识滞后性、信息幻觉、领域术语理解不足和知识库维护成本高。通过结合Milvus向量数据库和n8n低代码平台,提出了一种高效的解决方案。该方案利用Milvus的高性能向量检索和n8n的工作流编排能力,构建了一个可自动更新、精准回答技术问题的智能问答系统,并介绍了部署过程中的可观测性和安全性实现方法。
开源AI BI可视化工具-WrenAI
Wren AI 是一款开源的 SQL AI 代理,支持数据、产品及业务团队通过聊天、直观界面和与 Excel、Google Sheets 的集成获取洞察。它结合大型语言模型(LLM)与检索增强生成(RAG)技术,助力用户高效处理复杂数据分析任务。
2025年颠覆闭源大模型?MonkeyOCR:这款开源AI文档解析模型,精度更高,速度更快!
还在依赖昂贵且慢的闭源OCR工具?华中科技大学开源的MonkeyOCR文档解析模型,以其超越GPT4o的精度和更快的推理速度,在单机单卡(3090)上即可部署,正颠覆业界认知。本文将深入解析其设计哲学、核心突破——大规模自建数据集,并分享实测体验与避坑指南。
很火的DeepSeek到底是什么
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年。因推出开源 AI 模型 DeepSeek-R1 而引起了广泛关注。与ChatGPT相比,大幅降低了推理模型的成本。
基于yolo8的深度学习室内火灾监测识别系统
本研究基于YOLO8算法构建室内火灾监测系统,利用计算机视觉技术实现火焰与烟雾的实时识别。相比传统传感器,该系统响应更快、精度更高,可有效提升火灾初期预警能力,保障生命财产安全,具有重要的应用价值与推广前景。
香烟品牌识别和规格识别设计思路
基于YOLOv8实现香烟品牌与规格(条装/单盒装)识别,采用“品牌+规格”组合为60类的复合类别方案,结合充足标注数据(每类300-500张)、数据增强与反例优化,进行端到端联合训练,提升模型在复杂场景下的检测与分类精度。
Post-Training on PAI (4):模型微调SFT、DPO、GRPO
阿里云人工智能平台 PAI 提供了完整的模型微调产品能力,支持 监督微调(SFT)、偏好对齐(DPO)、强化学习微调(GRPO) 等业界常用模型微调训练方式。根据客户需求及代码能力层级,分别提供了 PAI-Model Gallery 一键微调、PAI-DSW Notebook 编程微调、PAI-DLC 容器化任务微调的全套产品功能。
如何用大模型评估大模型——PAI-Judge裁判员大语言模型的实现简介
阿里云人工智能平台 PAI 推出 PAI-Judge 裁判员大模型,为用户构建符合应用场景的多维度、细粒度的评测体系,支持单模型评测和双模型竞技两种模式,允许用户自定义参数,实现准确、灵活、高效的模型自动化评测,为模型迭代优化提供数据支撑。 相比通用大模型尤其在回答确定性/数学类问题、角色扮演、创意文体写作、翻译等场景下,PAI-Judge 系列模型表现优异,可以直接用于大模型的评估与质检。
淘宝直播间弹幕 API 接口(淘宝 API 系列)
淘宝直播间弹幕API助力电商直播数据分析与优化。通过实时获取弹幕信息(昵称、内容、时间、类型),商家可精准把握消费者需求,优化直播内容;开发者可构建数据分析工具和智能客服系统。接口采用WebSocket协议,支持全双工通信,确保数据实时性。请求需包含直播间ID(room_id),并遵循平台使用规范。示例代码展示了Python调用方法,需安装`websocket-client`库并处理重连与异常。

Vue 3 + TypeScript 现代前端开发最佳实践(2025版指南)
每日激励:“如果没有天赋,那就一直重复”。我是蒋星熠Jaxonic,一名执着于代码宇宙的星际旅人。用Vue 3与TypeScript构建高效、可维护的前端系统,分享Composition API、状态管理、性能优化等实战经验,助力技术进阶。
深度解析京东图片搜索API:从图像识别到商品匹配的算法实践
京东图片搜索API基于图像识别技术,支持通过上传图片或图片URL搜索相似商品,提供智能匹配、结果筛选、分页查询等功能。适用于比价、竞品分析、推荐系统等场景。支持Python等开发语言,提供详细请求示例与文档。

客流类API实测:门店到访客群画像数据
本文介绍了一个实用的API——“门店到访客群画像分布”,适用于线下实体门店进行客群画像分析。该API支持多种画像维度,如性别、年龄、职业、消费偏好等,帮助商家深入了解顾客特征,提升运营效率。文章详细说明了API的参数配置、响应数据、接入流程,并附有Python调用示例,便于开发者快速集成。适合零售、餐饮等行业从业者使用。
阿里云PAI AutoML实战:20分钟构建高精度电商销量预测模型
本文介绍了如何利用阿里云 PAI AutoML 平台,在20分钟内构建高精度的电商销量预测模型。内容涵盖项目背景、数据准备与预处理、模型训练与优化、部署应用及常见问题解决方案,助力企业实现数据驱动的精细化运营,提升市场竞争力。


计算机视觉五大技术——深度学习在图像处理中的应用
深度学习利用多层神经网络实现人工智能,计算机视觉是其重要应用之一。图像分类通过卷积神经网络(CNN)判断图片类别,如“猫”或“狗”。目标检测不仅识别物体,还确定其位置,R-CNN系列模型逐步优化检测速度与精度。语义分割对图像每个像素分类,FCN开创像素级分类范式,DeepLab等进一步提升细节表现。实例分割结合目标检测与语义分割,Mask R-CNN实现精准实例区分。关键点检测用于人体姿态估计、人脸特征识别等,OpenPose和HRNet等技术推动该领域发展。这些方法在效率与准确性上不断进步,广泛应用于实际场景。

分布式爬虫框架Scrapy-Redis实战指南
本文介绍如何使用Scrapy-Redis构建分布式爬虫系统,采集携程平台上热门城市的酒店价格与评价信息。通过代理IP、Cookie和User-Agent设置规避反爬策略,实现高效数据抓取。结合价格动态趋势分析,助力酒店业优化市场策略、提升服务质量。技术架构涵盖Scrapy-Redis核心调度、代理中间件及数据解析存储,提供完整的技术路线图与代码示例。
【赵渝强老师】史上最详细:Hadoop HDFS的体系架构
HDFS(Hadoop分布式文件系统)由三个核心组件构成:NameNode、DataNode和SecondaryNameNode。NameNode负责管理文件系统的命名空间和客户端请求,维护元数据文件fsimage和edits;DataNode存储实际的数据块,默认大小为128MB;SecondaryNameNode定期合并edits日志到fsimage中,但不作为NameNode的热备份。通过这些组件的协同工作,HDFS实现了高效、可靠的大规模数据存储与管理。

湖仓实时化升级 :Uniflow 构建流批一体实时湖仓
本文整理自阿里云产品经理李昊哲在Flink Forward Asia 2024流批一体专场的分享,涵盖实时湖仓发展趋势、基于Flink搭建流批一体实时湖仓及Materialized Table优化三方面。首先探讨了实时湖仓的发展趋势和背景,特别是阿里云在该领域的领导地位。接着介绍了Uniflow解决方案,通过Flink CDC、Paimon存储等技术实现低成本、高性能的流批一体处理。最后,重点讲解了Materialized Table如何简化用户操作,提升数据查询和补数体验,助力企业高效应对不同业务需求。
Python爬虫定义入门知识
Python爬虫是用于自动化抓取互联网数据的程序。其基本概念包括爬虫、请求、响应和解析。常用库有Requests、BeautifulSoup、Scrapy和Selenium。工作流程包括发送请求、接收响应、解析数据和存储数据。注意事项包括遵守Robots协议、避免过度请求、处理异常和确保数据合法性。Python爬虫强大而灵活,但使用时需遵守法律法规。
基于springboot的快递分拣管理系统
本系统基于SpringBoot框架,结合Java、MySQL与Vue技术,构建智能化快递分拣管理平台。通过自动化识别、精准分拣与实时跟踪,提升分拣效率与准确性,降低人力成本,推动快递行业向智能化、高效化转型,助力电商物流高质量发展。
云上AI推理平台全掌握 (5):大模型异步推理服务
针对大模型推理服务中“高计算量、长时延”场景下同步推理的弊端,阿里云人工智能平台 PAI 推出了一套基于独立的队列服务异步推理框架,解决了异步推理的负载均衡、实例异常时任务重分配等问题,确保请求不丢失、实例不过载。
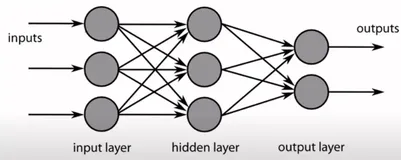
基于DJL的机器学习
本文介绍了基于Java的深度学习框架DJL,涵盖机器学习与深度学习的核心概念、神经网络结构及生命周期,并通过MNIST数据集展示了从模型构建、训练到推理的完整流程。内容深入浅出,适合初学者入门。
ODPS驱动电商仓储革命:动态需求预测系统的落地实践
本方案基于ODPS构建“预测-仿真-决策”闭环系统,解决传统仓储中滞销积压与爆款缺货问题。通过动态特征工程、时空融合模型与库存仿真引擎,实现库存周转天数下降42%,缺货率下降65%,年损减少5000万以上,显著提升运营效率与GMV。
一个完整 Java 项目常包含的各层次详解与全面解析
本内容介绍了Java项目的典型分层架构,涵盖开放接口层、终端显示层、Web层、Service层、Manager层、Mapper层及常用辅助层次,如实体层、DTO层、VO层等。通过合理划分各层职责,结合Spring Boot等框架,实现系统的高内聚、低耦合,提升可维护性与扩展性,适用于微服务与MVC架构设计。
大模型备案需要通过算法备案才能进行吗?
本内容详细介绍了算法备案与大模型备案的流程、审核重点及两者关系。算法备案覆盖生成合成类等5类算法,需提交安全自评估报告,审核周期约2个月;大模型备案针对境内公众服务的大模型,涉及多维度审查,周期3-6个月。两者存在前置条件关系,完成算法备案是大模型备案的基础。阿里云提供全流程工具支持,包括合规预评估、材料校验和进度追踪,助力企业高效备案。此外,文档解答了常见问题,如算法迭代是否需重新备案,并解析政策红利与技术支持,帮助企业降低合规成本、享受补贴奖励。适用于需了解备案流程和技术支持的企业和个人开发者。
体育应用怎么通过API接口接入数据源与直播源
本文介绍了体育类应用接入数据源与直播源的API接口方案。主要包括:1) 数据源API接入,涉及选择提供商、接入流程及常见数据类型;2) 直播源接入,涵盖直播源类型、提供商和技术方案;3) 技术实现要点,如数据缓存、实时更新机制和安全性考虑;4) 成本优化建议。附有HLS播放示例及Node.js完整集成代码,帮助开发者高效实现体育应用功能。

鹰角基于 Flink + Paimon + Trino 构建湖仓一体化平台实践项目
本文整理自鹰角网络大数据开发工程师朱正军在Flink Forward Asia 2024上的分享,主要涵盖四个方面:鹰角数据平台架构、数据湖选型、湖仓一体建设及未来展望。文章详细介绍了鹰角如何构建基于Paimon的数据湖,解决了Hudi入湖的痛点,并通过Trino引擎和Ranger权限管理实现高效的数据查询与管控。此外,还探讨了湖仓一体平台的落地效果及未来技术发展方向,包括Trino与Paimon的集成增强、StarRocks的应用以及Paimon全面替换Hive的计划。
ubuntu22 编译安装docker,和docker容器方式安装 deepseek
本脚本适用于Ubuntu 22.04,主要功能包括编译安装Docker和安装DeepSeek模型。首先通过Apt源配置安装Docker,确保网络稳定(建议使用VPN)。接着下载并配置Docker二进制文件,创建Docker用户组并设置守护进程。随后拉取Debian 12镜像,安装系统必备工具,配置Ollama模型管理器,并最终部署和运行DeepSeek模型,提供API接口进行交互测试。

数据分布检验利器:通过Q-Q图进行可视化分布诊断、异常检测与预处理优化
Q-Q图(Quantile-Quantile Plot)是一种强大的可视化工具,用于验证数据是否符合特定分布(如正态分布)。通过比较数据和理论分布的分位数,Q-Q图能直观展示两者之间的差异,帮助选择合适的统计方法和机器学习模型。本文介绍了Q-Q图的工作原理、基础代码实现及其在数据预处理、模型验证和金融数据分析中的应用。
从本地部署到企业级服务:十种主流LLM推理框架的技术介绍与对比
本文深入探讨了十种主流的大语言模型(LLM)服务引擎和工具,涵盖从轻量级本地部署到高性能企业级解决方案,详细分析了它们的技术特点、优势及局限性,旨在为研究人员和工程团队提供适合不同应用场景的技术方案。内容涉及WebLLM、LM Studio、Ollama、vLLM、LightLLM、OpenLLM、HuggingFace TGI、GPT4ALL、llama.cpp及Triton Inference Server与TensorRT-LLM等。
小红书笔记评论API:一键获取分层评论与用户互动数据
小红书笔记评论API可获取指定笔记的评论详情,包括内容、点赞数、评论者信息等,支持分页与身份认证,返回JSON格式数据,适用于舆情监控、用户行为分析等场景。

解决推理能力瓶颈,用因果推理提升LLM智能决策
从ChatGPT到AI智能体,标志着AI从对话走向自主执行复杂任务的能力跃迁。AI智能体可完成销售、旅行规划、外卖点餐等多场景任务,但其发展受限于大语言模型(LLM)的推理能力。LLM依赖统计相关性,缺乏对因果关系的理解,导致在非确定性任务中表现不佳。结合因果推理与内省机制,有望突破当前AI智能体的推理瓶颈,提升其决策准确性与自主性。

多智能体系统设计:5种编排模式解决复杂AI任务
本文探讨了多AI智能体协作中的关键问题——编排。文章指出,随着系统从单体模型向多智能体架构演进,如何设计智能体之间的通信协议、工作流程和决策机制,成为实现高效协作的核心。文章详细分析了五种主流的智能体编排模式:顺序编排、MapReduce、共识模式、分层编排和制作者-检查者模式,并分别介绍了它们的应用场景、优势与挑战。最后指出,尽管大模型如GPT-5提升了单体能力,但在复杂任务中,合理的智能体编排仍不可或缺。选择适合的编排方式,有助于在系统复杂度与实际效果之间取得平衡。
面向 Java 开发者:2024 最新技术栈下 Java 与 AI/ML 融合的实操详尽指南
Java与AI/ML融合实践指南:2024技术栈实战 本文提供了Java与AI/ML融合的实操指南,基于2024年最新技术栈(Java 21、DJL 0.27.0、Spring Boot 3.2等)。主要内容包括: 环境配置:详细说明Java 21、Maven依赖和核心技术组件的安装步骤 图像分类服务:通过Spring Boot集成ResNet-50模型,实现REST接口图像分类功能 智能问答系统:展示基于RAG架构的文档处理与向量检索实现 性能优化:利用虚拟线程、GraalVM等新技术提升AI服务性能 文

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。


