









时空API实测:区域人群客流画像数据快速获取
市场调研无需繁琐查找客流数据,通过API接口快速获取人群画像与客流统计信息。支持自由选择区域、时间季度及人群类型,返回包括年龄、性别、职业、消费偏好等多维数据。

告别低效代码:用对这10个Pandas方法让数据分析效率翻倍
本文将介绍 10 个在数据处理中至关重要的 Pandas 技术模式。这些模式能够显著减少调试时间,提升代码的可维护性,并构建更加清晰的数据处理流水线。
天猫商品详情API接口技术解析与Python实现
天猫商品详情API(tmall.item_get)通过商品ID获取商品标题、价格、库存、图片、SKU及评价等详细信息,支持HTTP请求与JSON格式返回,适用于电商数据分析与运营。本文提供Python调用示例,实现快速接入与数据解析。
淘宝API文档:淘宝商品详情API接口
淘宝商品详情API(taobao.item.get)为开发者提供获取商品信息的途径,涵盖基础信息、价格、图文、评价及物流等。适用于电商数据分析、比价平台与购物助手开发。本文提供Python调用示例,含请求构造与响应处理流程。
1688商品列表API全参数指南:从基础搜索到高级筛选
1688商品列表API是阿里巴巴B2B平台的核心接口,支持关键词搜索、高级筛选、排序与分页功能,适用于选品、价格监控等场景。数据规范、稳定高效,日均调用量大。提供Python示例代码,便于快速接入与扩展应用。
大数据时代的智能研发平台需求与阿里云DIDE的定位
阿里云DIDE是一站式智能大数据开发与治理平台,致力于解决传统大数据开发中的效率低、协同难等问题。通过全面整合资源、高度抽象化设计及流程自动化,DIDE显著提升数据处理效率,降低使用门槛,适用于多行业、多场景的数据开发需求,助力企业实现数字化转型与智能化升级。

大语言模型也可以进行图像分割:使用Gemini实现工业异物检测完整代码示例
本文将通过一个实际应用场景——工业传送带异物检测,详细介绍如何利用Gemini的图像分割能力构建完整的解决方案。

解决RAG检索瓶颈:RAPL线图转换让知识图谱检索准确率提升40%
本文探讨了RAPL框架,一种创新的人工智能架构,用于改进知识图谱环境下的检索增强生成系统。RAPL通过线图转换和合理化监督技术,构建高效且可泛化的检索器,显著提升大型语言模型在知识问答中的准确性和可解释性。文章分析了现有RAG系统的缺陷,即最短路径并非总是合理路径,并提出RAPL的三步解决方案:利用大型语言模型生成高质量训练数据、将知识图谱转换为线图以实现基于路径的推理,以及通过双向图神经网络进行路径检索。实验结果表明,RAPL不仅提高了检索精度,还缩小了小型与大型语言模型间的性能差距,推动了更高效、透明的AI系统发展。

Python 3D数据可视化:7个实用案例助你快速上手
本文介绍了基于 Python Matplotlib 库的七种三维数据可视化技术,涵盖线性绘图、散点图、曲面图、线框图、等高线图、三角剖分及莫比乌斯带建模。通过具体代码示例和输出结果,展示了如何配置三维投影环境并实现复杂数据的空间表示。这些方法广泛应用于科学计算、数据分析与工程领域,帮助揭示多维数据中的空间关系与规律,为深入分析提供技术支持。
最新技术栈下 Java 面试高频技术点实操指南详解
本指南结合最新Java技术趋势,涵盖微服务(Spring Cloud Alibaba)、响应式编程(Spring WebFlux)、容器化部署(Docker+Kubernetes)、函数式编程、性能优化及测试等核心领域。通过具体实现步骤与示例代码,深入讲解服务注册发现、配置中心、熔断限流、响应式数据库访问、JVM调优等内容。适合备战Java面试,提升实操能力,助力技术进阶。资源链接:[https://pan.quark.cn/s/14fcf913bae6](https://pan.quark.cn/s/14fcf913bae6)

朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文探讨了朴素贝叶斯算法在处理混合数据类型中的应用,通过投票和堆叠集成方法构建分类框架。实验基于电信客户流失数据集,验证了该方法的有效性。文章详细分析了算法的数学理论基础、条件独立性假设及参数估计方法,并针对二元、类别、多项式和高斯分布特征设计专门化流水线。实验结果表明,集成学习显著提升了分类性能,但也存在特征分类自动化程度低和计算开销大的局限性。作者还探讨了特征工程、深度学习等替代方案,为未来研究提供了方向。(239字)

NLP驱动网页数据分类与抽取实战
本文探讨了使用NLP技术进行网页商品数据抽取时遇到的三大瓶颈:请求延迟高、结构解析慢和分类精度低,并以目标站点goofish.com为例,展示了传统方法在采集商品信息时的性能问题。通过引入爬虫代理降低封禁概率、模拟真实用户行为优化请求,以及利用关键词提取提升分类准确性,实现了请求成功率从65%提升至98%,平均请求耗时减少72.7%,NLP分类错误率下降73.6%的显著优化效果。最终,代码实现快速抓取并解析商品数据,支持价格统计与关键词分析,为构建智能推荐模型奠定了基础。
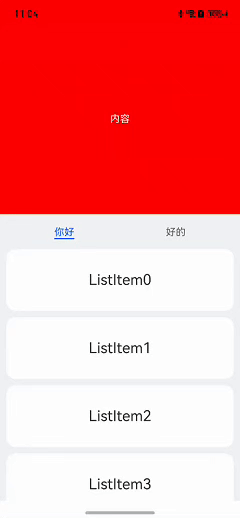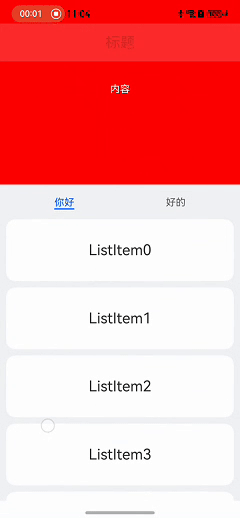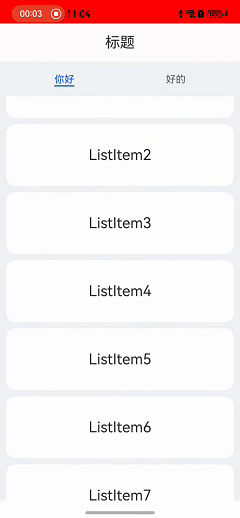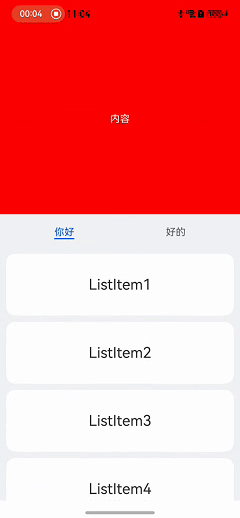
HarmonyOS实战:Tab顶部滑动悬停功能实现
在鸿蒙开发中,实现Scroll嵌套List列表滑动时顶部悬停的效果是一个常见需求。本文详细介绍了如何通过布局和事件处理来实现这一功能。首先,使用Scroll嵌套List和Tab布局来构建基础页面。然后,通过设置nestedScroll属性为NestedScrollMode.PARENT_FIRST,确保外层Scroll优先滑动。接着,通过监听List和Scroll的滑动事件,处理滑动冲突,确保在特定条件下Scroll停止滑动,将滑动事件交给List处理。最终,实现了在上下滑动时优先让Scroll滑动的效果,并提供了扩展思路,如优先让List滑动等。

HarmonyOS实战:高德地图自定义定位图标展示
本文详细介绍了在鸿蒙系统中实现地图定位功能的开发流程与注意事项。首先,开发者需要申请两个必要的定位权限,并确保用户手动开启系统设置中的位置权限。接着,通过高德定位获取用户位置信息,并使用自定义图标替代默认的定位箭头。文章特别强调了经纬度数据必须为float类型,否则可能导致定位不准确。此外,还需检查系统的GPS定位按钮是否开启,以确保定位功能正常使用。通过本文的指导,开发者可以避免常见的定位问题,顺利完成地图定位功能的开发。

SmolDocling技术解析:2.56亿参数胜过70亿参数的轻量级文档处理模型
SmolDocling是由HuggingFace与IBM联合研发的超紧凑视觉模型,专为端到端文档转换设计。基于SmolVLM-256M开发,参数量仅2.56亿,却媲美大型模型性能。其核心创新在于DocTags格式,一种类XML标记语言,能全面表示文档内容与结构。SmolDocling通过端到端架构实现图像理解与文本生成整合,在文档分类、OCR、布局分析等任务中表现出色。评估显示,其在多项指标上优于大参数量模型,适用于资源受限场景,推动文档处理技术发展。

防止交叉验证中的数据泄露:提升模型在实际环境中的性能
本文探讨了机器学习模型从开发到部署过程中可能出现的性能断崖问题,重点分析了**数据泄露**和**类别不平衡**两大主要原因。数据泄露可能源于预处理、特征工程或目标变量的不当操作,导致模型在测试阶段表现优异但实际应用中失效。同时,类别不平衡会使得常规交叉验证结果不可靠,需采用分层K折等方法应对。文章还介绍了通过Scikit-learn的Pipeline和ColumnTransformer防止数据泄露的最佳实践,并强调重采样技术(如SMOTE)应在数据划分后执行。最后,总结了构建可靠模型评估流程的核心原则,包括使用管道、分层验证及独立保留集等,帮助开发者构建在真实场景中性能稳定的模型。
一文掌握 1688 商品详情 API 接口:从入门到实战
1688是国内领先的综合电商批发平台,提供海量商品资源。其商品详情API助力开发者与企业获取商品的详细信息(如属性、价格、库存等),广泛应用于电商数据分析、比价系统及采购场景。API支持GET/POST请求,需传入通用参数(app_key、timestamp等)与业务参数(如product_id)。返回JSON格式数据,包含商品标题、价格、图片链接等详情,提升业务效率与决策精准度。
【SQL周周练】一句 SQL 如何帮助 5 个人买到电影院最好的座位?
这是一道我改编的 SQL 题目,不仅需要你输出连续的空座,还需要你去计算观影的最优位置。经过改编后,我相信是蛮有趣味的一道题。

GraphQL接口采集:自动化发现和提取隐藏数据字段
本文围绕GraphQL接口采集展开,详解如何通过`requests`+`Session`自动化提取隐藏数据字段,结合爬虫代理、Cookie与User-Agent设置实现精准抓取。内容涵盖错误示例(传统HTML解析弊端)、正确姿势(GraphQL请求构造)、原因解释(效率优势)、陷阱提示(反爬机制)及模板推荐(可复用代码)。掌握全文技巧,助你高效采集Yelp商家信息,避免常见误区,快速上手中高级爬虫开发。
亚马逊商品详情 API 接口开发指南
亚马逊商品详情API为开发者、分析师及电商从业者提供了获取商品数据的便捷途径。通过HTTP/HTTPS协议,支持GET/POST请求,可指定市场代码(如US、UK)和其他参数(如数据格式、附加信息)。返回信息涵盖商品基本信息(标题、品牌等)、价格(售价、货币单位)、库存状态、评论与评分(平均分、总评论数)以及销售排名等,助力市场分析、竞品研究和业务优化。
electron35-vue3-deepseek客户端流式输出AI对话系统
Electron35-DeepSeek桌面端AI系统|vue3.5+electron+arco客户端ai模板。2025跨平台ai实战electron35+vite6+arco仿DeepSeek/豆包ai流式打字聊天助手。

大数据新视界--大数据大厂之MySQL 数据库课程设计:开启数据宇宙的传奇之旅
本文全面剖析数据库课程设计 MySQL,展现其奇幻魅力与严峻挑战。通过实际案例凸显数据库设计重要性,详述数据安全要点及学习目标。深入阐述备份与恢复方法,并分享优秀实践项目案例。为开发者提供 MySQL 数据库课程设计的全面指南,助力提升数据库设计与管理能力,保障数据安全稳定。
云函数采集架构:Serverless模式下的动态IP与冷启动优化
本文探讨了在Serverless架构中使用云函数进行网页数据采集的挑战与解决方案。针对动态IP、冷启动及目标网站反爬策略等问题,提出了动态代理IP、请求头优化、云函数预热及容错设计等方法。通过网易云音乐歌曲信息采集案例,展示了如何结合Python代码实现高效的数据抓取,包括搜索、歌词与评论的获取。此方案不仅解决了传统采集方式在Serverless环境下的局限,还提升了系统的稳定性和性能。
阿里云 Elasticsearch Serverless 检索增强型8.17 版免费邀测!
阿里云Elasticsearch Serverless检索增强型8.17版现已开放邀测

Python 原生爬虫教程:京东商品详情页面数据API
本文介绍京东商品详情API在电商领域的应用价值及功能。该API通过商品ID获取详细信息,如基本信息、价格、库存、描述和用户评价等,支持HTTP请求(GET/POST),返回JSON或XML格式数据。对于商家优化策略、开发者构建应用(如比价网站)以及消费者快速了解商品均有重要意义。研究此API有助于推动电商业务创新与发展。

本地化部署DeepSeek-R1蒸馏大模型:基于飞桨PaddleNLP 3.0的实战指南
本文基于飞桨框架3.0,详细介绍了在Docker环境下部署DeepSeek-R1-Distill-Llama-8B蒸馏模型的全流程。飞桨3.0通过动静统一自动并行、训推一体设计等特性,显著优化大模型的推理性能与资源利用效率。实战中,借助INT8量化和自动化工具,模型在8卡A100上仅需60GB显存即可运行,推理耗时约2.8-3.2秒,吞吐率达10-12 tokens/s。本文为国产大模型的高效本地部署提供了工程参考,适配多场景需求。
【AI落地应用实战】大模型加速器2.0:基于 ChatDoc + TextIn ParseX+ACGE的RAG知识库问答系统
本文探讨了私有知识库问答系统的难点及解决方案,重点分析了企业知识管理中的痛点,如信息孤岛、知识传承依赖个人经验等问题。同时,介绍了IntFinQ这款知识管理工具的核心特点和实践体验,包括智能问答、深度概括与多维数据分析等功能。文章还详细描述了IntFinQ的本地化部署过程,展示了其从文档解析到知识应用的完整技术闭环,特别是自研TextIn ParseX引擎和ACGE模型的优势。最后总结了该工具对企业和开发者的价值,强调其在提升知识管理效率方面的潜力。
基于模糊神经网络的金融序列预测算法matlab仿真
本程序为基于模糊神经网络的金融序列预测算法MATLAB仿真,适用于非线性、不确定性金融数据预测。通过MAD、RSI、KD等指标实现序列预测与收益分析,运行环境为MATLAB2022A,完整程序无水印。算法结合模糊逻辑与神经网络技术,包含输入层、模糊化层、规则层等结构,可有效处理金融市场中的复杂关系,助力投资者制定交易策略。

GoT:基于思维链的语义-空间推理框架为视觉生成注入思维能力
本文探讨GoT框架如何通过语义-空间思维链方法提升图像生成的精确性与一致性。GoT(Generative Thoughts of Thinking)是一种创新架构,将显式推理机制引入图像生成与编辑领域。它通过语义推理分解文本提示,空间推理分配精确坐标,实现类人的场景构思过程。结合大型语言模型和扩散模型,GoT在复杂场景生成中表现出色,克服传统模型局限。其专用数据集包含900万样本,支持深度推理训练。技术架构融合语义-空间指导模块,确保生成图像高质量。GoT为图像生成与编辑带来技术革新,广泛应用于内容创作与教育工具开发等领域。
金融数据分析:解析JavaScript渲染的隐藏表格
本文详解了如何使用Python与Selenium结合代理IP技术,从金融网站(如东方财富网)抓取由JavaScript渲染的隐藏表格数据。内容涵盖环境搭建、代理配置、模拟用户行为、数据解析与分析等关键步骤。通过设置Cookie和User-Agent,突破反爬机制;借助Selenium等待页面渲染,精准定位动态数据。同时,提供了常见错误解决方案及延伸练习,帮助读者掌握金融数据采集的核心技能,为投资决策提供支持。注意规避动态加载、代理验证及元素定位等潜在陷阱,确保数据抓取高效稳定。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

