









人工智能的三大主义--——行为主义(actionism),连接主义 (connectionism)
这段内容涵盖了人工智能领域的重要概念和历史节点。首先介绍了布鲁克斯的六足行走机器人及Spot机器狗,被视为新一代“控制论动物”。接着解释了感知机作为最简单的人工神经网络,通过特征向量进行二分类。1974年,沃伯斯提出误差反向传播(BP)算法,利用梯度调整权重以优化模型。最后,阐述了符号主义、连接主义和行为主义三大学派的发展与融合,强调它们在持续学习中共同推动人工智能的进步。

AI智能体框架怎么选?7个主流工具详细对比解析
大语言模型需借助AI智能体实现“理解”到“行动”的跨越。本文解析主流智能体框架,从RelevanceAI、smolagents到LangGraph,涵盖技术门槛、任务复杂度、社区生态等选型关键因素,助你根据项目需求选择最合适的开发工具,构建高效、可扩展的智能系统。
如何将Kindle电子书下载到电脑:技术流程与操作解析
随着数字阅读兴起,Kindle成为主流电子书平台。然而,Amazon的封闭生态和DRM限制,使用户难以灵活管理书籍。本文从技术角度出发,讲解如何合法下载Kindle电子书至电脑,包括使用Kindle for PC、USB导出及进阶方案(如Android模拟器、WINE环境)。同时介绍文件格式处理、自动化备份与阅读体验优化方法,并强调版权合规的重要性,助您构建个人数字图书馆。

Flink Agents:基于Apache Flink的事件驱动AI智能体框架
本文基于Apache Flink PMC成员宋辛童在Community Over Code Asia 2025的演讲,深入解析Flink Agents项目的技术背景、架构设计与应用场景。该项目聚焦事件驱动型AI智能体,结合Flink的实时处理能力,推动AI在工业场景中的工程化落地,涵盖智能运维、直播分析等典型应用,展现其在AI发展第四层次——智能体AI中的重要意义。
ClickHouse 架构原理及核心特性详解
ClickHouse 是由 Yandex 开发的开源列式数据库,专为 OLAP 场景设计,支持高效的大数据分析。其核心特性包括列式存储、字段压缩、丰富的数据类型、向量化执行和分布式查询。ClickHouse 通过多种表引擎(如 MergeTree、ReplacingMergeTree、SummingMergeTree)优化了数据写入和查询性能,适用于电商数据分析、日志分析等场景。然而,它在事务处理、单条数据更新删除及内存占用方面存在不足。
nginx安装部署ssl证书,同时支持http与https方式访问
为了使HTTP服务支持HTTPS访问,需生成并安装SSL证书,并确保Nginx支持SSL模块。首先,在`/usr/local/nginx`目录下生成RSA密钥、证书申请文件及自签名证书。接着,确认Nginx已安装SSL模块,若未安装则重新编译Nginx加入该模块。最后,编辑`nginx.conf`配置文件,启用并配置HTTPS服务器部分,指定证书路径和监听端口(如20000),保存后重启Nginx完成部署。
ZyperWin++使用教程!让Windows更丝滑!c盘飘红一键搞定!ZyperWin++解决系统优化、Office安装和系统激活
ZyperWin++是一款仅5MB的开源免费Windows优化工具,支持快速优化、自定义设置与垃圾清理,兼具系统加速、隐私保护、Office安装等功能,轻便无广告,小白也能轻松上手,是提升电脑性能的全能管家。

高效获取淘宝商品详情:API 开发实现链接解析的完整技术方案
2025反向海淘新机遇:依托代购系统,聚焦小众垂直品类,结合Pandabay数据选品,降本增效。系统实现智能翻译、支付风控、物流优化,助力中式养生茶等品类利润翻倍,新手也能快速入局全球市场。
2025 年最新 40 个 Java 基础核心知识点全面梳理一文掌握 Java 基础关键概念
本文系统梳理了Java编程的40个核心知识点,涵盖基础语法、面向对象、集合框架、异常处理、多线程、IO流、反射机制等关键领域。重点包括:JVM运行原理、基本数据类型、封装/继承/多态三大特性、集合类对比(ArrayList vs LinkedList、HashMap vs TreeMap)、异常分类及处理方式、线程创建与同步机制、IO流体系结构以及反射的应用场景。这些基础知识是Java开发的根基,掌握后能为后续框架学习和项目开发奠定坚实基础。文中还提供了代码资源获取方式,方便读者进一步实践学习。
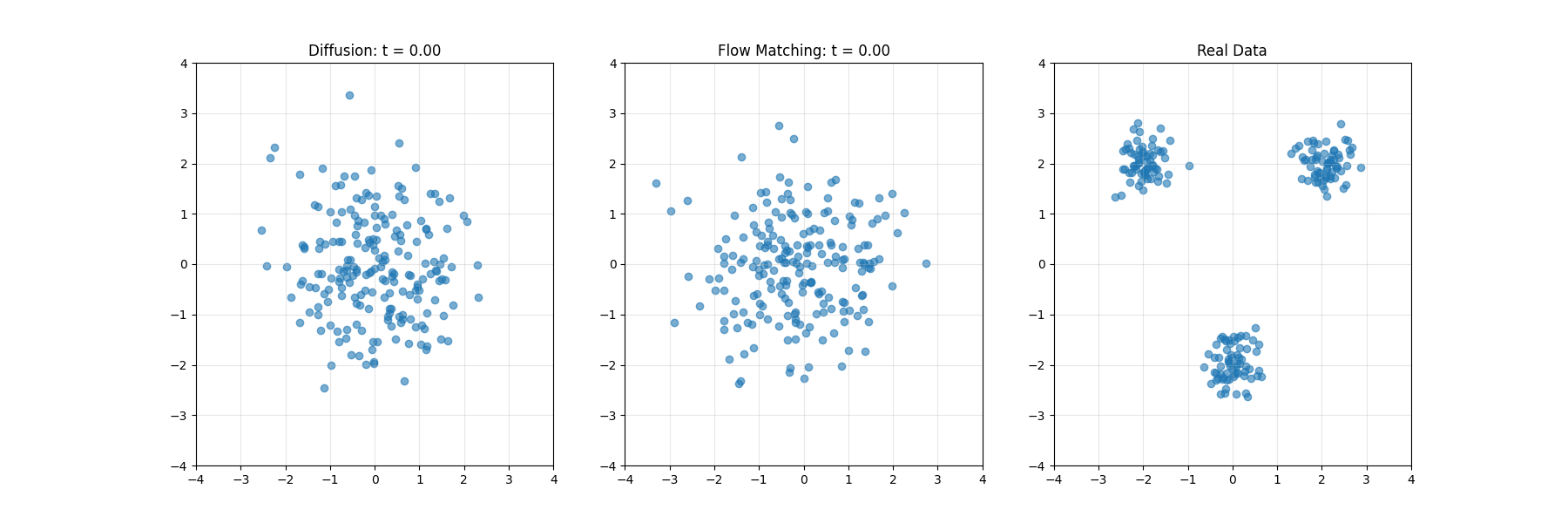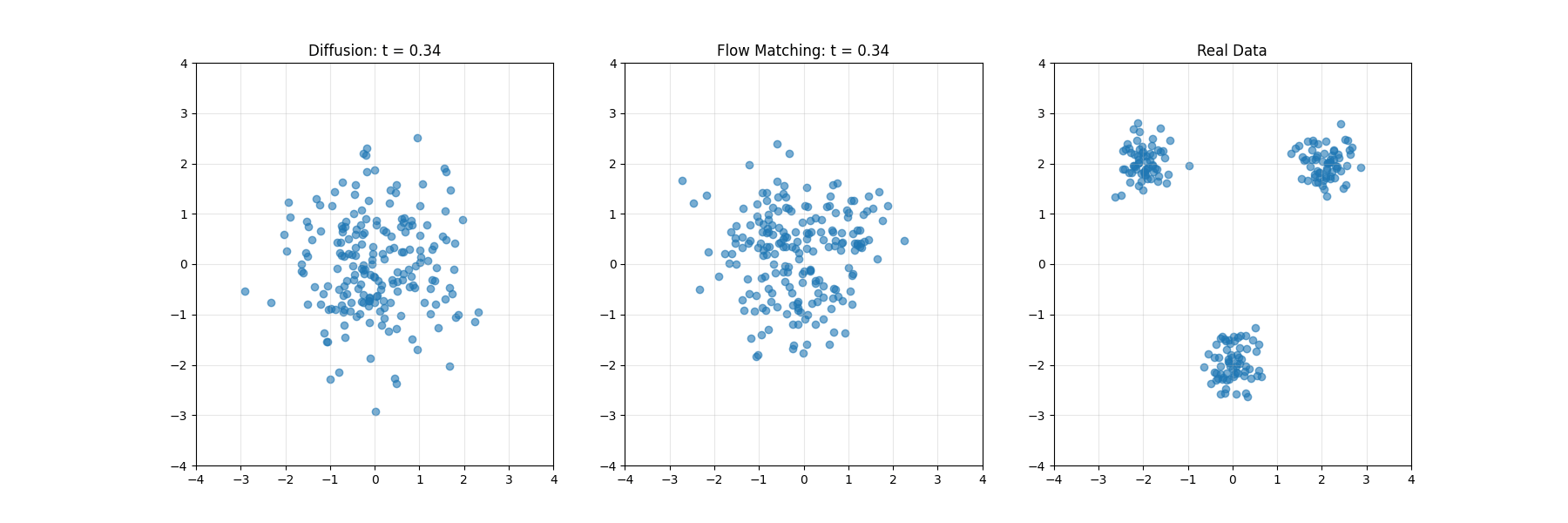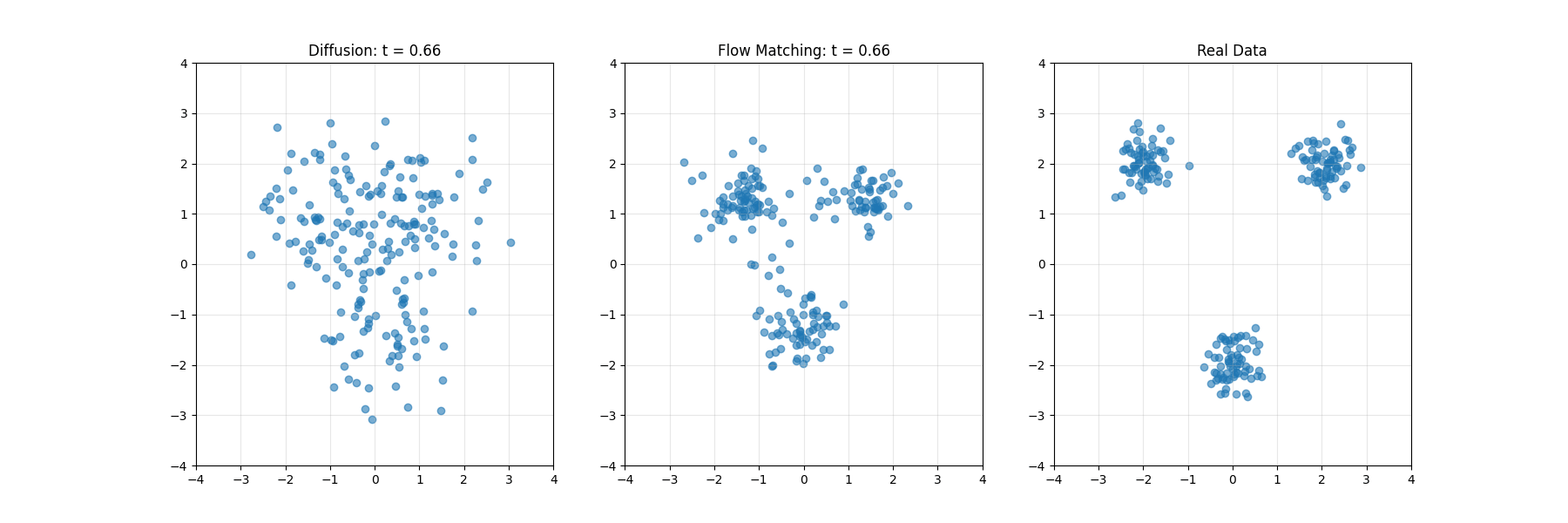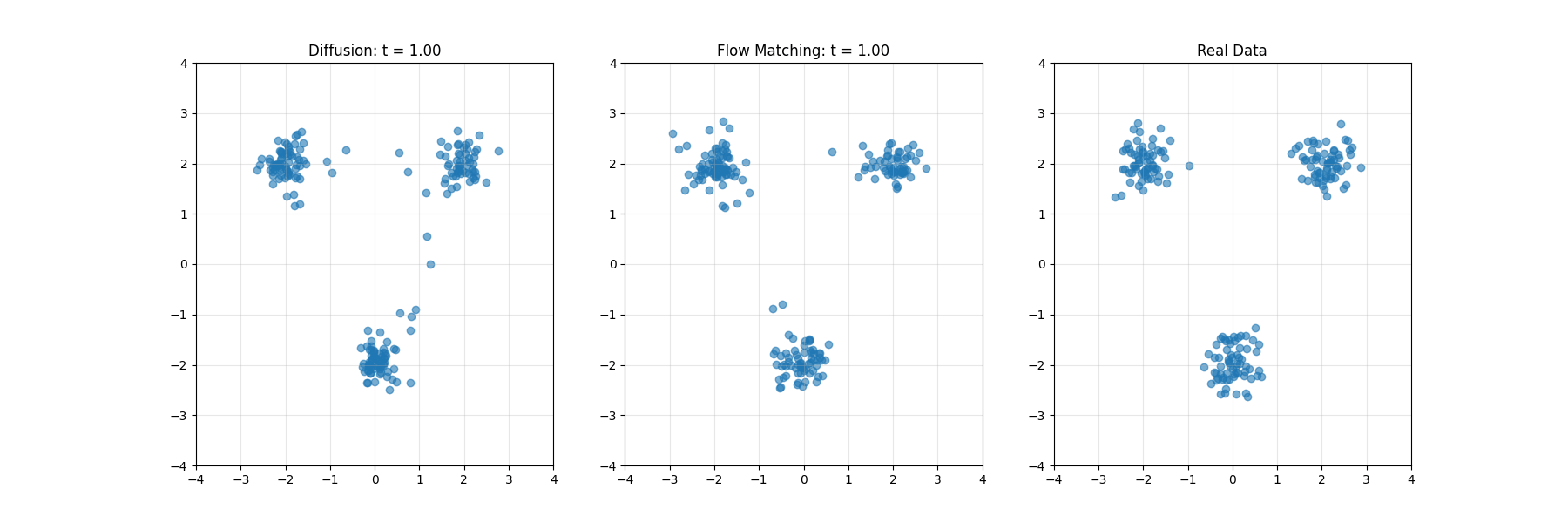
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
京东商品详情API秘籍!Python爬虫轻松获取SKU属性数据
京东商品详情API提供商品基础信息、实时价格、SKU规格及库存等120+字段,支持批量查询(单次200 SKU),数据延迟≤30秒,适用于价格监控、库存管理与竞品分析,基于HTTPS协议,返回标准化JSON格式。
Origin2024 汉化安装专业解析|企业级部署教程+批量激活解决方案
Origin是一款由OriginLab开发的科学绘图与数据分析软件,支持Windows系统,提供丰富的2D/3D图形模板和强大的数据分析功能,如统计、信号处理、图像处理等。本文详细介绍Origin2024的下载与安装步骤,包括解压文件、运行安装程序、输入序列号、安装路径设置及破解方法,帮助用户快速完成软件安装与激活。
京东商品详情API接口(标题|主图|SKU|价格)
京东商品详情API提供标准化接口,支持通过HTTPS获取商品标题、价格、库存、销量等120+字段,数据实时更新至分钟级。包含jd.item.get和jd.union.open.goods.detail.query等接口,支持批量查询200个SKU,适用于价格监控、竞品分析等电商场景。

从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。

Flow Matching生成模型:从理论基础到Pytorch代码实现
本文将系统阐述Flow Matching的完整实现过程,包括数学理论推导、模型架构设计、训练流程构建以及速度场学习等关键组件。通过本文的学习,读者将掌握Flow Matching的核心原理,获得一个完整的PyTorch实现,并对生成模型在噪声调度和分数函数之外的发展方向有更深入的理解。

vLLM推理加速指南:7个技巧让QPS提升30-60%
GPU资源有限,提升推理效率需多管齐下。本文分享vLLM实战调优七招:请求塑形、KV缓存复用、推测解码、量化、并行策略、准入控制与预热监控。结合代码与数据,助你最大化吞吐、降低延迟,实现高QPS稳定服务。
常见的分布式定时任务调度框架
分布式定时任务调度框架用于在分布式系统中管理和调度定时任务,确保任务按预定时间和频率执行。其核心概念包括Job(任务)、Trigger(触发器)、Executor(执行器)和Scheduler(调度器)。这类框架应具备任务管理、任务监控、良好的可扩展性和高可用性等功能。常用的Java生态中的分布式任务调度框架有Quartz Scheduler、ElasticJob和XXL-JOB。
AR技术融入到产品质量检测:提升效率与精度的未来趋势
元幂境认为,AR技术正革新产品质量检测,通过虚实融合提升精度、降低门槛、强化培训与协作,广泛应用于制造、电子、医疗及航空航天领域,未来结合AI将迈向智能检测新阶段。

【大模型私有化部署要花多少钱?】一张图看懂你的钱用在哪
本文探讨了高性价比实现DeepSeek大模型私有化部署的方法,分为两部分: 一是定义大模型性能指标,包括系统级(吞吐量、并发数)与用户体验级(首token生成时间、单token生成时间)指标,并通过roofline模型分析性能瓶颈; 二是评估私有化部署成本,对比不同硬件(如H20和4090)及模型选择,结合业务需求优化资源配置。适合关注数据安全与成本效益的企业参考。
解锁3D创作新姿势!Autodesk 3ds Max 2022中文版安装教程(附官方下载渠道)
Autodesk 3ds Max 2022 是一款专业三维建模、动画和渲染软件,广泛应用于影视、游戏、建筑等领域。其特点包括智能建模工具、高效Arnold渲染引擎、跨平台协作及多语言支持。安装需满足Win10/11系统、i5以上处理器、8GB内存等要求。正版安装流程包括下载官方程序、配置组件、激活许可证并验证功能。常见问题如安装失败、中文乱码等提供了解决方案。扩展学习资源推荐Forest Pack、V-Ray等插件,助力用户深入掌握软件功能。

大语言模型中的归一化技术:LayerNorm与RMSNorm的深入研究
本文分析了大规模Transformer架构(如LLama)中归一化技术的关键作用,重点探讨了LayerNorm被RMSNorm替代的原因。归一化通过调整数据量纲保持分布形态不变,提升计算稳定性和收敛速度。LayerNorm通过均值和方差归一化确保数值稳定,适用于序列模型;而RMSNorm仅使用均方根归一化,省略均值计算,降低计算成本并缓解梯度消失问题。RMSNorm在深层网络中表现出更高的训练稳定性和效率,为复杂模型性能提升做出重要贡献。

【新手必看】PyCharm2025 免费下载安装配置教程+Python环境搭建、图文并茂全副武装学起来才嗖嗖的快,绝对最详细!
PyCharm是由JetBrains开发的Python集成开发环境(IDE),专为Python开发者设计,支持Web开发、调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制等功能。它有专业版、教育版和社区版三个版本,其中社区版免费且适合个人和小型团队使用,包含基本的Python开发功能。安装PyCharm前需先安装Python解释器,并配置环境变量。通过简单的步骤即可在PyCharm中创建并运行Python项目,如输出“Hello World”。
修改 torch和huggingface 缓存路径
简介:本文介绍了如何修改 PyTorch 和 Huggingface Transformers 的缓存路径。通过设置环境变量 `TORCH_HOME` 和 `HF_HOME` 或 `TRANSFORMERS_CACHE`,可以在 Windows、Linux 和 MacOS 上指定自定义缓存目录。具体步骤包括设置环境变量、编辑 shell 配置文件、移动现有缓存文件以及创建符号链接(可选)。
从0到1掌握1688API:图片搜索获取技巧与避坑指南
1688图片搜索API基于图像识别技术,支持上传JPG/PNG格式图片(Base64或URL),实现同款或相似商品搜索。适用于电商选品、供应链管理等场景,提供价格、销量等多维度筛选,返回商品ID、标题、价格、销量及供应商信息。
YOLOv11浅浅解析:架构创新
YOLOv11是YOLO系列最新升级版,通过C3k2模块、SPPF优化和解耦检测头等创新,显著提升检测精度与速度,mAP提高2-5%,推理更快,支持多平台部署,适用于工业、安防、自动驾驶等场景。

广义优势估计(GAE):端策略优化PPO中偏差与方差平衡的关键技术
广义优势估计(GAE)由Schulman等人于2016年提出,是近端策略优化(PPO)算法的核心理论基础。它通过平衡偏差与方差,解决了强化学习中的信用分配问题,即如何准确判定历史动作对延迟奖励的贡献。GAE基于资格迹和TD-λ思想,采用n步优势的指数加权平均方法,将优势函数有效集成到损失函数中,为策略优化提供稳定梯度信号。相比TD-λ,GAE更适用于现代策略梯度方法,推动了高效强化学习算法的发展。
小红书笔记详情 API 接口(小红书 API 系列)
小红书作为热门生活方式平台,拥有海量用户生成内容。通过其笔记详情接口,开发者可获取指定笔记的完整内容、作者信息及互动数据(点赞、评论、收藏数等),助力内容分析与市场调研。接口采用HTTP GET请求,需提供笔记ID,响应数据为JSON格式。注意小红书有严格反爬虫机制,建议使用代理IP并控制请求频率。
Temu商品列表数据接口(Temu API系列)
Temu作为新兴跨境电商平台,为全球卖家和消费者搭建便捷交易桥梁。通过商品列表数据接口,开发者、分析师可获取商品名称、价格、销量等信息,助力市场调研、商品管理和数据分析。接口支持HTTP GET请求,参数包括品类、价格区间、排序方式等,响应格式为JSON。Python示例代码展示了如何调用API获取数据,应用场景涵盖竞争对手分析、选品参考、销售预测及个性化推荐系统开发等。

告别熬夜写代码!VSCode+Cline扩展插件+DeepSeek-V3大模型,让你的编程水平瞬间超越99.9%的人!
逆天改变!VSCode+Cline+DeepSeek-V3,编程界的新王者就是你!

完整教程:从0到1在Windows下训练YOLOv8模型
本文详细介绍在Windows系统下使用YOLOv8训练目标检测模型的完整步骤,涵盖环境配置、数据集准备、模型训练与测试、常见问题解决及GPU加速技巧。提供详细命令与代码示例,并推荐现成数据集与工具,助您高效完成模型训练。
【新模型速递】PAI-Model Gallery云上一键部署Qwen3-Coder模型
Qwen3-Coder 是通义千问最新开源的 AI 编程大模型正式开源,拥有卓越的代码和 Agent 能力,在多领域取得了开源模型的 SOTA 效果。PAI 已支持最强版本 Qwen3-Coder-480B-A35B-Instruct 的云上一键部署。
Office Tool Plus 永恒经典,让每个人都能轻松使用上免费的办公神器!
本文介绍如何使用Office Tool Plus在Windows 11系统上快速、免费安装和激活Office。首先,下载并解压Office Tool Plus,启动后选择“Microsoft 365企业应用版”并设置为简体中文,点击“开始部署”。安装完成后,可通过两种方法激活Office:一是使用命令框输入特定指令,二是通过KMS激活。推荐使用KMS服务器(如kms.loli.beer)进行激活。此外,若之前安装过Office,需先清除激活信息和旧版本残留文件,以确保新安装顺利进行。

摸鱼必备-80款在线HTML小游戏
本文推荐了80款精彩的HTML5在线小游戏,涵盖益智、冒险、射击、体育等多种类型,适合各年龄段玩家。无需下载安装,随时随地畅玩。地址:[https://game.share888.top/](https://game.share888.top/)
大模型推理加速实战:vLLM 部署 Llama3 的量化与批处理优化指南
本文详解如何通过量化与批处理优化,在vLLM中高效部署Llama3大模型。涵盖内存管理、推理加速及混合策略,提升吞吐量并降低延迟,适用于大规模语言模型部署实践。
2025年大模型就业:核心技术趋势、技能要求与职业发展全景解析
随着大语言模型(Large Language Models, LLMs)的技术飞速迭代,人工智能领域正经历从通用对话工具向高度智能化、任务导向的智能体(Agent)系统的深刻转型。到2025年4月,企业对掌握LLM相关技术的专业人才需求持续高涨,核心能力聚焦于检索增强生成(RAG)、智能体任务自动化、模型对齐优化以及多模态融合。本文将全面剖析2025年大模型就业市场的技术演进路径、核心技能要求、行业应用场景、推荐实践项目以及职业发展建议,旨在为从业者提供详尽的职业规划指南,帮助其精准把握行业机遇。
17种RAG实现方法大揭秘
RAG(检索增强生成)通过结合外部知识库与LLM生成能力,有效解决大模型知识滞后与幻觉问题。本文详解三类策略、17种实现方案,涵盖文档分块、检索排序与反馈机制,并提供工程选型指南,助力构建高效智能系统。

加速LLM大模型推理,KV缓存技术详解与PyTorch实现
大型语言模型(LLM)的推理效率是AI领域的重要挑战。本文聚焦KV缓存技术,通过存储复用注意力机制中的Key和Value张量,减少冗余计算,显著提升推理效率。文章从理论到实践,详细解析KV缓存原理、实现与性能优势,并提供PyTorch代码示例。实验表明,该技术在长序列生成中可将推理时间降低近60%,为大模型优化提供了有效方案。

多模态AI核心技术:CLIP与SigLIP技术原理与应用进展
近年来,多模态表示学习在人工智能领域取得显著进展,CLIP和SigLIP成为里程碑式模型。CLIP由OpenAI提出,通过对比学习对齐图像与文本嵌入空间,具备强大零样本学习能力;SigLIP由Google开发,采用sigmoid损失函数优化训练效率与可扩展性。两者推动了多模态大型语言模型(MLLMs)的发展,如LLaVA、BLIP-2和Flamingo等,实现了视觉问答、图像描述生成等复杂任务。这些模型不仅拓展了理论边界,还为医疗、教育等领域释放技术潜力,标志着多模态智能系统的重要进步。
反向海淘实战:Pandabuy、Hoobuy、CNFans 代购集运系统搭建真实体验
2025年,反向海淘成为新趋势。CSDN博主耗时2个月,模拟留学生、海外华人等场景,深度体验Pandabuy、Hoobuy、CNFans三大代购平台。Pandabuy极简易用,Hoobuy稳健实用,CNFans技术强大。通过真实案例分析,探讨各平台优劣及未来AI发展趋势,帮助用户避开常见陷阱,选择最适合的购物方案。

资料合集|Flink Forward Asia 2024 上海站
Apache Flink 年度技术盛会聚焦“回顾过去,展望未来”,涵盖流式湖仓、流批一体、Data+AI 等八大核心议题,近百家厂商参与,深入探讨前沿技术发展。小松鼠为大家整理了 FFA 2024 演讲 PPT ,可在线阅读和下载。

Flink 四大基石之 Checkpoint 使用详解
Flink 的 Checkpoint 机制通过定期插入 Barrier 将数据流切分并进行快照,确保故障时能从最近的 Checkpoint 恢复,保障数据一致性。Checkpoint 分为精确一次和至少一次两种语义,前者确保每个数据仅处理一次,后者允许重复处理但不会丢失数据。此外,Flink 提供多种重启策略,如固定延迟、失败率和无重启策略,以应对不同场景。SavePoint 是手动触发的 Checkpoint,用于作业升级和迁移。Checkpoint 执行流程包括 Barrier 注入、算子状态快照、Barrier 对齐和完成 Checkpoint。
Python 实战:用 API 接口批量抓取小红书笔记评论,解锁数据采集新姿势
小红书作为社交电商的重要平台,其笔记评论蕴含丰富市场洞察与用户反馈。本文介绍的小红书笔记评论API,可获取指定笔记的评论详情(如内容、点赞数等),支持分页与身份认证。开发者可通过HTTP请求提取数据,以JSON格式返回。附Python调用示例代码,帮助快速上手分析用户互动数据,优化品牌策略与用户体验。

2025年GitHub平台上的十大开源MCP服务器汇总分析
本文深入解析了GitHub上十个代表性MCP(Model Context Protocol)服务器项目,探讨其在连接AI与现实世界中的关键作用。这些服务器实现了AI模型与应用程序、数据库、云存储、项目管理等工具的无缝交互,扩展了AI的应用边界。文中涵盖Airbnb、Supabase、AWS-S3、Kubernetes等领域的MCP实现方案,展示了AI在旅行规划、数据处理、云存储、容器编排等场景中的深度应用。未来,MCP技术将向标准化、安全性及行业定制化方向发展,为AI系统集成提供更强大的支持。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。



