









记忆层增强的 Transformer 架构:通过可训练键值存储提升 LLM 性能的创新方法
Meta研究团队开发的记忆层技术通过替换Transformer中的前馈网络(FFN),显著提升了大语言模型的性能。记忆层使用可训练的固定键值对,规模达百万级别,仅计算最相似的前k个键值,优化了计算效率。实验显示,记忆层使模型在事实准确性上提升超100%,且在代码生成和通用知识领域表现优异,媲美4倍计算资源训练的传统模型。这一创新对下一代AI架构的发展具有重要意义。
探秘站点检测访问中代理 IP 的实用技巧
随着互联网发展,使用代理IP的需求增加。站点检测代理IP的方法包括:1. IP地址黑名单;2. HTTP头部检查(如X-Forwarded-For);3. 行为分析;4. 地理位置检测;5. CAPTCHA验证;6. 连接特征分析。这些技术帮助网站判断访问是否来自代理。
构建AI数据管道:从数据到洞察的高效之旅最佳实践
本文探讨了大模型从数据处理、模型训练到推理的全流程解决方案,特别强调数据、算法和算力三大要素。在数据处理方面,介绍了多模态数据的高效清洗与存储优化;模型训练中,重点解决了大规模数据集和CheckPoint的高效管理;推理部分则通过P2P分布式加载等技术提升效率。案例展示了如何在云平台上实现高性能、低成本的数据处理与模型训练,确保业务场景下的最优表现。
推理降本与提升资源效率的实践
本课程从业务角度探讨大模型推理部署及资源利用率提升。首先分析大模型与GPU发展趋势,包括模型开源、规模增长及多模态能力增强;其次介绍高效部署大模型推理业务的步骤,涵盖业务场景选择、架构优化及显存规划;接着讲解如何通过DeepCPU-LLM框架和DeepNCCL通讯库优化推理效率;最后探讨通过KuberGPU实现细粒度GPU资源管理,提升整体资源利用率,降低推理成本。

StarRocks元数据无法合并
StarRocks版本在3.1.4及以下,并且使用了metadata_journal_skip_bad_journal_ids来跳过某个异常的journal,会导致FE元数据无法合并。
BERT的继任者ModernBERT:融合长序列处理、代码理解与高效计算的新一代双向编码器
ModernBERT 是一个全新的模型系列,在**速度**和**准确性**两个维度上全面超越了 BERT 及其后继模型。

Apache Flink 2.0:Streaming into the Future
本文整理自阿里云智能高级技术专家宋辛童、资深技术专家梅源和高级技术专家李麟在 Flink Forward Asia 2024 主会场的分享。三位专家详细介绍了 Flink 2.0 的四大技术方向:Streaming、Stream-Batch Unification、Streaming Lakehouse 和 AI。主要内容包括 Flink 2.0 的存算分离云原生化、流批一体的 Materialized Table、Flink 与 Paimon 的深度集成,以及 Flink 在 AI 领域的应用。
物联网 GE-PREDIX
GE-Predix 是通用电气(GE)推出的一个工业互联网平台,旨在通过连接机器、数据与人,实现工业资产的智能管理和优化。该平台支持从设备监控到预测性维护等多种应用,助力企业提升运营效率和创新能力。

深入探讨 Puppeteer 如何使用 X 和 Y 坐标实现鼠标移动
本文介绍了如何利用Puppeteer实现鼠标移动模拟、代理IP技术、自定义请求头等方法,以增强爬虫的伪装性,成功抓取小红书等反爬能力强的网站内容。通过详细代码示例,展示了从配置代理到模拟用户行为的全过程。

通过pin_memory 优化 PyTorch 数据加载和传输:工作原理、使用场景与性能分析
在 PyTorch 中,`pin_memory` 是一个重要的设置,可以显著提高 CPU 与 GPU 之间的数据传输速度。当 `pin_memory=True` 时,数据会被固定在 CPU 的 RAM 中,从而加快传输到 GPU 的速度。这对于处理大规模数据集、实时推理和多 GPU 训练等任务尤为重要。本文详细探讨了 `pin_memory` 的作用、工作原理及最佳实践,帮助你优化数据加载和传输,提升模型性能。

氛围编程陷阱:为什么AI生成代码正在制造大量"伪开发者"
AI兴起催生“氛围编程”——用自然语言生成代码,看似高效实则陷阱。它让人跳过编程基本功,沦为只会提示、不懂原理的“中间商”。真实案例显示,此类项目易崩溃、难维护,安全漏洞频出。AI是技能倍增器,非替代品;真正强大的开发者,永远是那些基础扎实、能独立解决问题的人。

Python离群值检测实战:使用distfit库实现基于分布拟合的异常检测
本文解析异常(anomaly)与新颖性(novelty)检测的本质差异,结合distfit库演示基于概率密度拟合的单变量无监督异常检测方法,涵盖全局、上下文与集体离群值识别,助力构建高可解释性模型。

Transformer自回归关键技术:掩码注意力原理与PyTorch完整实现
掩码注意力是生成模型的核心,通过上三角掩码限制模型仅关注当前及之前token,确保自回归因果性。相比BERT的双向注意力,它实现单向生成,是GPT等模型逐词预测的关键机制,核心仅需一步`masked_fill_`操作。
搭建实时足球比分系统从零到一的实战指南
构建实时足球比分系统需聚焦数据流架构:从API/爬虫获取数据,经后端处理存储,通过REST/WebSocket提供接口,前端展示。推荐使用专业API保障稳定性,结合Python/Node.js、PostgreSQL/MongoDB、Redis缓存与WebSocket实现实时推送。优先考虑法律合规与高并发应对,建议逐步迭代开发,亦可借助现成插件或服务快速上线。(238字)

从零搭建RAG应用:跳过LangChain,掌握文本分块、向量检索、指代消解等核心技术实现
本文详解如何从零搭建RAG(检索增强生成)应用,跳过LangChain等框架,深入掌握文本解析、分块、向量检索、对话记忆、指代消解等核心技术,提升系统可控性与优化能力。
2025 年小白也能轻松上手的 Java 最新学习路线与实操指南深度剖析
2025年Java最新学习路线与实操指南,涵盖基础语法、JVM调优、Spring Boot 3.x框架、微服务架构及容器化部署,结合实操案例,助你快速掌握企业级Java开发技能。
基于python大数据的招聘数据可视化分析系统
本系统基于Python开发,整合多渠道招聘数据,利用数据分析与可视化技术,助力企业高效决策。核心功能包括数据采集、智能分析、可视化展示及权限管理,提升招聘效率与人才管理水平,推动人力资源管理数字化转型。
基于python大数据的nba球员可视化分析系统
本课题围绕NBA球员数据分析与可视化展开,探讨如何利用大数据与可视化技术提升篮球运动的表现评估与决策支持能力。研究涵盖数据采集、处理与可视化呈现,结合SQLite、Flask、Echarts等技术构建分析系统,助力球队训练、战术制定及球迷观赛体验提升。

MXFP4量化:如何在80GB GPU上运行1200亿参数的GPT-OSS模型
GPT-OSS通过MXFP4量化技术实现1200亿参数模型在单个80GB GPU上的高效运行,将权重压缩至每参数4.25位,大幅降低内存需求,同时保持高精度和竞争力的基准性能,为大规模模型部署提供了新思路。
大数据AI产品月刊-2025年7月
大数据& AI 产品技术月刊【2025年7月】,涵盖7月技术速递、产品和功能发布、市场和客户应用实践等内容,帮助您快速了解阿里云大数据& AI 方面最新动态。
Redis核心数据结构与分布式锁实现详解
Redis 是高性能键值数据库,支持多种数据结构,如字符串、列表、集合、哈希、有序集合等,广泛用于缓存、消息队列和实时数据处理。本文详解其核心数据结构及分布式锁实现,帮助开发者提升系统性能与并发控制能力。
Python AutoML框架选型攻略:7个工具性能对比与应用指南
本文系统介绍了主流Python AutoML库的技术特点与适用场景,涵盖AutoGluon、PyCaret、TPOT、Auto-sklearn、H2O AutoML及AutoKeras等工具,帮助开发者根据项目需求高效选择自动化机器学习方案。
深入研究:shopee商品详情API接口Python攻略
Shopee 商品详情 API 是用于获取 Shopee 平台商品详细信息的接口,支持开发者提取商品标题、价格、库存、描述和图片等多维度数据。该接口适用于电商数据分析、比价工具开发及商品监控等场景。请求方式为 GET,需提供 itemid(商品 ID)和 shopid(店铺 ID),返回格式为 JSON。部分功能可能需要 API 密钥或访问令牌认证。以马来西亚站点为例,URL 为 shopee.com.myapi/v4/item/get,不同国家站点域名可能有所不同。

NLP助力非结构化文本抽取:实体关系提取实战
本文介绍了一套基于微博热帖的中文非结构化文本分析系统,通过爬虫代理采集数据,结合NLP技术实现实体识别、关系抽取及情感分析。核心技术包括爬虫模块、请求配置、页面采集和中文NLP处理,最终将数据结构化并保存为CSV文件或生成图谱。代码示例从基础正则规则到高级深度学习模型(如BERT-BiLSTM-CRF)逐步演进,适合初学者与进阶用户调试与扩展,展现了中文NLP在实际场景中的应用价值。
Hologres+函数计算+Qwen3,对接MCP构建企业级数据分析 Agent
本文介绍了通过阿里云Hologres、函数计算FC和通义千问Qwen3构建企业级数据分析Agent的解决方案。大模型在数据分析中潜力巨大,但面临实时数据接入与跨系统整合等挑战。MCP(模型上下文协议)提供标准化接口,实现AI模型与外部资源解耦。方案利用SSE模式连接,具备高实时性、良好解耦性和轻量级特性。Hologres作为高性能实时数仓,支持多源数据毫秒级接入与分析;函数计算FC以Serverless模式部署,弹性扩缩降低成本;Qwen3则具备强大的推理与多语言能力。用户可通过ModelScope的MCP Playground快速体验,结合TPC-H样例数据完成复杂查询任务。
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
碧桂园服务通过引入 EMR Serverless StarRocks 存算分离架构,解决了海量数据处理中的资源利用率低、并发能力不足等问题,显著降低了硬件和运维成本。实时查询性能提升8倍,查询出错率减少30倍,集群数据 SLA 达99.99%。此次技术升级不仅优化了用户体验,还结合AI打造了“一看”和“—问”智能场景助力精准决策与风险预测。
体育比分网站开发如何选择靠谱的数据服务商
在开发体育比分网站时,选择数据服务商至关重要。熊猫比分凭借低延迟(<1秒)、高并发架构(支持10万+ QPS)、7×24小时技术支持及标准化API等优势脱颖而出。避免数据服务中的雷点,如高延迟、并发不足、售后迟缓和接口混乱,确保用户体验。开发者可联系大卫获取3天免费测试接口,验证数据质量与稳定性。代码示例展示了如何处理比赛数据,包括设置比赛ID、状态、计划标记和关注状态等功能。
优质网络舆情监测系统大盘点
一款出色的网络舆情监测系统,不仅能够助力相关主体迅速捕捉舆情信息,有效应对危机,还能够助力其更好地把握舆论动态,维护自身形象。那么,市场上有哪些比较好的网络舆情监测系统呢?这里,本文有为各位整理了一些好用的舆情检测系统,以供各位参考!
解锁 DeepSeek API 接口:构建智能应用的技术密钥
在数字化时代,智能应用蓬勃发展,DeepSeek API 作为关键技术之一,提供了强大的自然语言处理能力。本文详细介绍 DeepSeek API,并通过 Python 请求示例帮助开发者快速上手。DeepSeek API 支持文本生成、问答系统、情感分析和文本分类等功能,具备高度灵活性和可扩展性,适用于多种场景。示例展示了如何使用 Python 调用 API 生成关于“人工智能在医疗领域的应用”的短文。供稿者:Taobaoapi2014。
酒店旅游API:数据交互的隐形桥梁——以携程API为例
携程API提供酒店旅游行业的实时数据互通、业务自动化及生态扩展功能,涵盖酒店详情获取、搜索、房态管理、订单处理和支付等核心接口。技术架构采用微服务集群与数据中台,支持高并发和金融级安全防护。挑战包括高并发、数据一致性和商业博弈,未来将融合AI、元宇宙和区块链技术,实现智能旅游体验。
美的楼宇科技基于阿里云 EMR Serverless Spark 构建 LakeHouse 湖仓数据平台
美的楼宇科技基于阿里云 EMR Serverless Spark 建设 IoT 数据平台,实现了数据与 AI 技术的有效融合,解决了美的楼宇科技设备数据量庞大且持续增长、数据半结构化、数据价值缺乏深度挖掘的痛点问题。并结合 EMR Serverless StarRocks 搭建了 Lakehouse 平台,最终实现不同场景下整体性能提升50%以上,同时综合成本下降30%。
ssm026校园美食交流系统(文档+源码)_kaic
本文介绍了基于Java语言和MySQL数据库的校园美食交流系统的设计与实现。该系统采用B/S架构和SSM框架,旨在提高校园美食信息管理的效率与便捷性。主要内容包括:系统的开发背景、目的及内容;对Java技术、MySQL数据库、B/S结构和SSM框架的介绍;系统分析部分涵盖可行性分析、性能分析和功能需求分析;最后详细描述了系统各功能模块的具体实现,如登录、管理员功能(美食分类管理、用户管理等)和前台首页功能。通过此系统,管理员可以高效管理美食信息,用户也能方便地获取和分享美食资讯,从而提升校园美食交流的管理水平和用户体验。

构建可靠的时间序列预测模型:数据泄露检测、前瞻性偏差消除与因果关系验证
在时间序列分析中,数据泄露、前瞻性偏差和因果关系违反是三大常见且严重影响模型有效性的技术挑战。数据泄露指预测模型错误使用了未来信息,导致训练时表现优异但实际性能差;前瞻性偏差则是因获取未来数据而产生的系统性误差;因果关系违反则可能导致虚假相关性和误导性结论。通过严格的时序数据分割、特征工程规范化及因果分析方法(如格兰杰因果检验),可以有效防范这些问题,确保模型的可靠性和实用性。示例分析展示了日本天然气价格数据中的具体影响及防范措施。 [深入阅读](https://avoid.overfit.cn/post/122b36fdb8cb402f95cc5b6f2a22f105)
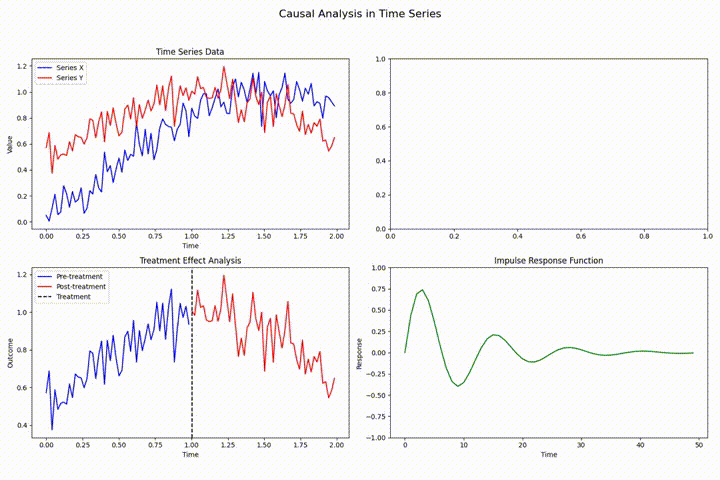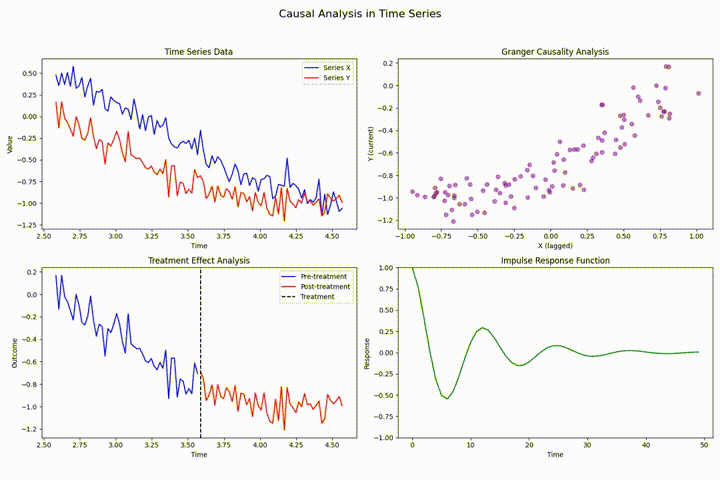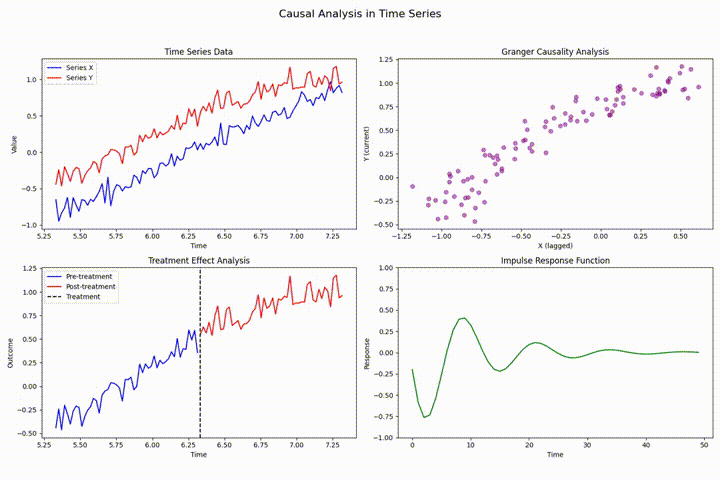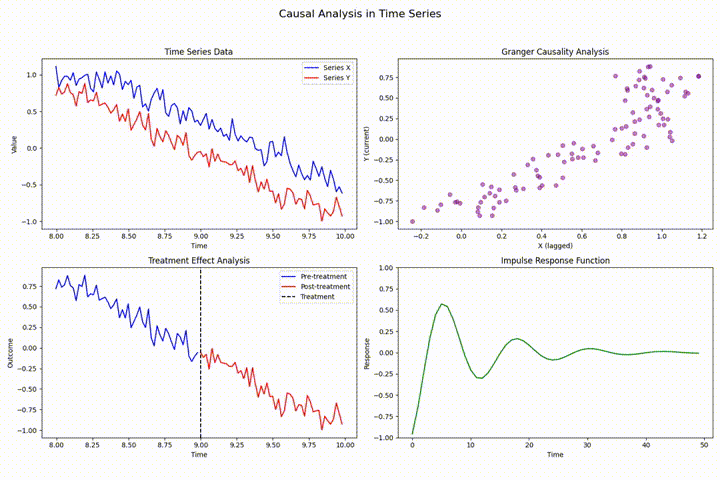
时间序列分析中的状态估计:状态空间模型与卡尔曼滤波的隐状态估计
状态空间模型通过构建生成可观测数据的潜在未观测状态来进行时间序列分析,卡尔曼滤波为其核心,提供实时隐状态估计。本文深入探讨其理论基础与实践应用,涵盖线性及非线性系统的高级滤波算法(如EKF和UKF),并展示在运动目标跟踪等领域的具体应用,强调了参数调优和性能评估的重要性。
面向法律场景的大模型 RAG 检索增强解决方案
检索增强生成模型结合了信息检索与生成式人工智能的优点,从而在特定场景下提供更为精准和相关的答案。以人工智能平台 PAI 为例,为您介绍在云上使用一站式白盒化大模型应用开发平台 PAI-LangStudio 构建面向法律场景的大模型 RAG 检索增强解决方案,应用构建更简便,开发环境更直观。此外,PAI 平台同样发布了面向医疗、金融和教育领域的 RAG 解决方案。
实时计算UniFlow:Flink+Paimon构建流批一体实时湖仓
实时计算架构中,传统湖仓架构在数据流量管控和应用场景支持上表现良好,但在实际运营中常忽略细节,导致新问题。为解决这些问题,提出了流批一体的实时计算湖仓架构——UniFlow。该架构通过统一的流批计算引擎、存储格式(如Paimon)和Flink CDC工具,简化开发流程,降低成本,并确保数据一致性和实时性。UniFlow还引入了Flink Materialized Table,实现了声明式ETL,优化了调度和执行模式,使用户能灵活调整新鲜度与成本。最终,UniFlow不仅提高了开发和运维效率,还提供了更实时的数据支持,满足业务决策需求。
高真实感3D高斯数字化身
本次分享介绍了3D高速扩建高新作为一种新的可微渲染技术,特别是高斯泼溅技术在数字化身3D领域的应用。该技术通过高斯点云扩展传统3D点云属性,实现高真实感、实时交互渲染,优化3D重建与多视点图像生成。文中还探讨了数字化身的构建与应用,包括全身和人头模型的创建,并展示了其在不同环境光照下的效果。最后,提出了未来研究方向,如更灵活的编辑和视频生成大模型的融合,以提升数字人的可控性和真实感。

高精度保形滤波器Savitzky-Golay的数学原理、Python实现与工程应用
Savitzky-Golay滤波器是一种基于局部多项式回归的数字滤波器,广泛应用于信号处理领域。它通过线性最小二乘法拟合低阶多项式到滑动窗口中的数据点,在降噪的同时保持信号的关键特征,如峰值和谷值。本文介绍了该滤波器的原理、实现及应用,展示了其在Python中的具体实现,并分析了不同参数对滤波效果的影响。适合需要保持信号特征的应用场景。

探索Flink动态CEP:杭州银行的实战案例
本文由杭州银行大数据工程师唐占峰、欧阳武林撰写,介绍Flink动态CEP的定义、应用场景、技术实现及使用方式。Flink动态CEP是基于Flink的复杂事件处理库,支持在不重启服务的情况下动态更新规则,适应快速变化的业务需求。文章详细阐述了其在反洗钱、反欺诈和实时营销等金融领域的应用,并展示了某金融机构的实际应用案例。通过动态CEP,用户可以实时调整规则,提高系统的灵活性和响应速度,降低维护成本。文中还提供了具体的代码示例和技术细节,帮助读者理解和使用Flink动态CEP。

[开发技巧] 如何获取汉字笔画数?
在开发卜筮小脚本时遇到获取汉字笔画数的需求,起初尝试使用`pypinyin`库却未得理想结果。经过探索,发现Unicode联盟维护的Unihan数据库提供准确的汉字笔画数据。通过下载Unihan数据库文件,解析其中的`kTotalStrokes`字段,利用正则表达式提取所需信息,并将其保存为JSON格式以供快速查询。最终编写函数`get_character_stroke_count`实现任意汉字笔画数的高效获取,满足了项目需求并提供了准确的数据支持。此方法不仅解决了问题,还为类似需求提供了参考方案。
淘宝图片搜索接口(Taobao.item_search_img)
淘宝图片搜索接口(Taobao.item_search_img)允许开发者通过上传商品图片或提供图片地址,获取相似的淘宝商品列表。该接口基于深度学习和计算机视觉技术,支持注册账号、申请权限、构造请求参数、调用接口、解析响应数据等步骤。适用于电商平台购物体验提升、商家商品优化与推广、商品推荐系统和图片版权保护等场景。

基于阿里云Elasticsearch Enterprise构建AI搜索与可观测Chatbot
本次公开课我们将深入探讨如何构建高效的AI技术解决方案,Elastic和阿里云搜索技术专家将深入解读阿里云Elasticsearch Enterprise版的AI功能及其在实际应用。通过公开课,您可以了解构建AI搜索和AI Assistant的技术原理,并轻松掌握从0到1搭建企业级RAG应用,和基于大模型搭建可观测Chatbot,获取运维洞察。 讲师/嘉宾简介 朱杰(Elastic中国首席解决方案架构师、Elastic社区和阿里云Elasticsearch社区布道者) 槐新 (阿里云Elasticsearch引擎研发工程师)
熊猫比分-专业体育赛事直播app/网页搭建
体育赛事直播APP已成为体育迷观看和讨论赛事的重要渠道。其核心功能包括:1) 实时直播,支持转播、录播、回放,确保低延迟、高流畅度和优质画质;2) 比分数据分析,提供首发阵容、历史对战等信息;3) 用户互动,支持评论、打赏及私聊;4) 主播中心,允许用户申请成为主播并获平台支持。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

