








淘宝 / 天猫官方商品 / 订单订单 API 接口丨商品上传接口对接步骤
要对接淘宝/天猫官方商品或订单API,需先注册淘宝开放平台账号,创建应用获取App Key和App Secret。之后,详细阅读API文档,了解接口功能及权限要求,编写认证、构建请求、发送请求和处理响应的代码。最后,在沙箱环境中测试与调试,确保API调用的正确性和稳定性。
【2025云栖大会】阿里云AI搜索年度发布:开启Agent时代,重构搜索新范式
2025云栖大会阿里云AI搜索专场上,发布了年度AI搜索技术与产品升级成果,推出Agentic Search架构创新与云原生引擎技术突破,实现从“信息匹配”到“智能问题解决”的跨越,支持多模态检索、百亿向量处理,助力企业降本增效,推动搜索迈向主动服务新时代。
基于springboot的电影购票管理系统
本系统基于Spring Boot框架,结合Vue、Java与MySQL技术,实现电影信息管理、在线选座、购票支付等核心功能,提升观众购票体验与影院管理效率,推动电影产业数字化发展。

JAX快速上手:从NumPy到GPU加速的Python高性能计算库入门教程
JAX是Google开发的高性能数值计算库,旨在解决NumPy在现代计算需求下的局限性。它不仅兼容NumPy的API,还引入了自动微分、GPU/TPU加速和即时编译(JIT)等关键功能,显著提升了计算效率。JAX适用于机器学习、科学模拟等需要大规模计算和梯度优化的场景,为Python在高性能计算领域开辟了新路径。
基于PAI-ChatLearn的GSPO强化学习实践
近期,阿里通义千问团队创新性提出了GSPO算法,GSPO 算法与其他 RL 算法相比,定义了序列级别的重要性比率,并在序列层面执行裁剪、奖励和优化。同时具有强大高效、稳定性出色、基础设施友好的突出优势。
Flink 2.1 SQL:解锁实时数据与AI集成,实现可扩展流处理
简介:本文整理自阿里云高级技术专家李麟在Flink Forward Asia 2025新加坡站的分享,介绍了Flink 2.1 SQL在实时数据处理与AI融合方面的关键进展,包括AI函数集成、Join优化及未来发展方向,助力构建高效实时AI管道。
大数据之路:阿里巴巴大数据实践——日志采集与数据同步
本资料全面介绍大数据处理技术架构,涵盖数据采集、同步、计算与服务全流程。内容包括Web/App端日志采集方案、数据同步工具DataX与TimeTunnel、离线与实时数仓架构、OneData方法论及元数据管理等核心内容,适用于构建企业级数据平台体系。
开源AI BI可视化工具-dataline
DataLine 是一个开源数据分析工具,支持自然语言交互,可快速生成图表与报告。数据默认存储本地,保障隐私安全,兼容 Postgres、MySQL、Excel 等多种数据源。提供可视化仪表盘、触发器及知识库功能,支持 Windows、Mac、Linux 平台运行,并可通过 Docker 部署,适合企业使用。
AI重构数据价值链,解码「智能问数」如何赋能医药制造
随着中国医药制造业的蓬勃发展,中国已跃居全球第二大医药市场。随着监管政策的深入实施,市场对医药企业在生产、运营、管理等方面提出了更为严苛的要求。2025年政府工作报告明确提出,持续推进“人工智能+”行动,将数字技术与制造优势、市场优势更好结合起来,支持大模型广泛应用。
VIN码查询_标准版API:帮助解锁车辆的“身份证”详细信息的实战指南
VIN码(车辆识别号码)是由17位字母和数字组成的全球唯一编码,相当于汽车的“身份证”。通过解析VIN码,可获取品牌、车系、生产年份等关键信息。探数API平台的VIN码查询API(标准版),只需输入VIN码即可返回完整车辆配置信息。 该API适用于多种场景:电商平台可自动填充商品详情,提升准确性;维修行业能精准匹配零件与诊断需求;二手车市场则增强交易透明度与安全性。其调用流程简单,包括准备VIN码、构造请求、处理响应及异常处理。 VIN码不仅是查询工具,更是连接制造、销售、维修、保险等环节的纽带。
DistilQwen-ThoughtX:变长思维链推理模型,能力超越DeepSeek蒸馏模型
阿里云PAI团队开发的 OmniThought 数据集,其中包含200万思维链,并标注了推理冗余度(RV)和认知难度(CD)分数。基于此数据集,我们还推出了 DistilQwen-ThoughtX 系列模型,可以通过RV和CD分数对思维链进行筛选,训练得到的模型获得根据问题和本身的认知能力,生成变长思维链的能力。同时在 EasyDistill 框架中开源了 OmniThought 数据集和 DistilQwen-ThoughtX 模型的全部权重。这些模型在性能上超过了 DeepSeek-R1-Distill 系列。

鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
鹰角网络为应对游戏业务高频活动带来的数据潮汐、资源弹性及稳定性需求,采用阿里云 EMR Serverless Spark 替代原有架构。迁移后实现研发效率提升,支持业务快速发展、计算效率提升,增强SLA保障,稳定性提升,降低运维成本,并支撑全球化数据架构部署。
浏览器自动化检测对抗:修改navigator.webdriver属性的底层实现
本文介绍了如何构建一个反检测爬虫以爬取Amazon商品信息。通过使用`undetected-chromedriver`规避自动化检测,修改`navigator.webdriver`属性隐藏痕迹,并结合代理、Cookie和User-Agent技术,实现稳定的数据采集。代码包含浏览器配置、无痕设置、关键词搜索及数据提取等功能,同时提供常见问题解决方法,助你高效应对反爬策略。

Playwright多语言生态:跨Python/Java/.NET的统一采集方案
随着数据采集需求的增加,传统爬虫工具如Selenium、Jsoup等因语言割裂、JS渲染困难及代理兼容性差等问题,难以满足现代网站抓取需求。微软推出的Playwright框架,凭借多语言支持(Python/Java/.NET/Node.js)、统一API接口和优异的JS兼容性,解决了跨语言协作、动态页面解析和身份伪装等痛点。其性能优于Selenium与Puppeteer,在学术数据库(如Scopus)抓取中表现出色。行业应用广泛,涵盖高校科研、大型数据公司及AI初创团队,助力构建高效稳定的爬虫系统。
强化学习:时间差分(TD)(SARSA算法和Q-Learning算法)(看不懂算我输专栏)——手把手教你入门强化学习(六)
本文介绍了时间差分法(TD)中的两种经典算法:SARSA和Q-Learning。二者均为无模型强化学习方法,通过与环境交互估算动作价值函数。SARSA是On-Policy算法,采用ε-greedy策略进行动作选择和评估;而Q-Learning为Off-Policy算法,评估时选取下一状态中估值最大的动作。相比动态规划和蒙特卡洛方法,TD算法结合了自举更新与样本更新的优势,实现边行动边学习。文章通过生动的例子解释了两者的差异,并提供了伪代码帮助理解。
vscode推送项目到github仓库故障解决1
本文介绍了如何优雅解决本地仓库与远程仓库历史记录不一致的问题,并提供避免未来问题的最佳实践。核心在于理解问题根源(如历史记录差异和常见原因),采用推荐的解决方案(先本地初始化再关联远程仓库),并遵循一致的工作流程、团队协作规范及熟悉 Git 命令。通过强制推送或合并无关历史记录等方式处理现有冲突,同时养成良好习惯以预防类似问题。
ollama+openwebui本地部署deepseek 7b
Ollama是一个开源平台,用于本地部署和管理大型语言模型(LLMs),简化了模型的训练、部署与监控过程,并支持多种机器学习框架。用户可以通过简单的命令行操作完成模型的安装与运行,如下载指定模型并启动交互式会话。对于环境配置,Ollama提供了灵活的环境变量设置,以适应不同的服务器需求。结合Open WebUI,一个自托管且功能丰富的Web界面,用户可以更便捷地管理和使用这些大模型,即使在完全离线的环境中也能顺利操作。此外,通过配置特定环境变量,解决了国内访问限制的问题,例如使用镜像站来替代无法直接访问的服务。

DeepSeek背后的技术基石:DeepSeekMoE基于专家混合系统的大规模语言模型架构
DeepSeekMoE是一种创新的大规模语言模型架构,融合了专家混合系统(MoE)、多头潜在注意力机制(MLA)和RMSNorm归一化。通过专家共享、动态路由和潜在变量缓存技术,DeepSeekMoE在保持性能的同时,将计算开销降低了40%,显著提升了训练和推理效率。该模型在语言建模、机器翻译和长文本处理等任务中表现出色,具备广泛的应用前景,特别是在计算资源受限的场景下。
基于DWA优化算法的机器人路径规划matlab仿真
本项目基于DWA优化算法实现机器人路径规划的MATLAB仿真,适用于动态环境下的自主导航。使用MATLAB2022A版本运行,展示路径规划和预测结果。核心代码通过散点图和轨迹图可视化路径点及预测路径。DWA算法通过定义速度空间、采样候选动作并评估其优劣(目标方向性、障碍物距离、速度一致性),实时调整机器人运动参数,确保安全避障并接近目标。
AirMSPI 椭圆体投影地理坐标辐射度产品包含云、气溶胶和地球表面的辐射和偏振图像
AirMSPI_ImPACT-PM_Ellipsoid-projected_Georegistered_Radiance_Data 是在 ImPACT-PM 飞行活动中获取的 AirMSPI 第6版椭球投影地理坐标辐射度产品。该数据包含云、气溶胶和地球表面的多角度、多光谱及偏振信息,涵盖8个波长(355至935纳米),并提供辐照度、时间、角度等参数。特别适用于大气颗粒物研究和遥感应用。数据格式为 HDF-EOS-5,采集时间为2016年7月5日至8日。
面向AI的服务器计算互连的创新探索
面向AI的服务器计算互连创新探索主要涵盖三个方向:Scale UP互连、AI高性能网卡及CIPU技术。Scale UP互连通过ALink系统实现极致性能,支持大规模模型训练,满足智算集群需求。AI高性能网卡针对大规模GPU通信和存储挑战,自研EIC网卡提供400G带宽和RDMA卸载加速,优化网络传输。CIPU作为云基础设施核心,支持虚拟化、存储与网络资源池化,提升资源利用率和稳定性,未来将扩展至2*800G带宽,全面覆盖阿里云业务需求。这些技术共同推动了AI计算的高效互联与性能突破。
拼多多商品详情API技术指南
拼多多商品详情API(pdd.goods.detail.get)支持通过商品ID获取商品标题、价格、销量、图片、库存及评价等详细信息,适用于电商数据分析、竞品监控与价格策略优化,返回标准JSON格式,便于集成开发。
(Pandas)Python做数据处理必选框架之一!(一):介绍Pandas中的两个数据结构;刨析Series:如何访问数据;数据去重、取众数、总和、标准差、方差、平均值等;判断缺失值、获取索引...
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。 Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。 Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。 Pandas 主要引入了两种新的数据结构:Series 和 DataFrame。

秒级行情推送系统实战:从触发、采集到入库的端到端架构
本文设计了一套秒级实时行情推送系统,涵盖触发、采集、缓冲、入库与推送五层架构,结合动态代理IP、Kafka/Redis缓冲及WebSocket推送,实现金融数据低延迟、高并发处理,适用于股票、数字货币等实时行情场景。

用Playwright打造可靠的企业级采集方案--从单机验证到集群化落地
本项目将单机Playwright爬虫逐步演进为分布式集群,解决脚本不稳定、限速、维护难等问题。以招聘数据采集为例,实现从页面解析、代理IP轮换、Redis任务队列到多机并发的完整链路,结合MongoDB/Elasticsearch落库与可视化,形成可复用的生产级爬虫架构,适用于数据分析、岗位监控等场景。
Transformer架构的简要解析
Transformer架构自2017年提出以来,彻底革新了人工智能领域,广泛应用于自然语言处理、语音识别等任务。其核心创新在于自注意力机制,通过计算序列中任意两个位置的相关性,打破了传统循环神经网络的序列依赖限制,实现了高效并行化与长距离依赖建模。该架构由编码器和解码器组成,结合多头注意力、位置编码、前馈网络等模块,大幅提升了模型表达能力与训练效率。从BERT到GPT系列,几乎所有现代大语言模型均基于Transformer构建,成为深度学习时代的关键技术突破之一。

Proximal SFT:用PPO强化学习机制优化SFT,让大模型训练更稳定
本文介绍了一种改进的监督微调方法——Proximal Supervised Fine-Tuning (PSFT),旨在解决传统SFT易过拟合、泛化能力差及导致“熵坍塌”的问题。受PPO强化学习算法启发,PSFT通过引入参数更新的稳定性机制,防止模型在训练中变得过于确定,从而提升探索能力与后续强化学习阶段的表现。实验表明,PSFT在数学推理、模型对齐及泛化能力方面均优于传统SFT。

让模型不再忽视少数类:MixUp、CutMix、Focal Loss三种技术解决数据不平衡问题
在机器学习应用中,数据集规模有限且类别分布不均(如医学影像中正类仅占5%)常导致模型偏向多数类,虽准确率高,但少数类识别效果差。本文探讨MixUp、CutMix和Focal Loss三种技术,分别从数据增强与损失函数角度提升小规模不平衡数据集上的模型表现。
Java 大视界 -- Java 大数据在智能医疗影像数据压缩与传输优化中的技术应用(227)
本文探讨 Java 大数据在智能医疗影像压缩与传输中的关键技术应用,分析其如何解决医疗影像数据存储、传输与压缩三大难题,并结合实际案例展示技术落地效果。

实时数仓Hologres V3.1版本发布,Serverless型实例从零开始构建OLAP系统
Hologres推出Serverless型实例,支持按需计费、无需独享资源,适合新业务探索分析。高性能查询内表及MaxCompute/OSS外表,弹性扩展至512CU,性能媲美主流开源产品。新增Dynamic Table升级、直读架构优化及ChatBI解决方案,助力高效数据分析。

【2025更新】视频压缩神器!视频体积瞬间缩小80%,可以指定大小压缩、批量压缩,超级良心免费使用!
Moo0视频压缩器是一款免费、高效的视频压缩工具,支持AVI、MP4等多种格式。可按文件大小、比例或屏幕尺寸智能压缩,兼顾画质与效率,操作简便,批量处理更省心,是2025年必备的视频压缩神器!

官宣 | Fluss 0.7 发布公告:稳定性与架构升级
Fluss 0.7 版本正式发布!历经 3 个月开发,完成 250+ 次代码提交,聚焦稳定性、架构升级、性能优化与安全性。新增湖流一体弹性无状态服务、流式分区裁剪功能,大幅提升系统可靠性和查询效率。同时推出 Fluss Java Client 和 DataStream Connector,支持企业级安全认证与鉴权机制。未来将在 Apache 孵化器中继续迭代,探索多模态数据场景,欢迎开发者加入共建!
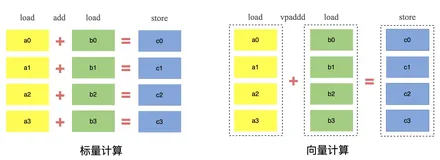
流批一体向量化引擎Flex
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。
婚恋交友相亲公众号app小程序系统源码「脱单神器」婚恋平台全套代码 - 支持快速二次开发
这是一套基于SpringBoot + Vue3开发的婚恋交友系统,支持微信公众号、Uniapp小程序和APP端。系统包含实名认证、智能匹配、视频相亲、会员体系等功能,适用于婚恋社交平台和相亲交友应用。后端采用SpringBoot 3.x与MyBatis-Plus,前端使用Vue3与Uniapp,支持快速部署和二次开发。适合技术团队或有经验的个人创业者使用。
HarmonyOS实战:高德地图定位功能完整流程详解
本文详细介绍了在鸿蒙系统中使用高德地图实现完整定位功能的流程。首先分析需求,包括权限申请、检查GPS状态、单次或多次定位选择以及定位失败处理。接着通过代码实现具体步骤:添加定位权限、申请用户权限、检查GPS开关状态、启动定位服务,并处理定位成功或失败的情况。若定位失败,可尝试获取历史定位信息或使用默认位置。最后总结指出,虽然定位功能基础简单,但完整的流程与细节处理才是关键。建议读者动手实践,掌握高德地图定位功能的使用。

合合信息TextIn大模型加速器2.0发布:智能图表解析测评
随着人工智能技术的飞速发展,大规模语言模型(LLM)在自然语言处理、图像识别、语音合成等领域的应用日益广泛。然而,大模型的计算复杂度和资源消耗问题也日益凸显。为了解决这一问题,合合信息TextIn推出了大模型加速器2.0,旨在提升大模型的训练和推理效率,降低计算成本,完成智能问答与对话式交互,深度概括与定位等。本文将对合合信息TextIn大模型加速器2.0进行详细测评,重点关注其在智能图表解析任务中的表现。

时间序列异常检测:MSET-SPRT组合方法的原理和Python代码实现
MSET-SPRT是一种结合多元状态估计技术(MSET)与序贯概率比检验(SPRT)的混合框架,专为高维度、强关联数据流的异常检测设计。MSET通过历史数据建模估计系统预期状态,SPRT基于统计推断判定偏差显著性,二者协同实现精准高效的异常识别。本文以Python为例,展示其在模拟数据中的应用,证明其在工业监控、设备健康管理及网络安全等领域的可靠性与有效性。

vivo基于Paimon的湖仓一体落地实践
本文整理自vivo互联网大数据专家徐昱在Flink Forward Asia 2024的分享,基于实际案例探讨了构建现代化数据湖仓的关键决策和技术实践。内容涵盖组件选型、架构设计、离线加速、流批链路统一、消息组件替代、样本拼接、查询提速、元数据监控、数据迁移及未来展望等方面。通过这些探索,展示了如何优化性能、降低成本并提升数据处理效率,为相关领域提供了宝贵的经验和参考。

通过Milvus内置Sparse-BM25算法进行全文检索并将混合检索应用于RAG系统
阿里云向量检索服务Milvus 2.5版本在全文检索、关键词匹配以及混合检索(Hybrid Search)方面实现了显著的增强,在多模态检索、RAG等多场景中检索结果能够兼顾召回率与精确性。本文将详细介绍如何利用 Milvus 2.5 版本实现这些功能,并阐述其在RAG 应用的 Retrieve 阶段的最佳实践。
DStream 以及基本工作原理?
DStream 是 Apache Spark Streaming 的核心抽象,表示连续数据流。它从 Kafka、Flume 等接收数据,分为小批量(RDD),进行转换处理后输出到存储系统,并通过 RDD 容错机制保证可靠性。示例代码展示了从套接字接收数据并统计单词频率的过程。

记忆层增强的 Transformer 架构:通过可训练键值存储提升 LLM 性能的创新方法
Meta研究团队开发的记忆层技术通过替换Transformer中的前馈网络(FFN),显著提升了大语言模型的性能。记忆层使用可训练的固定键值对,规模达百万级别,仅计算最相似的前k个键值,优化了计算效率。实验显示,记忆层使模型在事实准确性上提升超100%,且在代码生成和通用知识领域表现优异,媲美4倍计算资源训练的传统模型。这一创新对下一代AI架构的发展具有重要意义。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

