








Spring Boot 3.x 现代化应用开发实战技巧与最佳实践
本指南基于Spring Boot 3.x,融合微服务、云原生与响应式编程等前沿技术,打造现代化应用开发实践。通过构建智能电商平台案例,涵盖商品、订单、用户等核心服务,展示Spring WebFlux、OAuth 2.0认证、Spring Cloud Gateway路由、GraalVM原生编译等技术实现。同时提供Docker/Kubernetes部署方案及性能优化策略,助您掌握从开发到生产的全流程。代码示例详实,适合进阶开发者参考。
Spark RDD 及性能调优
RDD(弹性分布式数据集)是Spark的核心抽象,支持容错和并行计算。其架构包括分区、计算函数、依赖关系、分区器及优先位置等关键组件。操作分为转换(Transformations)与行动(Actions),提供丰富的API支持复杂数据处理。 执行模型涵盖用户代码到分布式执行的全流程,通过DAG调度优化任务划分与资源分配。内存管理机制动态调整存储与执行内存,提升资源利用率。 性能调优涉及资源配置、执行引擎优化及数据处理策略。Catalyst优化逻辑计划,Tungsten提高运行效率,而合理分区与缓解数据倾斜可显著改善性能。这些特性共同确保Spark在大规模数据处理中的高效表现。
淘宝天猫图片搜索商品接口(附代码示例)
拍立淘图片搜索接口支持开发者通过上传图片或提供图片URL,在淘宝、天猫平台搜索相似商品,适用于商品识别、比价等场景。接口采用POST(上传图片)或GET(图片URL)请求方式,返回JSON格式数据,包含商品ID、标题、价格、卖家信息、销量及图片URL等详情,参数可指定搜索关键词、类目、结果数量等,默认返回20条。
深入研究:淘宝天猫商品评论接口详解
淘宝天猫商品评论接口是用于获取商品用户评价信息的RESTful API,支持电商数据分析、竞品调研等需求。通过HTTP请求返回JSONP格式数据,包含评论内容、评分、时间及用户信息等字段。数据结构中,`rateDetail.rateList`为评论列表,`paginator`提供分页信息如每页数量、总评论数和最后一页页码,适用于情感分析与市场研究等多个领域。

PyTorch + MLFlow 实战:从零构建可追踪的深度学习模型训练系统
本文通过使用 Kaggle 数据集训练情感分析模型的实例,详细演示了如何将 PyTorch 与 MLFlow 进行深度集成,实现完整的实验跟踪、模型记录和结果可复现性管理。文章将系统性地介绍训练代码的核心组件,展示指标和工件的记录方法,并提供 MLFlow UI 的详细界面截图。
如何评估数据接口的稳定性和可靠性
评估数据接口(API)的稳定性和可靠性是保障系统运行的关键。本文从基础技术指标、场景化测试、长期监控及供应商评估四方面展开。技术指标涵盖响应时间、并发能力等;场景化测试包括负载、压力、容错与兼容性测试,确保复杂环境下的稳定性;长期监控通过实时指标、日志分析和历史数据复盘优化性能;供应商评估则关注资质、SLA与文档支持。建议建立常态化健康检查机制,确保API始终可靠。
深入研究:淘宝天猫商品详情接口详解
淘宝天猫商品详情API接口由淘宝开放平台提供,支持获取商品主图、价格、标题、销量及属性等详细信息,广泛应用于电商数据分析与自动化购物领域。其功能涵盖商品基础信息(标题、类目、价格等)、详情描述、图片视频资源、SKU属性及评价统计数据的查询。示例代码展示了使用Python调用该API的方法,包括签名生成和参数构造,方便开发者快速集成与使用。
深入研究:淘宝天猫关键词搜索接口详解
淘宝和天猫提供关键词搜索商品的API接口,支持开发者按关键词获取商品列表及相关数据。功能包括通过搜索关键词(q)返回商品基本信息,如ID、标题、价格、图片、销量等。支持排序(sort)、分页(page_no/page_size)、价格区间筛选(start_price/end_price)及分类搜索(cat)。返回JSON格式数据,含商品ID、标题、价格、图片链接、详情页链接和销量等字段。
赛事比分怎么实现实时更新?从采集到推送的“毫秒级“科技揭秘!
实时比分更新背后的技术奥秘,远比你想象的复杂!从数据采集、传输、处理到用户推送,每个环节都充满挑战。情报来源包括官方接口、AI视觉识别和人工录入;传输方式从HTTP轮询到WebSocket,追求毫秒级延迟;数据清洗确保准确性,用户推送注重适配与优先级。开发者还需规避常见坑点,如消息队列、时区转换等。未来,AI预测、边缘计算甚至量子通信将让零延迟成为可能。想了解如何打造像顶级中场般精准、快速且可靠的比分系统吗?本文为你深度拆解!
DistilQwen-ThoughtX 蒸馏模型在 PAI-ModelGallery 的训练、评测、压缩及部署实践
通过 PAI-ModelGallery,可一站式零代码完成 DistilQwen-ThoughtX 系列模型的训练、评测、压缩和部署。

Python 3D数据可视化:7个实用案例助你快速上手
本文介绍了基于 Python Matplotlib 库的七种三维数据可视化技术,涵盖线性绘图、散点图、曲面图、线框图、等高线图、三角剖分及莫比乌斯带建模。通过具体代码示例和输出结果,展示了如何配置三维投影环境并实现复杂数据的空间表示。这些方法广泛应用于科学计算、数据分析与工程领域,帮助揭示多维数据中的空间关系与规律,为深入分析提供技术支持。
深入研究:速卖通商品列表 API 接口详解
速卖通(AliExpress)商品列表 API 是跨境电商开发者的重要工具,支持通过关键词、分类、价格区间等多种条件批量获取商品信息。该接口采用 HTTP GET/POST 请求方式,返回 JSON 格式的响应数据,并提供分页机制以处理大量数据。适用于电商数据分析、价格监控及比价工具开发等场景,助力高效挖掘商品资源。
深入研究:速卖通商品详情API接口详解
速卖通(AliExpress)是阿里巴巴旗下的跨境电商平台,其商品详情API为开发者提供获取商品标题、价格、库存等详细信息的功能。通过HTTP GET/POST请求,结合请求URL与必要参数(如app_key、access_token、product_id等),可灵活获取所需数据,用于构建价格监控、比价网站或商品分析系统等应用,助力跨境电商领域的创新开发。
基于混沌序列和小波变换层次化编码的遥感图像加密算法matlab仿真
本项目实现了一种基于小波变换层次化编码的遥感图像加密算法,并通过MATLAB2022A进行仿真测试。算法对遥感图像进行小波变换后,利用Logistic混沌映射分别对LL、LH、HL和HH子带加密,完成图像的置乱与扩散处理。核心程序展示了图像灰度化、加密及直方图分析过程,最终验证加密图像的相关性、熵和解密后图像质量等性能指标。通过实验结果(附图展示),证明了该算法在图像安全性与可恢复性方面的有效性。

数据分布不明确?5个方法识别数据分布,快速找到数据的真实规律
本文深入探讨了数据科学中分布识别的重要性及其实践方法。作为数据分析的基础环节,分布识别影响后续模型性能与分析可靠性。文章从直方图的可视化入手,介绍如何通过Python代码实现分布特征的初步观察,并系统化地讲解参数估计、统计检验及distfit库的应用。同时,针对离散数据、非参数方法和Bootstrap验证等专题展开讨论,强调业务逻辑与统计结果结合的重要性。最后指出,正确识别分布有助于异常检测、数据生成及预测分析等领域,为决策提供可靠依据。作者倡导在实践中平衡模型复杂度与实用性,重视对数据本质的理解。
OpenFold2.0 基于NPU的推理适配与测试
本教程详细介绍了 OpenFold 的环境搭建、代码部署、依赖安装、数据集准备及推理测试全流程。首先通过 Anaconda 创建 Python3.9 环境并配置相关库,接着克隆 OpenFold 代码仓库并安装必要依赖(如 PyTorch、dllogger、hhsuite 等)。随后准备 PDB 数据集与模型参数,调整脚本路径以适配运行环境。最后执行推理脚本完成测试,并针对常见报错提供了解决方案,例如更新 NumPy、SciPy 或调整 GPU 配置等,确保流程顺利运行。
昇腾AI4S图机器学习:DGL图构建接口的PyG替换
本文探讨了在图神经网络中将DGL接口替换为PyG实现的方法,重点以RFdiffusion蛋白质设计模型中的SE3Transformer为例。SE3Transformer通过SE(3)等变性提取三维几何特征,其图构建部分依赖DGL接口。文章详细介绍了两个关键函数的替换:`make_full_graph` 和 `make_topk_graph`。前者构建完全连接图,后者生成k近邻图。通过PyG的高效实现(如`knn_graph`),我们简化了图结构创建过程,并调整边特征处理逻辑以兼容不同框架,从而更好地支持昇腾NPU等硬件环境。此方法为跨库迁移提供了实用参考。
Origin2024 汉化安装专业解析|企业级部署教程+批量激活解决方案
Origin是一款由OriginLab开发的科学绘图与数据分析软件,支持Windows系统,提供丰富的2D/3D图形模板和强大的数据分析功能,如统计、信号处理、图像处理等。本文详细介绍Origin2024的下载与安装步骤,包括解压文件、运行安装程序、输入序列号、安装路径设置及破解方法,帮助用户快速完成软件安装与激活。
最新技术栈下 Java 面试高频技术点实操指南详解
本指南结合最新Java技术趋势,涵盖微服务(Spring Cloud Alibaba)、响应式编程(Spring WebFlux)、容器化部署(Docker+Kubernetes)、函数式编程、性能优化及测试等核心领域。通过具体实现步骤与示例代码,深入讲解服务注册发现、配置中心、熔断限流、响应式数据库访问、JVM调优等内容。适合备战Java面试,提升实操能力,助力技术进阶。资源链接:[https://pan.quark.cn/s/14fcf913bae6](https://pan.quark.cn/s/14fcf913bae6)
使用DevEcoStudio 开发、编译鸿蒙 NEXT_APP 以及使用中文插件
# 使用DevEcoStudio 开发、编译鸿蒙 NEXT_APP 以及使用中文插件 #鸿蒙开发工具 #DevEco Studio
从MaxCompute到Milvus:通过DataWorks进行数据同步,实现海量数据高效相似性检索
如果您需要将存储在MaxCompute中的大规模结构化数据导入Milvus,以支持高效的向量检索和相似性分析,可以通过DataWorks的数据集成服务实现无缝同步。本文介绍如何利用DataWorks,快速完成从MaxCompute到Milvus的离线数据同步。
基于混沌加密的遥感图像加密算法matlab仿真
本项目实现了一种基于混沌加密的遥感图像加密算法MATLAB仿真(测试版本:MATLAB2022A)。通过Logistic映射与Baker映射生成混沌序列,对遥感图像进行加密和解密处理。程序分析了加解密后图像的直方图、像素相关性、信息熵及解密图像质量等指标。结果显示,加密图像具有良好的随机性和安全性,能有效保护遥感图像中的敏感信息。该算法适用于军事、环境监测等领域,具备加密速度快、密钥空间大、安全性高的特点。
构建AI时代的大数据基础设施-MaxCompute多模态数据处理最佳实践
本文介绍了大数据与AI一体化架构的演进及其实现方法,重点探讨了Data+AI开发全生命周期的关键步骤。文章分析了大模型开发中的典型挑战,如数据管理混乱、开发效率低下和运维管理困难,并提出了解决方案。同时,详细描述了MaxCompute在构建AI时代数据基础设施中的作用,包括其强大的计算能力、调度能力和易用性特点。此外,还展示了MaxCompute在多模态数据处理中的应用实践以及具体客户案例,最后提供了体验MaxFrame解决方案的方式。
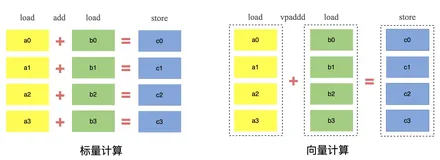
流批一体向量化引擎Flex
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。
深入研究: 亚马逊 amazon商品列表API接口 Python 攻略
本内容介绍了亚马逊商品列表API接口的应用价值与操作方法。在电商数据分析驱动决策的背景下,该接口可自动化获取商品基本信息(如名称、价格、评价等),助力市场调研、竞品分析及价格监控等场景。接口通过设置搜索条件(关键词、类目、价格范围等)筛选商品列表,以GET请求方式调用,返回JSON或XML格式数据,包含商品基本信息、价格、评价、图片链接及库存状态等内容。合理使用此接口可提升运营效率、降低人力成本并及时掌握市场动态。

数据可视化实战:如何采集并分析马蜂窝上的热门旅游信息?
通过自动化工具抓取马蜂窝旅游数据,分析杭州热门景点与用户关注焦点,生成排行榜和词云图。项目采用低成本方案,结合Playwright模拟浏览器行为采集信息,并用Python处理数据、绘制图表。结果显示西湖、灵隐寺等为热门景点,游客多关注门票、交通等问题。此方法简单高效,适合个性化旅行攻略分析。
SnapViewer:解决PyTorch官方内存工具卡死问题,实现高效可视化
深度学习训练中,GPU内存不足(OOM)是常见难题。PyTorch虽提供内存分析工具,但其官方可视化方案存在严重性能瓶颈,尤其在处理大型模型快照时表现极差。为解决这一问题,SnapViewer项目应运而生。该项目通过将内存快照解析为三角形网格结构并借助成熟渲染库,充分发挥GPU并行计算优势,大幅提升大型快照处理效率。此外,SnapViewer优化了数据处理流水线,采用Rust和Python结合的方式,实现高效压缩与解析。项目不仅解决了现有工具的性能缺陷,还为开发者提供了更流畅的内存分析体验,对类似性能优化项目具有重要参考价值。
深入研究:亚马逊amazon商品详情API接口Python攻略
亚马逊商品详情API(Product Advertising API)让开发者以编程方式获取亚马逊商品信息,如标题、价格、库存、评价等。功能涵盖商品基本信息、购买属性、用户反馈、分类与促销信息。使用时需选择端点(如ItemLookup或ItemSearch)、构建请求、发送至服务器并处理响应数据(JSON/XML格式),同时做好错误处理。适合电商应用开发与数据分析。
婚恋交友相亲公众号app小程序系统源码「脱单神器」婚恋平台全套代码 - 支持快速二次开发
这是一套基于SpringBoot + Vue3开发的婚恋交友系统,支持微信公众号、Uniapp小程序和APP端。系统包含实名认证、智能匹配、视频相亲、会员体系等功能,适用于婚恋社交平台和相亲交友应用。后端采用SpringBoot 3.x与MyBatis-Plus,前端使用Vue3与Uniapp,支持快速部署和二次开发。适合技术团队或有经验的个人创业者使用。
App Trace技术解析:传参安装、一键拉起与快速安装
本文从开发者视角解析App Trace技术的关键功能与实现方法,涵盖传参安装、一键拉起和快速安装技术。详细介绍了Android和iOS平台的具体实现代码与配置要点,探讨了参数丢失、跨平台一致性及iOS限制等技术挑战的解决方案,并提供了测试策略、监控指标和性能优化的最佳实践建议,帮助开发者提升用户获取效率与体验。
基于RMD算法模型的信号传输统计特性的matlab模拟仿真
本项目基于RMD(Random Midpoint Displacement)算法模型,使用MATLAB 2022A进行信号传输统计特性的模拟仿真。通过递归在区间中点加入随机位移,生成具有自相似性和长相关性的随机信号,实现了文中多个仿真图,并提供操作视频与中文注释代码。RMD模型生成的信号均值为零,方差无穷大,具备低误码率、强抗干扰能力及高传输效率等优势,为现代通信系统提供了新思路。
华为仓颉语言初识:并发编程之同步机制(下)
本文介绍了华为仓颉语言中的三种线程同步机制:MultiConditionMonitor、synchronized和ThreadLocal。MultiConditionMonitor继承自ReentrantMutex,通过条件变量实现复杂线程同步,文中以生产者-消费者模型为例展示了其用法。synchronized关键字自动加解锁,简化了ReentrantMutex的使用。ThreadLocal则通过线程局部存储实现线程隔离。这三种机制分别适用于不同场景,与Java中的同步工具类似,掌握后可以有效解决多线程并发问题。文章包含代码示例和测试结果,清晰地展示了各机制的实现原理和使用方法。

鸿蒙Next实现瀑布流布局
在开始实现瀑布流布局前,需确保已安装好 DevEco Studio,且已配置好鸿蒙开发环境。打开 DevEco Studio,新建一个鸿蒙应用项目,选择合适的模板(如 Empty Feature Ability),设置项目名称、包名等信息,完成项目创建。
1688API接口终极宝典:列表、详情全掌握,图片搜索攻略助你一臂之力
1688为开发者提供涵盖商品、交易、物流等核心业务的丰富API。商品类API支持搜索、详情获取及图片搜索等功能;交易类API可实现订单创建、查询与支付;物流类API提供报价、轨迹查询及服务商列表获取等服务,满足多样化开发需求。
2025 版 Java 学习路线图之技术方案与实操指南详解
这是一份详尽的Java学习路线图,涵盖从入门到精通的全流程。基础阶段包括环境搭建、语法基础与面向对象编程;进阶阶段深入数据结构、算法、多线程及JVM原理;框架阶段学习Spring、MyBatis等工具;数据库阶段掌握SQL与NoSQL技术;前端阶段了解HTML、CSS及JavaScript框架;分布式与微服务阶段探讨容器化、服务注册与发现;最后通过项目实战提升性能优化与代码规范能力。资源地址:[https://pan.quark.cn/s/14fcf913bae6](https://pan.quark.cn/s/14fcf913bae6)。
体育动画直播怎么做出来的?揭秘从数据到卡通的魔法过程!
体育动画直播是一种结合实时数据、游戏引擎与AI技术的创新形式,可将真实比赛数据转化为动画呈现。它支持自由视角观看、100%还原比赛细节,适用于足球/篮球可视化直播、电竞虚拟形象直播等场景。制作流程包括数据采集(如球员定位、生物力学数据)、3D建模(创建虚拟球场与球员模型)、动画生成(关键帧或AI驱动动作)及实时渲染播出。开发者需注意数据清洗、性能优化与版权问题,未来还将融入元宇宙技术,带来全息、VR沉浸式体验。这是一场体育与科技的完美碰撞!
小红书视频图文提取:采集+CV的实战手记
这是一套用于自动抓取小红书热门视频内容的工具脚本,支持通过关键词搜索提取前3名视频的封面图、视频文件及基本信息(标题、作者、发布时间)。适用于品牌营销分析、热点追踪或图像处理等场景。脚本包含代理配置、接口调用和文件下载功能,并提供扩展建议如图像识别与情绪分析。适合需要高效采集小红书数据的团队或个人使用,稳定性和灵活性兼备。

提升长序列建模效率:Mamba+交叉注意力架构完整指南
本文探讨了Mamba架构中交叉注意力机制的集成方法,Mamba是一种基于选择性状态空间模型的新型序列建模架构,擅长处理长序列。通过引入交叉注意力,Mamba增强了多模态信息融合和条件生成能力。文章从理论基础、技术实现、性能分析及应用场景等方面,详细阐述了该混合架构的特点与前景,同时分析了其在计算效率、训练稳定性等方面的挑战,并展望了未来优化方向,如动态路由机制和多模态扩展,为高效序列建模提供了新思路。
深入研究:shopee商品列表API接口指南
Shopee 是东南亚和中国台湾地区的跨境电商平台,其开放平台(Shopee Open API)为开发者提供商品数据、店铺管理和订单处理等接口。商品列表 API 为核心功能之一,支持按店铺获取商品列表和搜索平台商品。通过 shop_id 等参数可获取指定店铺商品信息,支持分页与状态筛选;通过关键词、类目 ID 和价格范围等条件可搜索平台商品,适用于构建比价工具和选品分析系统。
大学四年学好 Java 拿到 offer 的过来人生成长尾关键词 Java 学习路线分享
这是一篇针对大一学生学习Java的指南,帮助你在大学四年中系统掌握Java,最终成功拿到offer。文章详细介绍了Java的学习路线,包括Java基础(JavaSE)、异常处理、并发多线程(可选)和JVM基础知识。同时提供了具体的学习方法,如观看视频教程、阅读经典书籍和刷技术博客。此外,还给出了简单计算器和多线程打印等应用实例,帮助巩固所学知识。按照此路线认真学习,为未来深入研究和求职打下坚实基础。资源地址:[点击下载](https://pan.quark.cn/s/14fcf913bae6)。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。


