
问题:ACP学习过程中,第二章第二节扩展答疑机器人的知识范围中利用文件创建RAG文件相关的代码块执行之后报错:BadZipFile: File is not a zip;
代码块内容如下:
from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.openai_like import OpenAILike
import logging
logging.basicConfig(level=logging.ERROR)
print("正在解析文件...")
documents = SimpleDirectoryReader('./docs').load_data()
print("正在创建索引...")
index = VectorStoreIndex.from_documents(
documents,
# 指定embedding 模型
embed_model=DashScopeEmbedding(
# 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hw
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
print("正在创建提问引擎...")
query_engine = index.as_query_engine(
# 设置为流式输出
streaming=True,
# 此处使用qwen-plus模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5u
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
))
print("正在生成回复...")
streaming_response = query_engine.query('我们公司项目管理应该用什么工具')
print("回答是:")
streaming_response.print_response_stream()
报错内容如下:
BadZipFile Traceback (most recent call last)
Cell In[1], line 16
14 print("正在创建索引...")
15 # from_documents方法包含切片与建立索引步骤
---> 16 index = VectorStoreIndex.from_documents(
17 documents,
18 # 指定embedding 模型
19 embed_model=DashScopeEmbedding(
20 # 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hw
21 model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
22 ))
23 print("正在创建提问引擎...")
24 query_engine = index.as_query_engine(
25 # 设置为流式输出
26 streaming=True,
(...)
32 is_chat_model=True
33 ))
File /mnt/workspace/llm_learn/lib/python3.10/site-packages/llama_index/core/indices/base.py:115, in BaseIndex.from_documents(cls, documents, storage_context, show_progress, callback_manager, transformations, **kwargs)
112 for doc in documents:
113 docstore.set_documenthash(doc.id, doc.hash)
--> 115 nodes = run_transformations(
116 documents, # type: ignore
...
-> 1338 raise BadZipFile("File is not a zip file")
1339 if self.debug > 1:
1340 print(endrec)
BadZipFile: File is not a zip file
解决方案:
尝试询问AI,得到结论是下载的NLTK文件可能损坏,但是不知道怎么重新下载安装相关NLTK文件,或者如何修复已损坏的配置文件;
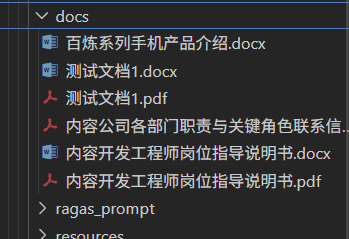
查看配置好的环境中的文档文件,的确没有ZIP格式的文件,如下图:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

