
本地部署Funasr-runtime-sdk-cpu-0.4.7,使用8k模型进行电话录音文件识别返回乱码,且结果状态显示为未完成,不知道是怎么回事,启动命令如下:
```nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir iic/speech_fsmn_vad_zh-cn-8k-common-onnx \
--model-dir iic/speech_paraformer_asr_nat-zh-cn-8k-common-vocab8358-tensorflow1-onnx \
--punc-dir iic/punc_ct-transformer_zh-cn-common-vocab272727-onnx \
--certfile 0 \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
返回j结果:
```buffer.size=4380204,result json={"is_final":false,"mode":"offline","text":"买买买炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯。买炯炯炯炯炯炯炯。买炯炯砣砣砣砣砣砣砣炯炯炯炯炯炯炯炯炯炯炯炯,砣砣砣炯炯。买炯炯砣砣砣砣砣砣砣砣砣买炯炯砣砣砣。买炯炯炯炯炯炯炯炯炯炯炯炯。买炯炯。买炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯,炯炯炯炯。买买炯炯炯,炯炯炯炯。买炯炯炯炯。买炯炯炯,炯炯炯炯。买炯炯炯炯炯,炯炯炯炯。买炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯炯,炯炯炯炯。买炯炯。买。","wav_name":"h5"}
文件编码信息如下: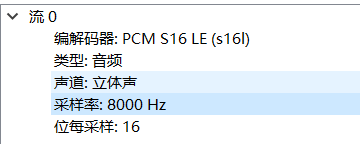
使用的工具为网页,在js中将采样率调整为了8000
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
