
视觉智能平台视频拆条功能有什么配置可以不依赖音频吗,因为这边会使用其他服务进行语音的解析,所以对这个接口期望的是根据视频内容进行分析
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云视觉智能平台的视频拆条功能,在调用时可通过设置相关参数来实现不依赖音频进行拆条,通常在构建请求参数时,将与音频相关的参数设置为空或指定不使用音频分析的标识等即可,以下是一般的步骤:
您好,视觉智能开放平台的视频拆条能力暂时不支持个性化参数的设置,目前支持的请求参数有以下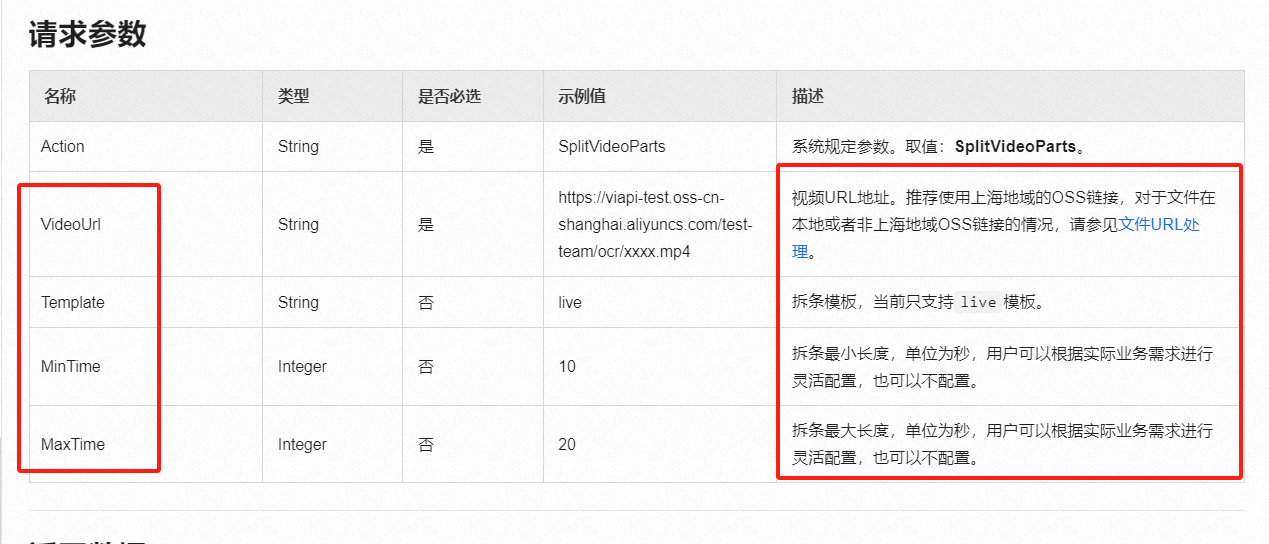
另外,视频拆条能力可以多维度对视频进行分析理解,将视频拆解为多个片段并返回每个片段的边界时间点(不返回具体视频片段),并对片段进行摘要描述,拆分维度包含镜头和主题等,并不只是依赖音频去拆解的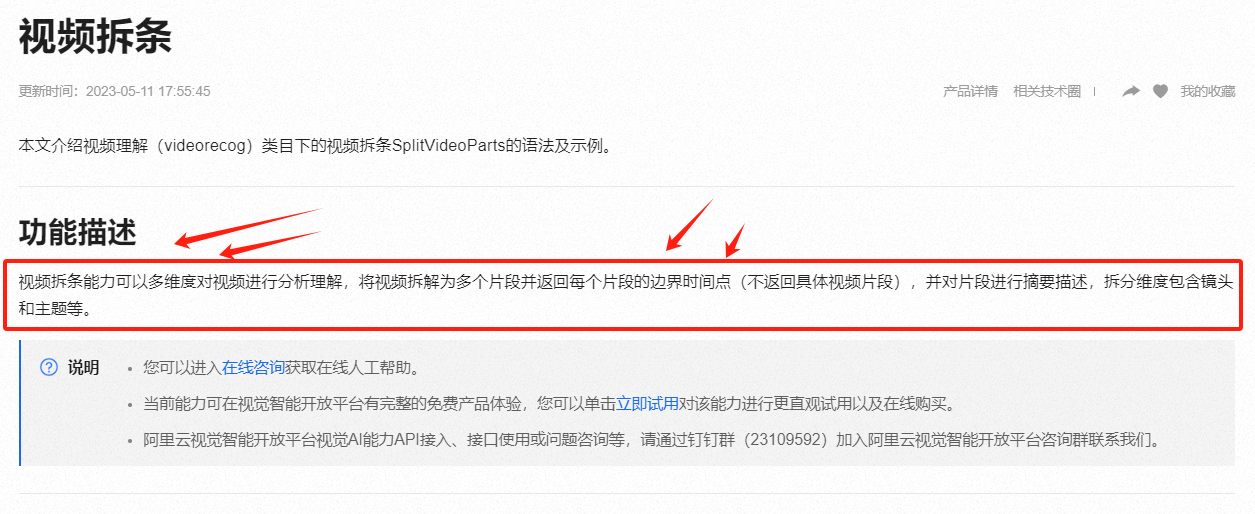
关于接口详细说明参考文档:https://help.aliyun.com/zh/viapi/developer-reference/api-video-strip-splitting?spm=a2c4g.11186623.0.i9


