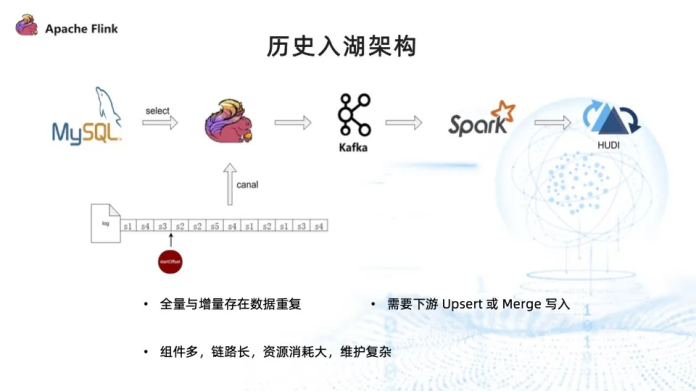
Flink + Canal的实时数据入湖架构存在哪些主要问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink + Canal的实时数据入湖架构主要存在三个问题。首先,全量与增量数据存在重复,因为采集过程中不会锁表,可能导致在全量采集过程中采集到已变更的数据,从而造成数据重复。其次,需要下游进行Upsert或Merge写入来剔除重复数据,增加了处理复杂度和资源消耗。最后,该架构涉及多个组件(Flink、Canal、Kafka、Spark)和较长的链路,导致资源消耗大且难以维护。