
在机器学习PAI我们每天写前一天的数据到pt里,然后全量数据同步前30天,是怎么同步的?是从当前时间往前推30个pt吗?还是说,一个pt存储前30天的数据?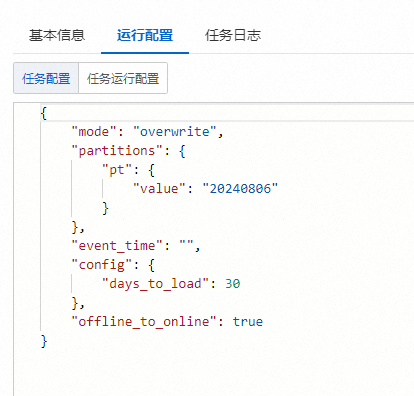
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在机器学习PAI中,将全量数据同步前30天,通常有以下几种方法:
使用DataX工具同步
DataX是阿里巴巴开源的数据同步工具,可以将HBase、Mysql、HDFS等不同类型的数据同步成统一格式。可以配置DataX任务,指定源数据存储位置(如MaxCompute表、OSS文件等)和目标存储位置(如PAI的PT表),并设置同步的时间范围为前30天,DataX会按照配置将数据从源端全量同步到目标端。
通过MaxCompute SQL实现
如果数据存储在MaxCompute中,可以利用MaxCompute SQL的INSERT OVERWRITE语句来实现全量数据同步。例如,假设每天的数据都有一个日期分区,可以使用类似 INSERT OVERWRITE TABLE target_table PARTITION (pt='${date}') SELECT * FROM source_table WHERE date BETWEEN '${date-29}' AND '${date}' 的SQL语句,其中 ${date} 为当前日期,通过调度任务每天执行该SQL,即可将前30天的数据全量同步到指定的PT分区中。
借助PAI-EAS等服务的集成功能
如果使用PAI-EAS等模型部署和服务化平台,平台可能提供了与数据存储和同步相关的集成功能。可以在PAI-EAS的任务配置或数据管理界面中,设置数据同步的规则和时间范围,将前30天的数据从数据源同步到PAI-EAS所使用的存储中,供模型训练和预测使用。
利用DataWorks进行调度同步
DataWorks是阿里云的数据集成和调度平台,可以创建数据同步任务,并通过调度配置来实现定期全量同步前30天的数据。在DataWorks中,可以配置任务的依赖关系、调度周期等,确保数据按照每天的节奏,将前30天的数据准确同步到PT表中。
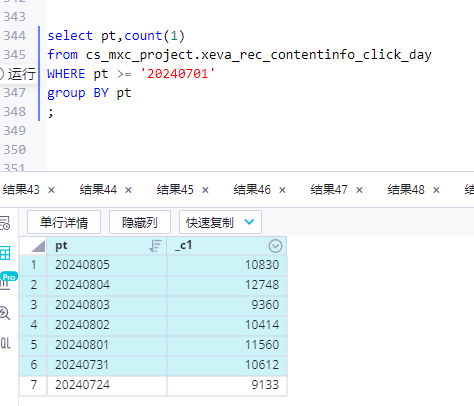
从填写的分区值开始(包含),往前推30天,所有数据同步的时候fs会进行整合去重,然后写入在线数据源 ,可以在 运行配置 的 任务运行配置,看到具体运行的sql语句。 此回答整理自钉群“PAI-FeatureStore特征平台应用交流”
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


