
如何在MaxCompute中执行SQL全表扫描所有分区?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果当前SQL需要进行全表扫描,可以在SQL语句前加set odps.sql.allow.fullscan=true;
语句并一起提交运行。全表扫描会导致输入量增加从而使成本增加。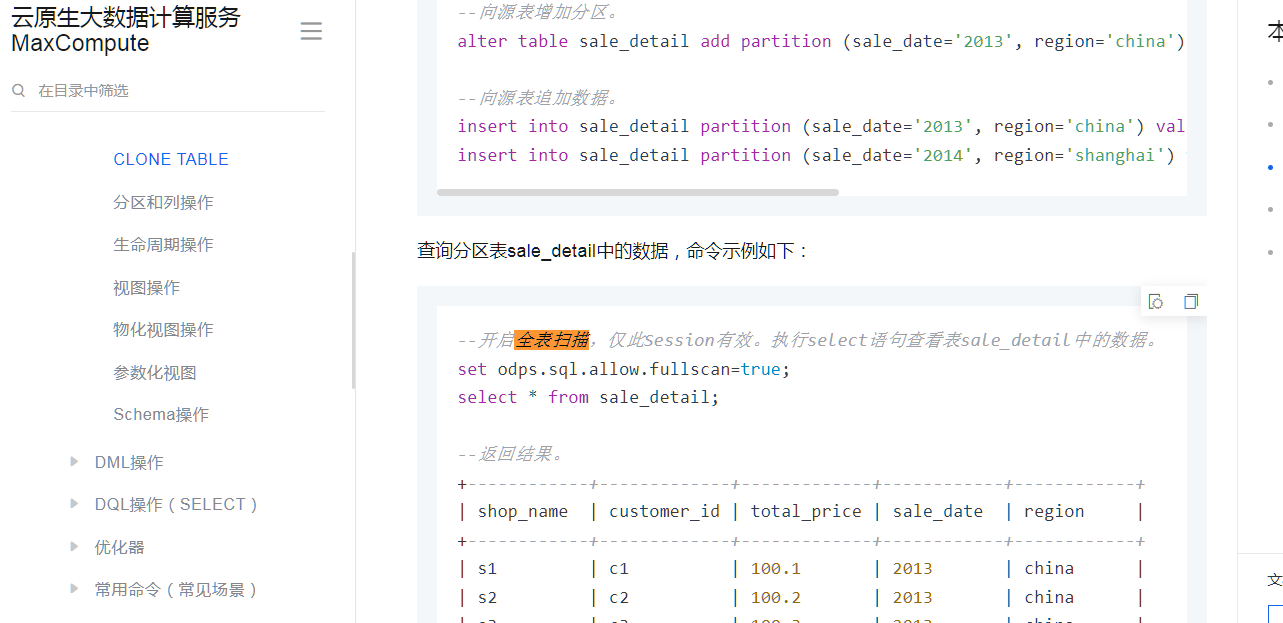
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/clone-table
回答不易请采纳
在MaxCompute中执行SQL全表扫描所有分区,可以通过编写SQL查询语句来实现。以下是一些步骤和示例,帮助你理解如何操作:
确定数据表和分区:
首先,你需要知道你要查询的数据表的名称以及该表的分区列。分区列是用于将数据分割成多个部分的列,每个分区包含表中的一部分数据。
编写SQL查询:
使用标准的SQL语法来编写查询。如果你想要扫描整个表的所有分区,通常不需要指定特定的分区条件,因为MaxCompute会自动处理分区的合并和扫描。
示例SQL查询:
SELECT * FROM your_table_name;
这里的your_table_name应该替换为你的实际表名。这条SQL语句会返回表中所有分区的所有数据。
执行查询:
在MaxCompute的控制台或通过客户端工具(如DataWorks、MaxCompute Studio等)执行上述SQL查询。执行时,MaxCompute会自动处理数据的分区,并从所有相关分区中检索数据。
查看结果:
查询执行完成后,你可以查看返回的结果。这些结果包含了来自所有分区的数据。
优化查询性能:
如果数据量非常大,全表扫描可能会消耗较多的资源和时间。为了优化性能,可以考虑以下策略:
使用WHERE子句限制扫描的数据范围,减少需要处理的数据量。
利用MaxCompute的并行处理能力,确保查询能够高效执行。
考虑对常用查询进行索引优化。
监控和调整:
监控查询的执行情况,并根据需要进行调整。例如,如果发现查询速度慢,可能需要优化表结构或查询逻辑。
通过以上步骤,你可以在MaxCompute中有效地执行SQL全表扫描所有分区的操作。记得根据实际情况调整查询和优化策略,以获得最佳性能。
--开启全表扫描,。执行select语句查看表sale_detail_insert中的数据。
set odps.sql.allow.fullscan=true;
select * from sale_detail_insert;
--返回结果。
+------------+-------------+-------------+------------+------------+
| shop_name | customer_id | total_price | sale_date | region |
+------------+-------------+-------------+------------+------------+
| s1 | c1 | 100.1 | 2013 | china |
| s2 | c2 | 100.2 | 2013 | china |
| s3 | c3 | 100.3 | 2013 | china |
+------------+-------------+-------------+------------+------------+
——参考链接。
MaxCompute支持通过SELECT语句查询数据。本文为您介绍SELECT命令格式及如何实现嵌套查询、分组查询、排序等操作。
执行SELECT操作前需要具备目标表的读取数据权限(SELECT)。授权操作请参见MaxCompute权限。
本文中的命令您可以在如下工具平台执行:
MaxCompute客户端
使用SQL分析连接
使用云命令行(odpscmd)连接
使用DataWorks连接
MaxCompute Studio
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/select-syntax
要在MaxCompute中执行SQL全表扫描所有分区,您需要使用SELECT * FROM [table_name]的语句,这里的table_name是您的表名。由于MaxCompute的分区表设计,您需要针对每个分区执行查询。例如,如果您有一个日期分区dt,您需要查询所有日期,如下:
不断改变dt_value(日期分区值)以查询所有分区的数据。
在阿里云的MaxCompute(原名ODPS)中执行SQL全表扫描所有分区,可以通过简单的SQL语句来实现。MaxCompute支持分区表的概念,这样可以提高查询性能并便于管理大数据集。如果你想要对一个分区表进行全表扫描,即读取所有分区的数据,你可以直接在SELECT语句中省略分区谓词。
假设你有一个名为my_table的分区表,并且该表按日期字段dt进行了分区。要执行全表扫描,可以使用如下SQL语句:
SELECT * FROM my_table;
这条语句会扫描my_table的所有分区,并返回所有数据。
成本与性能:全表扫描可能会非常耗费资源和时间,特别是当表很大或有很多分区时。因此,在生产环境中执行这样的操作之前,请确保这是必要的,并考虑是否可以通过添加过滤条件来优化查询。
限制结果集:如果只是想查看部分数据以检查结构或内容,可以使用LIMIT子句来限制返回的行数,例如:
SELECT * FROM my_table LIMIT 100;
指定分区:如果你只关心某些特定的分区而不是整个表,可以在WHERE子句中明确指定分区键,如:
SELECT * FROM my_table WHERE dt = '2023-01-01';
或者多个分区:
SELECT * FROM my_table WHERE dt IN ('2023-01-01', '2023-01-02');
统计信息:在进行大规模数据处理前,建议先查看表的统计信息,这可以帮助你估计作业的成本和所需的时间。使用DESCRIBE EXTENDED my_table;命令可以看到更详细的表信息。
使用索引或其他优化手段:虽然MaxCompute不直接支持传统意义上的索引,但通过合理的设计分区、分桶等策略,以及选择合适的压缩格式,都可以有效提升查询性能。
总之,当你决定执行全表扫描时,请确保已经评估了相关的成本和影响,并采取适当的措施来管理和优化你的查询。
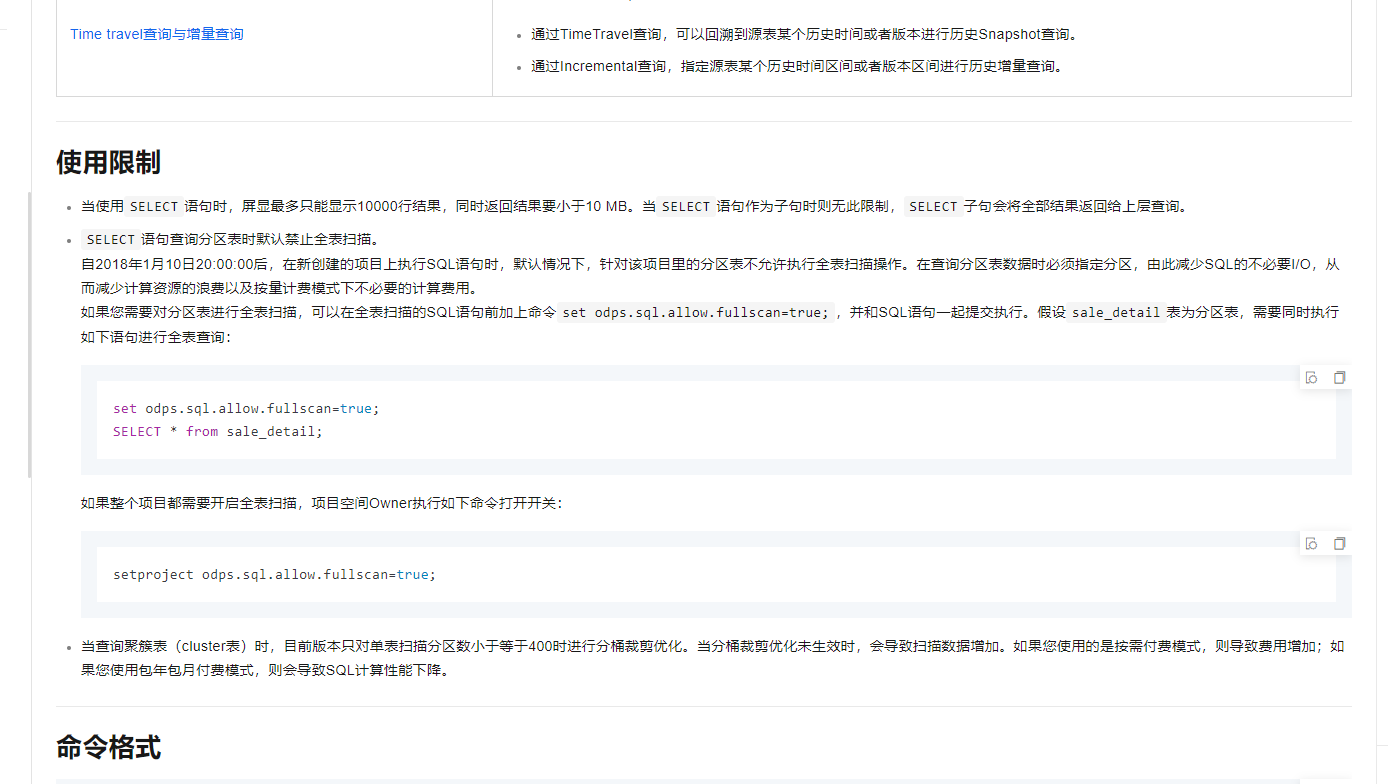
当使用SELECT语句时,屏显最多只能显示10000行结果,同时返回结果要小于10 MB。当SELECT语句作为子句时则无此限制,SELECT子句会将全部结果返回给上层查询。
SELECT语句查询分区表时默认禁止全表扫描。
自2018年1月10日20:00:00后,在新创建的项目上执行SQL语句时,默认情况下,针对该项目里的分区表不允许执行全表扫描操作。在查询分区表数据时必须指定分区,由此减少SQL的不必要I/O,从而减少计算资源的浪费以及按量计费模式下不必要的计算费用。
如果您需要对分区表进行全表扫描,可以在全表扫描的SQL语句前加上命令set odps.sql.allow.fullscan=true;,并和SQL语句一起提交执行。假设sale_detail表为分区表,需要同时执行如下语句进行全表查询:
set odps.sql.allow.fullscan=true;
SELECT * from sale_detail;
如果整个项目都需要开启全表扫描,项目空间Owner执行如下命令打开开关:
setproject odps.sql.allow.fullscan=true;
当查询聚簇表(cluster表)时,目前版本只对单表扫描分区数小于等于400时进行分桶裁剪优化。当分桶裁剪优化未生效时,会导致扫描数据增加。如果您使用的是按需付费模式,则导致费用增加;如果您使用包年包月付费模式,则会导致SQL计算性能下降。
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/select-syntax

