如何查询项目中的所有分区表?
如何查询项目中的所有分区表?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
一条sql就搞定了
select table_name from information_schema.columns where is_partition_key = true group by table_name;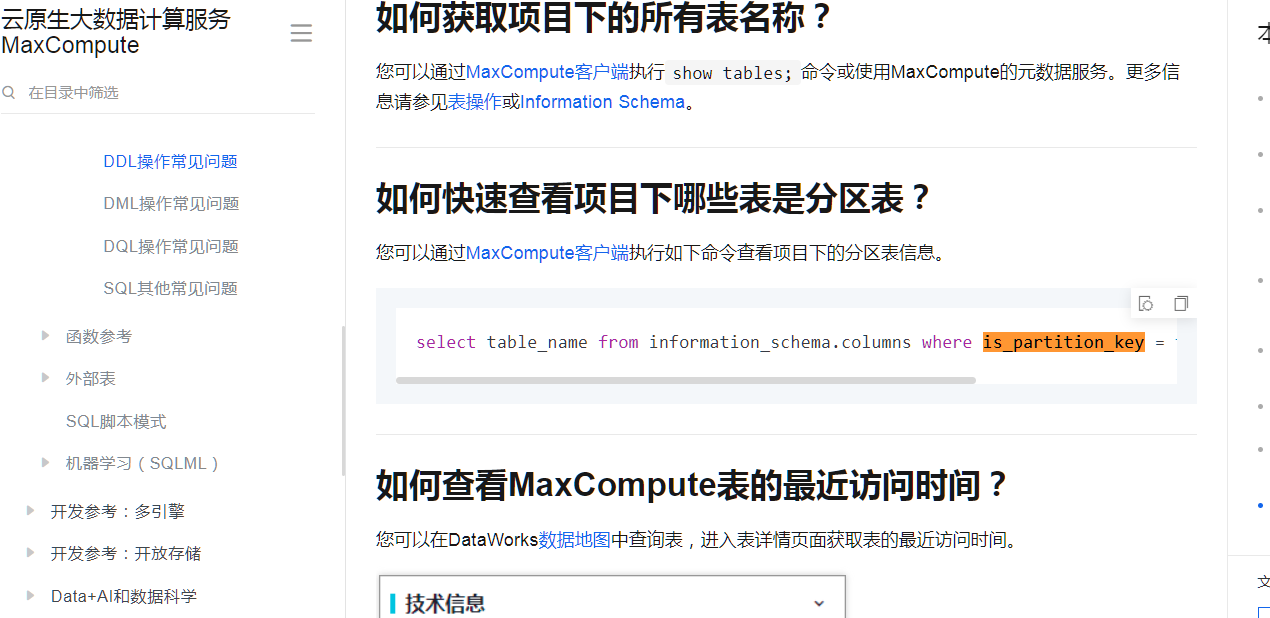
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/faq-about-ddl-operations
回答不易请采纳2024-10-28 16:38:49赞同 展开评论 -
深耕大数据和人工智能
在MaxCompute中查询项目中的所有分区表,可以通过编写SQL语句来获取这些信息。MaxCompute提供了系统视图和函数,可以帮助你识别哪些表是分区表以及它们的分区信息。
以下是一些步骤和示例,说明如何查询项目中的所有分区表:步骤1: 连接到MaxCompute
首先,确保你已经通过pyodps或其他方式连接到MaxCompute。如果你使用的是pyodps,可以参考前面的回答来设置连接。步骤2: 使用SQL查询分区表
你可以使用以下SQL查询来查找项目中所有的分区表及其分区信息:
SELECT
t.TBL_NAME AS table_name,
p.PART_NAME AS partition_name,
p.CREATE_TIME AS partition_create_time
FROM
tables t
JOIN
partitions p ON t.TBL_ID = p.TBL_ID
WHERE
t.TBL_TYPE = 'VIRTUAL_VIEW'
ORDER BY
t.TBL_NAME, p.PART_NAME;这个查询会返回所有虚拟视图(即分区表)的名称、分区名称和分区创建时间。注意,这里假设你的表类型为虚拟视图,这通常是分区表的类型。如果有不同的表类型,请根据实际情况调整TBL_TYPE的值。
步骤3: 执行查询并处理结果
使用Python或其他工具执行上述SQL查询,并处理返回的结果。例如,使用pyodps的代码可能如下所示:
from odps import ODPS配置你的Access Key ID, Access Key Secret, Project Name和Endpoint
ACCESS_ID = 'your_access_id'
ACCESS_KEY = 'your_access_key'
PROJECT = 'your_project_name'
ENDPOINT = 'your_endpoint'创建ODPS实例
o = ODPS(ACCESS_ID, ACCESS_KEY, PROJECT, ENDPOINT)
SQL查询所有分区表
sql = """
SELECT
t.TBL_NAME AS table_name,
p.PART_NAME AS partition_name,
p.CREATE_TIME AS partition_create_time
FROM
tables t
JOIN
partitions p ON t.TBL_ID = p.TBL_ID
WHERE
t.TBL_TYPE = 'VIRTUAL_VIEW'
ORDER BY
t.TBL_NAME, p.PART_NAME;
"""
with o.execute_sql(sql).open_reader() as reader:
for record in reader:
print(record)这段代码将连接到MaxCompute,执行SQL查询,并打印出每个分区表的名称、分区名称和创建时间。
注意事项
确保你有足够的权限来访问系统视图和执行查询。
根据实际使用的MaxCompute环境(如不同的项目或区域),可能需要调整连接参数和查询细节。
对于非虚拟视图类型的分区表,需要相应地调整查询中的TBL_TYPE条件。2024-10-22 11:04:15赞同 展开评论 -
查看当前用户下的分区表:
select from user_part_tables ;
或者下面的语句可以:
select from dba_part_tables where owner ='scheme名称' ;
dba_part_tables表是sys用户下的表。
要想查看表分区的名称:
select partition_name from user_segments where segment_type='TABLE PARTITION' and segment_name='表名';
或者下面的语句可以:
select * from dba_part_col_statistics where lower(table_name)= '表名';
dba_part_col_statistics表是sys用户下的表。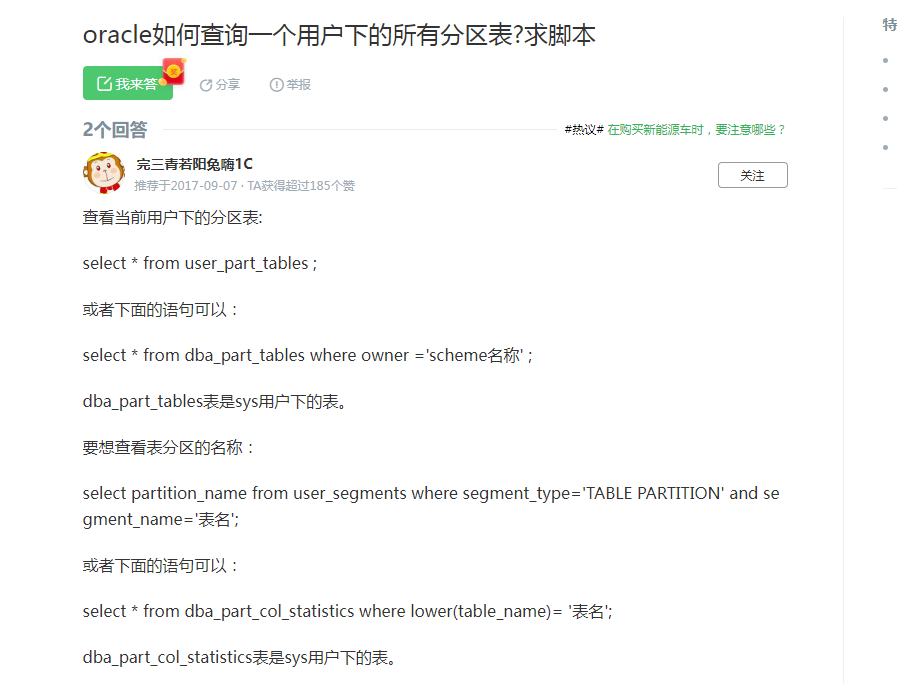
参考文档https://zhidao.baidu.com/question/134984327111052045.html
2024-10-15 14:18:00赞同 展开评论 -
技术浪潮涌向前,学习脚步永绵绵。
要查询MaxCompute项目中的所有分区表,你可以使用
pyodps库来列出所有的表,并检查每个表是否是分区表。下面是如何实现这一点的步骤和示例代码:
步骤
- 连接到你的MaxCompute项目。
- 获取项目中所有的表列表。
- 对于每张表,检查它是否有分区字段。
- 如果有分区字段,则该表是一个分区表。
示例代码
首先确保你已经安装了
pyodps库,并且配置好了访问凭证(如通过环境变量或直接在代码中指定)。from odps import ODPS # 创建ODPS对象 # 如果已经设置了环境变量,则可以直接创建ODPS对象 odps = ODPS() # 或者手动指定参数 # odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>') # 获取当前项目的所有表 tables = odps.list_tables() # 遍历所有表,查找分区表 partitioned_tables = [] for table in tables: # 获取表的schema信息 schema = odps.get_table(table.name).schema # 检查表是否包含分区字段 if schema.partitions: partitioned_tables.append(table.name) # 打印所有分区表 print("Partitioned Tables:") for table_name in partitioned_tables: print(table_name)这段代码做了以下几件事:
- 使用
ODPS对象连接到MaxCompute项目。 - 通过
list_tables()方法获取项目中的所有表。 - 对每个表调用
get_table()方法以获取其模式(schema)信息。 - 检查模式中是否存在分区字段(
partitions)。 - 如果存在分区字段,则将表名添加到
partitioned_tables列表中。 - 最后打印出所有找到的分区表名称。
注意事项
- 确保你有足够的权限去访问项目中的所有表。
- 在处理大型项目时,遍历所有表可能会消耗一定的时间和资源,请根据实际情况进行优化或分批处理。
- 如果需要进一步操作这些分区表(例如查询特定分区的数据),可以继续使用
pyodps提供的API来进行更复杂的操作。
这样,你就可以得到一个列表,其中包含了项目中所有的分区表。
2024-10-15 09:55:53赞同 展开评论 -
PostgreSQL-获取一个表的所有分区表
inhrelid和inhparent都是 pg_class 表中的隐藏列 oid。
那么查询 parent_table_name 的分区表名字的SQL如下:select
c.relname
from
pg_class c
join pg_inherits i on i.inhrelid = c. oid
join pg_class d on d.oid = i.inhparent
where
d.relname = 'parent_table_name';
1
2
3
4
5
6
7
8
或者使用下面的SQL:SELECT
relname
from
pg_class
where
oid in (
SELECT inhrelid FROM pg_inherits WHERE inhparent in (
SELECT oid FROM pg_class WHERE relname = 'parent_table_name'
)
)
参考文档https://blog.csdn.net/fengbohello/article/details/110632011
2024-10-14 16:42:26赞同 展开评论