如何查询项目中的所有分区表?
如何查询项目中的所有分区表?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
一条sql就搞定了
select table_name from information_schema.columns where is_partition_key = true group by table_name;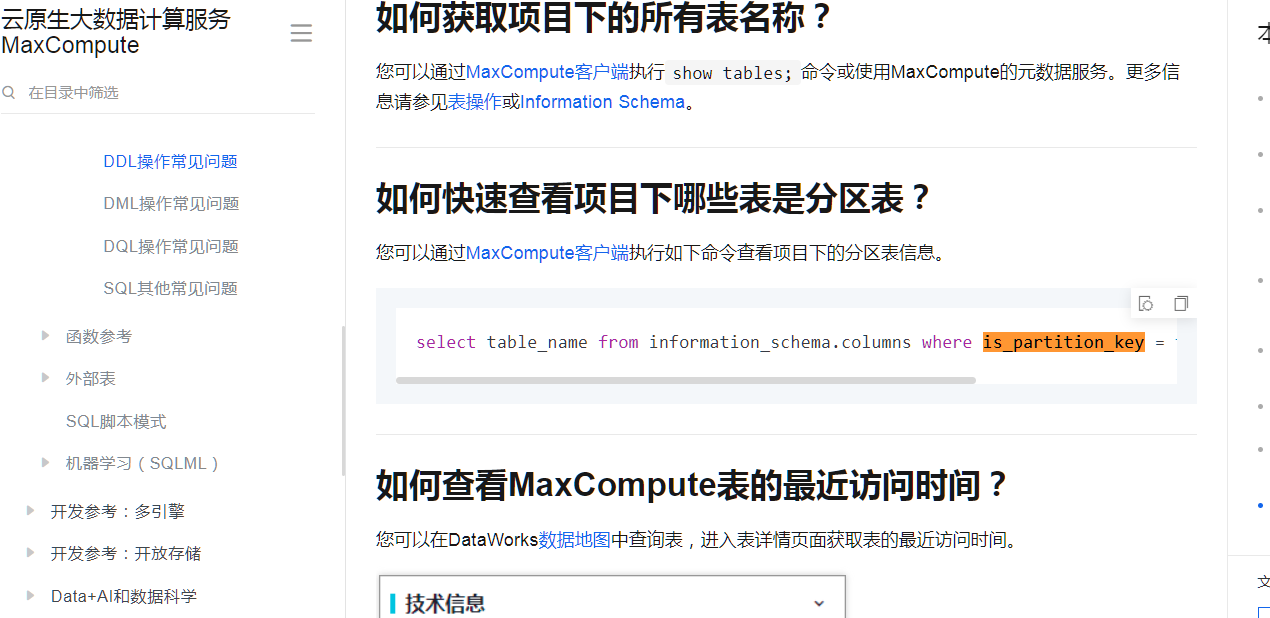
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/faq-about-ddl-operations
回答不易请采纳2024-10-28 16:38:43赞同 展开评论 -
查询MaxCompute项目中的所有分区表,您可以通过MaxCompute客户端执行以下SQL命令:

这将列出所有分区表的名称。可参考Information Schema。2024-10-23 17:09:24赞同 展开评论 -
深耕大数据和人工智能
要查询MaxCompute项目中的所有分区表,您可以使用PyODPS库来执行SQL查询,以获取所有分区表的列表。以下是具体的步骤和示例代码:
安装并导入PyODPS:
确保您已经安装了PyODPS库,并在您的Python脚本中导入它。python
复制代码
from odps import ODPS配置访问凭证:
使用您的AccessKey ID、AccessKey Secret以及MaxCompute项目的URL来初始化一个MaxCompute项目对象。python
复制代码
access_id = 'your-access-key-id'
secret_access_key = 'your-secret-access-key'
project = 'your-project-name'
endpoint = 'http://service.cn.maxcompute.aliyun.com/api'o = ODPS(access_id, secret_access_key, project, endpoint)
执行SQL查询:
使用SHOW TABLES命令结合LIKE子句来筛选出分区表。在MaxCompute中,分区表的名称通常包含斜杠(/),表示分区信息。python
复制代码
with o.execute_sql('SHOW TABLES LIKE "%/%"').open_reader() as reader:
for record in reader:
print(record[0])处理查询结果:
上述代码将打印出所有分区表的名称。每条记录是一个元组,其中第一个元素是表名。关闭连接:
完成数据操作后,确保关闭与MaxCompute的连接。以上步骤将帮助您查询MaxCompute项目中的所有分区表。根据您的具体需求,您可能还需要进行更复杂的数据处理或分析。
2024-10-22 11:04:57赞同 展开评论 -
PostgreSQL-获取一个表的所有分区表
表的分区关系存储在pg_inherits中,其定义如下:
Table "pg_catalog.pg_inherits"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+---------+-----------+----------+---------+---------+--------------+-------------
inhrelid | oid | | not null | | plain | | 子表的 OID
inhparent | oid | | not null | | plain | | 父表的 OID
inhseqno | integer | | not null | | plain | | 直接继承多个父表时指定被继承column 的顺序
Indexes:
"pg_inherits_relid_seqno_index" UNIQUE, btree (inhrelid, inhseqno)
"pg_inherits_parent_index" btree (inhparent)
1
2
3
4
5
6
7
8
9
inhrelid和inhparent都是 pg_class 表中的隐藏列 oid。
那么查询 parent_table_name 的分区表名字的SQL如下:select
c.relname
from
pg_class c
join pg_inherits i on i.inhrelid = c. oid
join pg_class d on d.oid = i.inhparent
where
d.relname = 'parent_table_name';
1
2
3
4
5
6
7
8
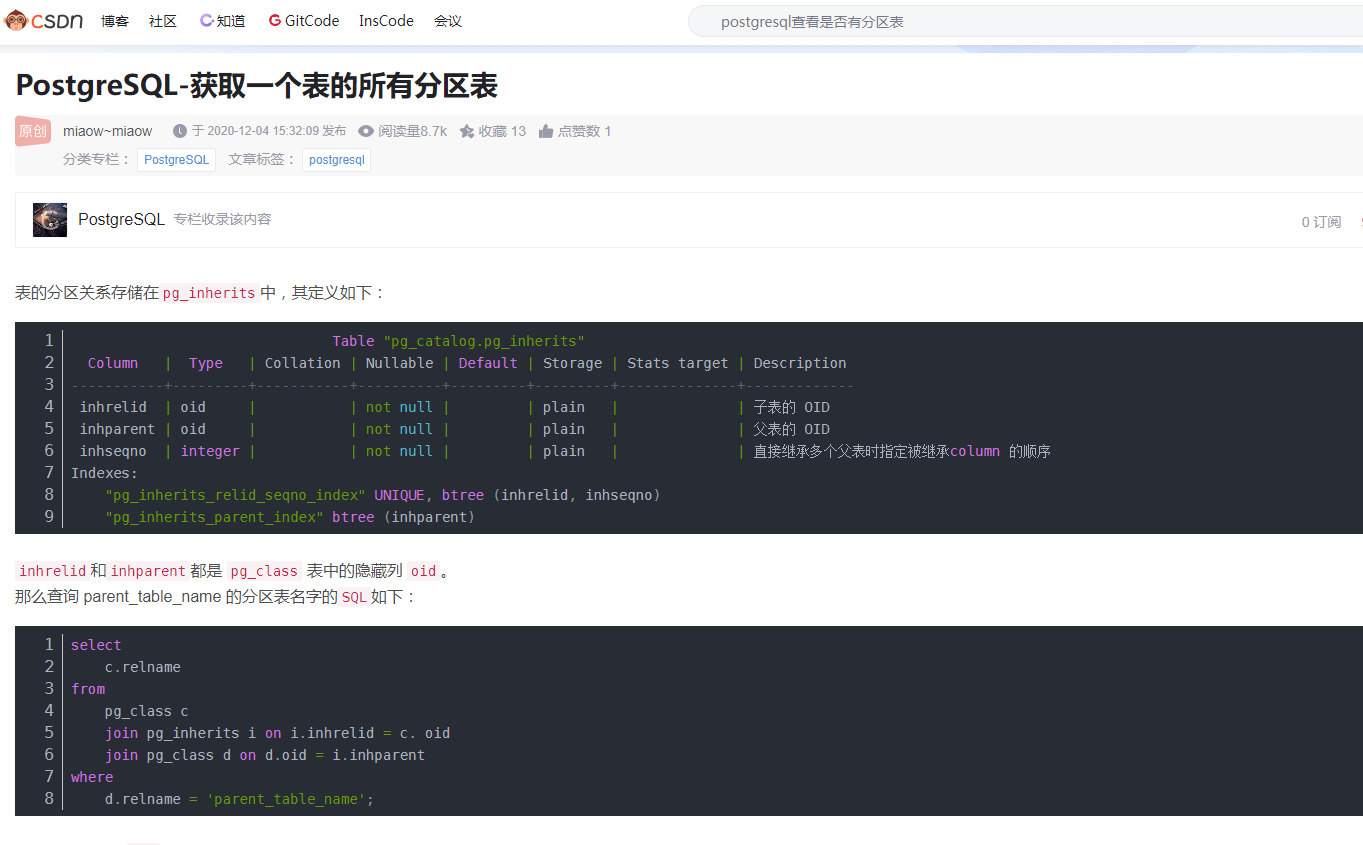
或者使用下面的SQL:SELECT
relname
from
pg_class
where
oid in (
SELECT inhrelid FROM pg_inherits WHERE inhparent in (
SELECT oid FROM pg_class WHERE relname = 'parent_table_name'
)
)
参考文档https://blog.csdn.net/fengbohello/article/details/110632011
2024-10-15 14:17:50赞同 展开评论 -
技术浪潮涌向前,学习脚步永绵绵。
要查询MaxCompute项目中的所有分区表,你可以使用
pyodps库来列出所有的表,并检查每个表是否是分区表。下面是如何实现这一点的步骤和示例代码:
步骤
- 连接到MaxCompute项目:使用
ODPS对象连接到你的MaxCompute项目。 - 获取项目中所有的表列表:使用
list_tables()方法获取项目中的所有表。 - 检查每个表是否是分区表:通过
get_table()方法获取每个表的Schema信息,检查是否有分区字段。
示例代码
首先确保你已经安装了
pyodps库,并且配置好了访问凭证(如通过环境变量或直接在代码中指定)。from odps import ODPS # 创建ODPS对象 # 如果已经设置了环境变量,则可以直接创建ODPS对象 odps = ODPS() # 或者手动指定参数 # odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>') # 获取当前项目的所有表 tables = odps.list_tables() # 遍历所有表,查找分区表 partitioned_tables = [] for table in tables: # 获取表的schema信息 schema = odps.get_table(table.name).schema # 检查表是否包含分区字段 if schema.partitions: partitioned_tables.append(table.name) # 打印所有分区表 print("Partitioned Tables:") for table_name in partitioned_tables: print(table_name)详细说明
创建ODPS对象:
ODPS():如果你已经在环境中设置了ODPS_ENDPOINT、ODPS_ACCESS_ID、ODPS_ACCESS_KEY和ODPS_PROJECT这些环境变量,可以直接创建ODPS对象。ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>'):如果没有设置环境变量,可以手动指定这些参数。
获取项目中所有的表:
odps.list_tables():返回一个包含所有表名的列表。
检查每个表是否是分区表:
odps.get_table(table.name):获取表对象。table.schema:获取表的Schema信息。schema.partitions:如果表有分区字段,partitions属性将是一个非空列表;否则为空。
注意事项
- 权限:确保你有足够的权限去访问项目中的所有表。
- 性能:如果项目中有大量的表,遍历所有表并获取Schema信息可能会比较耗时。请根据实际情况进行优化或分批处理。
- 网络延迟:由于数据存储在云端,网络延迟可能会影响操作的性能。
通过以上步骤和示例代码,你可以轻松地查询MaxCompute项目中的所有分区表。这样可以帮助你更好地管理和分析项目中的数据。
2024-10-15 10:14:44赞同 展开评论 - 连接到MaxCompute项目:使用
-
查询oracle数据库中所有的的分区表
[size=medium]怎样查询出oracle数据库中所有的的分区表[/size]
select * from user_tables a where a.partitioned='YES'[size=medium]删除一个表的数据[/size]
truncate table table_name;[size=medium]删除分区表一个分区的数据[/size]
alter table table_name truncate partition p5;[size=medium]如何查询某用户下所有分区表:[/size]
select table_name,partition_name,tablespace_name from USER_TAB_PARTITIONS;[size=medium]对数据库进行瘦身,用下面语句查询出来直接执行即可:[/size]
select 'alter table ' || table_name || ' truncate partition ' || partition_name || ';' from USER_TAB_PARTITIONS where partition_name < 'P_2012' order by table_name,partition_name
参考文档https://blog.csdn.net/qq_24536625/article/details/84278087
2024-10-14 16:42:38赞同 展开评论