
Kafka主要应用于哪些场景?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
云消息队列 Kafka 版的典型应用场景,包括网站活动跟踪、日志聚合、数据处理、数据中转枢纽。
网站活动跟踪
成功的网站运营需要对站点的用户行为进行分析。通过云消息队列 Kafka 版的发布/订阅模型,您可以实时收集网站活动数据(例如注册、登录、充值、支付、购买),根据业务数据类型将消息发布到不同的Topic,然后利用订阅消息的实时投递,将消息流用于实时处理、实时监控或者加载到Hadoop、MaxCompute等离线数据仓库系统进行离线处理。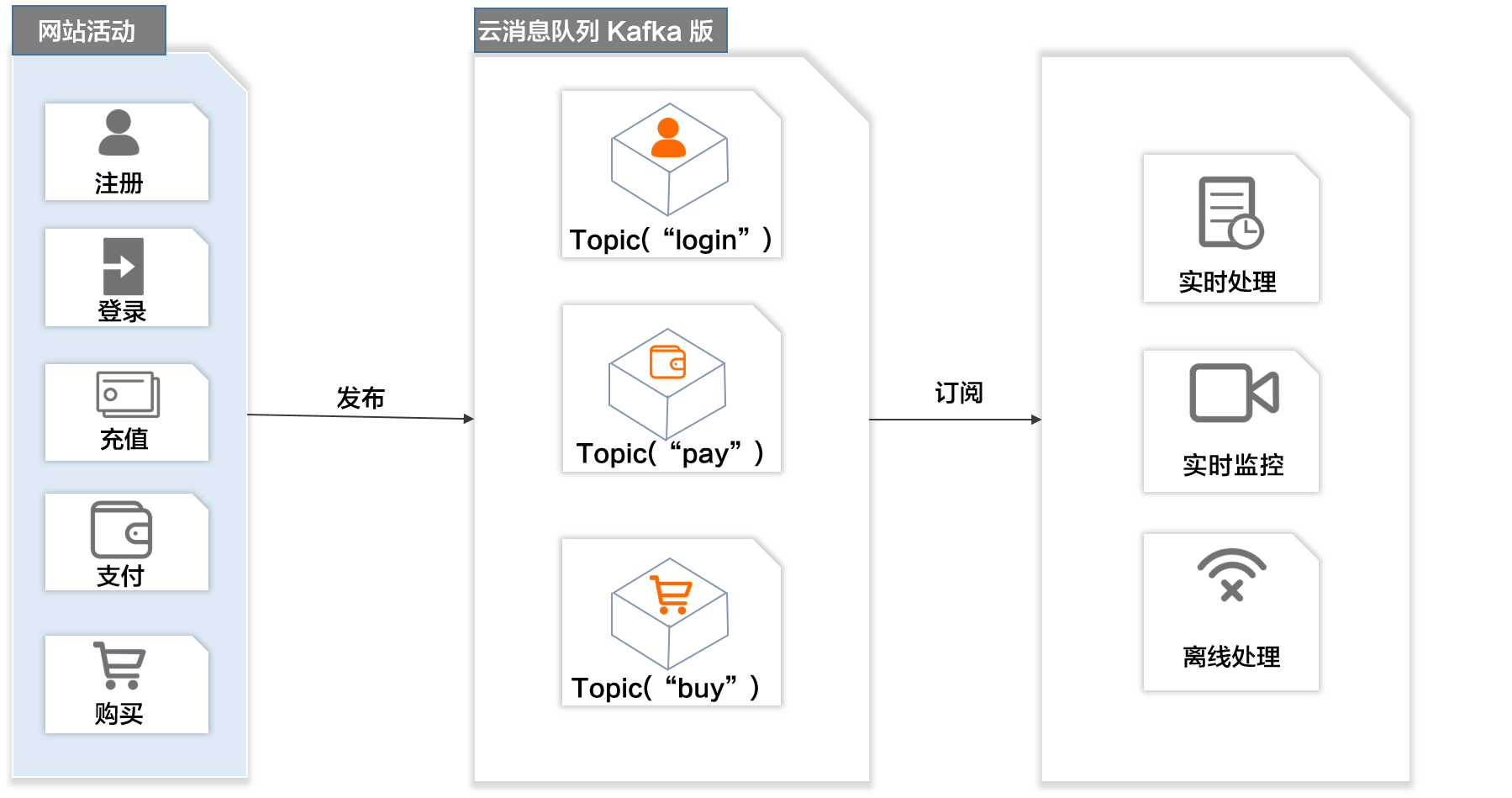
日志聚合
许多公司,例如淘宝、天猫等,每天都会产生大量的日志(一般为流式数据,例如搜索引擎PV、查询等)。相较于以日志为中心的系统,例如Scribe和Flume,云消息队列 Kafka 版在具备高性能的同时,可以实现更强的数据持久化以及更短的端到端响应时间。云消息队列 Kafka 版的这种特性决定它适合作为日志收集中心。云消息队列 Kafka 版忽略掉文件的细节,可以将多台主机或应用的日志数据抽象成一个个日志或事件的消息流,异步发送到云消息队列 Kafka 版集群,从而实现非常低的RT。云消息队列 Kafka 版客户端可批量提交消息和压缩消息,对生产者而言几乎感觉不到性能的开支。消费者可以使用Hadoop、MaxCompute等离线仓库存储和Storm、Spark等实时在线分析系统对日志进行统计分析。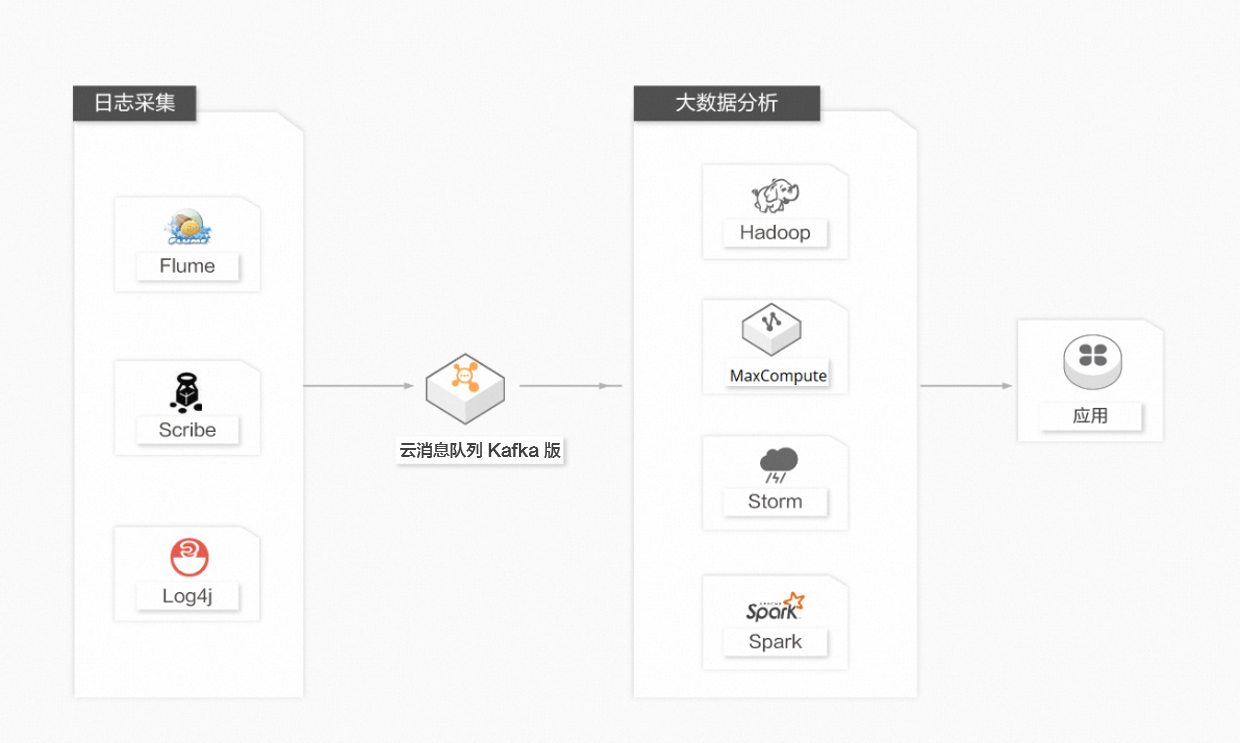
数据处理
在很多领域,如股市走向分析、气象数据测控、网站用户行为分析,由于数据产生快、实时性强且量大,您很难统一采集这些数据并将其入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。与传统架构不同,云消息队列 Kafka 版以及Storm、Samza、Spark等数据处理引擎的出现,就是为了更好地解决这类数据在处理过程中遇到的问题,数据处理模型能实现在数据流动的过程中对数据进行实时地捕捉和处理,并根据业务需求进行计算分析,最终把结果保存或者分发给需要的组件。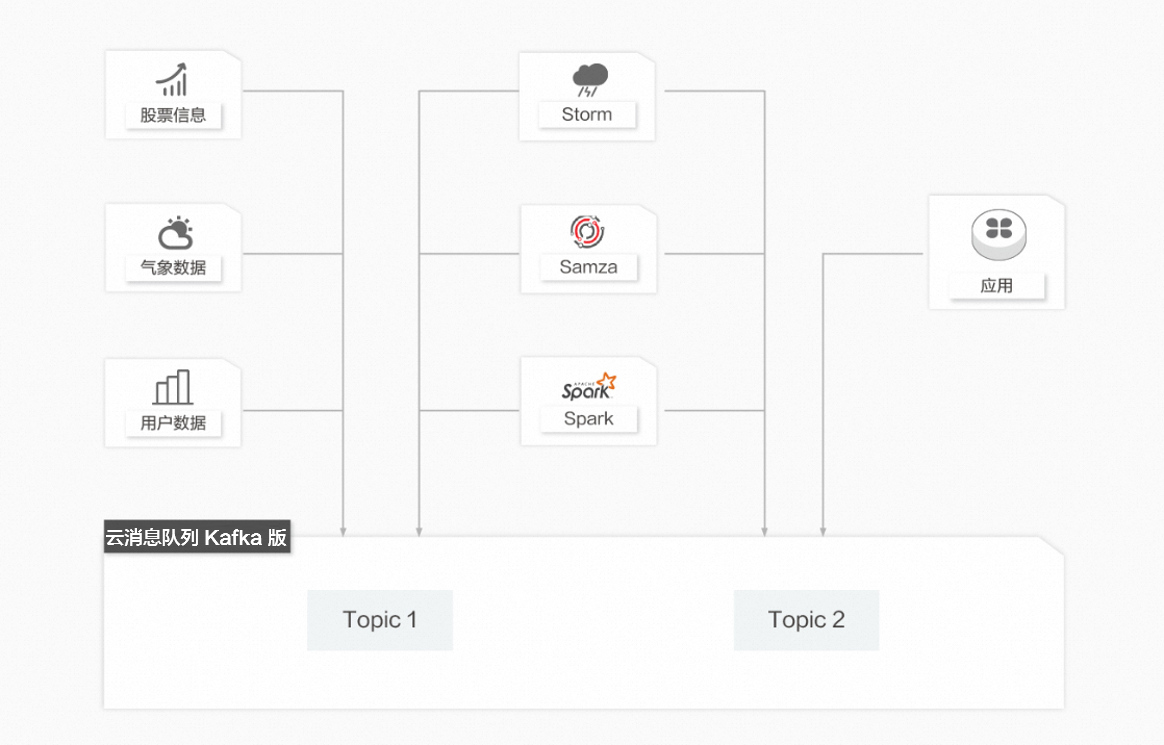
数据中转枢纽
近10多年来,诸如KV存储(HBase)、搜索(Elasticsearch)、流式处理(Storm、Spark、Samza)、时序数据库(OpenTSDB)等专用系统应运而生。这些系统是为单一的目标而产生的,因其简单性使得在商业硬件上构建分布式系统变得更加容易且性价比更高。通常,同一份数据集需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析时,搜索单个日志记录同样不可或缺,而构建各自独立的工作流来采集每种类型的数据再导入到各自的专用系统显然不切实际,利用云消息队列 Kafka 版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。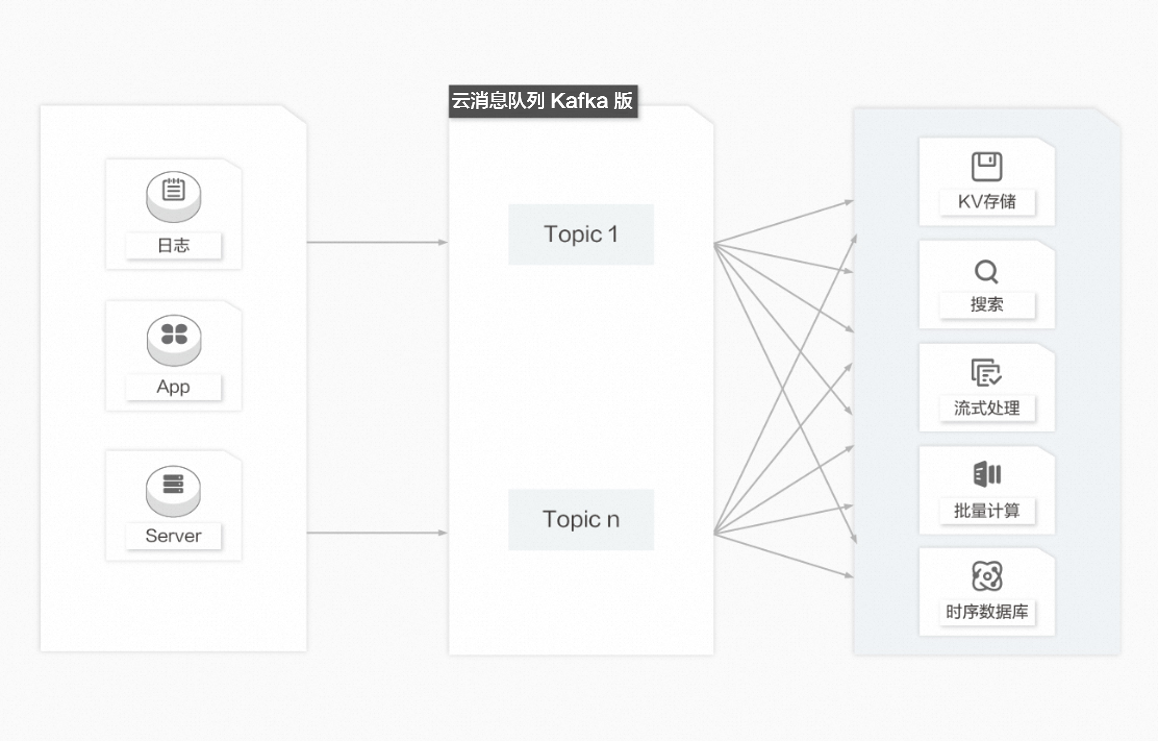
——参考链接。
涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系列产品 Serverless 化。RocketMQ 中文社区:https://rocketmq-learning.com/


