
flink如何从数据湖中读取实时数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
使用Flink从阿里云OSS数据湖读取实时数据的步骤如下:
在实时计算Flink作业中,使用filesystem连接器来读取OSS中的数据。
编写如下的SQL语句来定义源表,这里以读取Parquet格式的数据为例: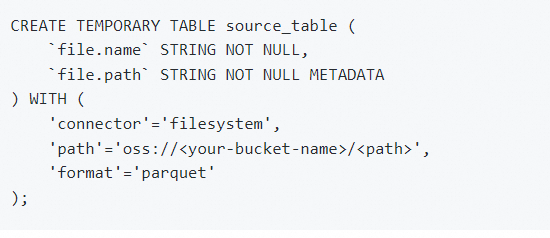
将/替换为您实际的OSS存储空间名和数据路径。
参考链接https://help.aliyun.com/zh/flink/use-cases/build-real-time-data-warehouse-based-on-flink-hologres?spm=a2c4g.11186623.4.8.7b0d7ad1rDfeDr&scm=20140722.H_2400416._.ID_2400416-OR_rec-V_1#dcbd5e0813xfd
创建RDS MySQL实例,详情请参见创建RDS MySQL实例。
创建数据库和账号。
为目标实例创建名称为order_dw的数据库和具有对应数据库读写权限的普通账号。具体操作请参见创建数据库和账号和管理数据库。
准备MySQL CDC数据源。
在目标实例详情页面,单击上方的登录数据库。
在弹出的DMS页面中,填写创建的数据库账号名和密码,然后单击登录。
登录成功后,在左侧双击order_dw数据库,切换数据库。
在SQL Console区域编写三张业务表的建表DDL以及插入的数据语句。
单击执行,单击直接执行。
创建Hologres实例和计算组
创建独享Hologres实例,详情请参见购买Hologres。
为了体验Hologres通过读写分离实现资源强隔离的核心能力,本文以计算组型实例为例为您进行介绍。
在HoloWeb页面连接目标实例后,创建数据库并授权。
创建名为order_dw的数据库(需要开启简单权限模型),并授予用户admin权限。数据库创建和授权
创建Flink工作空间和Catalog这个是重点
创建Flink工作空间,详情请参见开通实时计算Flink版。
登录实时计算控制台,单击目标工作空间操作列下的控制台。
创建Session集群,为后续创建Catalog和查询脚本提供执行环境,详情请参见步骤一:创建Session集群。
创建Hologres Catalog。
在数据开发 > 数据查询页面的查询脚本页签,将如下代码拷贝到查询脚本,并修改目标参数取值,选中目标片段后单击左侧代码行上的运行。
回答不易请采纳
使用Flink从数据湖读取实时数据,您可以参考官方文档中的指导。这里是如何操作的概述:实时计算Flink读写OSS或者OSS-HDFS。首先您需要创建表并指定connector为filesystem,format为如parquet这样的格式,然后配置path到您的数据存储位置。例如,如果数据存储在OSS的srcbucket下,配置可能如下:
Apache Flink 是一个流处理框架,可以用于实时数据处理。要从数据湖中读取实时数据,通常需要使用Flink的连接器(connectors)来连接和读取数据湖中的数据。以下是一些常见的步骤和方法:
Amazon S3: 使用 flink-s3-fs-hadoop 或 flink-s3-fs-presto 连接器。
Google Cloud Storage (GCS): 使用 flink-gcs-connector。
Azure Blob Storage: 使用 flink-azure-datalake 连接器。
HDFS: 使用内置的 HDFS 连接器。
在整个数据湖里面批量更新的两个场景。
第一批量更新的这种场景,在这个场景中我们使用一个 SQL 更新了成千上万行的数据,比如欧洲的 GDPR 策略,当一个用户注销掉自己的账户之后,后台的系统是必须将这个用户所有相关的数据全部物理删除。
第二个场景是我们需要将 date lake 中一些拥有共同特性的数据删除掉,这个场景也是属于批量更新的一个场景,在这个场景中删除的条件可能是任意的条件,跟主键(Primary key)没有任何关系,同时这个待更新的数据集是非常大,这种作业是一个长耗时低频次的作业。
另外是 CDC 写入的场景,对于对 Flink 来说,一般常用的有两种场景,第一种场景是上游的 Binlog 能够很快速的写到 data lake 中,然后供不同的分析引擎做分析使用; 第二种场景是使用 Flink 做一些聚合操作,输出的流是 upsert 类型的数据流,也需要能够实时的写到数据湖或者是下游系统中去做分析。如下图示例中 CDC 写入场景中的 SQL 语句,我们使用单条 SQL 更新一行数据,这种计算模式是一种流式增量的导入,而且属于高频的更新。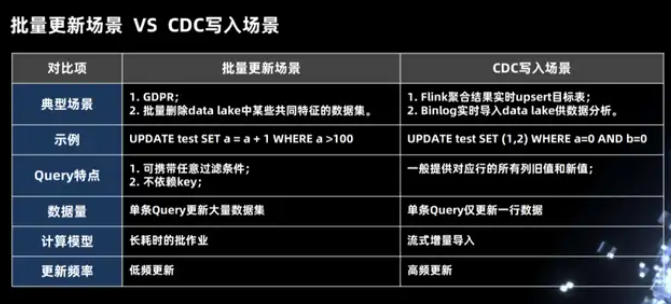
——参考链接。
数据湖通常存储的是原始的、未经处理的数据(如Parquet、ORC等格式),这些数据可以分布在分布式文件系统中,例如HDFS、S3等。要让Flink从数据湖中读取实时数据,你可以使用Flink提供的File Input Formats或者更高级的DataStream API/Table API。下面是一个简单的例子来说明如何使用Flink从数据湖(这里假设是HDFS中的Parquet文件)中读取数据,确保你的环境中已经安装了Apache Flink,并且配置好了相应的依赖库。然后,创建一个Flink程序来读取数据湖中的数据。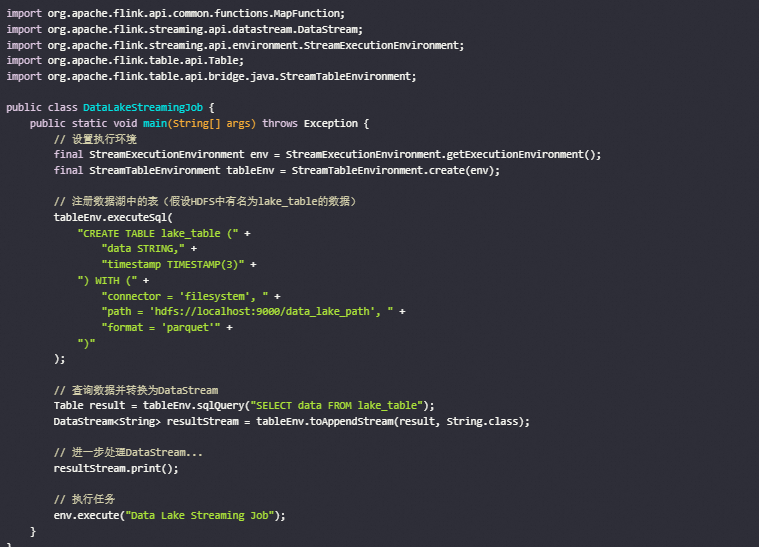
Apache Flink 是一个强大的流处理框架,它可以用来从各种数据源中读取实时数据,包括数据湖。数据湖通常是指存储大量原始数据的中心化存储库,常见的数据湖解决方案包括 Amazon S3、Google Cloud Storage、Azure Data Lake Storage 和 Hadoop Distributed File System (HDFS)。
要使用 Flink 从数据湖中读取实时数据,可以按照以下步骤进行:
准备环境
确保你已经安装并配置好了 Apache Flink 和相关的依赖库。如果你使用的是云存储服务(如 Amazon S3 或 Google Cloud Storage),还需要安装相应的客户端库。
添加依赖
在你的项目中添加必要的依赖。例如,如果你使用的是 Maven,可以在 pom.xml 文件中添加以下依赖: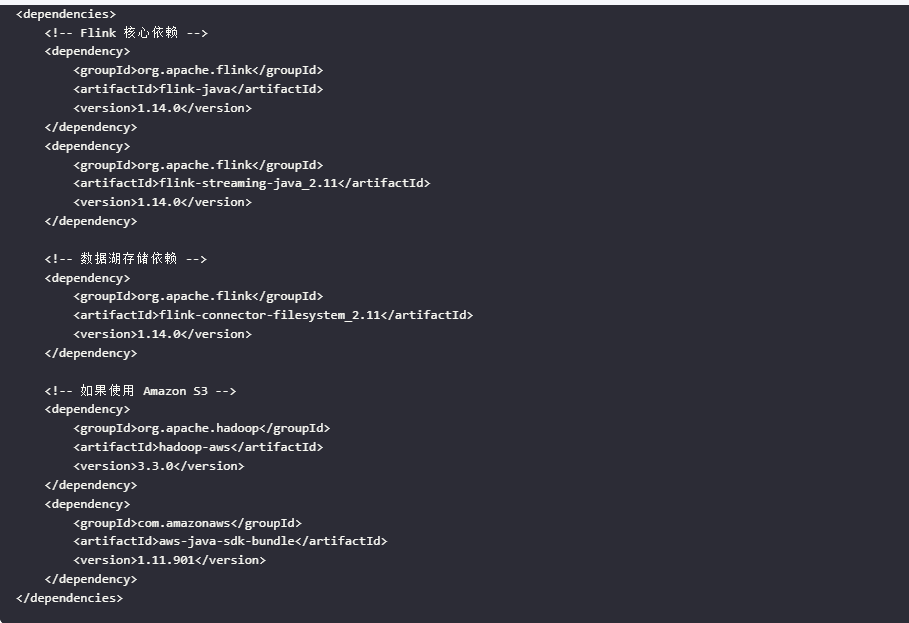
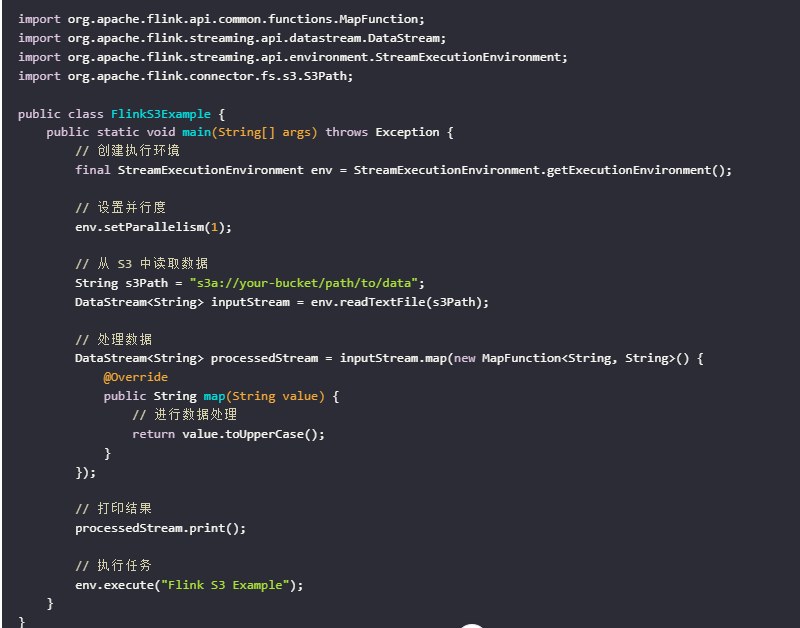
注意事项
数据格式:确保数据湖中的数据格式是你期望的格式(如 CSV、JSON、Parquet 等)。
性能优化:对于大规模数据处理,可以考虑使用分区和并行处理来提高性能。
错误处理:添加适当的错误处理机制,以应对数据读取过程中可能出现的异常。
通过以上步骤,你可以使用 Apache Flink 从数据湖中读取实时数据并进行处理。如果你有特定的数据湖解决方案或数据格式,可以提供更多详细信息,以便进一步优化和调整。
操作流程
创建结构化索引和向量化索引。
将向量化测试数据写入Kafka Topic。
创建映射表并导入数据。
Apache Flink 是一个强大的流处理框架,支持从多种数据源读取数据,包括数据湖。数据湖通常存储大量结构化和非结构化数据,并且支持多种数据格式(如Parquet、ORC、Avro等)。Flink 可以通过不同的连接器和API来从数据湖中读取实时数据。
以下是一些常见的方法和步骤,展示如何使用 Flink 从数据湖中读取实时数据:
Flink 的 DataStream API 提供了灵活的方式来处理无界数据流。你可以使用 Flink 的连接器来从数据湖中读取数据。
Flink 提供了一个 FileSystem Connector,可以用来读取存储在文件系统中的数据。这个连接器支持多种文件格式,如 CSV、JSON、Parquet 等。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.fs.FileStreamSink;
import org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink;
public class ReadFromDataLake {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取存储在HDFS或S3中的数据
String dataLakePath = "hdfs://path/to/your/data.lake";
DataStream<String> stream = env.readFile(new TextInputFormat(new Path(dataLakePath)), dataLakePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000);
// 处理数据
stream.print();
// 执行任务
env.execute("Read from Data Lake");
}
}
Flink 的 Table API 和 SQL 提供了更高级的数据处理方式。你可以使用这些API来读取和处理存储在数据湖中的数据。
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class ReadFromDataLakeWithTableAPI {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建Hive Catalog
HiveCatalog hiveCatalog = new HiveCatalog(
"myhive", // catalog name
null, // default database
"<path-to-hive-conf-dir>" // Hive配置目录
);
tableEnv.registerCatalog("myhive", hiveCatalog);
tableEnv.useCatalog("myhive");
// 读取Hive表
Table hiveTable = tableEnv.from("default.my_table");
// 将Table转换为DataStream
DataStream<Row> stream = tableEnv.toAppendStream(hiveTable, Row.class);
// 处理数据
stream.print();
// 执行任务
env.execute("Read from Data Lake with Table API");
}
}
如果你的数据湖是通过Kafka进行数据传输的,你可以使用 Flink 的 Kafka Connector 来读取实时数据。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class ReadFromKafka {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置Kafka消费者属性
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
// 创建Kafka消费者
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"my-topic",
new SimpleStringSchema(),
properties
);
// 读取Kafka数据
DataStream<String> stream = env.addSource(kafkaConsumer);
// 处理数据
stream.print();
// 执行任务
env.execute("Read from Kafka");
}
}
Apache Hudi 是一种数据湖技术,提供了高效的更新和删除操作。Flink 提供了 Hudi 连接器,可以从 Hudi 表中读取实时数据。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer;
import org.apache.hudi.utilities.schema.SchemaProvider;
import org.apache.hudi.utilities.sources.JsonKafkaSource;
import org.apache.spark.sql.SaveMode;
public class ReadFromHudi {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置Hudi Delta Streamer
HoodieDeltaStreamer.Config config = new HoodieDeltaStreamer.Config();
config.basePath = "<hudi-base-path>";
config.sourceClassName = JsonKafkaSource.class.getName();
config.targetTableName = "my_hudi_table";
config.schemaproviderClassName = SchemaProvider.class.getName();
config.kafkaConfigProps = "bootstrap.servers=localhost:9092,topic=my_topic";
// 启动Hudi Delta Streamer
HoodieDeltaStreamer deltaStreamer = new HoodieDeltaStreamer(config);
deltaStreamer.syncHoodieTable();
// 读取Hudi表
// 注意:这里假设你已经将Hudi表注册为Flink的表
Table hudiTable = tableEnv.from("my_hudi_table");
// 将Table转换为DataStream
DataStream<Row> stream = tableEnv.toAppendStream(hudiTable, Row.class);
// 处理数据
stream.print();
// 执行任务
env.execute("Read from Hudi");
}
}
通过上述方法,你可以使用 Flink 从数据湖中读取实时数据。具体选择哪种方法取决于你的数据湖架构和数据格式。以下是一些关键点:
根据你的具体情况选择合适的方法,并参考 Flink 和相关连接器的官方文档获取更多详细信息。如果有更多具体需求或遇到问题,可以参考 Flink 的官方文档或联系社区获取帮助。
使用Flink从阿里云OSS数据湖读取实时数据,可以按照以下步骤操作:
登录实时计算控制台。
创建SQL作业,编写如下代码:
CREATE TEMPORARY TABLE source_table (
file.name STRING NOT NULL,
file.path STRING NOT NULL METADATA
) WITH (
'connector'='filesystem',
'path'='oss:///dir/',
'format'='parquet'
);
其中srcbucket是你的OSS bucket名,dir是数据路径。
保存并进行深度检查,确保配置无误。
部署作业并启动,Flink将从指定的OSS路径读取Parquet格式的数据。
可参考对象存储OSS连接器
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


