dataworks的odps资源申请多少,如何衡量?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
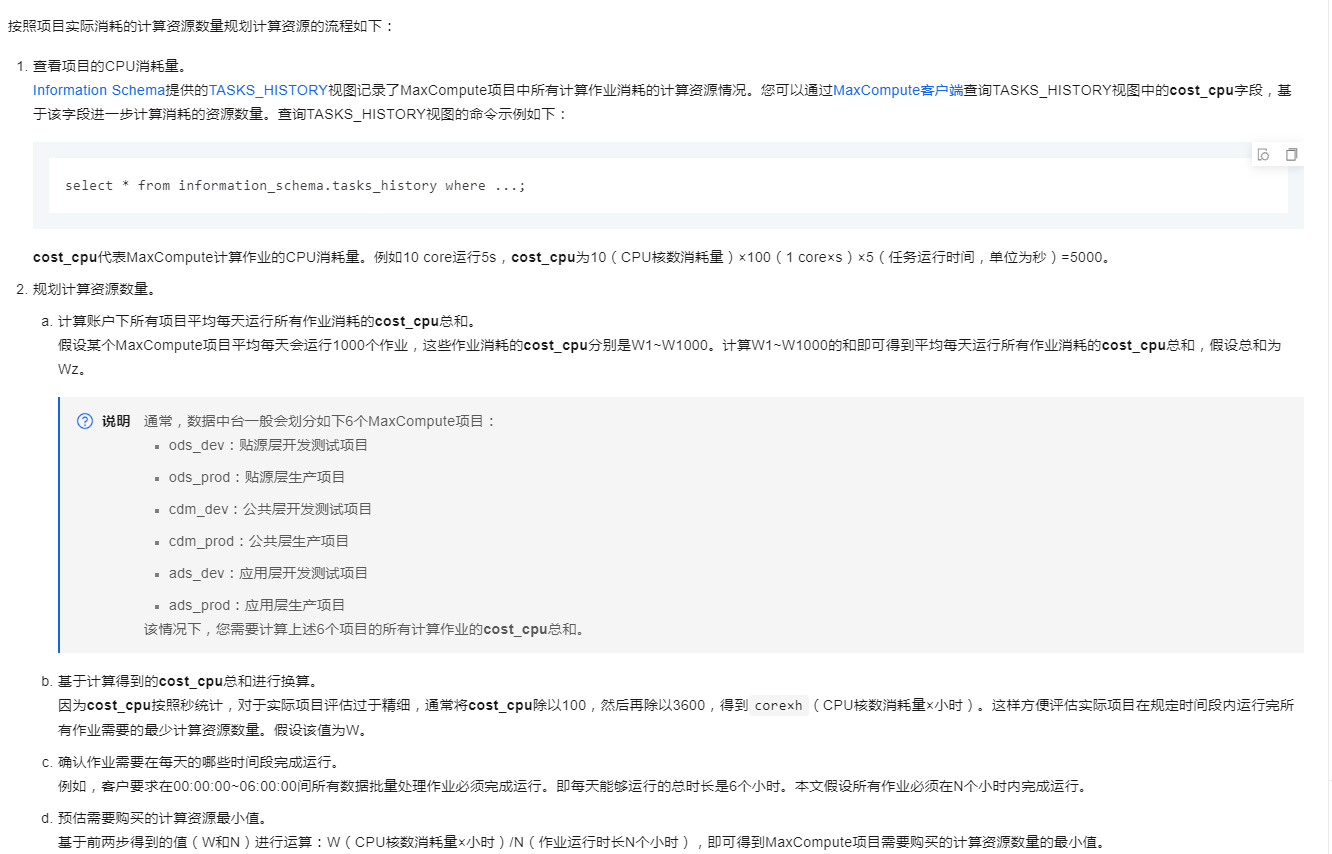
衡量ODPS(MaxCompute)资源申请量时,应考虑以下几个关键因素:
数据量:评估您将处理的数据总量,包括读取、写入的数据规模。
计算复杂度:分析任务的计算逻辑,如涉及到的JOIN操作、聚合操作的复杂度等。
并发需求:考虑任务的并发执行情况,以及是否与其他任务共享资源。
性能测试:通过实际运行小规模测试作业,观察资源使用情况(CPU、内存),据此调整资源申请量。
监控与调整:利用DataWorks的监控功能,监控任务运行时的实际资源消耗,根据监控结果适时调整资源配置,达到最优的资源利用率。
在DataWorks中,ODPS(MaxCompute)资源的申请主要涉及以下几个方面:
综上所述,衡量和申请ODPS资源时,应综合考虑存储需求、计算需求、权限管理以及作业调度的具体情况,确保资源的有效利用与成本控制。在DataWorks中,通过精细的权限管理和资源管理功能,可以灵活配置以满足不同场景的需求。
相关链接
https://help.aliyun.com/zh/maxcompute/user-guide/overview-15
作业的计算需求:评估作业需要处理的数据量和计算的复杂度,例如数据的ETL操作、数据分析、机器学习等任务的资源消耗。
作业的内存需求:根据作业在处理过程中的内存使用情况来分配合适的内存资源,以避免内存溢出错误。
作业的执行时间:预估作业完成所需的时间,结合作业的优先级和时效性要求,合理分配资源。
并发作业的数量:如果同时运行多个作业,需要考虑它们对资源的总体需求,并合理分配以避免资源争抢。
ataWorks不直接支持MaxCompute(ODPS)数据源,但可以通过配置Hologres数据源来连接和查询MaxCompute。资源申请应基于Hologres的规格,衡量标准包括存储容量、并发查询能力等。具体资源需求应根据您的数据量、查询复杂度和业务负载来评估。请参考Hologres数据源配置进行设置。
DataWorks 的 ODPS 资源申请和衡量需要综合考虑多个因素,包括任务类型、数据量、并发量等。具体如下:
任务类型:不同类型的任务对计算资源的需求不同。例如,Spark on MaxCompute 和 ODPS SQL 节点的资源需求就有所区别。
数据量:处理的数据量越大,所需的计算资源越多。尤其是在进行大规模数据分析或机器学习时,数据量的增加会显著影响资源需求。
并发量:多个任务并发执行时,需要更多的计算资源以保证每个任务都能高效运行。这种情况下,可能需要申请更多的 ODPS 资源。
任务复杂性:复杂的数据处理逻辑(如多表连接、多级聚合等)通常需要更多的计算资源。
调度频率:高频率的任务调度也会增加对计算资源的需求,特别是在实时数据处理的场景下。
预期执行时间:如果任务需要在特定时间内完成,可能需要更多的计算资源来保证任务按时完成。
总的来说,通过以上步骤和建议,可以合理申请和衡量 DataWorks 的 ODPS 资源,确保任务高效稳定地运行。同时,要注意根据实际业务需求和系统负载情况动态调整资源申请,以优化成本和性能。
在DataWorks中申请ODPS(Open Data Processing Service,阿里云的大数据计算服务)资源时,需要考虑的因素和衡量标准主要包括以下几个方面:
一、资源申请量的衡量
预期使用规模:
数据量:评估您将要在ODPS中处理的数据总量,包括日常处理的数据量和可能的峰值数据量。
计算量:考虑数据处理任务的复杂度和执行频率,以及是否需要高并发处理能力。
计算资源需求:
vCPU数:根据数据处理任务的CPU需求来确定所需的vCPU数量。
内存大小:根据任务的内存使用情况和峰值需求来配置内存大小。
存储资源需求:
存储空间:评估需要存储的数据量,并预留一定的扩展空间。
存储类型:根据数据访问的频率和性能需求选择合适的存储类型,如标准云盘或SSD云盘。
二、具体申请步骤
评估需求:首先明确您的数据处理需求,包括数据类型、处理量、处理频率等。
查看现有资源:了解当前DataWorks和ODPS的资源使用情况,评估是否需要增加资源。
制定申请计划:根据评估结果,制定ODPS资源申请计划,包括所需的vCPU数、内存大小、存储空间等。
提交申请:在DataWorks管理控制台或阿里云官网提交ODPS资源申请。
审核与部署:阿里云会对您的申请进行审核,并根据实际情况进行资源部署。
三、注意事项
灵活性:由于数据处理需求可能会随着业务发展而变化,建议在申请资源时保持一定的灵活性,以便在未来进行扩展或调整。
成本考虑:ODPS资源的费用是根据使用量(vCPU数、内存数等)和计算时间计算的,因此在申请资源时需要考虑成本因素,避免浪费。
性能优化:在申请资源后,还需要关注数据处理的性能表现,并根据实际情况对资源进行调优,以提高处理效率和降低成本。
综上所述,申请DataWorks的ODPS资源时需要根据预期使用规模、计算资源需求和存储资源需求进行衡量和规划,并在申请过程中注意灵活性、成本考虑和性能优化等方面的问题。
在DataWorks中申请ODPS(MaxCompute)资源时,主要涉及两个方面的考量:数据计算费用和数据调度费>。
数据计算费用:这是根据实际运行的任务所消耗的计算资源来计费的,计量单位是CU(Compute Unit)。数据计算任务,比如离线同步任务、数据服务任务、数据计算任务(ODPS SQL、PyODPS、EMR Hive)、数据质量规则执行等,都会产生数据计算费用。为了衡量这部分费用,你需要了解你的任务类型、复杂度、数据量以及预期的执行频率,从而预估所需的CU数量。可以通过监控历史任务执行情况或使用DataWorks提供的成本估算工具来帮助评估。
数据调度费用:当任务被发布至生产环境并进行周期性调度时,会产生数据调度费用,计费依据是成功运行的实例数(排除空跑任务)。这意味着你需要考虑任务的调度频率和成功执行的次数来预估调度费用。
针对Serverless资源组,它仅支持支付数据计算费用,数据调度费用需另外计费,不论采用按量付费还是包年包月模式
为了准确申请ODPS资源,建议采取以下步骤:
综上,ODPS资源的申请量应基于对工作负载的准确评估和成本效益分析来确定,确保既能满足业务需求又尽可能地经济高效。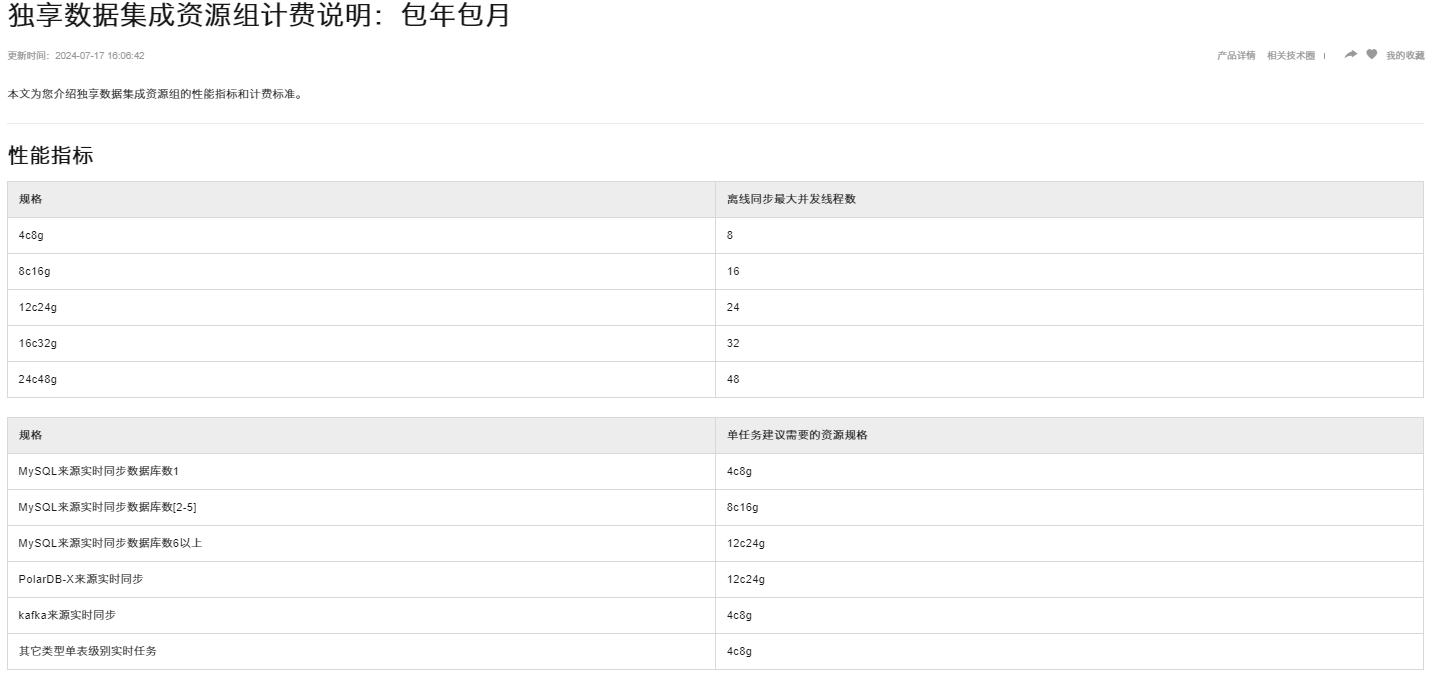
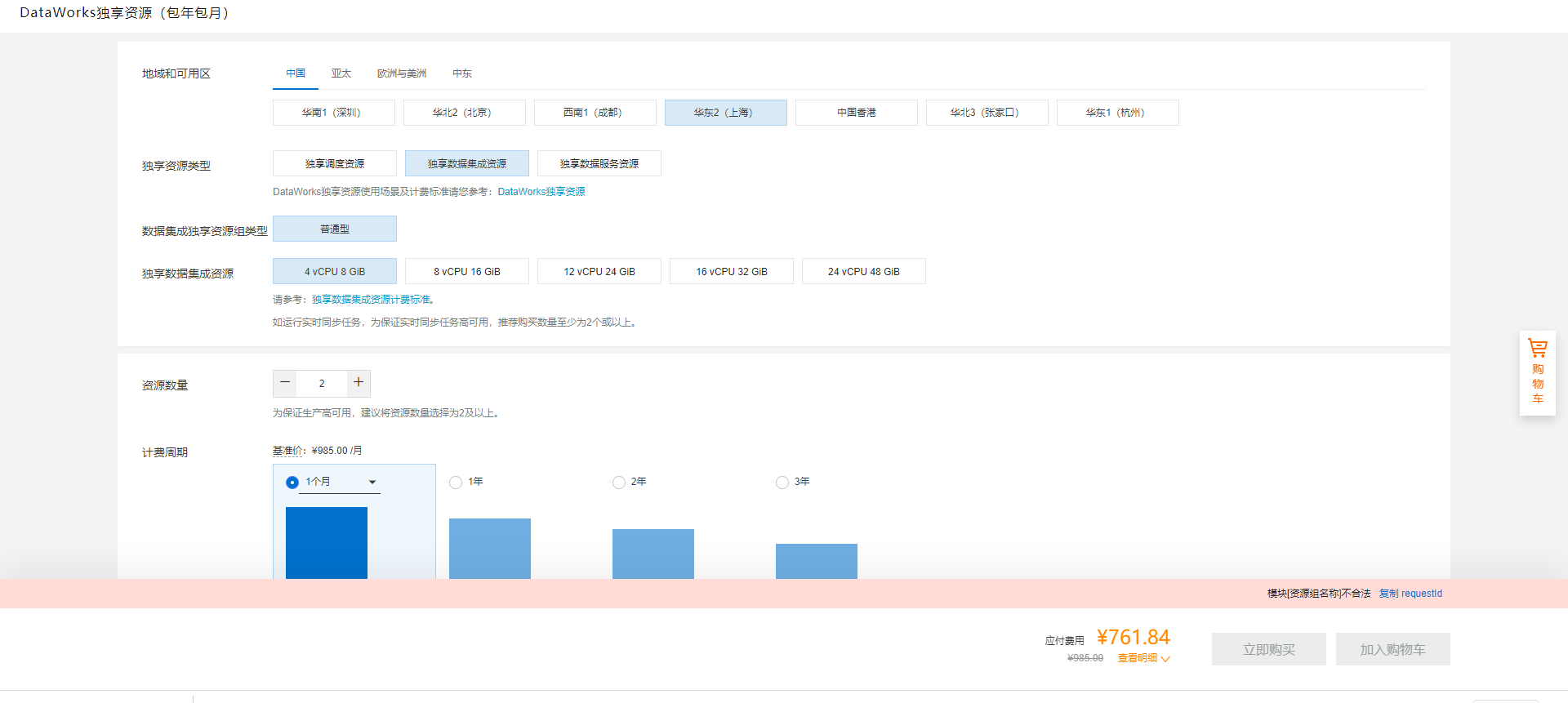
在阿里云DataWorks中,ODPS(现称为MaxCompute)是用于大规模数据处理的核心组件之一。当您在DataWorks中创建或运行任务时,涉及到ODPS的计算和存储资源的使用。要确定所需的ODPS资源,您需要考虑以下几个方面:
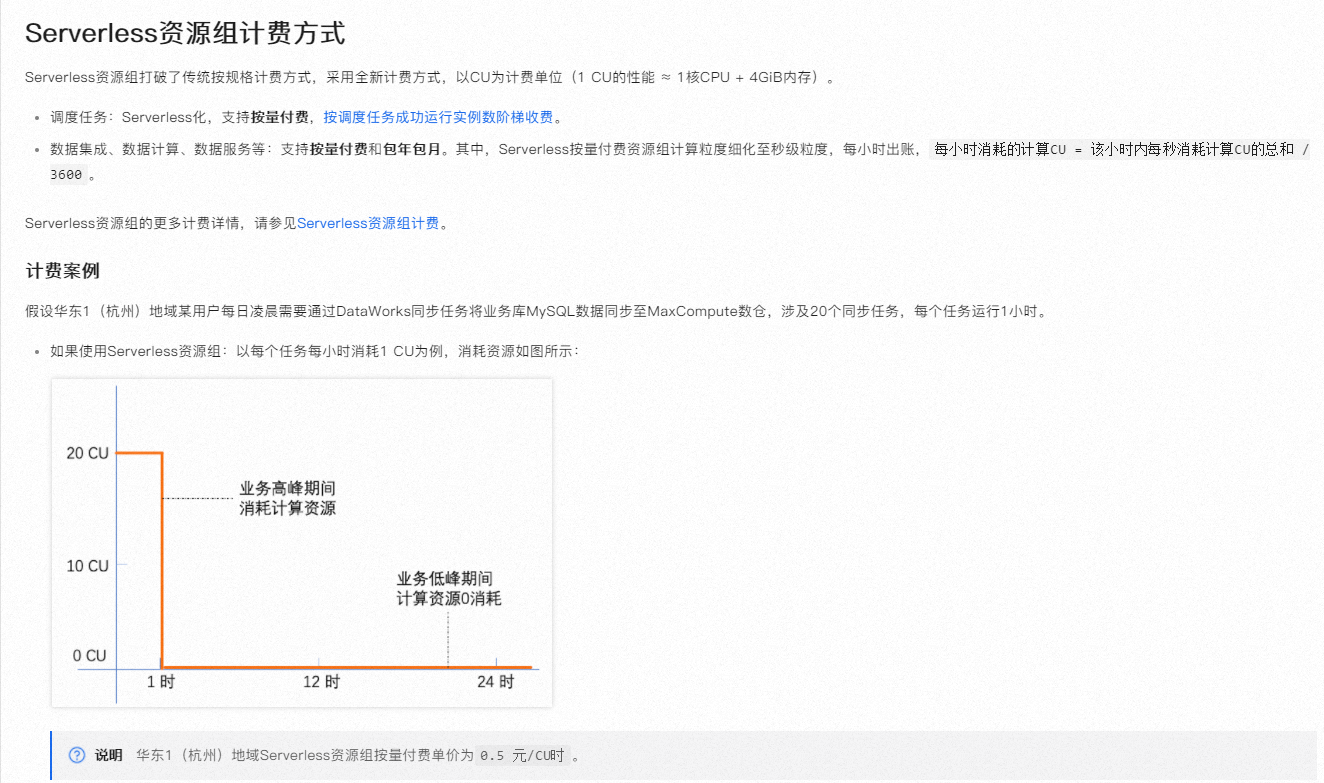
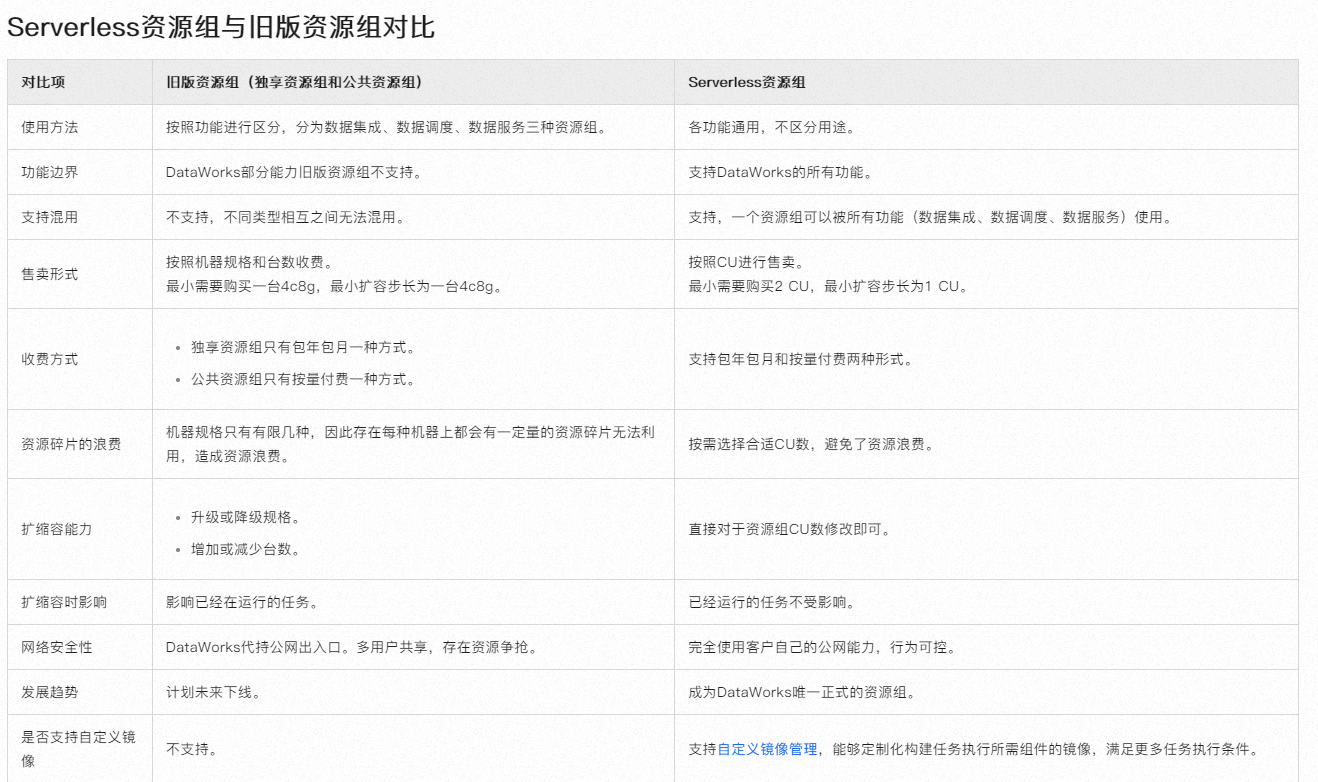
衡量ODPS资源需求时,可以参考以下指标: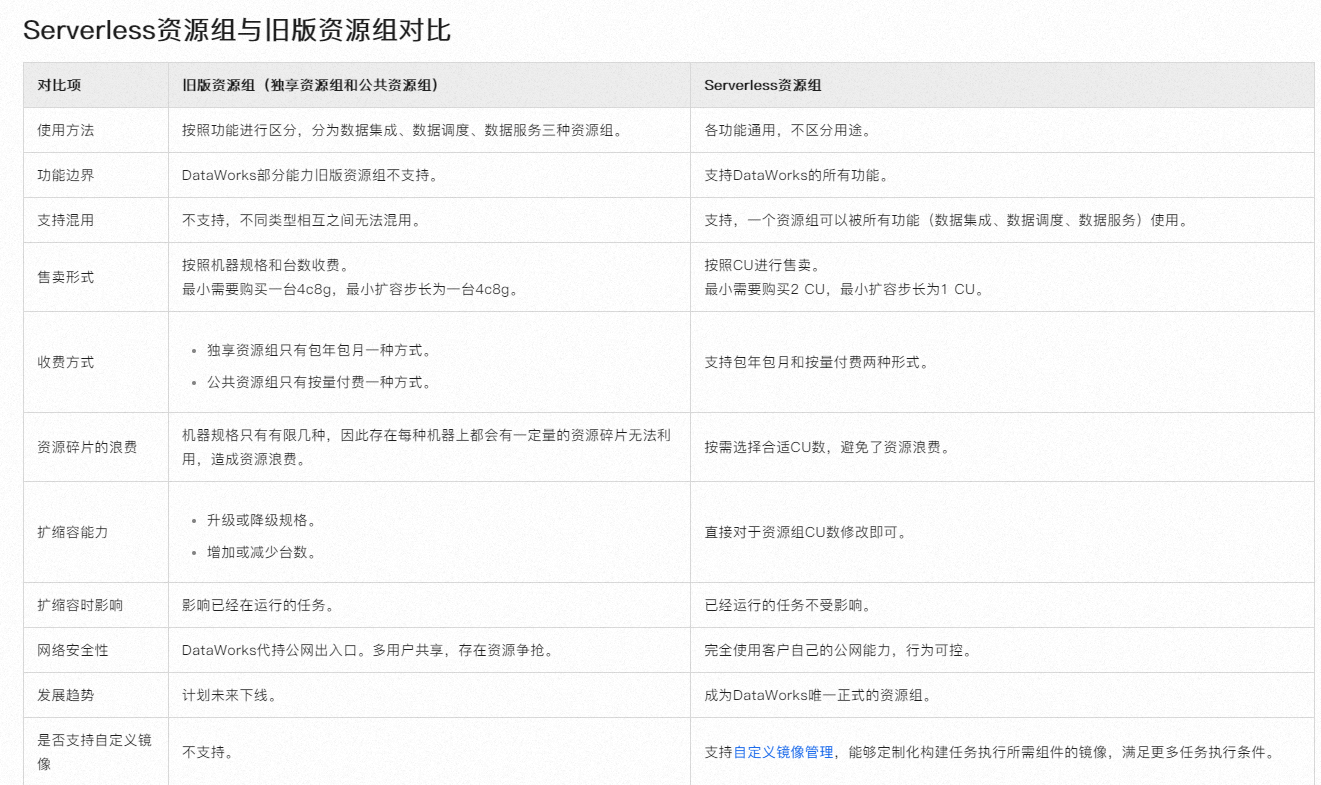
确定ODPS资源的最佳实践包括评估数据量、任务类型、并发度等因素,并根据历史数据和测试结果来估算资源需求。同时,持续监控资源使用情况,并根据实际需要进行调整,以确保资源的有效利用。
如果您需要更具体的指导或帮助,请随时告诉我。
如果你说的是钱的需要,这样看,你看看需要申请多少
在DataWorks中申请ODPS(MaxCompute)资源主要涉及到数据计算费用和数据调度费用两个方面:
数据计算费用:这是在执行数据处理任务时产生的费用,包括但不限于离线同步任务、数据服务任务、数据计算任务(如ODPS SQL、PyODPS、EMR Hive作业)以及数据质量规则的执行。费用以CU(Compute Unit)为计费单位,表示计算资源的使用量。
数据调度费用:当任务被发布到生产环境并进行周期性调度时产生,计费依据是成功运行的实例数(排除空跑)。需要注意的是,Serverless资源组目前仅支持支付数据计算费用,数据调度费用需另外计费,不论选择按量付费还是包年包月的Serverless资源组。
衡量所需资源量的方法:
评估数据量与复杂度:首先,根据您的数据处理需求,评估数据的总量、处理的复杂度(如SQL查询的复杂性、计算任务的逻辑等)以及任务的频率,这将直接影响所需的CU数量。
测试与监控:建议先使用较小规模的资源进行测试,通过实际运行来监测任务的资源消耗(特别是CU使用情况),并结合DataWorks提供的监控与分析工具来优化资源配置。
考虑调度需求:如果您的应用场景涉及大量周期性调度任务,除了计算资源外,还需预算数据调度费用。根据成功运行的任务实例数来预估这部分成本。
选择合适的资源组:根据您的业务需求和成本考量,选择独享资源组或公共资源组。独享资源组提供更稳定、专属的资源,适合对性能和稳定性有高要求的场景;公共资源组则更适合测试或成本敏感型应用。
任务的复杂度会影响所需资源的多少。例如,数据量大、计算密集型的任务可能需要更多的计算资源。如果任务需要快速完成,可能需要分配更多的资源以实现更快的处理速度
DataWorks提供不同类型的资源组,例如公共调度资源组和独享调度资源组,它们具有不同的资源规格和限制。例如,在独享调度资源组中,您可能需要根据代码是否调用第三方包来准备环境,而在新版资源组(通用型资源组)中,可以通过自定义镜像安装第三方包,还有就是DataWorks建议在PyODPS节点内获取到本地处理的数据不超过50 MB,以避免内存使用超限导致的错误。这需要根据任务处理的数据量来调整资源申请
DataWorks的ODPS资源申请取决于您的业务需求和数据处理量。
DataWorks的ODPS资源申请取决于您的业务需求和数据处理量。
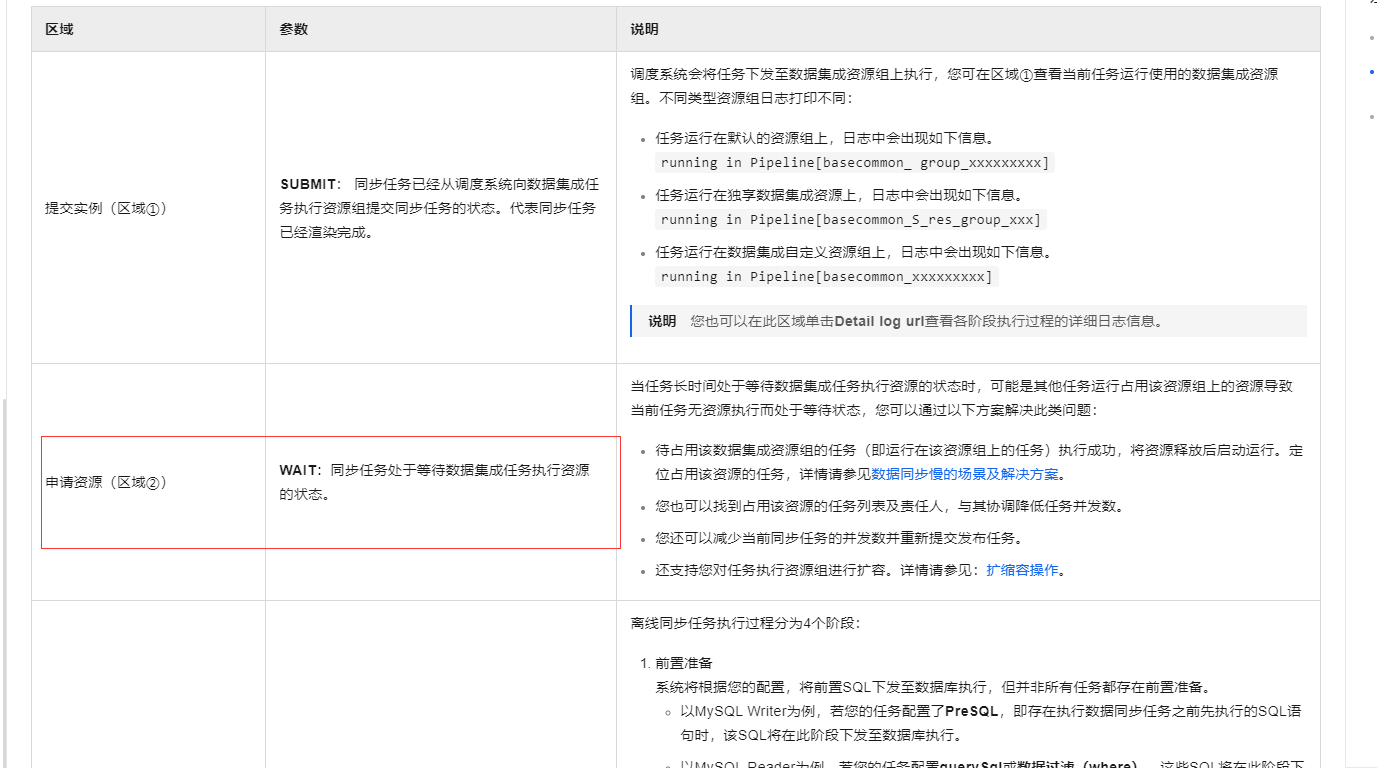
当任务长时间处于等待数据集成任务执行资源的状态时,可能是其他任务运行占用该资源组上的资源导致当前任务无资源执行而处于等待状态,您可以通过以下方案解决此类问题:
待占用该数据集成资源组的任务(即运行在该资源组上的任务)执行成功,将资源释放后启动运行。定位占用该资源的任务,详情请参见数据同步慢的场景及解决方案。
您也可以找到占用该资源的任务列表及责任人,与其协调降低任务并发数。
您还可以减少当前同步任务的并发数并重新提交发布任务。
还支持您对任务执行资源组进行扩容。详情请参见:扩缩容操作。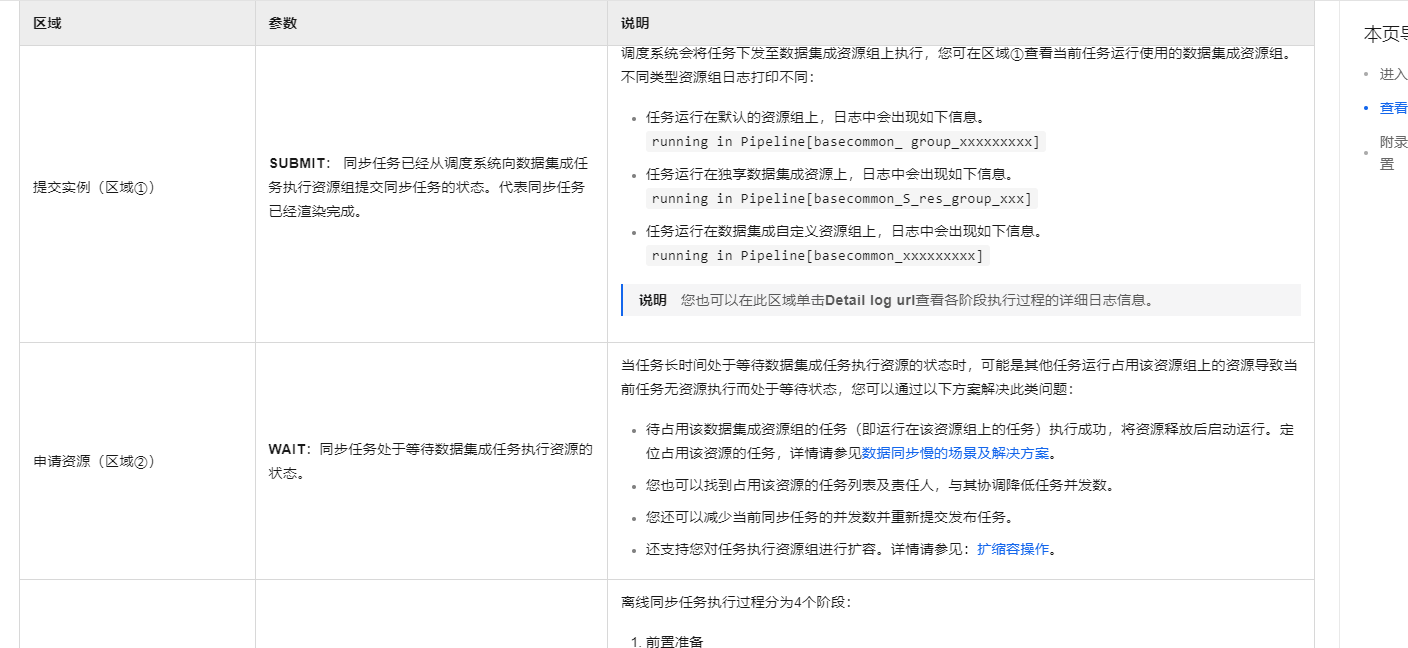
参考文档https://help.aliyun.com/zh/dataworks/user-guide/analyze-run-logs-generated-for-a-batch-synchronization-node?spm=a2c4g.11186623.0.i50
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。