
DataWorks从oss将csv数据加载到google drive的其他选项是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
直接从DataWorks将数据加载到Google Drive并非标准功能。通常做法是:
,您可以通过以下间接方法操作:
从OSS下载到本地:
使用DataWorks处理数据:
综上所述,虽然没有直接从OSS到Google Drive的桥梁,但结合本地操作、DataWorks的数据处理能力以及第三方API,可以构建一个流程实现数据迁移。请根据实际情况选择合适的步骤组合实施。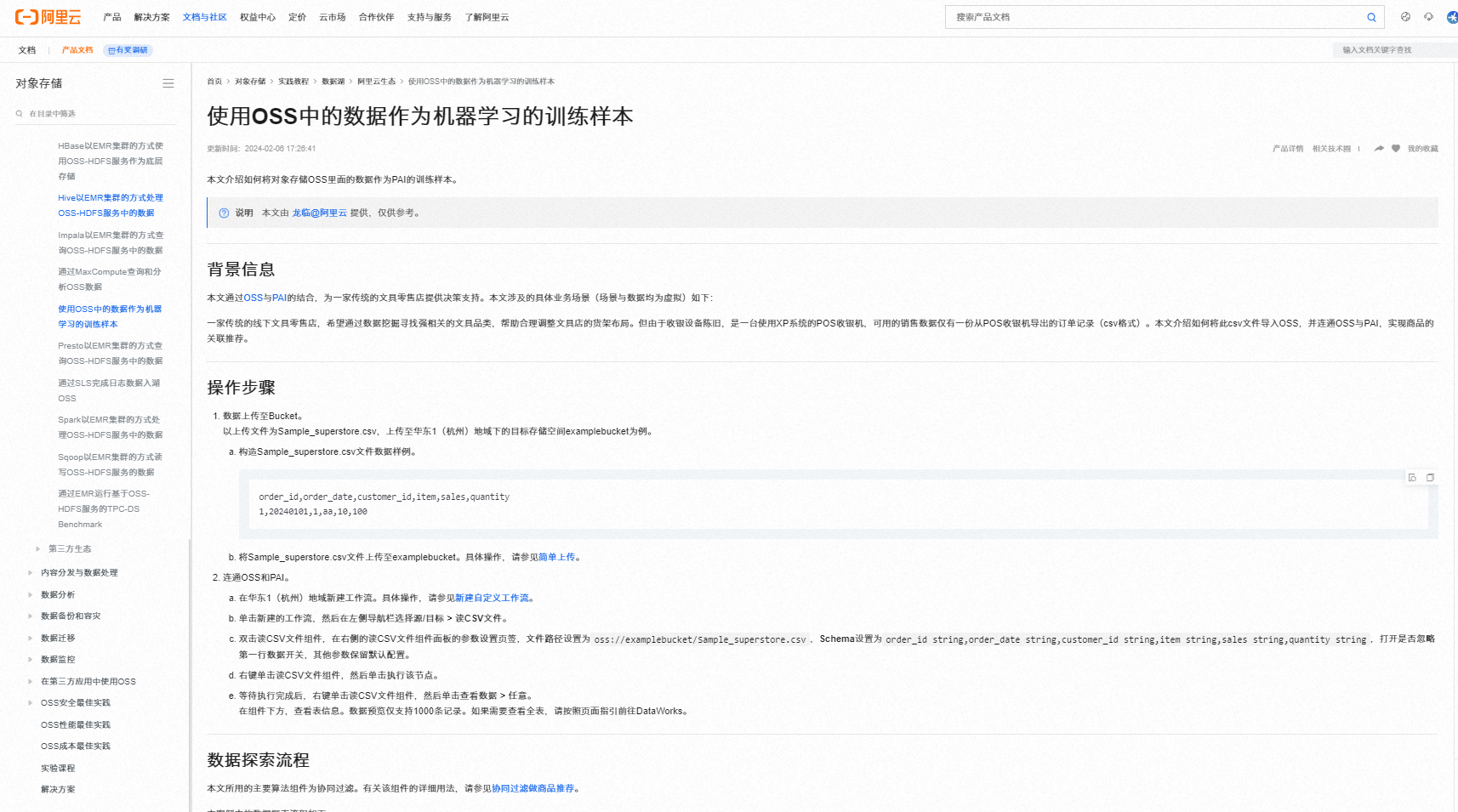
相关链接
https://help.aliyun.com/zh/oss/use-cases/use-oss-data-as-
使用Google Drive API通过脚本将数据上传到Google Drive。
手动从OSS下载CSV文件到本地,然后通过浏览器或Google Drive的桌面客户端上传到Google Drive。
DataWorks从OSS将CSV数据加载到Google Drive的其他选项包括使用脚本或编程语言、手动下载和上传、使用第三方工具等。在处理云存储服务之间的数据传输时,了解不同方法及其实现步骤至关重要。以下将深入探讨这些不同的方法,以及如何根据情况选择最佳方案:
使用脚本或编程语言:通过编写代码,可以使用Google Drive API将CSV文件从OSS直接上传到Google Drive。这需要创建一个Google API项目并获取API密钥,然后使用Python或其他编程语言编写代码来实现文件的上传。
手动下载和上传:如果数据量不大,可以考虑手动从OSS下载CSV文件,然后再上传到Google Drive。虽然这种方法可能不如其他选项方便,但它不需要任何额外的技术知识。
使用ETL工具:ETL(Extract, Transform, Load)工具如Apache Airflow或其他数据管道服务,可以配置流程将数据从OSS提取,处理后加载到Google Drive。
使用中间存储服务:可以将数据先加载到一个支持与Google Drive集成的服务上,例如使用Google Cloud Storage作为中转站,然后从Google Cloud Storage同步到Google Drive。
使用第三方工具或服务:利用第三方的数据迁移服务,有些服务商提供从一种云存储迁移到另一种云存储的服务。
使用Google Colab:如果您需要在Google Drive中处理CSV文件,可以考虑使用Google Colab。您可以在Colab中运行Python代码,从OSS读取CSV文件,然后使用pandas等库进行数据处理和分析。最后,您可以将处理后的数据保存到Google Drive中。
使用阿里云函数计算:创建函数计算函数,使用阿里云函数计算服务编写一个函数,该函数可以从OSS下载文件,并上传到Google Drive。
此外,在选择最适合的方法时,还需要考虑数据的敏感性和安全性。确保在传输过程中使用适当的加密和身份验证措施,以保护数据不被未授权访问。同时,对于大规模数据传输,考虑网络带宽和传输时间的成本也是重要的。
总的来说,DataWorks本身虽然不支持直接从OSS将数据加载到Google Drive,但通过上述多种方法可以实现这一需求。每种方法都有其独特的优势和局限性,因此最佳选择取决于具体情况,包括数据传输的规模、频率、安全性要求以及用户的技术能力。
将CSV文件从阿里云OSS传输到Google Drive,通常需要经过几个步骤或者使用一些中间工具来完成。DataWorks本身并不直接支持将数据从OSS传输到Google Drive,但你可以采用以下几种方式来实现这一过程:
除了使用DataWorks从OSS加载CSV数据到Google Drive,还可以考虑以下几种方法:
使用Google Drive API:通过编写代码,可以使用Google Drive API将CSV文件从OSS直接上传到Google Drive。这需要创建一个Google API项目并获取API密钥,然后使用Python或其他编程语言编写代码来实现文件的上传。
使用第三方工具:有一些第三方工具可以帮助您将CSV文件从OSS传输到Google Drive,例如CloudConvert、Zamzar等。这些工具通常提供简单的Web界面或命令行工具,可以让您轻松地将文件从一个云存储服务转移到另一个云存储服务。
手动下载和上传:如果您不想使用编程或第三方工具,可以从OSS下载CSV文件到本地计算机,然后手动将其上传到Google Drive。虽然这种方法可能不如其他选项方便,但它不需要任何额外的技术知识。
使用Google Colab:如果您需要在Google Drive中处理CSV文件,可以考虑使用Google Colab。您可以在Colab中运行Python代码,从OSS读取CSV文件,然后使用pandas等库进行数据处理和分析。最后,您可以将处理后的数据保存到Google Drive中。
要将CSV数据从阿里云OSS(Object Storage Service)加载到Google Drive,通常情况下,您需要先将数据从OSS下载到本地或另一个云服务,然后再上传到Google Drive。不过,考虑到DataWorks本身并不直接支持将数据从OSS加载到Google Drive,这里为您提供几种可行的方法来实现这一目标:
下载数据:
aliyun-python-sdk-oss)从OSS下载CSV文件到本地。上传数据:
google-auth, google-auth-oauthlib, google-api-python-client)将CSV文件上传到Google Drive。from oss2 import Auth, Bucket
from googleapiclient.discovery import build
from googleapiclient.http import MediaFileUpload
from google.oauth2.credentials import Credentials
# OSS配置
oss_access_key_id = 'your_oss_access_key_id'
oss_access_key_secret = 'your_oss_access_key_secret'
oss_bucket_name = 'your_bucket_name'
oss_endpoint = 'http://oss-cn-hangzhou.aliyuncs.com'
oss_object_key = 'path/to/your/csv_file.csv'
# Google Drive配置
google_drive_folder_id = 'your_google_drive_folder_id'
credentials = Credentials.from_authorized_user_file('token.json', ['https://www.googleapis.com/auth/drive'])
# 下载OSS文件
auth = Auth(oss_access_key_id, oss_access_key_secret)
bucket = Bucket(auth, oss_endpoint, oss_bucket_name)
bucket.get_object_to_file(oss_object_key, '/tmp/local_file.csv')
# 上传到Google Drive
drive_service = build('drive', 'v3', credentials=credentials)
file_metadata = {'name': 'csv_file.csv', 'parents': [google_drive_folder_id]}
media = MediaFileUpload('/tmp/local_file.csv', mimetype='text/csv')
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print(f'File ID: {file.get("id")}')
下载数据:
上传数据:
import oss2
from googleapiclient.discovery import build
from googleapiclient.http import MediaFileUpload
from google.oauth2.credentials import Credentials
def handler(event, context):
# OSS配置
oss_access_key_id = event['oss_access_key_id']
oss_access_key_secret = event['oss_access_key_secret']
oss_bucket_name = event['oss_bucket_name']
oss_endpoint = 'http://oss-cn-hangzhou.aliyuncs.com'
oss_object_key = event['oss_object_key']
# Google Drive配置
google_drive_folder_id = event['google_drive_folder_id']
credentials = Credentials.from_authorized_user_info(event['credentials'])
# 下载OSS文件
auth = oss2.Auth(oss_access_key_id, oss_access_key_secret)
bucket = oss2.Bucket(auth, oss_endpoint, oss_bucket_name)
bucket.get_object_to_file(oss_object_key, '/tmp/local_file.csv')
# 上传到Google Drive
drive_service = build('drive', 'v3', credentials=credentials)
file_metadata = {'name': 'csv_file.csv', 'parents': [google_drive_folder_id]}
media = MediaFileUpload('/tmp/local_file.csv', mimetype='text/csv')
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
print(f'File ID: {file.get("id")}')
这些方法提供了不同的灵活性和自动化程度,您可以根据您的具体需求和技术背景选择最合适的一种。如果您需要更详细的指导或者遇到具体问题,请随时告诉我。
,直接将CSV数据从OSS(Object Storage Service)加载到Google Drive并不直接支持,因为这是跨云平台的操作。但是,你可以通过以下步骤间接完成这个任务:
数据导出: 首先,在DataWorks中,你可以使用DataWorks的数据开发或数据集成模块,将OSS中的CSV数据导出到本地文件系统或者阿里云的其他服务,如RDS、TableStore等。
云间传输: 然后,你需要使用一种云间数据迁移工具或服务,例如阿里云的Data Transmission Service (DTS),将数据从阿里云迁移到其他云平台,但这通常需要目标云平台的支持。
本地处理: 另一个选择是将CSV文件下载到本地,然后使用本地工具(如Google Drive的Web界面、Google Takeout、第三方同步工具,或编程语言如Python的gspread库)将数据上传到Google Drive。
API/SDK: 你可以编写一个脚本或程序,使用阿里云和Google提供的API或SDK来实现数据的自动迁移。例如,使用阿里云的OSS SDK将CSV文件下载,然后使用Google Drive API或gspread库将数据写入Google Sheets。
中间服务器: 如果你有在两个云平台之间运行的服务器,你可以将数据从阿里云OSS复制到该服务器,然后从服务器上传到Google Drive。
DataWorks本身是一个大数据开发治理平台,它主要基于阿里云的大数据引擎(如MaxCompute、Hologres等)提供服务,并不直接支持将数据从OSS(对象存储服务)加载到Google Drive这样的非阿里云服务。
最简单直接的方式是将OSS中的CSV文件手动下载到本地计算机。然使用Google Drive的网页版或桌面应用将文件上传至Google Drive。
本身是不支持的,但是可以这样实现
先将OSS数据同步至MaxCompute:首先,利用DataWorks的数据集成服务,将OSS中的CSV文件同步至MaxCompute中。这一步骤遵循之前提到的配置流程,包括创建离线同步任务,配置OSS Reader读取OSS文件以及MaxCompute Writer写入数据
从MaxCompute导出数据到本地或OSS:完成同步后,您可将MaxCompute中的数据导出为CSV或其他格式文件,可以选择下载到本地或者再次上传到OSS中。DataWorks支持数据导出功能,但需注意处理数据量,大量数据可能需要更复杂的导出策略。
使用其他工具或服务迁移至Google Drive:最后,利用第三方工具或服务(如Cloud Storage Transfer Service、Python脚本结合Google Drive API等),将从OSS导出或存放的文件迁移到Google Drive中。这一步脱离了DataWorks环境,需要额外的编程或云服务配置能力。
有间接的方式
实时同步任务:DataWorks 的实时同步功能支持将源端数据库的数据变化实时同步至目标数据库中,适用于需要实时更新数据的场景。但是,实时同步任务目前仅支持运行在独享数据集成资源组上,并且不支持同步视图
。
离线同步任务:通过数据集成模块,您可以创建离线同步节点,用于批量数据的周期性同步。这适用于不需要实时同步,而是需要定期将数据从一处移动到另一处的场景
。
数据集成同步任务:数据集成提供了丰富的数据同步任务,包括整库离线同步和一键实时同步等。您可以根据同步场景选择同步解决方案,创建并执行同步任务,将源端数据同步至目标端
。
通过脚本模式配置:对于更复杂的同步需求,或者当数据源不支持向导模式配置任务时,您可以使用脚本模式配置离线同步任务,实现更精细化的同步控制
。
使用 DataWorks 的 OSS 数据同步能力:DataWorks 支持从 OSS 读取 TXT、ORC、PARQUET 格式的文件,并且支持递归读取、文件名过滤和多种压缩格式。写入时,支持文本类型并允许自定义分隔符,以及多线程写入不同的子文件
DataWorks本身不支持直接将数据从OSS加载到Google Drive。
可以编写一个脚本,使用Python或其他编程语言,结合阿里云OSS SDK和Google Drive API,将数据从OSS下载到本地,然后上传到Google Drive。

参考文档https://help.aliyun.com/zh/dataworks/user-guide/create-an-odps-sql-node?spm=a2c4g.11186623.0.i318
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


