使用datawork运行pyspark脚本,其中的python第三方库需要怎么导入?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
已安装Python 3.8及以上版本。本文以Python 3.8为例介绍。
使用Conda
步骤一:Conda环境构建与部署
通过以下命令安装Miniconda。
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh -b
source miniconda3/bin/activate
构建使用Python 3.8和numpy的Conda环境。
conda create -y -n pyspark_conda_env -c conda-forge conda-pack numpy python=3.8
conda activate pyspark_conda_env
conda pack -f -o pyspark_conda_env.tar.gz
要在DataWorks中运行PySpark脚本并导入Python第三方库,使用PEX文件
打包PEX文件:
pip3.8 install --user pex wheelpip3.8 wheel -w /tmp/wheel pyspark pandas pyarrow numpypex -f /tmp/wheel pyspark pandas pyarrow numpy -o spark_with_deps.pex上传PEX文件至OSS:
kmeans.py和数据文件)上传至阿里云对象存储服务(OSS)。开发并运行任务:
kmeans.py路径。Spark配置中指定驱动和执行器的Python为PEX文件内的Python环境,如:spark.pyspark.driver.python ./spark_with_deps.pex 和 spark.pyspark.python ./spark_with_deps.pex。使用PEX文件:
# 首先,安装pex和wheel工具:
pip3.8 install --user pex wheel
下载所需的Python库wheel文件至临时目录,如:
pip3.8 wheel -w /tmp/wheel pyspark==3.3.1 pandas==1.5.3 pyarrow==15.0.1 numpy==1.24.4
生成PEX文件:
pex -f /tmp/wheel --no-index pyspark==3.3.1 pandas==1.5.3 pyarrow==15.0.1 numpy==1.24.4 -o spark331_pandas153.pex
安装pex和wheel。
下载所需库的wheel文件。
生成包含所需库的PEX文件。
将PEX文件上传至OSS。
在DataWorks创建PySpark任务,配置主Python资源、运行参数和files资源,设置Spark配置指向PEX文件。
使用Conda环境:
在本地构建Conda环境并打包成tar.gz文件。
上传Conda环境文件至OSS。
在DataWorks创建PySpark任务,配置主Python资源、运行参数和archives资源,设置Spark配置指向Conda环境中的Python路径。
在使用DataWorks运行PySpark脚本时,导入Python第三方库的方式与在标准Python环境中类似,但需要注意DataWorks环境的特殊性和限制。DataWorks主要是一个数据开发平台,它支持使用PySpark等大数据处理框架,但可能并不直接支持所有Python第三方库的安装或导入。以下是一些建议的步骤和注意事项:
检查DataWorks的内置库
首先,检查DataWorks是否已经内置了你需要的Python第三方库。DataWorks可能会预装一些常用的库,如numpy、pandas等,以支持常见的数据处理任务。
使用DataWorks的依赖管理功能
如果DataWorks支持依赖管理(如Maven依赖或自定义依赖包),你可以尝试通过这些功能来导入所需的Python库。不过,需要注意的是,DataWorks主要面向大数据处理,其依赖管理可能更侧重于Java或Scala的库,而不是Python库。
自定义资源包
如果DataWorks支持上传自定义资源包(如jar包、zip包等),你可以考虑将Python第三方库及其依赖打包成一个zip文件,并上传到DataWorks中。然后,在你的PySpark脚本中,你可能需要编写一些额外的代码来解压这个zip包,并将其添加到Python的搜索路径中。然而,这种方法可能比较复杂,且不一定在所有DataWorks环境中都可行。
使用虚拟环境或Docker容器
如果DataWorks允许你使用虚拟环境或Docker容器来运行你的PySpark脚本,那么你可以在一个预装了所有所需Python第三方库的虚拟环境或Docker容器中运行你的脚本。不过,这通常需要你有一定的系统管理员权限,并且需要了解如何配置和部署虚拟环境或Docker容器。
咨询DataWorks的技术支持
如果你不确定如何在DataWorks中导入Python第三方库,或者上述方法都不适用,那么最好的做法是咨询DataWorks的技术支持团队。他们可以提供针对你具体需求的解决方案,并帮助你解决在导入第三方库时遇到的问题。
注意事项
在尝试导入Python第三方库之前,请确保这些库与PySpark兼容,并且可以在你的DataWorks环境中正常运行。
考虑到DataWorks主要面向大数据处理,一些轻量级的Python库可能并不适合在DataWorks环境中使用。在这种情况下,你可能需要寻找替代方案或调整你的数据处理策略。
始终关注DataWorks的官方文档和更新日志,以了解有关依赖管理和库支持的最新信息。
在DataWorks中运行PySpark脚本时,如果需要导入第三方Python库,可以按照以下步骤操作:
首先,确保你已经安装了需要的第三方库。可以使用pip install命令来安装所需的库。例如,如果你需要安装pandas库,可以在命令行中执行以下命令:
复制代码运行
pip install pandas
将安装好的第三方库上传到DataWorks的工作空间。可以通过DataWorks控制台的文件管理功能,或者使用FTP等方式将库文件上传到工作空间的指定目录。
在PySpark脚本中,使用--py-files参数指定要加载的第三方库文件。例如,如果你已经将pandas库上传到了工作空间的libs目录下,你可以在提交PySpark任务时添加以下参数:
复制代码运行
--py-files libs/pandas-*.whl
在PySpark脚本中,你可以像通常那样导入第三方库。例如,导入pandas库后,就可以使用其提供的功能了:
python
复制代码运行
import pandas as pd
请注意,由于DataWorks是基于Hadoop集群运行的,因此你需要确保上传的第三方库与Hadoop集群中的Python环境兼容。另外,如果你使用的是虚拟环境,还需要确保虚拟环境中安装了相应的库。
在阿里云 DataWorks 中运行 PySpark 脚本时,如果需要使用 Python 第三方库,可以采用以下几种方法来导入这些库:
添加依赖库:
.py 文件或 .jar 文件。在 PySpark 脚本中引用:
在 PySpark 脚本的开头,使用如下方式引用你添加的资源:
from odps import ODPS
odps = ODPS('<access_id>', '<access_key>', '<project_name>', endpoint='<endpoint>')
# 添加 PyFile 资源
odps.add_file('<resource_name>')
# 导入第三方库
import <library_name>
配置 PyPI 镜像源:
在 PySpark 脚本中安装和导入库:
!pip install 命令安装所需的库,然后导入。!pip install <library_name> --target /tmp/user_library
import sys
sys.path.insert(0, '/tmp/user_library')
import <library_name>
下载第三方库:
.whl 文件。上传到 DataWorks:
.whl 文件上传到 DataWorks 的项目中。在 PySpark 脚本中引用:
import sys
sys.path.insert(0, '<path_to_your_whl_file>')
import <library_name>
addPyFile 方法添加 PyFile:
在 DataWorks 中上传 .py 文件或 .whl 文件,并在 PySpark 脚本中使用 addPyFile 方法添加这些文件。
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
sc.addPyFile('<path_to_your_py_file_or_whl_file>')
import <library_name>
假设你需要使用 requests 库,你可以按照以下步骤操作:
requests 的 .whl 文件。.whl 文件到 DataWorks。import sys
sys.path.insert(0, 'libs/requests-2.27.1-py2.py3-none-any.whl')
import requests
print(requests.__version__)
请注意,实际路径可能需要根据你的项目设置进行调整。
希望这些信息对你有所帮助!如果有任何具体的问题或需要进一步的帮助,请随时告诉我。
在使用DataWorks运行PySpark脚本时,导入Python第三方库可以按照以下步骤进行:
首先,确保您要导入的第三方库与DataWorks的PySpark环境兼容。DataWorks的PySpark运行环境可能有限制,不是所有的第三方库都能在其中正常运行。
--py-files参数上传依赖在提交PySpark作业时,可以使用--py-files参数来上传包含第三方库的.zip文件或.egg文件。
.zip文件。--py-files参数,并指定上传的.zip文件路径。--py-files /path/to/your/libraries.zip
import语句导入第三方库。import some_third_party_library
addPyFile方法SparkContext的addPyFile方法来动态添加Python文件。
```
如果你是通过Spark参数配置自定义Python环境
那么就需要在PySpark中直接使用第三方库进行数据处理。
操作步骤:
使用PEX文件打包Python环境和第三方库。
安装PEX与wheel工具。
下载所需库的wheel文件至临时目录。
生成PEX文件,例如:
bash
pex -f /tmp/wheel pyspark==特定版本 pandas==特定版本 ... -o 自定义PEX文件名.pex
将生成的PEX文件上传至OSS。
在DataWorks中开发并运行任务:
创建PySpark应用,配置主Python资源、运行参数、files资源(指向PEX文件)及Spark配置,如:
properties
spark.pyspark.driver.python ./自定义PEX文件名.pex
spark.pyspark.python ./自定义PEX文件名.pex
使用--py-files选项:你可以将Python库的压缩文件(.zip或.egg)传递给--py-files选项,这样PySpark就可以在会话中使用这些库了。例如,如果你有一个包含所需库的libraries.zip文件,可以在提交作业时这样配置:
--py-files /path/to/libraries.zip
这样就可以啦
进入运维助手
登录DataWorks控制台,单击左侧导航栏的资源组列表,进入资源组列表页面。
在独享资源组页签,单击相应调度资源组后的image.png图标,选择运维助手,进入所选资源组的运维助手页面。
您可根据需要创建命令,通过命令安装执行任务所需的第三方包。
说明
运维助手只能用于独享调度资源组,不能用于独享数据集成资源组、新版资源组。
安装第三方包
创建用于安装第三方包的命令。
安装的第三方包可被当前资源组运行调度任务时使用。在所选资源组的运维助手页面,单击创建命令,可选择使用快捷方式或手动输入方式创建命令。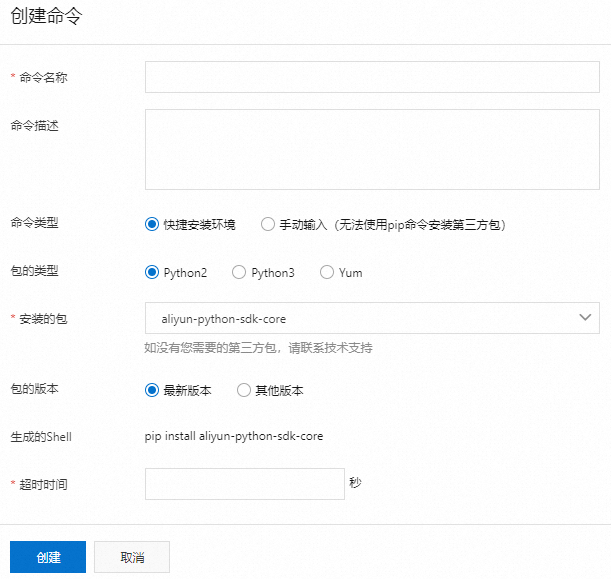
参考文档https://help.aliyun.com/zh/dataworks/user-guide/use-the-maintenance-assistant-feature?spm=a2c4g.11186623.0.i26
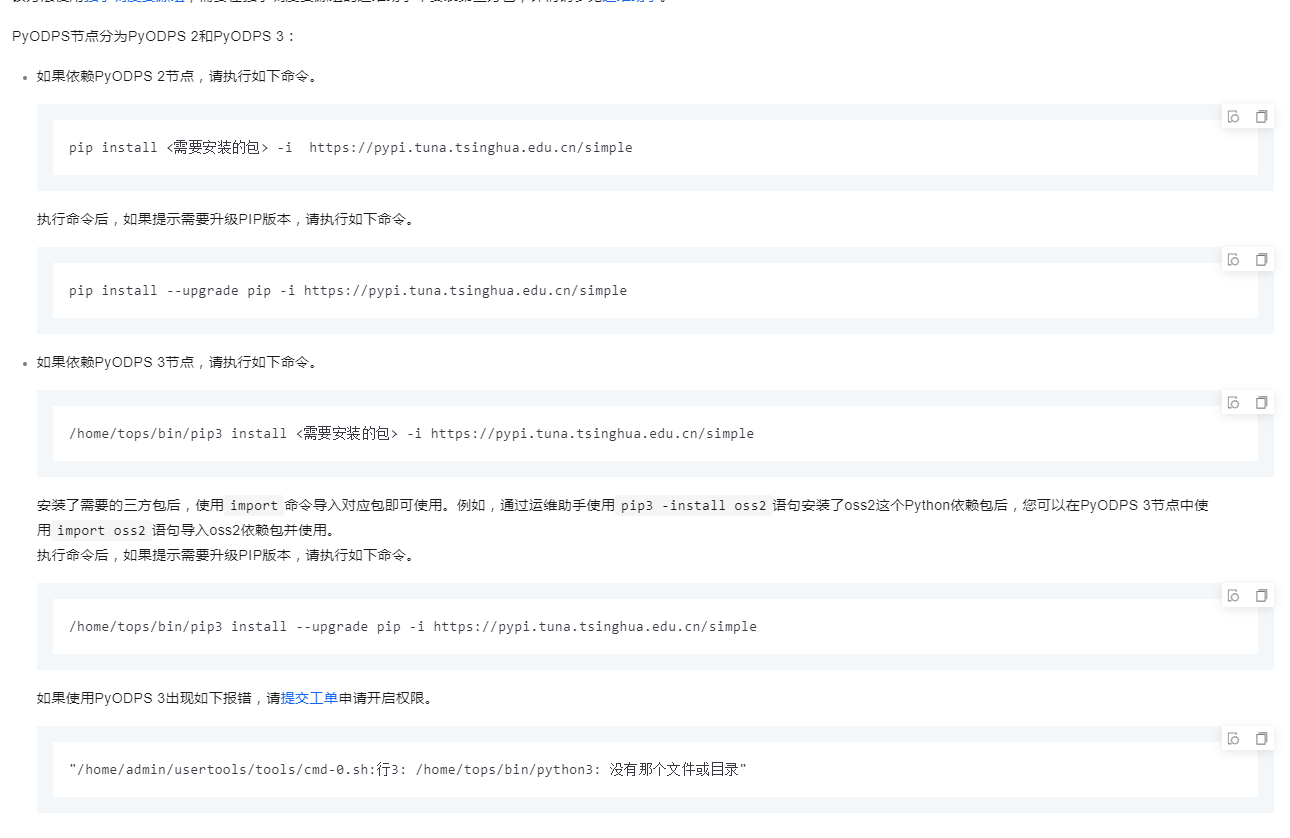
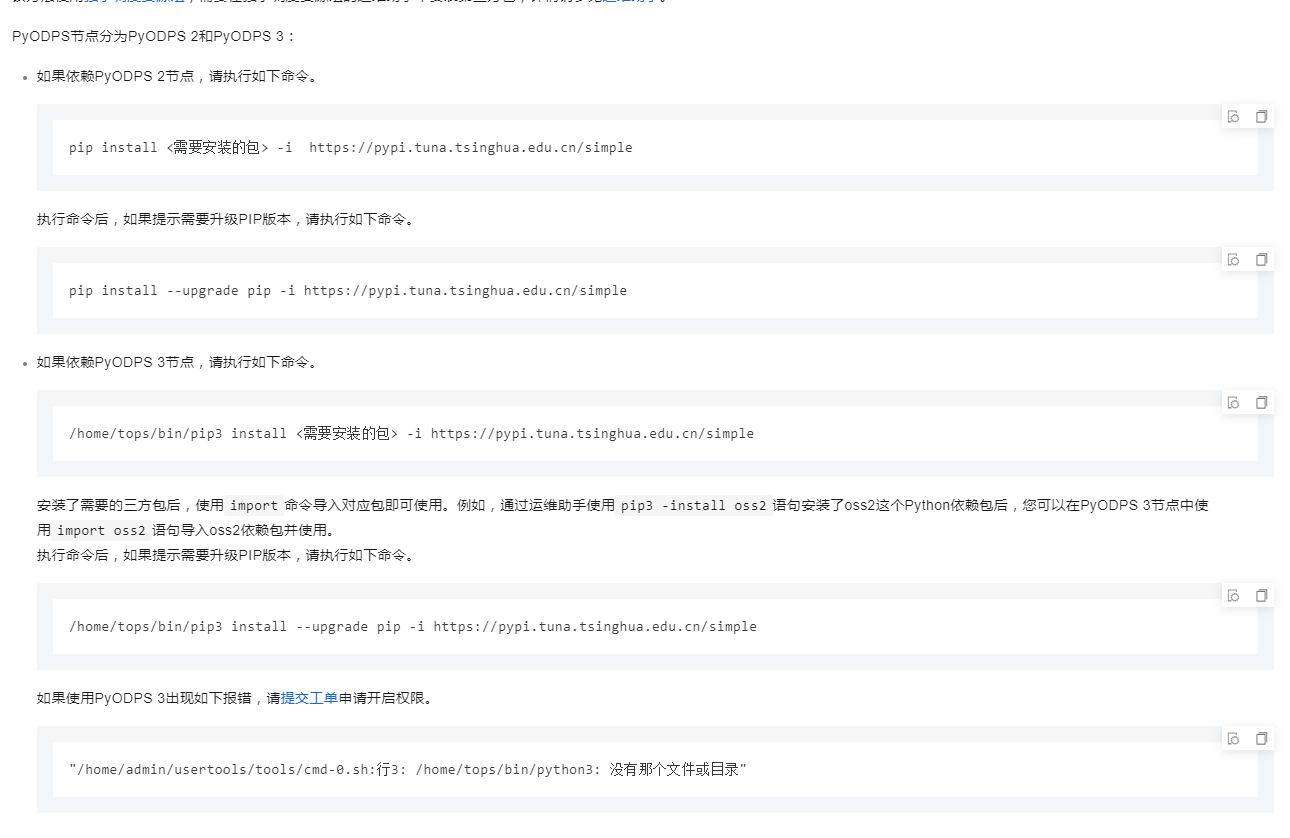
本文为您介绍在依赖普通的Python脚本和开源第三方包的场景下,如何使用DataWorks PyODPS节点调用第三方包。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/use-a-pyodps-node-to-reference-a-third-party-package?spm=a2c4g.11186623.0.i122
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。