
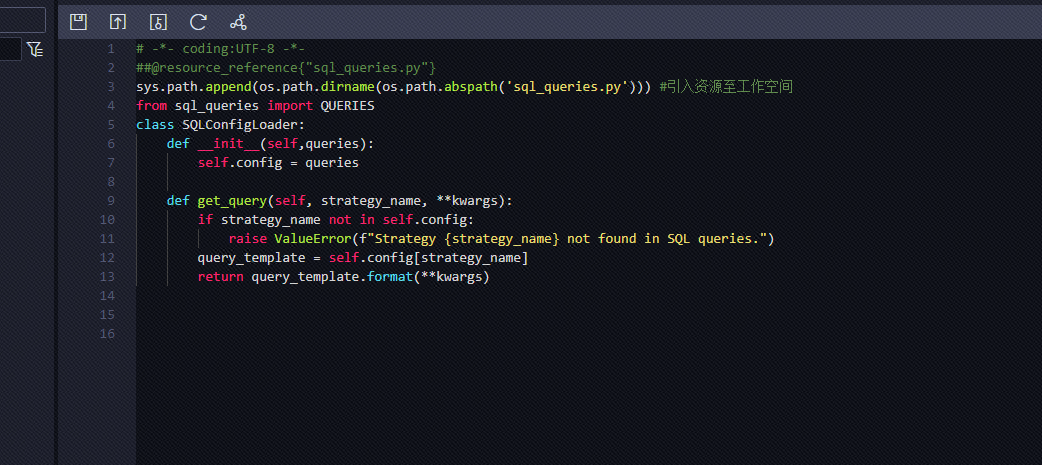
在用datawroks的python目录,资源目录下放了一个方法,用来读取数据, 数据queries也放在了同目录下的资源下,但是后续在正常脚本中引入这个sql_config_loader没法正常读取,也不会报错,目前是资源不支持引用资源吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
按理解是支持的
py1.py:
print 'py1'
pyodps2测试import py文件资源:
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath('py1.py')))
import py1
print 'pyodps2,import了py1'
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks (阿里云的数据开发平台) 中,资源目录用于存放各类静态资源文件,如SQL脚本、配置文件等。当你提到在Python目录下的资源目录中放置了一个方法来读取数据,这里可能存在一定的误解。通常情况下,资源目录存放的是数据或配置文件,而非直接存放Python脚本或方法。
如果你想要在DataWorks的Python脚本中引用另一个Python脚本(例如你的sql_config_loader方法),你需要确保遵循Python模块导入的规范。但直接在资源目录下存放可执行的Python代码并尝试在其他脚本中直接导入,这并不符合DataWorks的标准使用方式。DataWorks期望资源目录中的文件更多地被当作静态资源配置,而不是作为代码模块直接执行。
解决此问题的方法如下:
模块化组织代码: 如果你的sql_config_loader是一个通用的函数或类,应该将其放在一个标准的Python模块中。你可以创建一个新的Python文件(例如utils.py),将该方法定义在这个文件里,然后将此文件上传至DataWorks的Python代码目录(非资源目录),之后在其他脚本中通过标准的import语句引用。
# 在utils.py中
def sql_config_loader():
# 你的方法实现
pass
# 在另一个脚本中引用
from utils import sql_config_loader
使用DataWorks的依赖管理: 如果你的脚本依赖于外部库或自定义模块,确保这些依赖已经在项目设置中正确添加。DataWorks允许你上传额外的Python包或指定自定义的Python环境,以满足脚本的运行需求。
资源文件的引用: 对于SQL查询文件(如.sql文件),正确的做法是在Python脚本中使用DataWorks提供的API(如odps.run_sql)来读取并执行这些SQL脚本,而不是直接在Python脚本内部通过代码读取资源目录下的SQL文件。
如果确实需要动态加载资源目录下的配置文件(比如JSON或YAML格式的配置文件),可以通过DataWorks的SDK(如MaxCompute Python SDK)读取项目空间内的资源文件,但这也需要明确的路径和适当的API调用,而不是直接在脚本中通过文件系统路径访问。
确保检查你的DataWorks项目配置、权限设置以及代码逻辑,确保按照平台的最佳实践进行操作。如果问题仍然存在,建议查看DataWorks的帮助文档或联系技术支持获取进一步的帮助。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


