DataWorks这里是通过数据过滤的方式去做增量?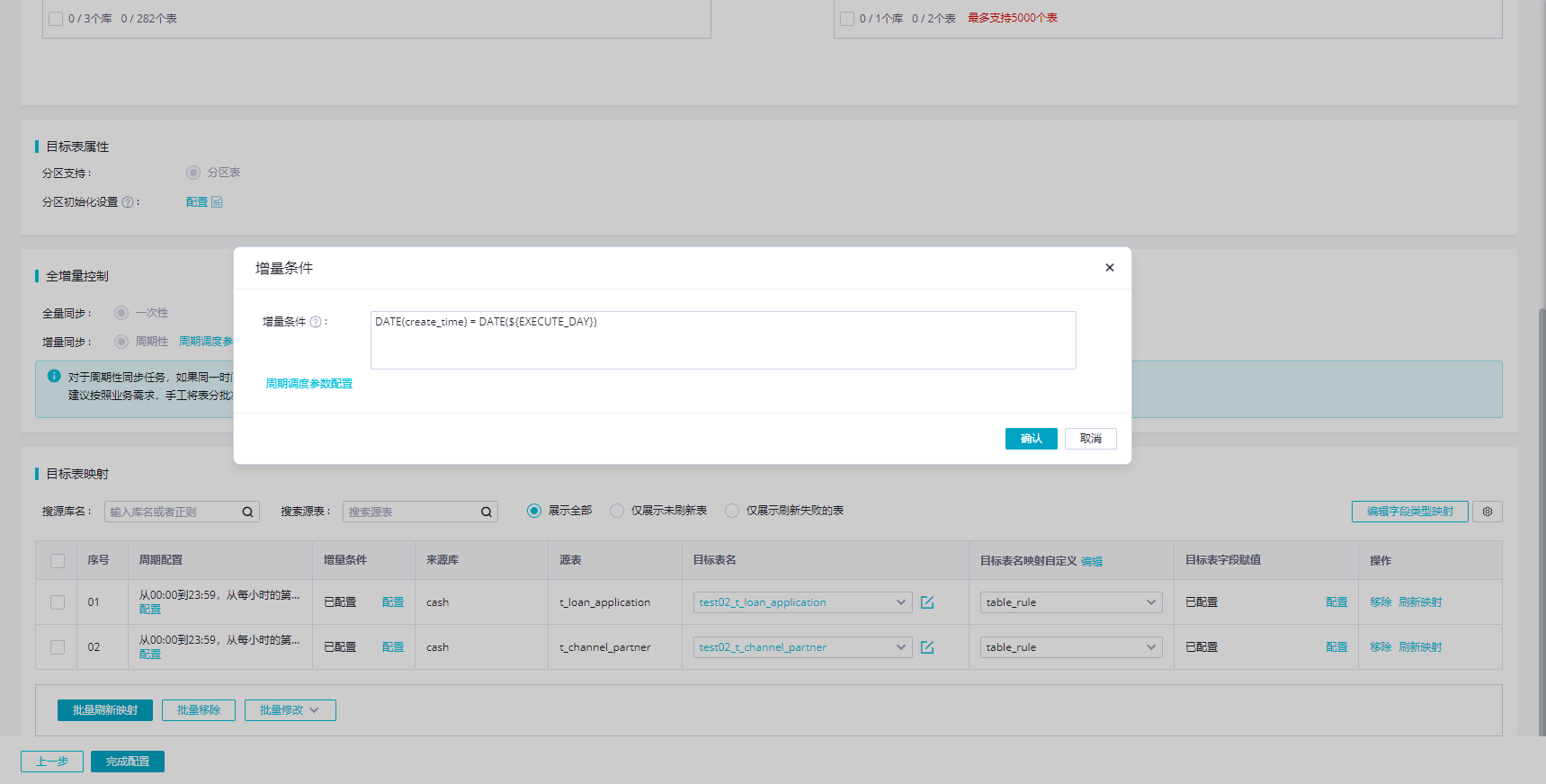
当天创建的任务,分区值只能取到增量数据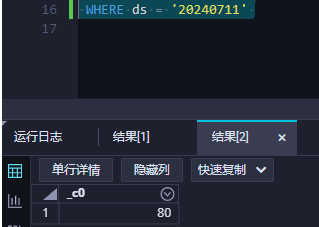
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
关于在DataWorks中如何通过数据过滤方式实现增量数据同步,您需要遵循以下步骤:
识别数据源支持性:首先确认您的数据源是否支持增量同步。部分数据源如HBase、OTSStream目前不支持增量同步,而MySQL、MongoDB等则支持。具体支持情况请查阅对应Reader插件的文档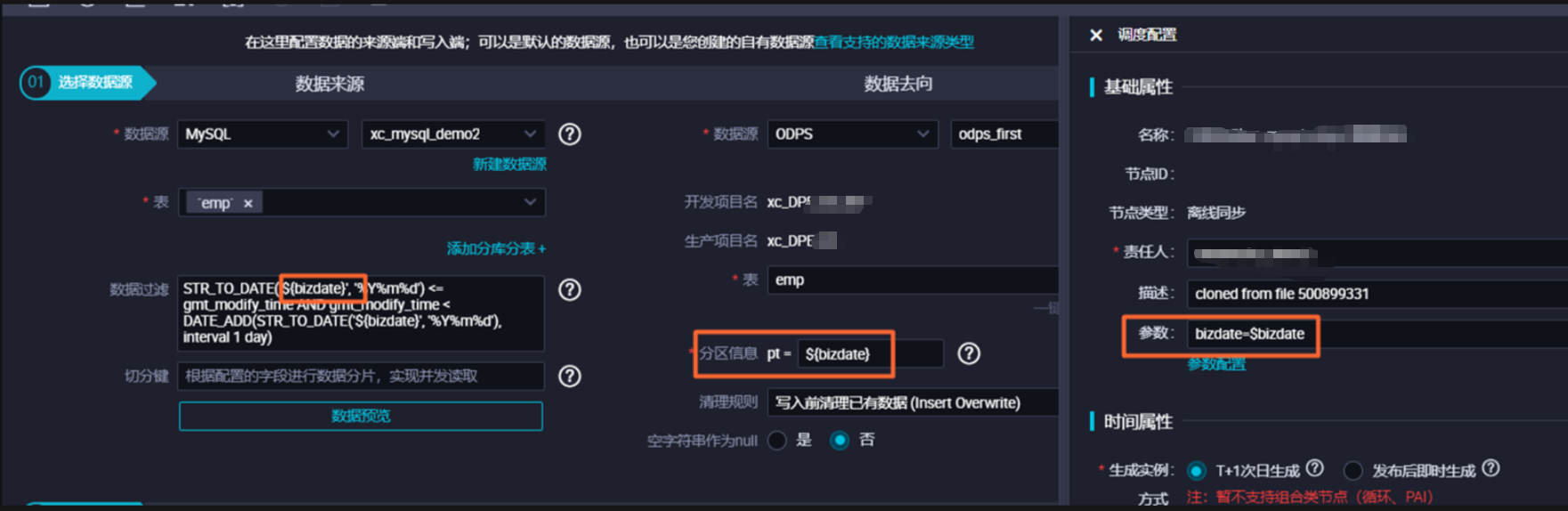
配置增量参数:在数据集成任务配置界面,针对支持增量的数据源,利用Reader插件提供的增量同步参数进行配置。例如,对于MySQL Reader,您可以在“数据过滤”(向导模式下)配置筛选条件,以实现只同步满足条件的增量数据至目标表中
利用调度参数:结合调度参数(如${bdp.system.bizdate}代表业务日期)来动态控制数据同步的时间范围,实现每日或特定时间间隔的数据增量同步。调度参数可以用于时间类型增量字段的动态替换,也可以通过赋值节点处理非时间类型的增量字段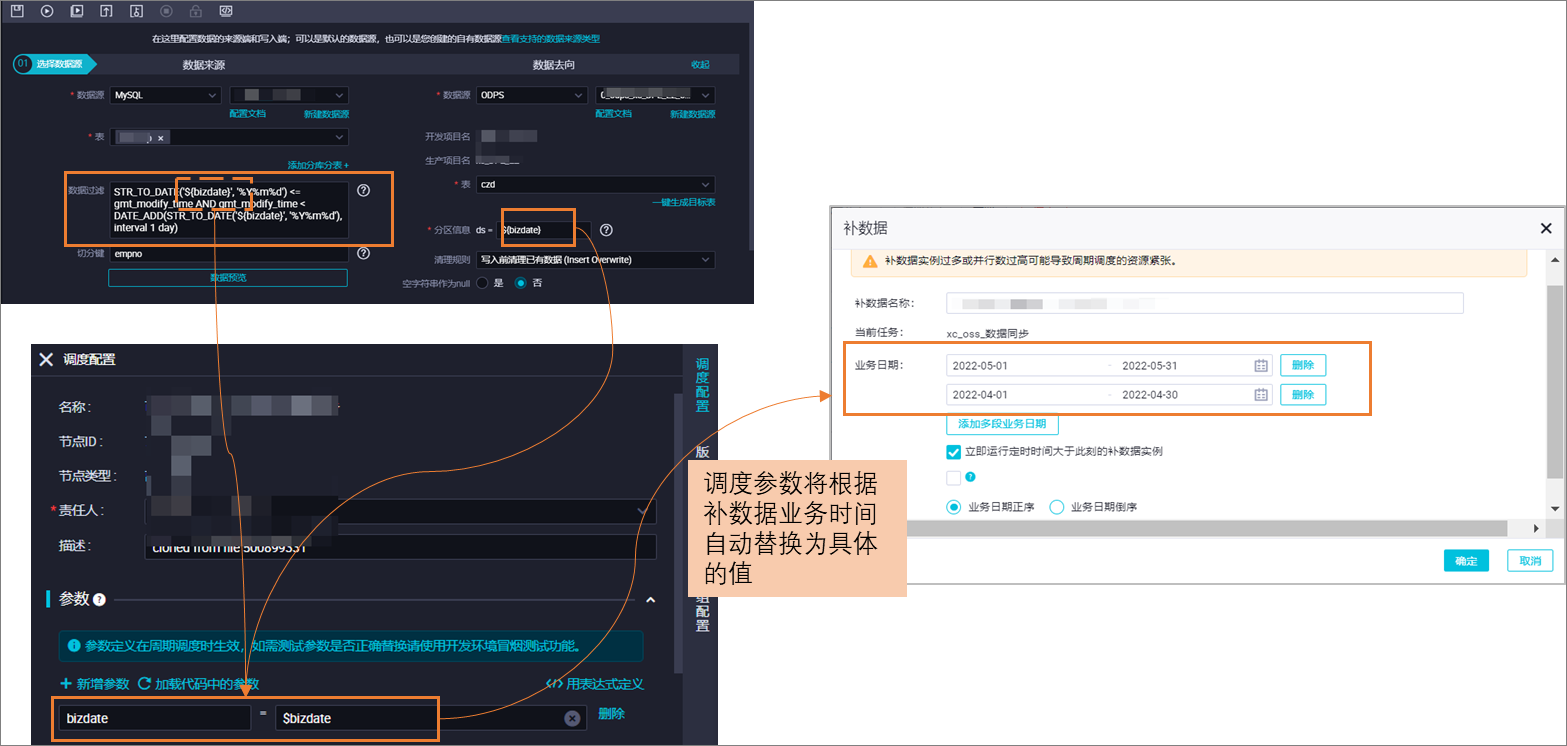
配置调度周期:在同步规则设置中,明确增量同步的数据规则,使用where子句(无需写where关键字)来过滤数据,并配置任务的调度周期、生效日期等,确保任务按预期周期性执行增量同步
综上所述,通过在OSS Writer配置中寻找包含表头的选项,以及利用数据过滤和调度参数策略,您可以在DataWorks中实现数据导出到OSS时包含表头,并有效执行增量数据同步任务。
https://help.aliyun.com/zh/dataworks/user-guide/configure-a-batch-synchronization-node-to-synchronize-only-incremental-data?spm=a2c6h.13066369.question.115.289a45e88ptEsp
配置增量同步
数据集成离线同步任务中,可以使用调度参数来指定同步源表及目标表的数据路径以及数据范围,调度参数的配置方式与其他类型任务一致,没有特殊限制。
在同步任务运行时,任务中配置的占位符参数都会被替换为调度参数表达式所表达的实际值,然后再执行数据同步。
以同步MySQL数据为例:
当不配置数据过滤时,默认同步全量数据至目标表中。
当配置数据过滤时,将只同步满足过滤条件的数据至目标表中。
目标MaxCompute表分区名称以调度参数的方式指定,$bizdate表示业务日期,定时任务执行时,任务配置的分区表达式会替换为调度参数所表达的业务日期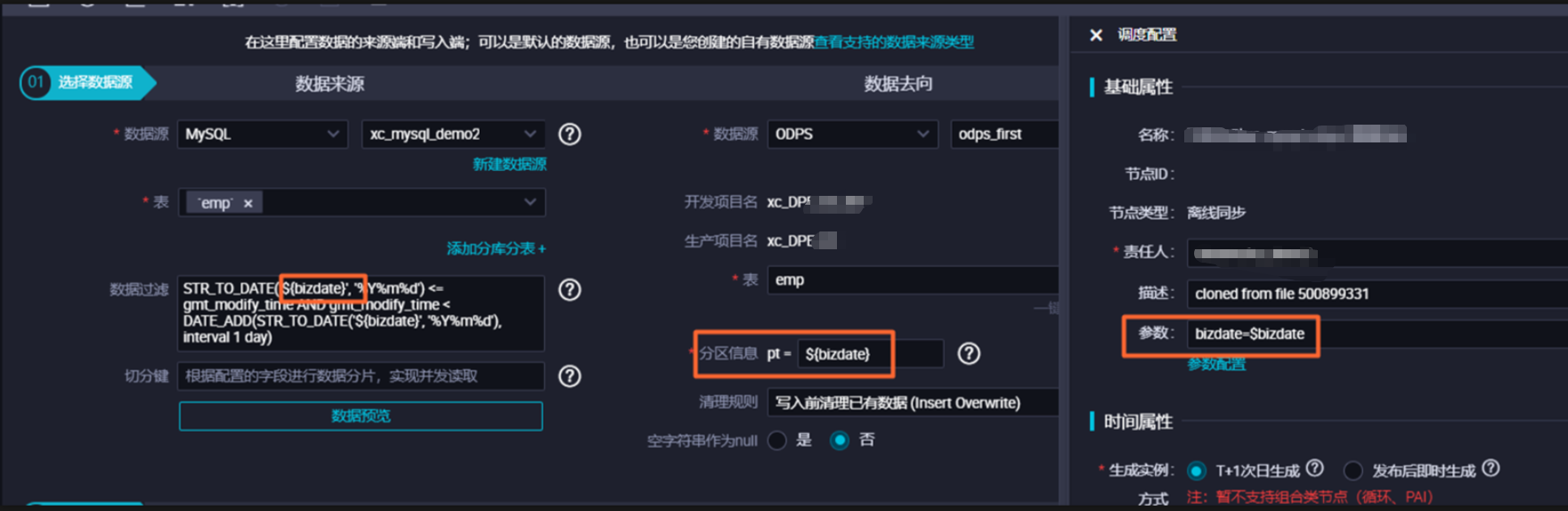
https://help.aliyun.com/zh/dataworks/user-guide/configure-a-batch-synchronization-node-to-synchronize-only-incremental-data?spm=a2c4g.11186623.0.0.1a282751FOUt4i#task-2351237
在阿里云的DataWorks平台上,通过数据过滤的方式实现增量同步是一种高效处理数据更新的方法。以下将详细解析如何在DataWorks上进行增量同步:
对恒定的存量数据进行增量同步
创建并配置源头数据表:先在RDS数据库中创建源头数据表,例如oplog表,并插入一些初始数据作为历史数据。
创建目标表并进行数据同步:在MaxCompute中创建对应的目标表,如ods_oplog,并按照天进行数据分区。使用DataWorks的数据同步工具配置同步任务,将历史数据同步至前一天的分区中。
插入增量数据并配置同步:向RDS源头表插入新的数据作为增量数据,并在数据来源中设置数据过滤条件,确保仅同步当日新增的数据。设置数据去向的分区信息,保证同步的数据被放置在正确的时间分区内。
对持续更新的数据进行增量同步
全量与增量数据同步策略选择:对于会发生变化的数据,如人员表、订单表等,通常建议每天进行全量同步以保存完整的数据快照。但在特殊情况下,如果需要只同步当日的增量数据,也可以通过相应的策略实现。
利用全增量同步任务简化流程:对于不支持Update语句修改数据的情况,可以使用全增量同步任务来简化操作。这种方法可以自动合并全量与增量数据,并写入新的全量表分区。
配置增量数据离线同步任务
使用调度参数动态替换:在同步任务中结合调度参数,如业务日期,来实现过滤条件的动态变化,从而只同步满足当前时间条件的增量数据。
配置数据过滤条件:在Reader插件中设置合适的过滤条件,以确保只有增量数据被同步。例如,MySQL Reader需要配置where条件,而MongoDB Reader则配置query条件。
优化和运维同步任务
监控和维护:确保同步任务的正确性和效率,可以通过实时同步报警和Merge节点监控报警配置来进行维护。
补数据功能:如果需要将历史增量数据同步至目标表对应时间分区,可以使用运维中心的补数据功能来实现。
此外,在进行增量同步时,还需要注意以下几点:
注意数据过滤条件的准确设置:正确配置过滤条件是同步正确数据的关键。
考虑数据源的特性和限制:了解不同数据源是否支持增量同步以及它们的特定配置要求。
定时和调度的合理规划:合理设置任务的调度周期,以保证按时进行数据同步。
资源组和网络连通性的确认:确保数据集成资源组与您将同步的数据来源端与目标端网络环境已经连通。
脏数据处理:在同步过程中决定如何处理可能产生的脏数据,保证数据的一致性和完整性。
总的来说,在DataWorks中通过数据过滤方式做增量同步,关键在于精确地识别和提取自上次同步以来发生变化的数据。这涉及到合理的数据过滤条件设定、调度参数的使用以及对不同数据源插件的配置了解。同时,不断监控和优化同步任务,以确保数据的准确性和同步过程的高效性。
在DataWorks中,通过数据过滤的方式来实现增量同步是一种常见且有效的方法。以下是如何在DataWorks中通过数据过滤来实现增量同步的详细步骤和注意事项:
一、理解增量同步的基本概念
增量同步是指只同步自上次同步以来发生变化的数据,而不是整个数据集。这通常通过比较数据中的时间戳或版本号等字段来实现。
二、配置数据源和同步任务
配置数据源:
在DataWorks中配置好源数据库和目标数据库(如MySQL、MaxCompute等)的连接信息。
确保数据源中的表包含可用于增量同步的时间戳或版本号字段。
创建同步任务:
在DataWorks的数据集成或数据开发界面中,创建一个新的同步任务。
选择适当的同步方式(如离线同步、实时同步等)。
三、设置数据过滤条件
确定过滤字段:
确定用于增量同步的过滤字段,通常是数据表中的时间戳或版本号字段。
配置过滤条件:
在同步任务的配置页面中,找到数据过滤或字段映射部分。
添加过滤条件,指定只同步时间戳或版本号大于上一次同步时间的数据。
过滤条件的具体语法取决于数据源的类型和SQL方言(如MySQL、Hive等)。
四、配置调度参数
设置调度周期:
根据业务需求设置同步任务的调度周期(如每天、每小时等)。
确保调度周期与增量同步的过滤条件相匹配,以避免遗漏数据。
配置调度参数:
在调度配置中,设置与过滤条件相关的参数(如业务日期bizdate)。
这些参数将在每次任务执行时动态替换到过滤条件中。
五、测试和验证
测试同步任务:
在正式部署之前,先对同步任务进行测试,确保它能够正确地过滤并同步增量数据。
检查同步日志和执行结果,确认没有遗漏或错误的数据。
验证数据一致性:
对比源数据库和目标数据库中的数据,确保增量同步后的数据一致性和完整性。
六、注意事项
确保时间戳的准确性:
增量同步依赖于时间戳或版本号的准确性,因此需要确保数据源中的时间戳字段是正确且及时的。
处理数据延迟:
在某些情况下,数据源中的数据可能存在延迟。需要根据实际情况调整过滤条件和调度参数,以确保不会遗漏数据。
监控和报警:
设置监控和报警机制,以便在同步任务失败或数据异常时及时得到通知并处理。
文档和记录:
记录同步任务的配置和过滤条件,以便后续维护和优化。
通过以上步骤,你可以在DataWorks中通过数据过滤的方式实现增量同步,从而高效地管理和同步数据。
是的,根据您提供的截图和描述,看起来在DataWorks中创建的新任务似乎只能获取到增量数据。具体来说,在您的例子中,分区值(ds)被设置为当前日期(20240711),这表明它正在基于时间戳进行增量更新。如果您希望获取全部数据或者特定时间段的数据,可能需要调整任务配置或者添加额外的步骤来处理历史数据。通常,这种增量加载设计用于实时或准实时地捕获新数据的变化,而不是一次性加载所有数据。
在阿里云 DataWorks 中,实现增量数据处理通常有两种主要方式:通过数据过滤的方式和通过变更数据捕获(CDC, Change Data Capture)的方式。您提到的数据过滤方式是一种常用的方法,主要用于增量同步或增量加载场景。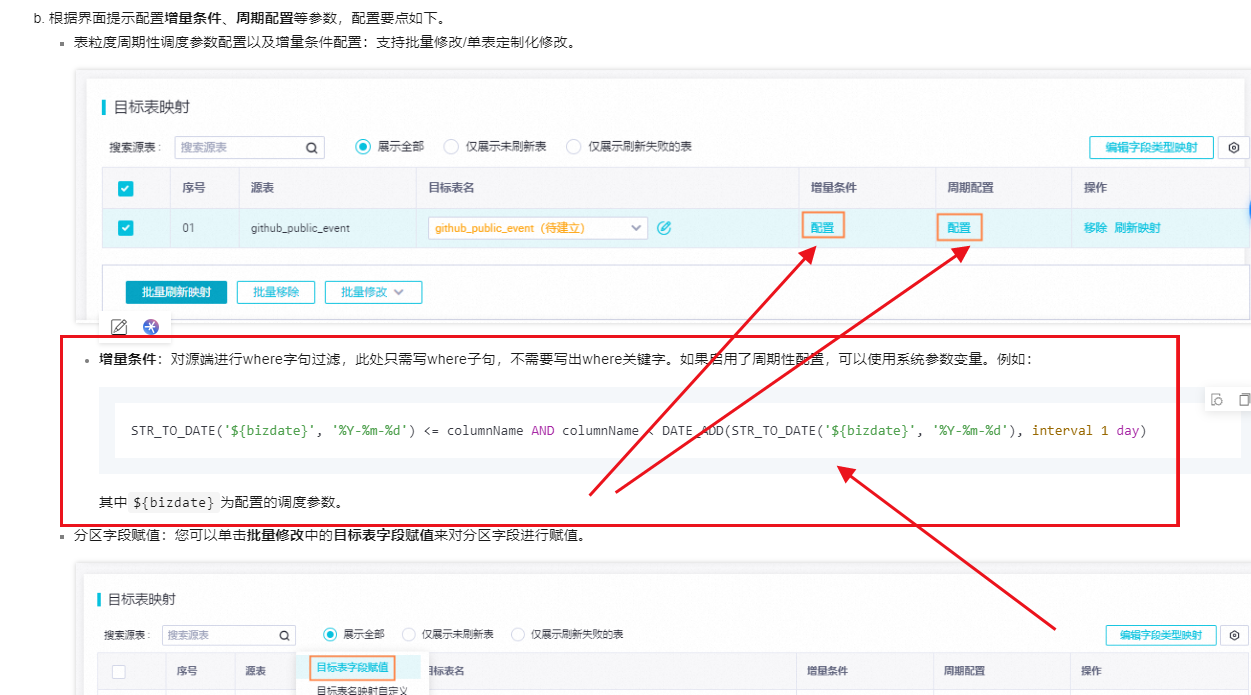
数据过滤通常是基于某种标识字段(如时间戳、序列号等)来确定哪些数据是新增或更新的。这种方法适用于大多数场景,尤其是在数据源不支持 CDC 的情况下。
确定增量标识字段:
last_modified_time 或 sequence_number。获取最新标识值:
过滤数据:
last_modified_time 作为增量标识,SQL 语句可能如下所示:SELECT *
FROM source_table
WHERE last_modified_time > '2023-01-01 00:00:00';
处理数据:
加载数据:
假设您有一个名为 orders 的源表,其中包含一个名为 last_modified_time 的字段,用来标记每条记录最后修改的时间。您想要将最近一天内修改过的订单数据加载到另一个名为 orders_incremental 的表中。以下是一个简单的示例:
获取最新的 last_modified_time:
orders_incremental 表中获取最新的 last_modified_time。过滤数据:
INSERT INTO orders_incremental
SELECT *
FROM orders
WHERE last_modified_time > (SELECT MAX(last_modified_time) FROM orders_incremental);
性能考量:
数据完整性:
错误处理:
通过数据过滤的方式实现增量处理是一种简单且广泛适用的方法。这种方法不需要额外的硬件或软件支持,只需基于现有数据源即可实现。如果您需要更具体的帮助或遇到特定的问题,请提供更多信息,我会尽力帮助您解决问题。
在DataWorks中,若需通过数据过滤方式实现增量数据同步,您可以按照以下步骤操作:
配置数据集成任务:
添加数据过滤组件:
update_time同步过去一天的数据,过滤条件可设为update_time > ${bdp.system.bizdate},这里${bdp.system.bizdate}是DataWorks提供的调度参数,代表业务日期<配置数据来源与去向:
调度参数应用:
${bdp.system.bizdate})赋予具体的值或表达式,以实现按计划自动同步增量数据测试与运行:
通过上述步骤,您可以有效地利用DataWorks的数据过滤功能实现从MaxCompute到Hologres的增量数据同步。
在DataWorks中,实现增量同步可以通过配置数据过滤的方式进行。以下是详细的步骤和注意事项:
配置同步任务:
首先,新建或配置您的数据集成任务,确保选择了正确的数据源和目标数据存储。
对于离线同步任务,在任务配置的“数据来源与去向”步骤中,利用数据过滤功能来指定增量数据的筛选条件。
设置数据过滤条件:
在数据过滤配置界面,根据您的业务需求定义过滤规则。例如,您可以基于时间戳字段设置过滤条件,仅同步指定时间范围内的数据。
支持多种条件运算类型,如等于、大于、小于等,以及文本类型的包含、开头为、结尾为等,帮助精准定位增量数据。
使用调度参数:
利用调度参数(如$bizdate)动态指定过滤条件中的时间或其他变量,使得每次任务调度时自动适配最新的增量范围。
调度参数可以在任务的调度属性中设定,支持根据定时任务的执行时间动态调整,实现自动化增量同步。
试试这个步骤呢:
确定增量字段--》需要确定表中用于标识数据变化的时间戳字段或其他逻辑字段,例如gmt_modify或自增ID。
配置数据过滤条件-》》在数据集成同步任务中,通过设置数据过滤条件来实现增量同步。例如,对于MySQL数据库,可以使用STR_TO_DATE('${bizdate}', '%Y%m%d') <= 增量时间列 AND 增量时间列 < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y%m%d'), interval 1 day)作为过滤条件,这样就可以同步指定时间范围内的数据。
调度参数配置:调度参数对于增量同步至关重要,需要确保调度周期与数据过滤条件相匹配。例如,如果数据过滤是基于天的增量,那么调度周期也应设置为按天调度。
处理逻辑删除:对于逻辑删除的数据,可以在目标表中添加一个额外的字段(如_data_integrationdeleted),并在同步时将删除操作转换为更新操作,设置该字段的值为true。
还需要你需要考虑数据源特性:不同的数据源可能需要不同的增量同步策略。例如,对于恒定的存量数据,可以基于数据生成规律进行分区,如每天一个分区
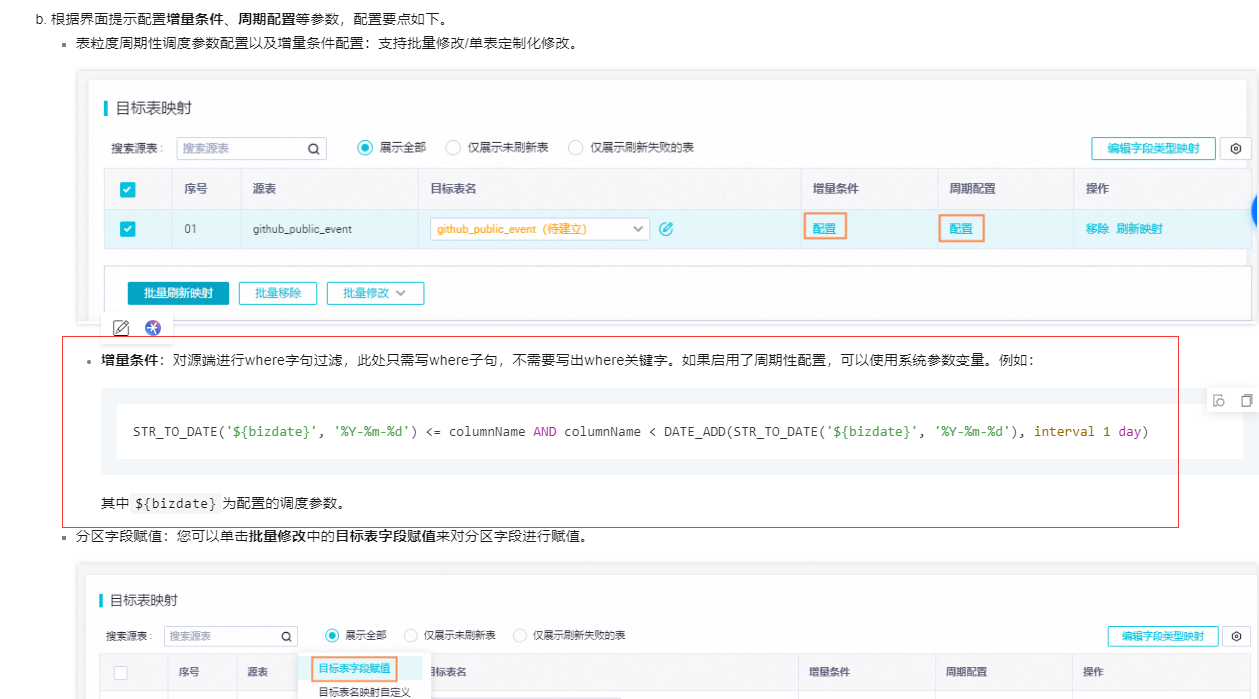
增量条件:对源端进行where字句过滤,此处只需写where子句,不需要写出where关键字。如果启用了周期性配置,可以使用系统参数变量。例如:
STR_TO_DATE('${bizdate}', '%Y-%m-%d') <= columnName AND columnName < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y-%m-%d'), interval 1 day)
其中${bizdate}为配置的调度参数。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。