DataWorks如何根据 logview 优化sql 呀,有些慢 sql跑了 1-2 个小时 ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
分析SQL:
分析SQL语句,查看是否有以下问题:
全表扫描:如果查询涉及全表扫描,可能会非常慢。尝试添加适当的索引。
无效的JOIN:检查JOIN操作是否必要,或者JOIN的列是否可以优化。
过度的数据过滤:过多的WHERE子句条件可能会导致大量数据被排除,试着简化条件或创建索引来加速筛选。
数据复制:如果查询涉及到多次复制数据,可能需要优化数据模型或查询设计。
使用EXPLAIN PLAN:
在DataWorks中,你可能无法直接查看EXPLAIN PLAN,但可以通过运行类似EXPLAIN SELECT * FROM your_table的SQL来获取执行计划。这可以帮助你了解查询如何执行和优化。
针对DataWorks中通过Logview优化慢SQL的问题,您可以遵循以下步骤进行分析与优化: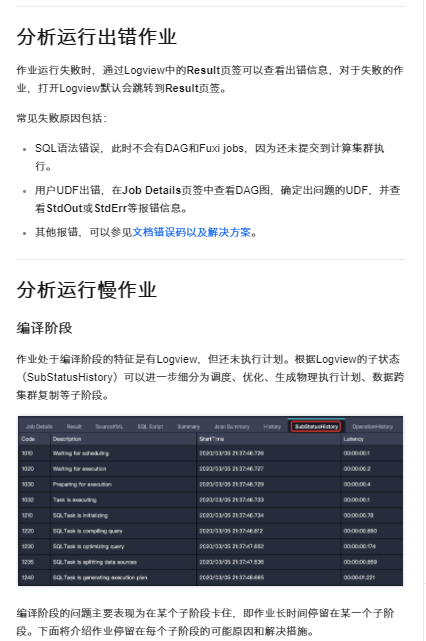

DISTRIBUTE BY或PARTITION BY优化数据划分。相关链接
Logview诊断实践 分析运行慢作业 https://help.aliyun.com/zh/maxcompute/use-cases/diagnostic-cases-of-logview
作业运行常见问题 作业运行时长不达预期(作业运行慢),通常由什么原因导致,如何解决? https://help.aliyun.com/zh/maxcompute/user-guide/job-run-faq
分析日志信息:
观察日志中是否有警告或错误信息,这些信息可能提示了性能瓶颈或配置问题。
识别瓶颈:
确定是CPU、内存还是I/O成为瓶颈。根据资源使用情况调整查询逻辑或增加资源。
优化数据过滤:
确保WHERE子句有效,减少需要处理的数据量。
索引使用:
如果可能,使用索引来加速查询。检查是否所有需要的列都已建立索引。
减少数据转换:
避免在SELECT语句中进行复杂的数据转换,这些操作可能会消耗大量资源。
在DataWorks中,当遇到SQL执行缓慢,特别是运行时间长达1-2个小时的情况时,可以利用LogView进行性能分析和优化。LogView是DataWorks提供的一个强大的日志查看和性能分析工具,可以帮助开发者快速定位和解决SQL执行缓慢的问题。以下是根据LogView优化SQL的一般步骤和策略:
一、查看执行日志和性能指标
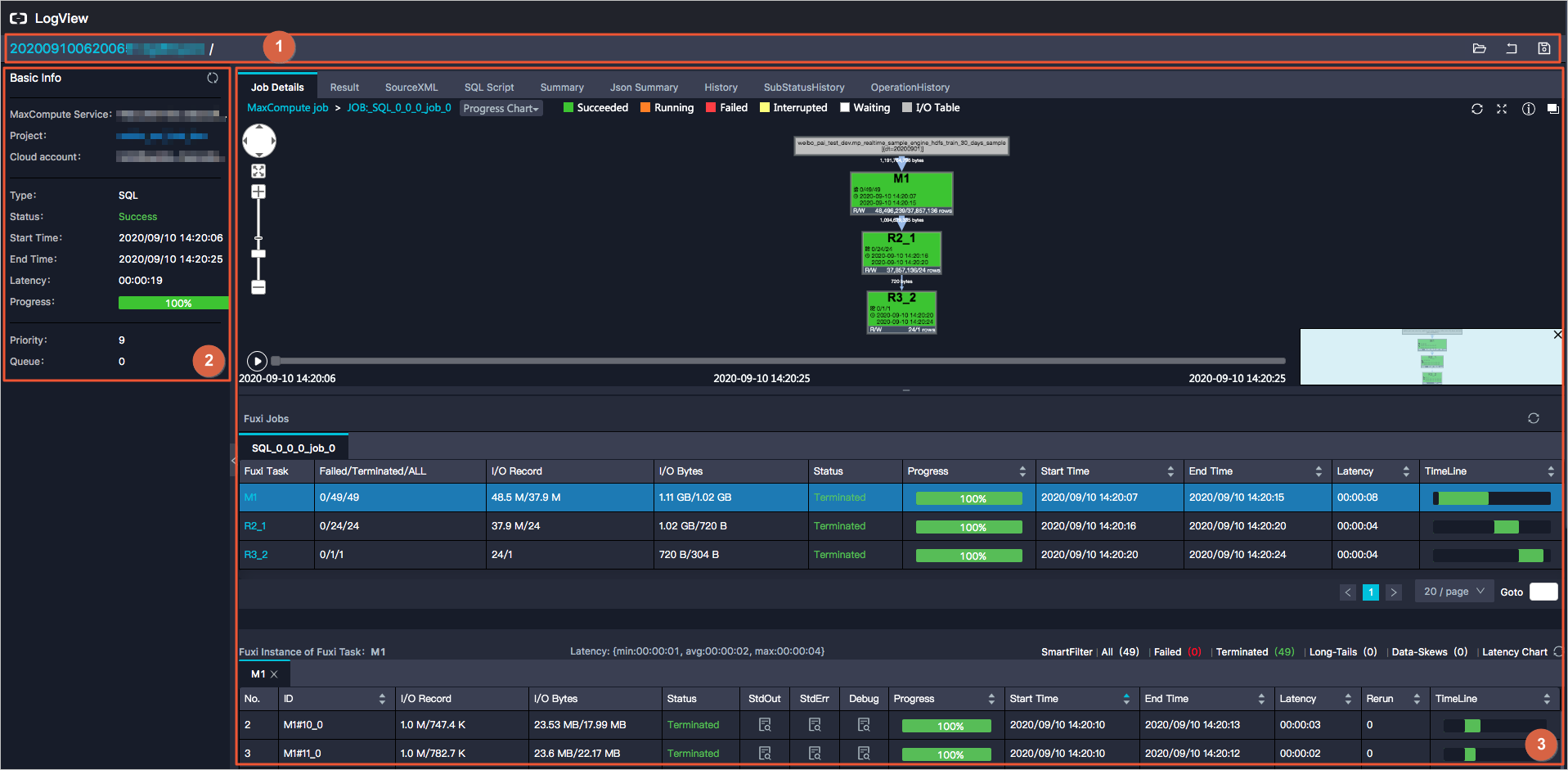
打开LogView:在DataWorks的运维中心找到对应的SQL任务,右击选择“查看运行日志”,进入LogView界面。
分析执行日志:
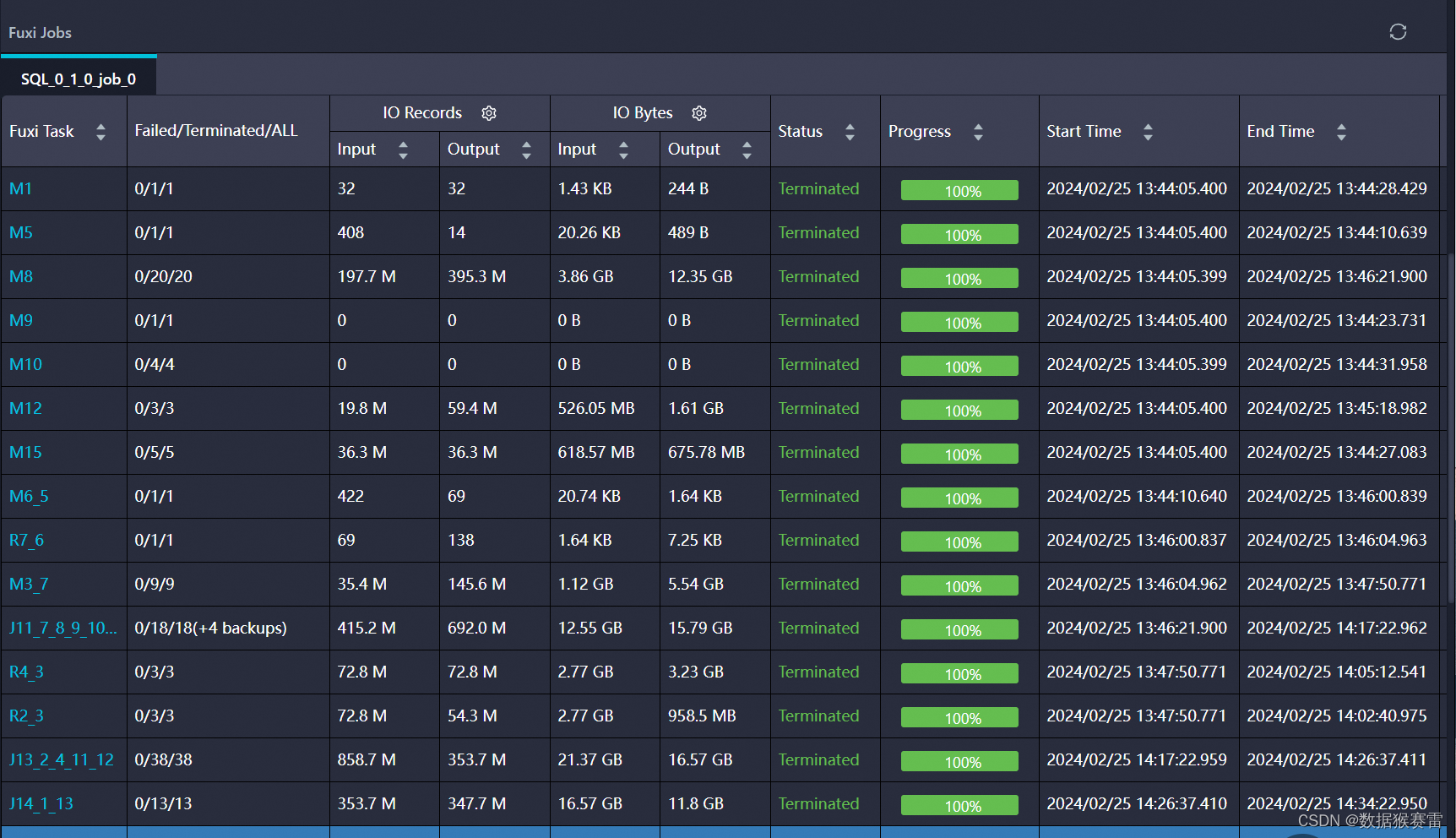
查看SQL的执行时间、输入输出数据量(IO Records、IO Bytes)、节点运行时长(Latency)等关键指标。
特别注意执行时间较长的节点,如Map、Reduce、Join等。
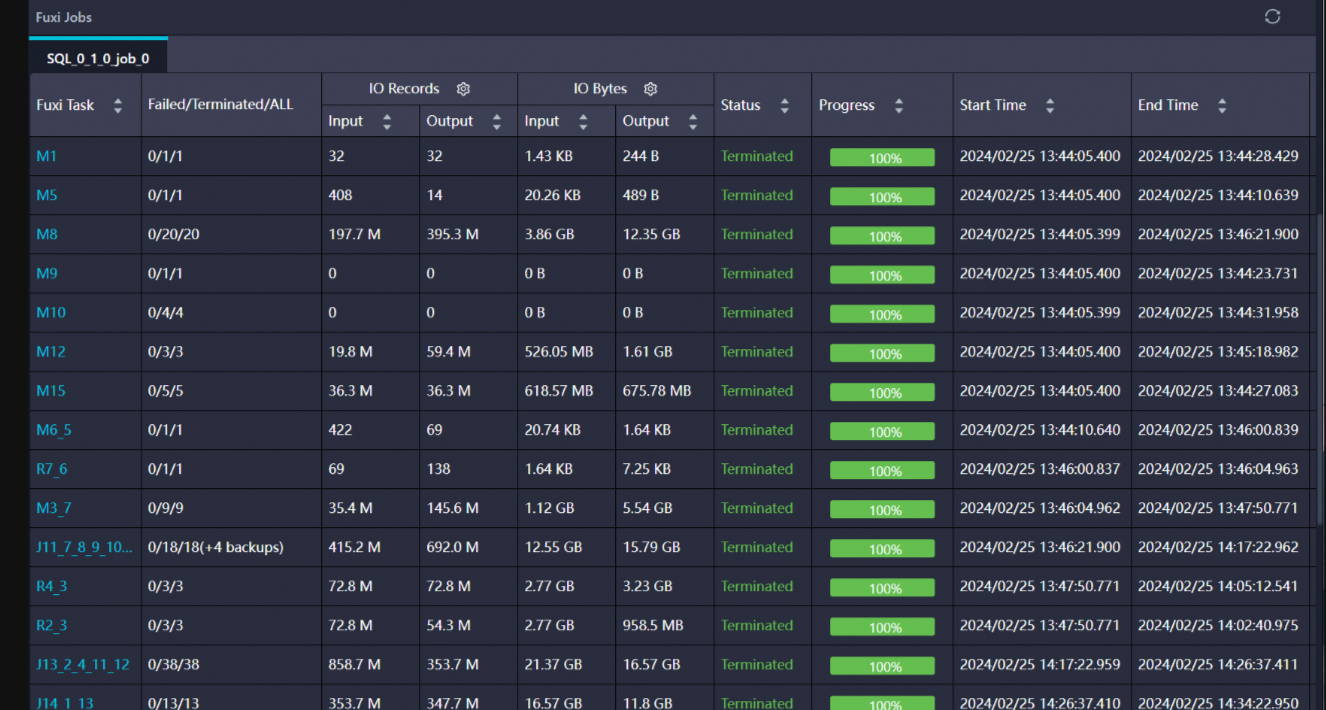
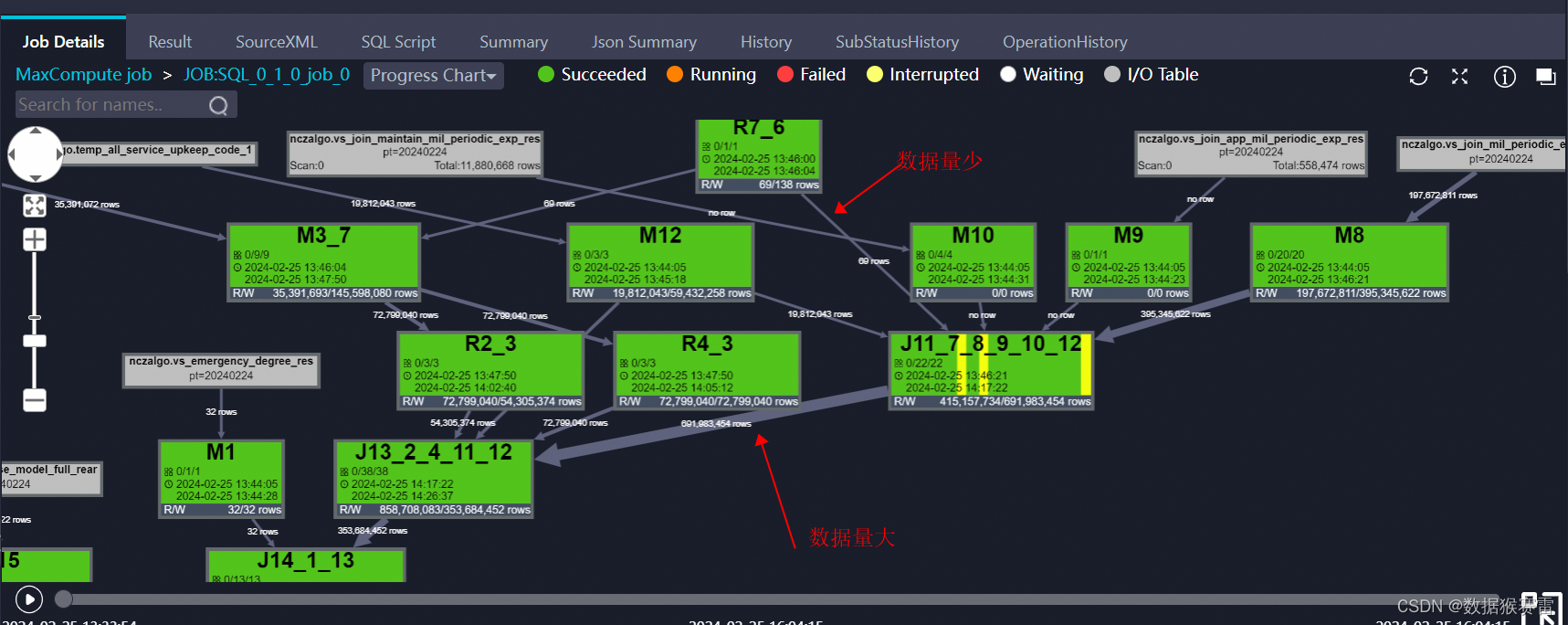
观察DAG图:DAG图展示了SQL任务被切分后的执行流程,通过它可以直观地看到哪些节点数据量较大,哪些节点运行时间较长。
二、定位问题原因
资源瓶颈:
检查是否有资源争用的情况,如CPU、内存、网络带宽等。
如果发现资源使用率接近或超过配额,可能需要调整资源分配或优化查询逻辑以减少资源消耗。
数据倾斜:
某些节点处理的数据量远大于其他节点,导致执行时间显著延长。
通过LogView查看各个节点的数据分布情况,定位数据倾斜的具体位置和原因。
执行计划复杂:
复杂的SQL查询可能涉及多个表的连接、复杂的聚合和排序操作,导致执行计划复杂且耗时。
通过LogView的执行计划部分查看具体的执行步骤和子任务,分析是否有优化空间。
三、优化策略
优化SQL查询:
简化查询逻辑,减少不必要的表连接和子查询。
使用合适的索引来加速数据检索。
尽量避免在查询中使用大量的函数和复杂的计算逻辑。
调整资源分配:
如果使用的是公共资源池,可以考虑切换到独享资源池以获取更好的性能。
根据执行日志中的资源使用情况调整Map、Reduce、Join等实例的数量,以充分利用集群资源。
处理数据倾斜:
对数据进行预处理,如重新分区、排序等,以减少数据倾斜的影响。
在SQL查询中增加适当的过滤条件来减少处理的数据量。
利用并行处理:
充分利用DataWorks的并行处理能力,将大任务拆分成多个小任务并行执行。
注意控制并行度,避免过度并行导致资源争用和性能下降。
监控和调优:
持续关注SQL查询的性能表现,定期进行性能调优。
利用DataWorks提供的监控工具实时监控集群状态和SQL执行情况,及时发现并解决问题。
通过以上步骤和策略,可以基于LogView对DataWorks中的慢SQL进行有效的性能优化,提高查询效率和系统稳定性。
在DataWorks中,针对运行时间长达1-2个小时的慢SQL,可以通过LogView等工具进行性能分析和优化。以下是一些具体的优化步骤和策略:
一、使用LogView进行性能分析
查看执行日志:
在DataWorks的运维中心,找到对应的周期实例,右击选择“查看运行日志”。
LogView会显示SQL任务切分为MapReduce任务后的DAG图,包括Map、Reduce、Join等节点的详细信息。
分析关键节点:
重点关注DAG图中链路较粗的节点,这些节点通常表示数据量较大或处理时间较长。
查看节点的IO Records(数据条数)、IO Bytes(数据大小)和Latency(运行时长)等指标,以识别性能瓶颈。
检查资源使用情况:
查看节点的start_time和end_time,如果差异很大,可能说明计算资源紧缺,导致任务被抢占。
二、SQL优化策略
优化SQL查询语句:
尽量避免全表扫描和笛卡尔积等操作,通过添加合适的索引和分区来提高查询效率。
减少查询的数据量,通过筛选条件、分组聚合等方式来减少需要处理的数据。
尽量避免使用子查询、联合查询等复杂的查询方式,尽量使用简单的查询语句。
调整资源配置:
如果SQL节点的运行时间较长,可以考虑增加节点的计算资源,如增加实例个数或CPU核数。
根据集群资源和数据规模,合理设置SQL节点的并行度参数,如map任务数、reduce任务数等。
处理数据倾斜:
如果查询的数据存在倾斜,即某些数据量特别大或特别小,会导致任务运行时间不均衡。
可以采用数据分片、数据重分布等方式来解决数据倾斜问题,提高任务执行效率。
优化数据存储和压缩:
选择合适的数据存储格式和压缩方式,如ORC、Parquet等列式存储格式和Snappy、LZO等压缩技术,以减少数据的存储空间和提高查询性能。
使用缓存和物化视图:
对于频繁访问的数据,可以考虑使用缓存或物化视图来减少数据读写的次数和数据计算的复杂度。
三、其他优化措施
调整作业调度策略:
根据任务执行的情况,调整作业的调度周期和执行顺序,以优化资源利用和任务执行效率。
数据预处理和合并:
对于输出结果较大的任务,可以在数据生成过程中进行合并和汇总操作,以减少数据量和读取操作。
增量同步:
如果任务是用于数据同步,考虑使用增量同步而不是全量同步,以减少每次处理的数据量。
定期维护和优化:
定期对DataWorks集群和SQL任务进行维护和优化,包括清理无用数据、更新索引、调整资源配置等。
通过以上步骤和策略,可以有效地根据LogView对DataWorks中的慢SQL进行优化,提高SQL的执行效率和任务的完成速度。
优化DataWorks中的SQL性能可以借助Copilot的SQL改写功能.您需要有慢SQL的查询语句。在DataWorks的数据开发界面,选中这段SQL,右键选择Copilot > SQL Chat > SQL改写。输入指令,比如“优化这段SQL以提高执行效率”,点击发送,等待Copilot返回优化后的SQL。根据返回结果,对比改写前后的SQL,确认无误后,可以应用改写后的SQL。
在阿里云 DataWorks 中,针对慢 SQL 的优化是非常重要的,特别是当 SQL 执行时间达到 1-2 个小时时,这可能严重影响数据处理的效率和准确性。MaxCompute 提供了 LogView 工具来帮助您分析 SQL 的执行计划和性能瓶颈。下面是一些基于 LogView 的 SQL 优化技巧: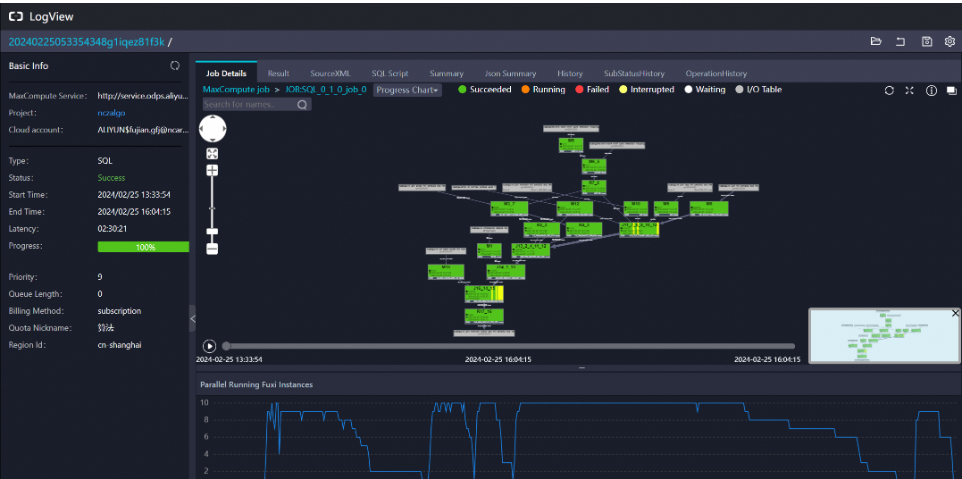
打开 LogView:
分析执行计划:
减少数据扫描量:
优化 Join 语句:
优化 Group By 和 Aggregation:
使用物化视图或汇总表:
避免使用 Subquery:
使用分区裁剪:
检查数据分布:
处理数据倾斜:
使用 SQL 提示:
/*+ BROADCAST(t1) */ 来强制广播小表。调整资源配置:
set odps.sql.parallel=true; set odps.sql.shuffle.parallel=<num>;)。set odps.sql.memory.limit=<size>;)。持续监控:
定期调优:
假设您有一条 SQL 语句执行非常慢,您可以按照以下步骤进行分析:
运行 SQL 并查看 LogView:
分析执行计划:
优化 SQL:
测试和验证:
通过使用 LogView 分析 SQL 的执行计划和性能瓶颈,您可以找出导致 SQL 执行缓慢的原因,并据此进行优化。请根据您的具体情况应用上述技巧,并不断测试和调整,以获得最佳性能。如果您需要更具体的帮助或遇到特定的问题,请提供更多信息,我会尽力帮助您解决问题。
DataWorks通过LogView优化SQL性能时,主要可以从以下几个方面入手:
分析执行计划:利用LogView查看SQL任务切分为MapReduce任务后的DAG图,分析Map、Reduce、Join等节点的运行情况,识别出数据量大、运行时间长的节点。
资源调整:根据分析结果,调整资源配置,如增加map、reduce、join的实例数,使用独享资源而非公共资源,以减少资源竞争,提升处理速度。
SQL优化:
简化查询逻辑,避免不必要的复杂子查询和连接操作。
使用连接(JOIN)代替子查询,在适用的情况下提高效率。
优化WHERE子句,确保能够利用索引减少扫描数据量。
只选择需要的列,避免使用SELECT *语句。
索引优化:为查询中经常用于过滤和排序的列添加索引,并定期维护索引以消除碎片。
数据预处理:提前对数据进行shuffle和排序,减少计算过程中的数据重排开销。
利用缓存:对于重复执行的查询,考虑使用查询缓存来避免重复计算。
定期监控:使用性能监控工具定期检查数据库的性能指标,及时发现并解决潜在的性能问题。
通过上述步骤,可以有效地利用DataWorks的LogView功能来优化SQL性能,减少长时间运行的慢SQL。
优化方案
1、资源切换
如果之前使用的是公共资源,那么可以切换为独享资源
2、Hash clustering
将数据提前进行shuffle和排序,在使用数据的过程中,读取数据后直接参与计算。这种模式非常适合产出后 后续节点多次按照相同key进行join或聚合的场景。
当然生成hash clustering table本身也是有代价的,在生辰阶段会进行一次额外的shuffle。
执行方法示例:
alter table s_auction_auctions CLUSTERED by (acution_id) SORTED by (auction_id) into 1200 buckets;
3、设置任务执行时的map、reduce、join实例数
'odps.stage.mapper.num' : 1024
'odps.stage.joiner.num' : 2048
'odps.stage.reducer.num' : 2048
4、提早过滤不必要的数据
DAG中输入较多数据的节点(线较粗的),提早过滤没用的数据,让输入数据变少点。
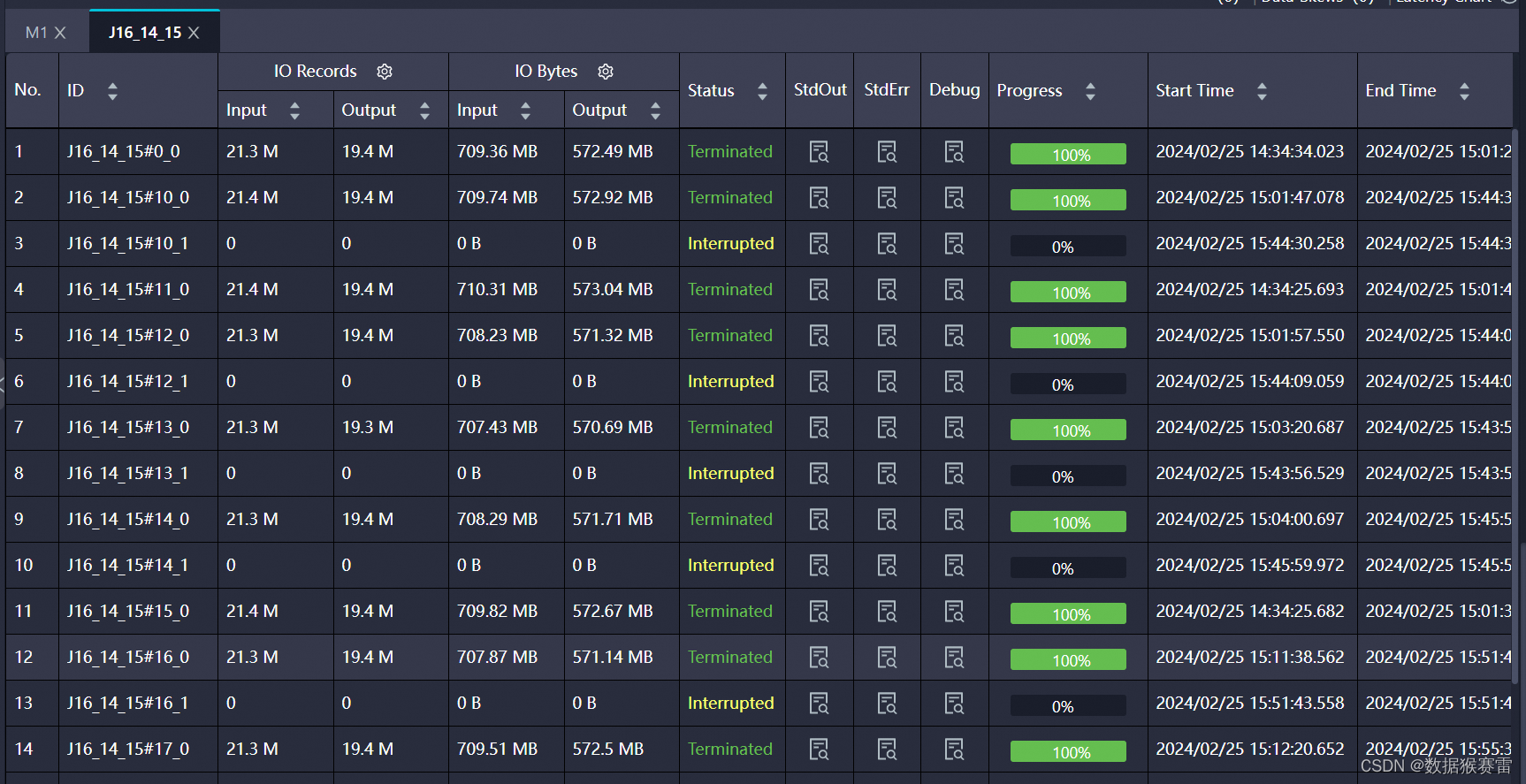
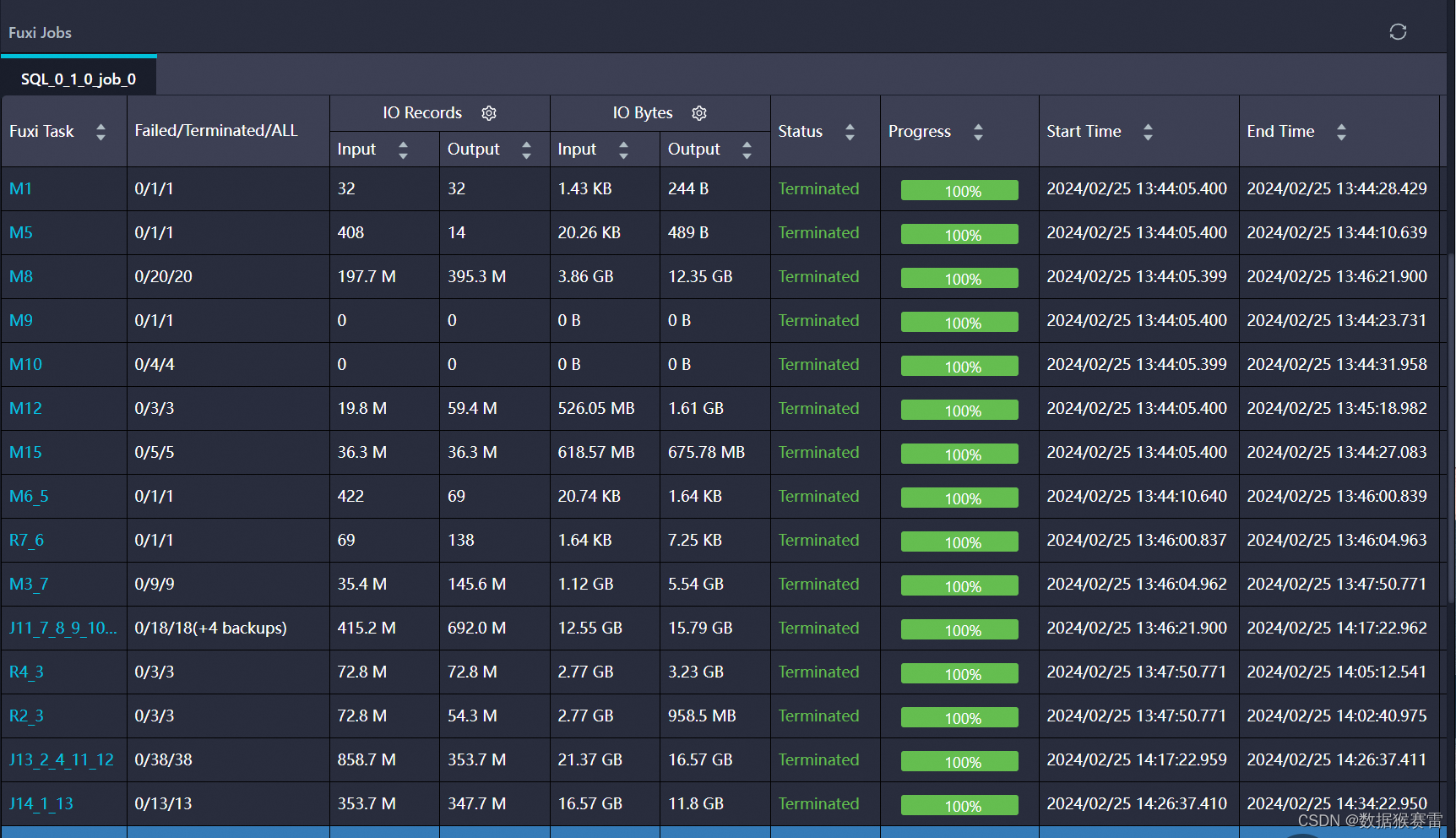
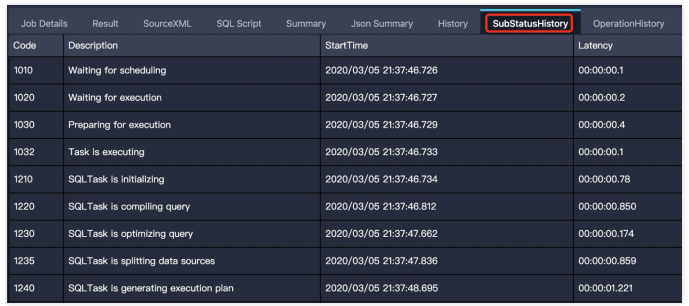
分析LogView的信息
在日志中根据instanceId搜索SQL任务的Logview如(instance20220807101058817gbb6ghx5):Logview Portal。可以打开Logview看SQL任务的执行情况,sql执行慢的可能性很多:
BASE数据量很大,启动的mapper和reducer过多,可以项目级别调整对应odps参数解决。
启动的SQL任务过多,导致提交任务时资源不足,打开Logview,可以看到sql实例处在Waiting状态,需要优化解决ODPS资源问题。如有需要可以联系ODPS值班同学支持。
如果未找到上述日志,可能存在提交ODPS SQL任务卡顿情况,可以找到最后的一个SQL Logview,查看日志或者联系ODPS值班同学支持分析Logview。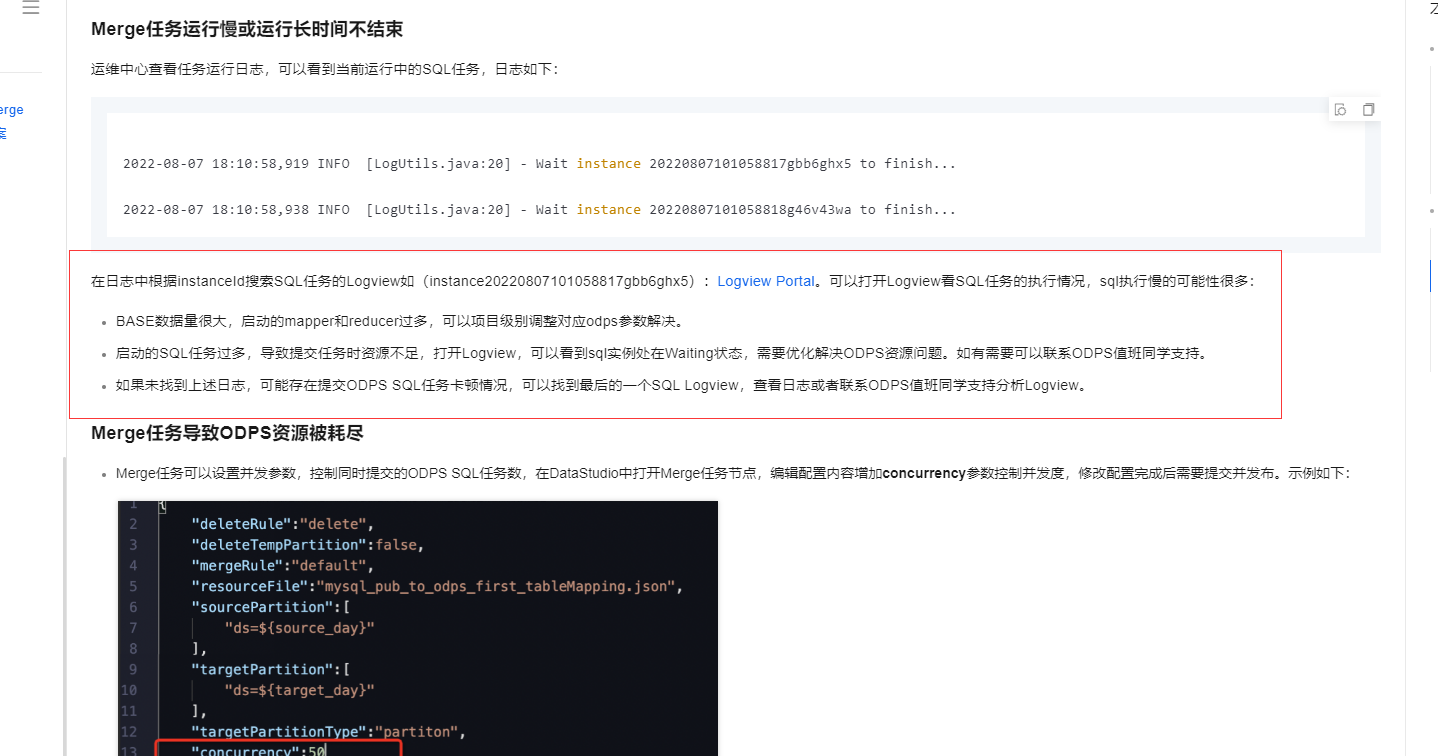
参考文档https://help.aliyun.com/zh/dataworks/user-guide/troubleshoot-issues-of-a-merge-node-generated-by-a-one-click-real-time-synchronization-to-maxcompute-solution?spm=a2c4g.11186623.0.i4
在日志中根据instanceId搜索SQL任务的Logview如(instance20220807101058817gbb6ghx5):Logview Portal。可以打开Logview看SQL任务的执行情况,sql执行慢的可能性很多:
BASE数据量很大,启动的mapper和reducer过多,可以项目级别调整对应odps参数解决。
启动的SQL任务过多,导致提交任务时资源不足,打开Logview,可以看到sql实例处在Waiting状态,需要优化解决ODPS资源问题。如有需要可以联系ODPS值班同学支持。
如果未找到上述日志,可能存在提交ODPS SQL任务卡顿情况,可以找到最后的一个SQL Logview,查看日志或者联系ODPS值班同学支持分析Logview。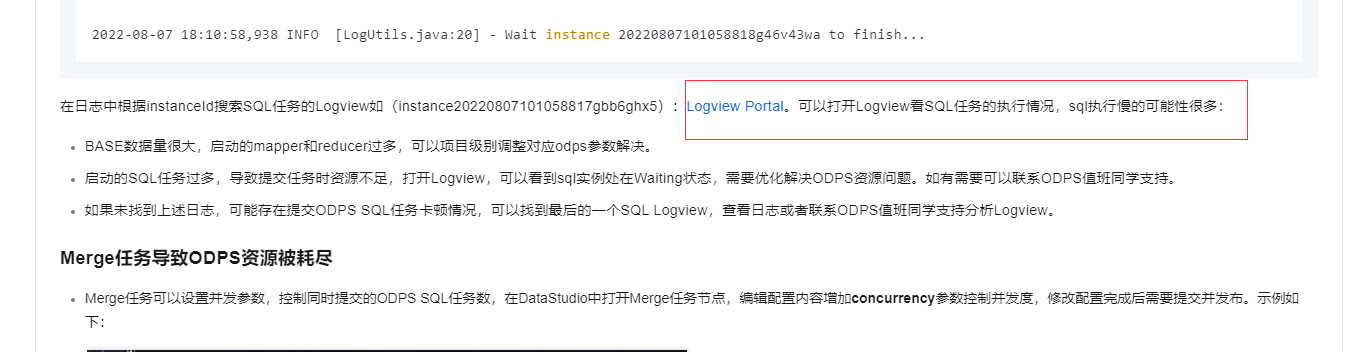
参考文档https://help.aliyun.com/zh/dataworks/user-guide/troubleshoot-issues-of-a-merge-node-generated-by-a-one-click-real-time-synchronization-to-maxcompute-solution?spm=a2c4g.11186623.0.i167
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。