
 4000积分,蓝牙自拍杆*7
4000积分,蓝牙自拍杆*7
PAI快速开始(PAI-QuickStart)集成了业界流行的预训练模型,提供一站式、零代码的模型微调训练、服务部署、模型评测功能,帮助用户快速上手使用AI能力。模型涵盖众多AI场景,包括LLM、AIGC、CV、NLP等。用户可一键部署模型,调用在线服务;也可以使用自己的数据微调训练模型,使模型更加匹配自身业务场景。现邀请您使用PAI-快速开始,低代码实现大语言模型微调和部署:https://developer.aliyun.com/adc/scenario/f2f81c8f883543528140e80f1ced3069?并分享配置过程、输出结果及使用体验。
本期话题:使用PAI-快速开始,低代码实现大语言模型微调和部署,并分享配置过程、输出结果及使用体验
话题规则:话题讨论要求围绕指定方向展开,图文并茂,字数少于50字无效,言之无物无效,无具体讨论的回复将会视为无效回复,对于无效回复工作人员有权删除。
配置过程: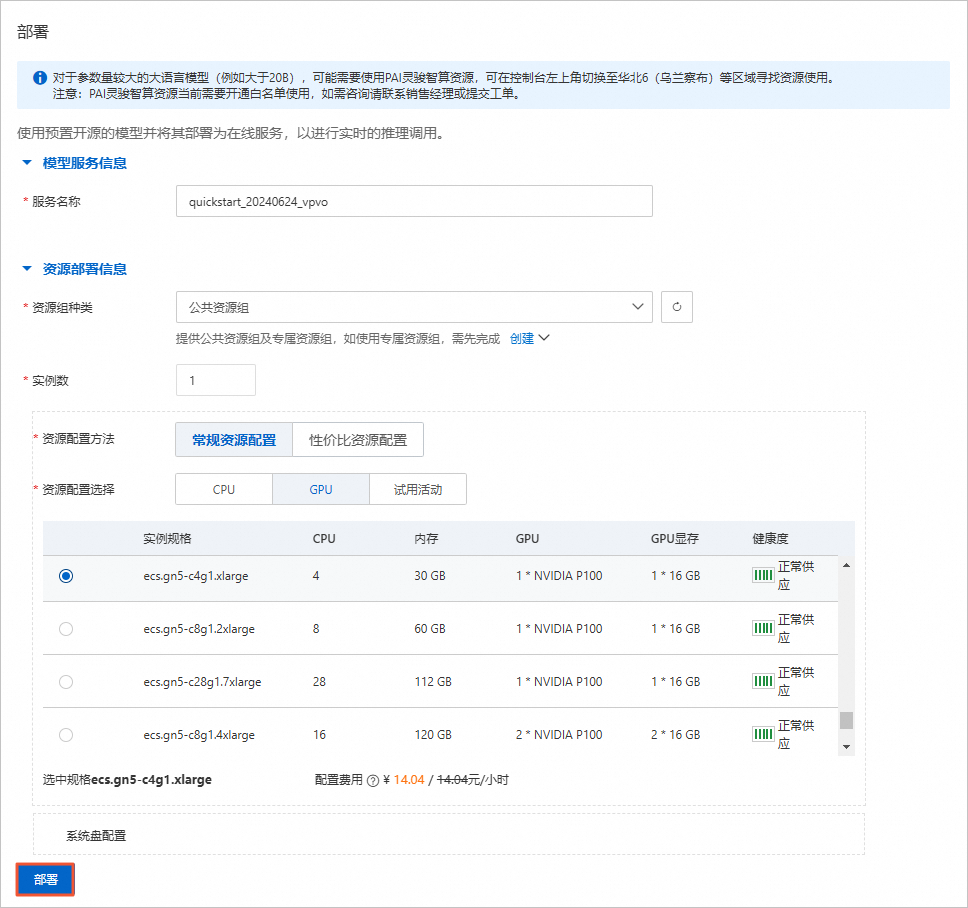
输出结果: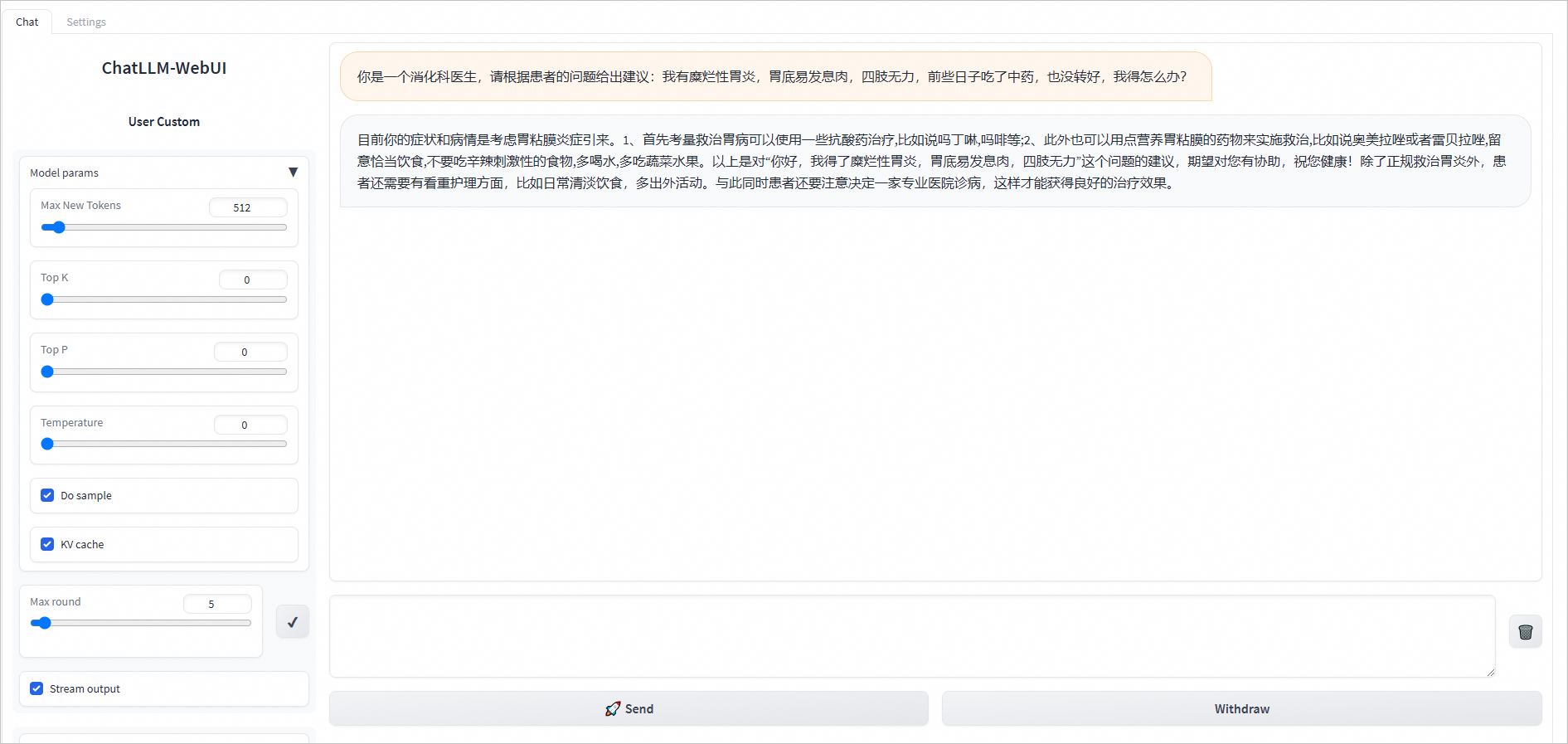
本期奖品:截止2024年8月2日24时,参与本期话题讨论,将会选出7个优质回答获得蓝牙自拍杆。快来参加讨论吧~
优质回答获奖规则:字数不少于100字,明确清晰的配置过程、详细的使用体验分享。内容阳光积极,健康向上。
未获得实物奖品者,按要求完成回复的参与者均可获得20积分奖励。
注:讨论内容要求原创,如有参考,一律注明出处,如有复制抄袭、不当言论等回答将不予发奖。阿里云开发者社区有权对回答进行删除。获奖名单将于活动结束后5个工作日内公布,奖品将于7个工作日内进行发放,节假日顺延。
中奖用户:
截止到8月2日共收到40条有效回复,获奖用户如下
优质回答:算精通、申公豹、六月的雨在钉钉、北京-宏哥、huc_逆天、DreamSpark、郑小健
恭喜以上用户!感谢大家对本话题的支持~
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
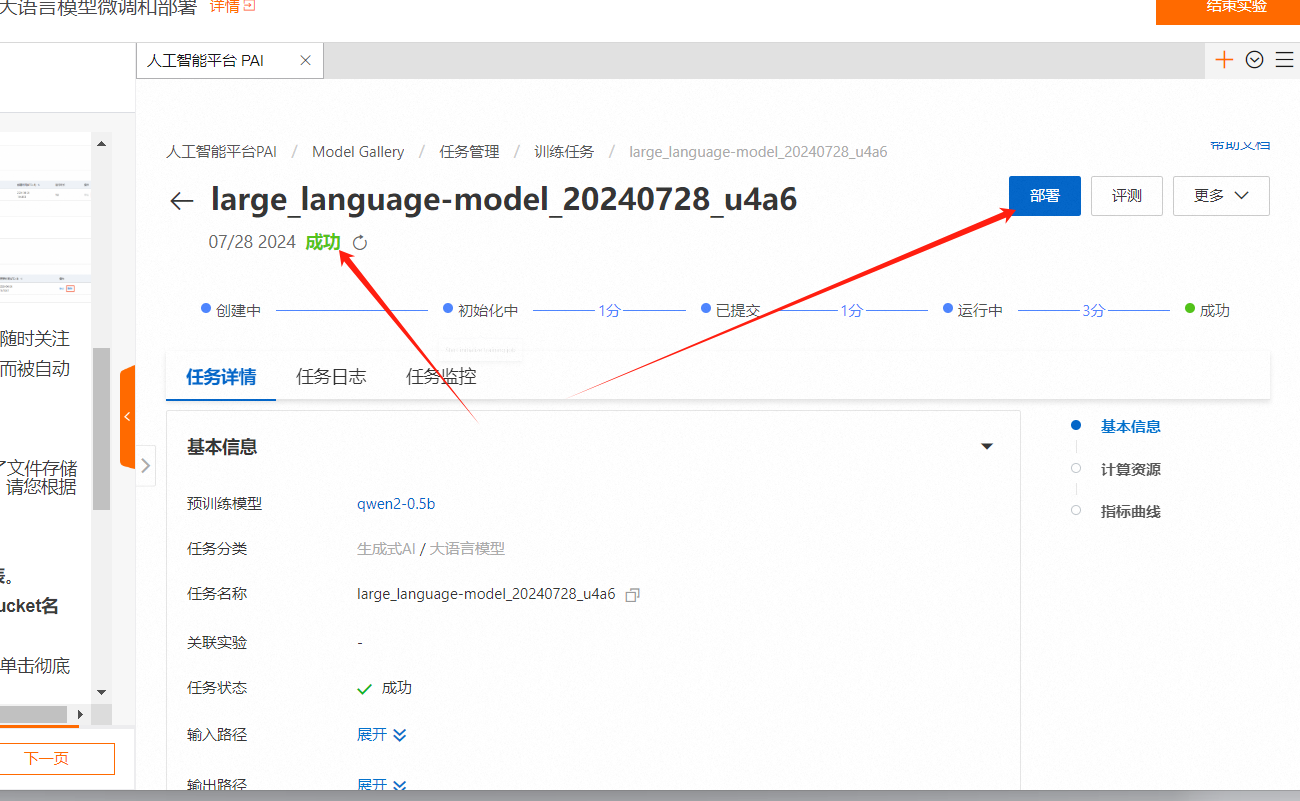
使用PAI-快速开始,低代码实现大语言模型微调和部署
配置过程:
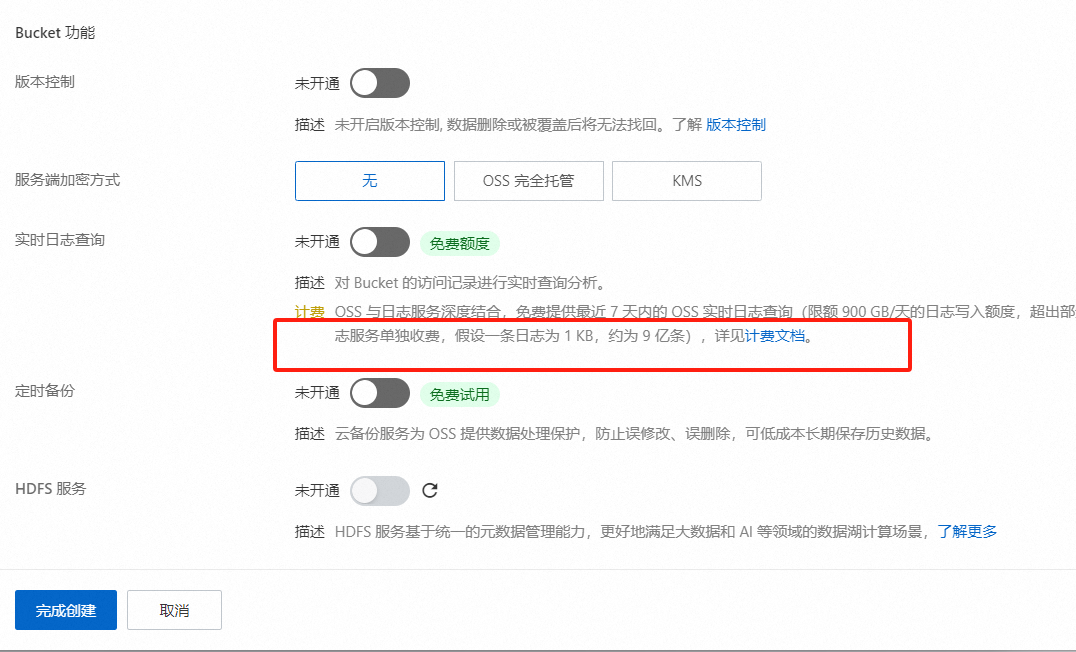
请确保已开通PAI及OSS服务,创建对应Bucket,并同意模型许可协议。
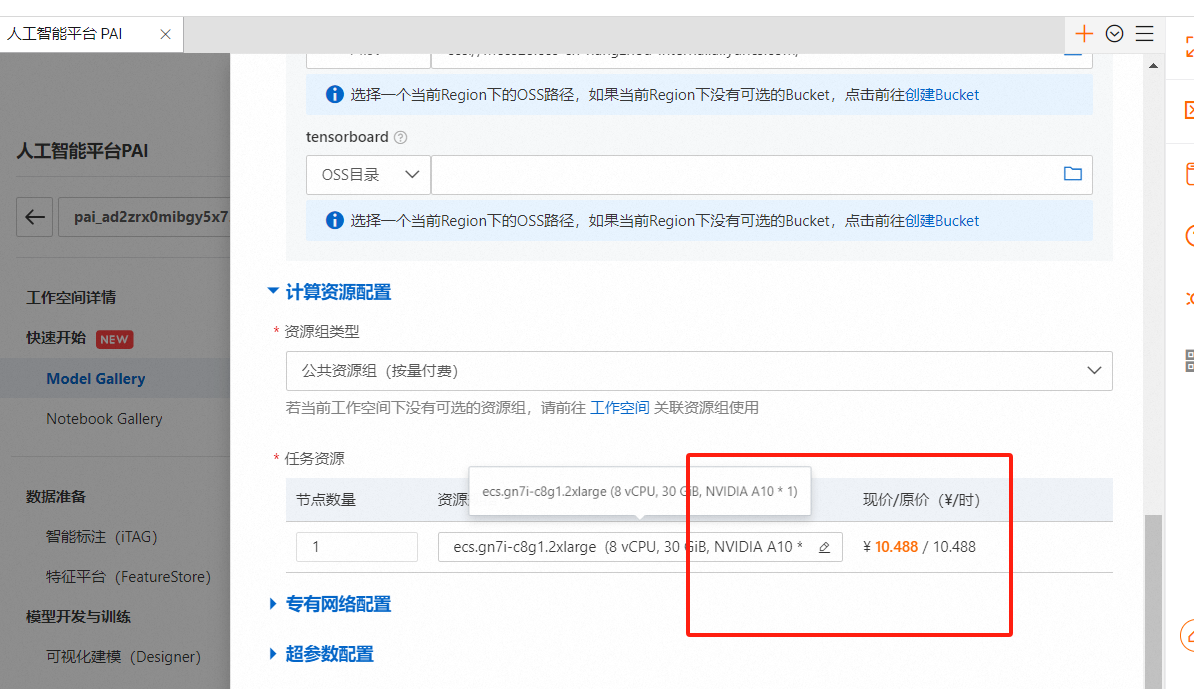
登录PAI控制台,根据需求选择合适模型(例如Qwen2-7b-Instruct),并确认资源匹配。
使用内置LoRA微调算法进行低成本训练,准备JSON格式的训练数据,上传后启动微调流程。
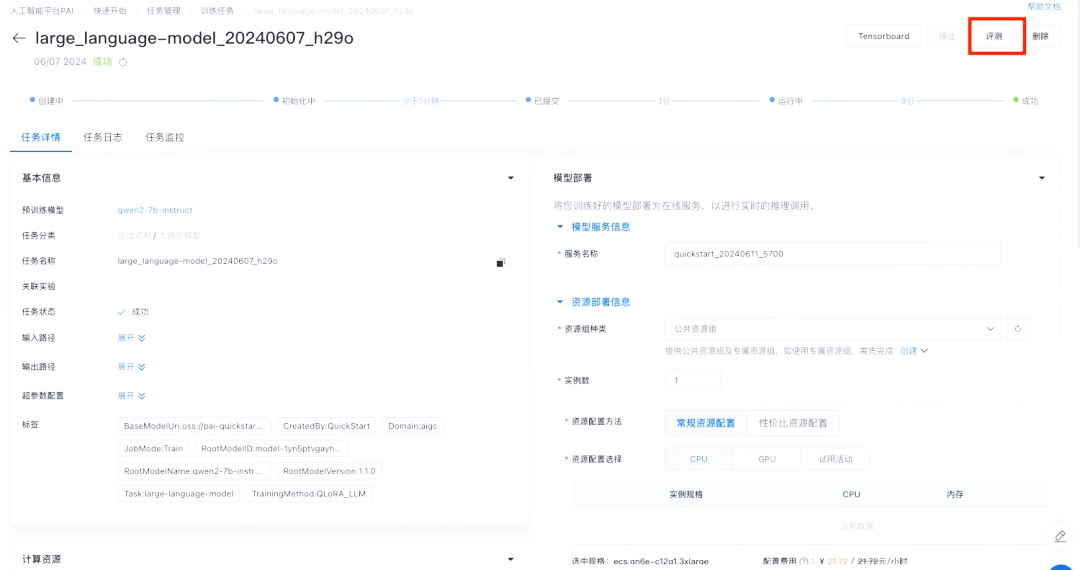
结果
该微调模型基于定制数据集进行训练,能够更精准地满足特定业务需求,有效提升处理具体任务的表现与效率。
使用体验
PAI-QuickStart极大简化了AI模型的微调与部署流程,它能够随时帮助企业解决在这一过程中遇到的问题,并实现价值创造。
使用PAI-快速开始,低代码实现大语言模型微调和部署
配置过程:
确保已激活阿里云PAI服务(含EAS、DLC)及OSS,并同意所选模型(如Llama2系列)的开源许可。
登录PAI控制台,选择工作空间快速开始。从模型库中选取目标模型,例如Qwen2-7b-Instruct,配置资源后部署至EAS,支持WebUI和API访问。
微调训练需设置数据集、输出路径与超参数,完成后即可部署优化模型。
结果
部署完毕后,用户能通过API接口获取模型的预测结果,适用于文本分类、情感分析等多种场景。
使用体验
PAI-QuickStart平台提供一个直观简便的操作界面和多样化功能,使专业人士和非开发者均能轻松使用复杂的AI功能。
该平台极大地简化了模型微调、训练和部署的流程,并内置了许多主流预训练模型以及丰富的微调选项和部署设置,以满足个性化需求并快速找到最适合的模型。
使用PAI-快速开始,低代码实现大语言模型微调和部署
配置过程:
首先在阿里云开发者平台上登录并进入PAI-QuickStart,选择大语言模型的微调与部署场景。
随后上传已按指定格式整理的数据集。
在多种预训练模型中挑选合适的大语言模型,并通过调整关键参数进行微调以更好地满足业务需求。
最后,一键部署微调后的模型为在线服务,并可通过详细的日志与监控信息实时跟踪部署进度及服务状态。
结果
微调模型根据定制数据集生成更符合业务需求,实现更精准、专业的信息交流,满足需求,大幅提升应用效果及用户体验。
使用体验
用户可根据业务需求自由选择和切换模型,调整资源。利用LoRA训练方法可大幅减少训练成本与时间,特别适合需快速迭代的场景。PAI-快速开始提供低代码界面,极大简化了模型微调和部署流程。请注意确保模型与当地区域兼容,拥有足够计算资源,并遵循相关许可协议。
使用PAI-快速开始,低代码实现大语言模型微调和部署
配置过程:
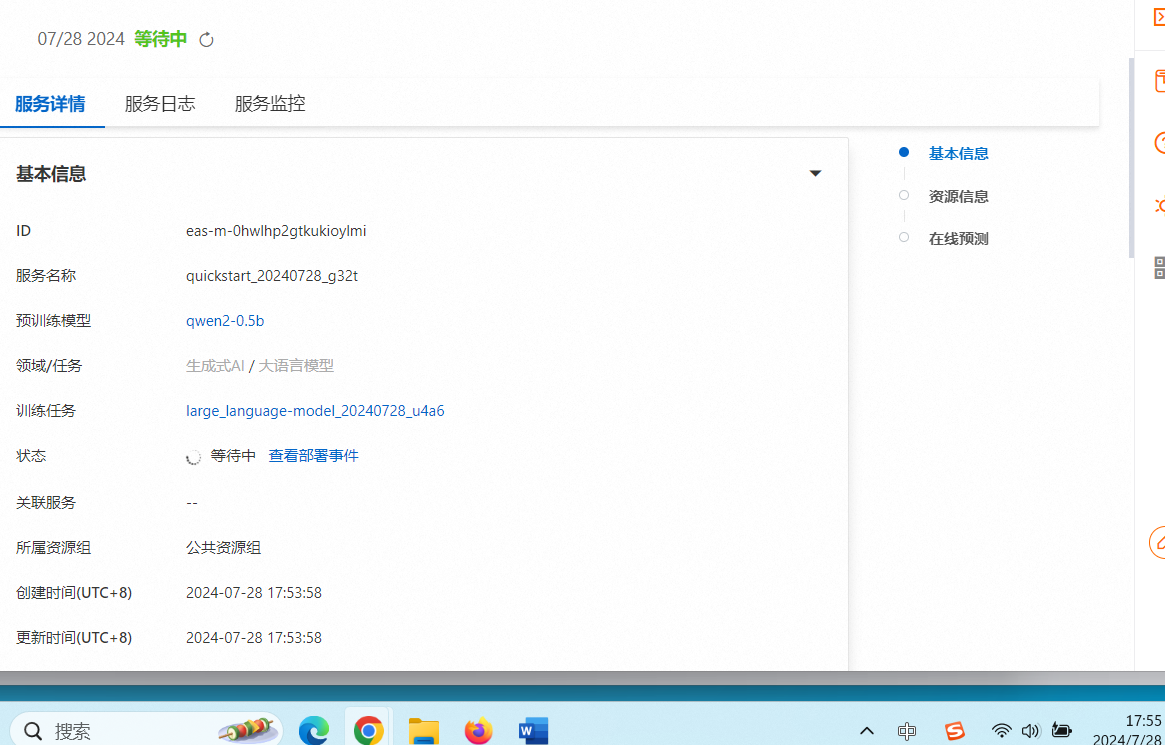
在阿里云PAI平台上,创建了高效直观的工作空间,并从Model Gallery中选择了“通义千问2-0.5B-Instruct”模型进行快速配置与部署。通过日志监控保障服务稳定运行,在微调训练阶段,需正确设置OSS路径。尽管初期遇到模型加载失败的问题,但通过检查日志并做出相应调整后,成功完成了部署。
结果
部署后,利用PAI-QuickStart提供的API接口进行在线服务的调用测试及测试数据输入。模型返回了准确、预期内的结果,表明经过精细调整的模型在真实的业务场景中表现优秀。
使用体验
PAI-QuickStart平台提供用户友好的操作界面和多种预训练模型,使模型的微调、训练和部署工作变得更加高效快捷。即使是非专业人员也能轻松实现复杂的AI功能,并根据业务需求选择合适的模型进行个性化调整。此外,平台支持一键式模型部署,可显著缩短应用周期,提高工作效率。
使用PAI-快速开始,低代码实现大语言模型微调和部署
配置过程:
在PAI工作空间中,通过Model Gallery快速启动,选择并部署“通义千问2-0.5B-Instruct”。
部署成功后会提供一个体验链接。
在模型详情页点击微调训练,上传符合要求的自定义数据集用来优化模型。
设置训练参数(如轮次、学习率等),设置完毕后系统将自动完成微调训练,在此期间可以实时监控进展。
结果
通过PAI-QuickStart对大型语言模型进行业务数据上的微调和训练,有效提升了文本处理的准确度与效率,并成功部署为在线服务。这一优化流程极大地改善了处理性能,更好地满足了业务需求。
使用体验
PAI-QuickStart平台大大简化了大型语言模型的微调和部署过程,支持低代码甚至零代码操作模式,提供直观用户界面,无论是技术背景还是非技术背景的用户都能轻松上手。
配置过程:
输出结果:
使用体验:
在实际操作中,上传数据集后,通过简单的参数设置启动训练,整个过程流畅高效。训练完成后,部署模型并进行测试,模型能够准确地回答相关问题,表现出较好的性能。
总之,PAI-QuickStart为用户提供了一种便捷、高效的方式来实现大语言模型的微调和部署,降低了AI应用的门槛,使得更多用户能够受益于AI技术。
每次都需要开资源体验
10-20一小时
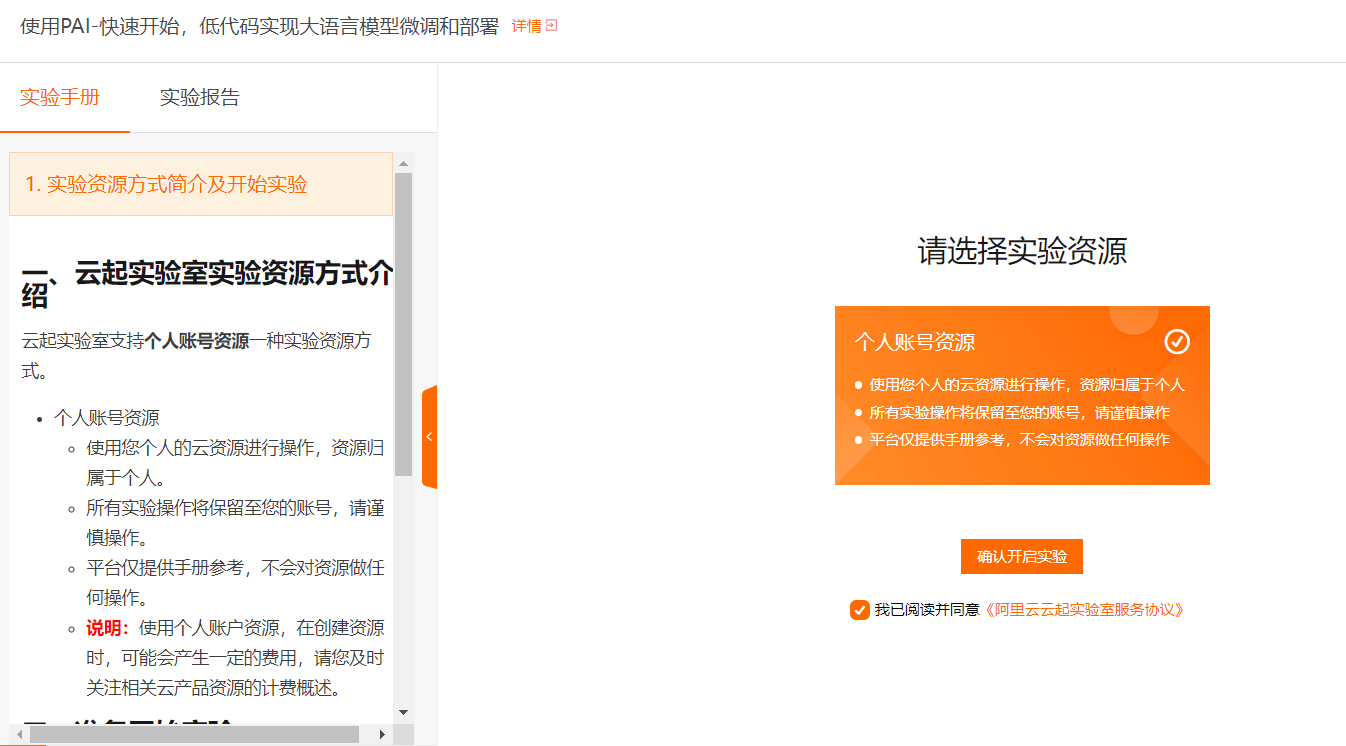
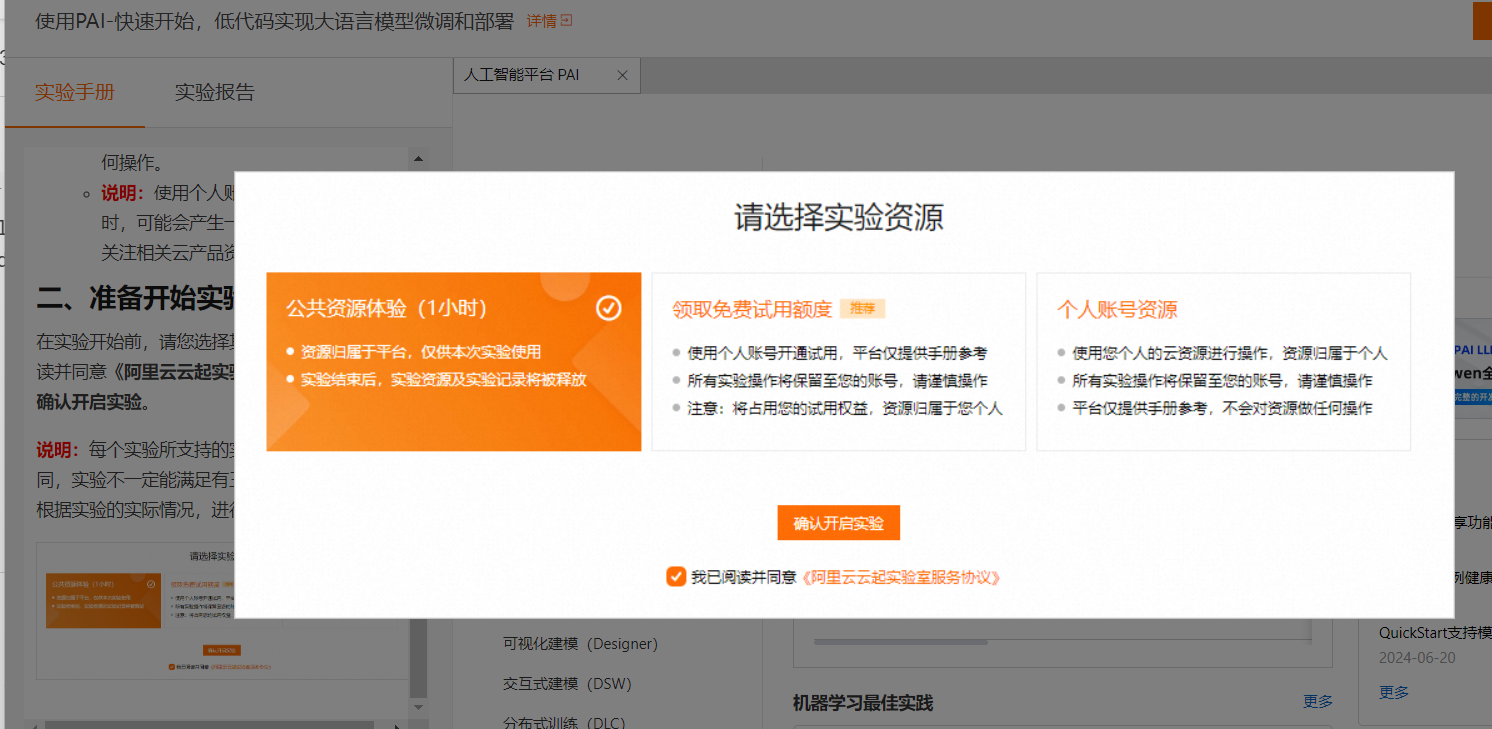
手册说有三个选项。 真是操作只有 自己的
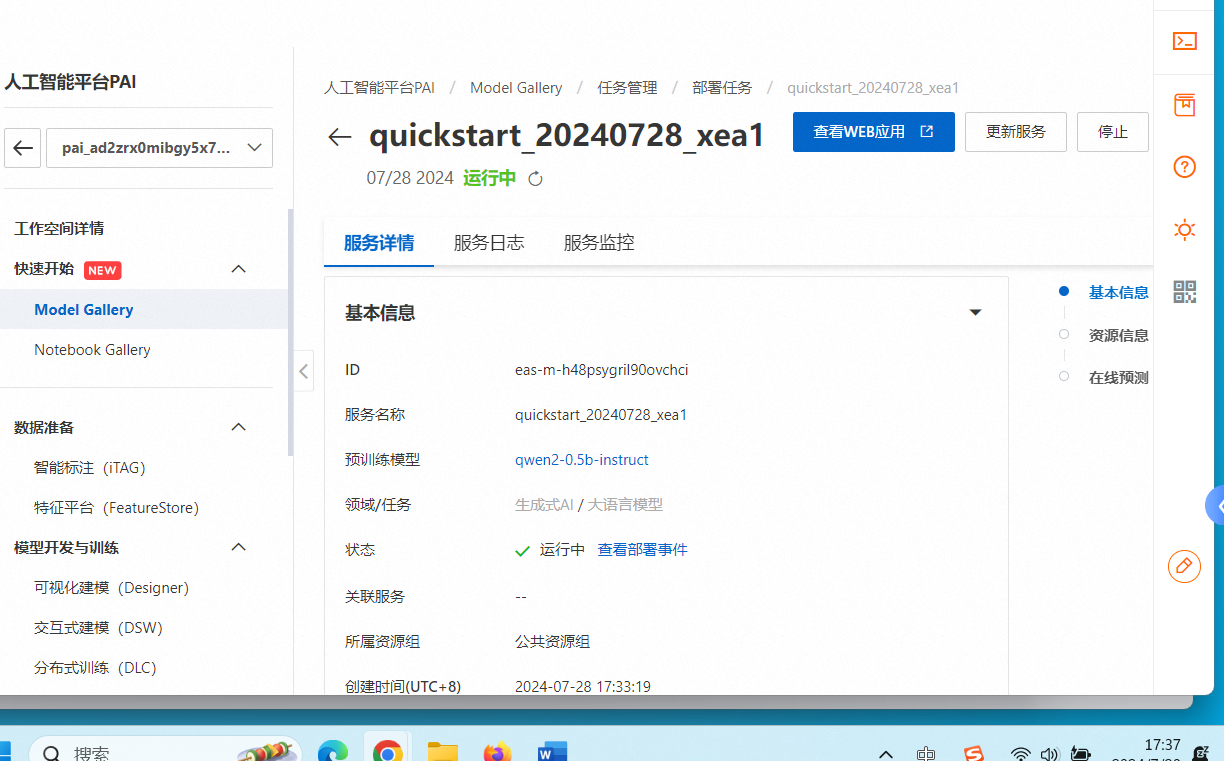
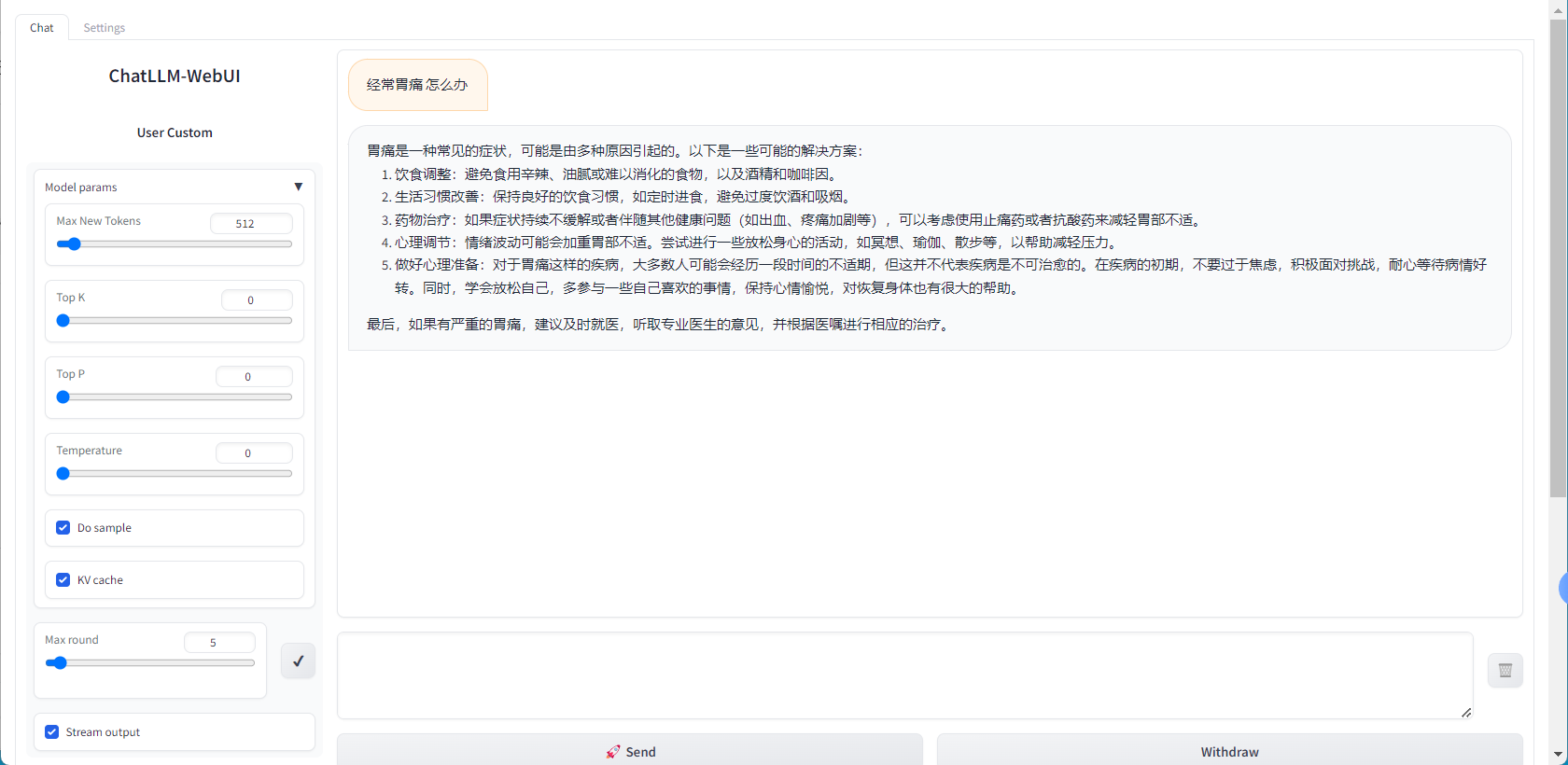
5分钟部署
https://quickstart-20240728-xea1-1650087321066347.pai-eas.cn-hangzhou.aliyun.com/
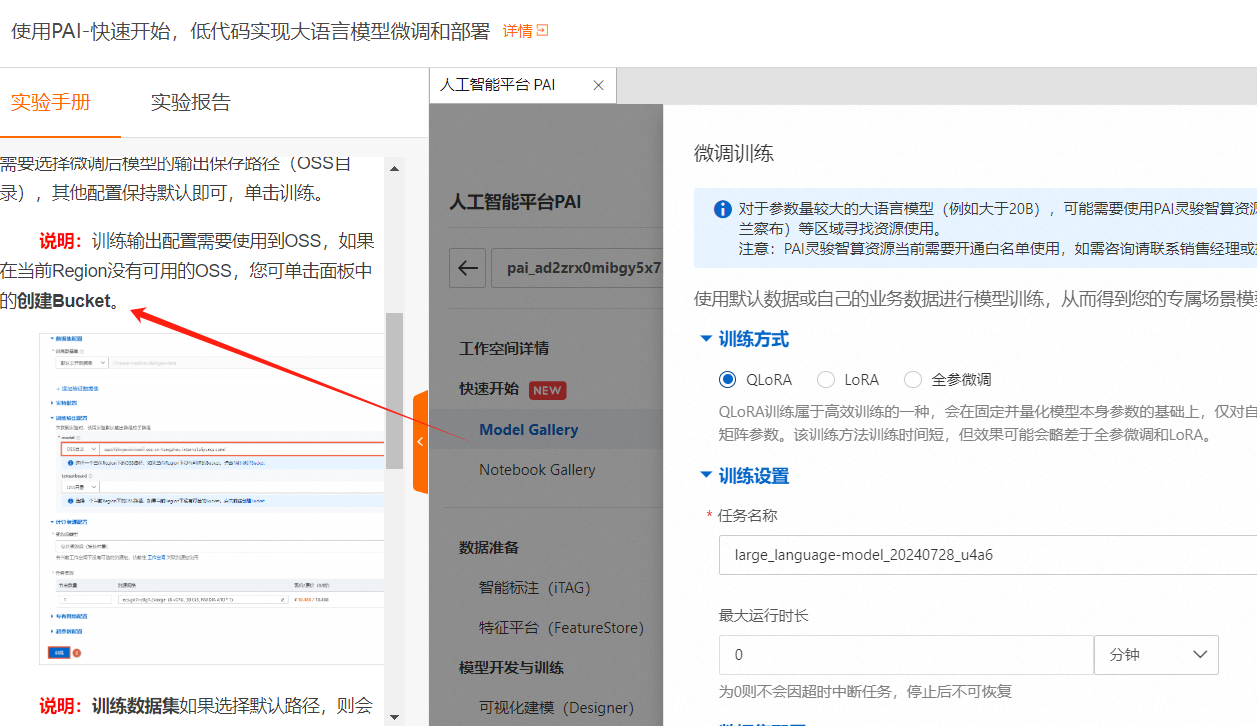
需要创建 oss
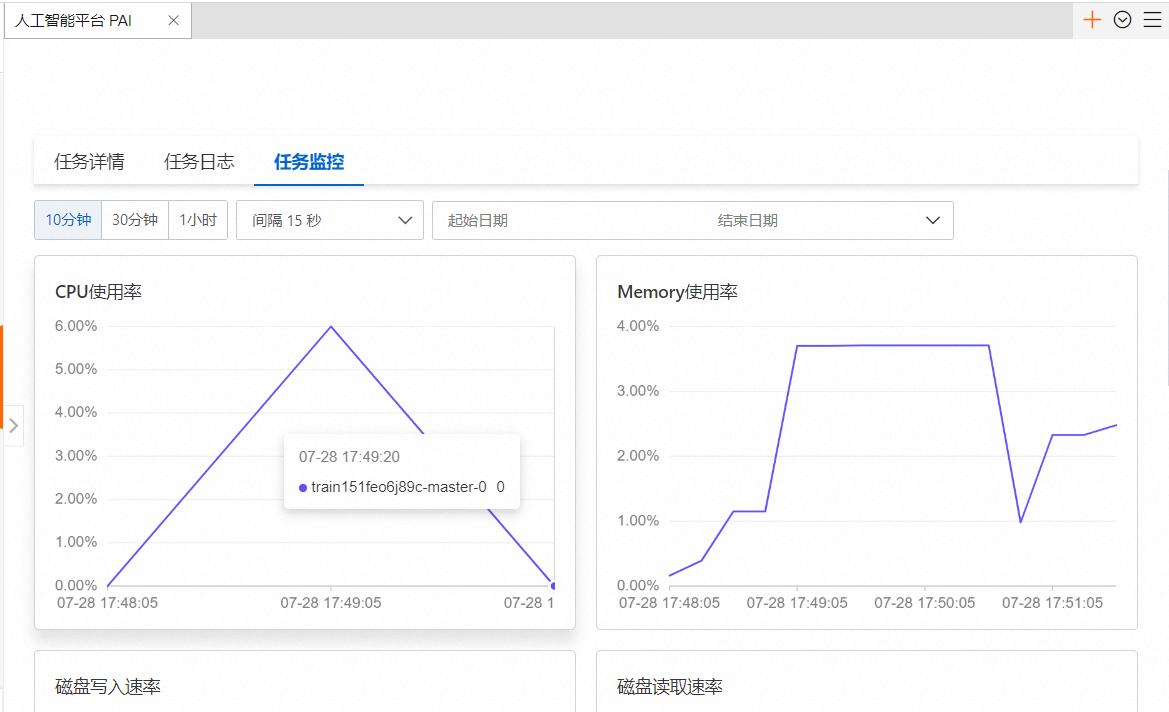
TrainingJob launch starting
NPP_VERSION=12.1.0.4
SHELL=/bin/bash
PAI_HPS={"apply_chat_template":"true","gradient_accumulation_steps":"8","learning_rate":"5e-5","load_in_4bit":"true","load_in_8bit":"false","lora_alpha":"32","lora_dim":"32","num_train_epochs":"1","per_device_train_batch_size":"1","seq_length":"128","system_prompt":"You are a helpful assistant"}
KUBERNETES_SERVICE_PORT_HTTPS=443
NVIDIA_VISIBLE_DEVICES=0
DALI_BUILD=7922358
KUBERNETES_SERVICE_PORT=6443
PYTHONUNBUFFERED=0
CUSOLVER_VERSION=11.4.5.107
CUBLAS_VERSION=12.1.3.1
KUBERNETES_CONTAINER_RESOURCE_GPU=1
HOSTNAME=train151feo6j89c-master-0
PYVER=3.10
MASTER_PORT=23456
SCRAPE_PROMETHEUS_METRICS=yes
CUFFT_VERSION=11.0.2.54
NVIDIA_REQUIRE_CUDA=cuda>=9.0
PAI_HPS_NUM_TRAIN_EPOCHS=1
CUDA_CACHE_DISABLE=1
TENSORBOARD_PORT=6006
_CUDA_COMPAT_STATUS=CUDA Driver OK
PAI_OUTPUT_MODEL=/ml/output/model/
TORCH_CUDA_ARCH_LIST=5.2 6.0 6.1 7.0 7.5 8.0 8.6 9.0+PTX
NCCL_VERSION=2.18.1
OPENBLAS_VERSION=0.3.20
NCCL_SOCKET_IFNAME=eth0
REGION_ID=cn-hangzhou
CUSPARSE_VERSION=12.1.0.106
ENV=/etc/shinit_v2
PWD=/ml/code
OPENUCX_VERSION=1.14.0
PAI_HPS_APPLY_CHAT_TEMPLATE=true
NSIGHT_SYSTEMS_VERSION=2023.2.1.89
NVIDIA_DRIVER_CAPABILITIES=compute,utility,video
POLYGRAPHY_VERSION=0.47.1
TZ=Asia/Shanghai
TRT_VERSION=8.6.1.2+cuda12.0.1.011
WORLD_SIZE=1
PAI_HPS_SYSTEM_PROMPT=You are a helpful assistant
NVIDIA_PRODUCT_NAME=PyTorch
RDMACORE_VERSION=36.0
HOME=/root
LANG=C.UTF-8
KUBERNETES_PORT_443_TCP=tcp://10.192.0.1:443
PAI_TRAINING_JOB_ID=train151feo6j89c
COCOAPI_VERSION=2.0+nv0.7.3
CUDA_VERSION=12.1.1.009
PYTORCH_VERSION=2.0.0
PIP_TRUSTED_HOST=mirrors.cloud.aliyuncs.com
PAI_INPUT_TRAIN=/ml/input/data/train/chinese_medical_train_sampled.json
CURAND_VERSION=10.3.2.106
PAI_TRAINING_USE_ECI=true
PYTORCH_BUILD_NUMBER=0
USE_EXPERIMENTAL_CUDNN_V8_API=1
CUTENSOR_VERSION=1.7.0.1
PIP_DEFAULT_TIMEOUT=100
PAI_HPS_LEARNING_RATE=5e-5
PAI_INPUT_MODEL=/ml/input/data/model
HPCX_VERSION=2.14
PAI_CONFIG_DIR=/ml/input/config/
TORCH_CUDNN_V8_API_ENABLED=1
NVM_DIR=/usr/local/nvm
MASTER_ADDR=train151feo6j89c-master-0
PYTHONPATH=/ml/code
SETUPTOOLS_USE_DISTUTILS=stdlib
GDRCOPY_VERSION=2.3
OPENMPI_VERSION=4.1.4
NVJPEG_VERSION=12.2.0.2
LIBRARY_PATH=/usr/local/cuda/lib64/stubs:
PYTHONIOENCODING=utf-8
PAI_ODPS_CREDENTIAL=/ml/input/credential/odps.json
PIP_INDEX_URL=https://mirrors.cloud.aliyuncs.com/pypi/simple
SHLVL=1
BASH_ENV=/etc/bash.bashrc
KUBERNETES_PORT_443_TCP_PROTO=tcp
PAI_HPS_GRADIENT_ACCUMULATION_STEPS=8
PAI_HPS_LORA_DIM=32
CUDNN_VERSION=8.9.1.23
PAI_HPS_PER_DEVICE_TRAIN_BATCH_SIZE=1
KUBERNETES_PORT_443_TCP_ADDR=10.192.0.1
NSIGHT_COMPUTE_VERSION=2023.1.1.4
TENANT_API_SERVER_URL=https://10.224.64.60:6443
DALI_VERSION=1.25.0
JUPYTER_PORT=8888
PYTORCH_HOME=/opt/pytorch/pytorch
LD_LIBRARY_PATH=/usr/local/cuda/compat/lib.real:/usr/local/lib/python3.10/dist-packages/torch/lib:/usr/local/lib/python3.10/dist-packages/torch_tensorrt/lib:/usr/local/cuda/compat/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
NVIDIA_BUILD_ID=60708168
RANK=0
PAI_HPS_LORA_ALPHA=32
OMPI_MCA_coll_hcoll_enable=0
PAI_USER_ARGS=--learning_rate 5e-5 --per_device_train_batch_size 1 --seq_length 128 --lora_alpha 32 --load_in_8bit false --gradient_accumulation_steps 8 --num_train_epochs 1 --lora_dim 32 --load_in_4bit true --apply_chat_template true --system_prompt 'You are a helpful assistant'
OPAL_PREFIX=/opt/hpcx/ompi
KUBERNETES_SERVICE_HOST=10.224.64.60
CUDA_DRIVER_VERSION=530.30.02
LC_ALL=C.UTF-8
TRANSFORMER_ENGINE_VERSION=0.8
KUBERNETES_PORT=tcp://10.192.0.1:443
KUBERNETES_PORT_443_TCP_PORT=443
PYTORCH_BUILD_VERSION=2.0.0
_CUDA_COMPAT_PATH=/usr/local/cuda/compat
CUDA_HOME=/usr/local/cuda
CUDA_MODULE_LOADING=LAZY
NPROC_PER_NODE=1
NVIDIA_REQUIRE_JETPACK_HOST_MOUNTS=
PATH=/usr/local/lib/python3.10/dist-packages/torch_tensorrt/bin:/usr/local/mpi/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/ucx/bin:/opt/tensorrt/bin:/home/pai/bin
PAI_HPS_SEQ_LENGTH=128
MOFED_VERSION=5.4-rdmacore36.0
NVIDIA_PYTORCH_VERSION=23.05
TRTOSS_VERSION=23.05
PAI_HPS_LOAD_IN_8BIT=false
PAI_HPS_LOAD_IN_4BIT=true
TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1
_=/usr/bin/env
Installing dependencies from /ml/input/config//requirements.txt
Looking in indexes: https://mirrors.cloud.aliyuncs.com/pypi/simple, https://pypi.ngc.nvidia.com
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 24.0 -> 24.1.2
[notice] To update, run: python -m pip install --upgrade pip
User program launching
-----------------------------------------------------------------
2024/07/28 09:47:53 INFO: training_utils version: 1.0.4
2024/07/28 09:47:53 INFO: Env DALI_BUILD=7922358
2024/07/28 09:47:53 INFO: Env PAI_INPUT_MODEL=/ml/input/data/model
2024/07/28 09:47:53 INFO: Env LIBRARY_PATH=/usr/local/cuda/lib64/stubs:
2024/07/28 09:47:53 INFO: Env PAI_HPS_PER_DEVICE_TRAIN_BATCH_SIZE=1
2024/07/28 09:47:53 INFO: Env KUBERNETES_SERVICE_PORT=6443
2024/07/28 09:47:53 INFO: Env PYTORCH_BUILD_NUMBER=0
2024/07/28 09:47:53 INFO: Env PYTHONIOENCODING=utf-8
2024/07/28 09:47:53 INFO: Env KUBERNETES_PORT=tcp://10.192.0.1:443
2024/07/28 09:47:53 INFO: Env NCCL_SOCKET_IFNAME=eth0
2024/07/28 09:47:53 INFO: Env PAI_HPS_APPLY_CHAT_TEMPLATE=true
2024/07/28 09:47:53 INFO: Env PIP_TRUSTED_HOST=mirrors.cloud.aliyuncs.com
2024/07/28 09:47:53 INFO: Env PIP_DEFAULT_TIMEOUT=100
2024/07/28 09:47:53 INFO: Env PYTORCH_HOME=/opt/pytorch/pytorch
2024/07/28 09:47:53 INFO: Env SCRAPE_PROMETHEUS_METRICS=yes
2024/07/28 09:47:53 INFO: Env MASTER_ADDR=train151feo6j89c-master-0
2024/07/28 09:47:53 INFO: Env PAI_HPS_LORA_DIM=32
2024/07/28 09:47:53 INFO: Env CUSOLVER_VERSION=11.4.5.107
2024/07/28 09:47:53 INFO: Env HOSTNAME=train151feo6j89c-master-0
2024/07/28 09:47:53 INFO: Env COCOAPI_VERSION=2.0+nv0.7.3
2024/07/28 09:47:53 INFO: Env CUTENSOR_VERSION=1.7.0.1
2024/07/28 09:47:53 INFO: Env SHLVL=1
2024/07/28 09:47:53 INFO: Env LD_LIBRARY_PATH=/usr/local/cuda/compat/lib.real:/usr/local/lib/python3.10/dist-packages/torch/lib:/usr/local/lib/python3.10/dist-packages/torch_tensorrt/lib:/usr/local/cuda/compat/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
2024/07/28 09:47:53 INFO: Env MASTER_PORT=23456
2024/07/28 09:47:53 INFO: Env HOME=/root
2024/07/28 09:47:53 INFO: Env PAI_USER_ARGS=--learning_rate 5e-5 --per_device_train_batch_size 1 --seq_length 128 --lora_alpha 32 --load_in_8bit false --gradient_accumulation_steps 8 --num_train_epochs 1 --lora_dim 32 --load_in_4bit true --apply_chat_template true --system_prompt 'You are a helpful assistant'
2024/07/28 09:47:53 INFO: Env PYTHONUNBUFFERED=0
2024/07/28 09:47:53 INFO: Env CUDA_CACHE_DISABLE=1
2024/07/28 09:47:53 INFO: Env PYVER=3.10
2024/07/28 09:47:53 INFO: Env OPENBLAS_VERSION=0.3.20
2024/07/28 09:47:53 INFO: Env PAI_CONFIG_DIR=/ml/input/config/
2024/07/28 09:47:53 INFO: Env NPROC_PER_NODE=1
2024/07/28 09:47:53 INFO: Env WORLD_SIZE=1
2024/07/28 09:47:53 INFO: Env PAI_HPS_SEQ_LENGTH=128
2024/07/28 09:47:53 INFO: Env REGION_ID=cn-hangzhou
2024/07/28 09:47:53 INFO: Env ENV=/etc/shinit_v2
2024/07/28 09:47:53 INFO: Env RDMACORE_VERSION=36.0
2024/07/28 09:47:53 INFO: Env NVJPEG_VERSION=12.2.0.2
2024/07/28 09:47:53 INFO: Env NVIDIA_BUILD_ID=60708168
2024/07/28 09:47:53 INFO: Env CUDA_VERSION=12.1.1.009
2024/07/28 09:47:53 INFO: Env PAI_INPUT_TRAIN=/ml/input/data/train/chinese_medical_train_sampled.json
2024/07/28 09:47:53 INFO: Env NVM_DIR=/usr/local/nvm
2024/07/28 09:47:53 INFO: Env RANK=0
2024/07/28 09:47:53 INFO: Env TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1
2024/07/28 09:47:53 INFO: Env CUBLAS_VERSION=12.1.3.1
2024/07/28 09:47:53 INFO: Env TORCH_CUDA_ARCH_LIST=5.2 6.0 6.1 7.0 7.5 8.0 8.6 9.0+PTX
2024/07/28 09:47:53 INFO: Env NSIGHT_SYSTEMS_VERSION=2023.2.1.89
2024/07/28 09:47:53 INFO: Env OPAL_PREFIX=/opt/hpcx/ompi
2024/07/28 09:47:53 INFO: Env CUDA_MODULE_LOADING=LAZY
2024/07/28 09:47:53 INFO: Env NVIDIA_REQUIRE_CUDA=cuda>=9.0
2024/07/28 09:47:53 INFO: Env TRT_VERSION=8.6.1.2+cuda12.0.1.011
2024/07/28 09:47:53 INFO: Env GDRCOPY_VERSION=2.3
2024/07/28 09:47:53 INFO: Env TENANT_API_SERVER_URL=https://10.224.64.60:6443
2024/07/28 09:47:53 INFO: Env PYTORCH_BUILD_VERSION=2.0.0
2024/07/28 09:47:53 INFO: Env _=/usr/bin/sh
2024/07/28 09:47:53 INFO: Env NVIDIA_DRIVER_CAPABILITIES=compute,utility,video
2024/07/28 09:47:53 INFO: Env POLYGRAPHY_VERSION=0.47.1
2024/07/28 09:47:53 INFO: Env PAI_TRAINING_JOB_ID=train151feo6j89c
2024/07/28 09:47:53 INFO: Env CURAND_VERSION=10.3.2.106
2024/07/28 09:47:53 INFO: Env MOFED_VERSION=5.4-rdmacore36.0
2024/07/28 09:47:53 INFO: Env PAI_OUTPUT_MODEL=/ml/output/model/
2024/07/28 09:47:53 INFO: Env KUBERNETES_PORT_443_TCP_ADDR=10.192.0.1
2024/07/28 09:47:53 INFO: Env TRANSFORMER_ENGINE_VERSION=0.8
2024/07/28 09:47:53 INFO: Env PAI_HPS_LOAD_IN_4BIT=true
2024/07/28 09:47:53 INFO: Env TORCH_CUDNN_V8_API_ENABLED=1
2024/07/28 09:47:53 INFO: Env NVIDIA_PYTORCH_VERSION=23.05
2024/07/28 09:47:53 INFO: Env PATH=/usr/local/lib/python3.10/dist-packages/torch_tensorrt/bin:/usr/local/mpi/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/ucx/bin:/opt/tensorrt/bin:/home/pai/bin
2024/07/28 09:47:53 INFO: Env PAI_HPS_SYSTEM_PROMPT=You are a helpful assistant
2024/07/28 09:47:53 INFO: Env PYTORCH_VERSION=2.0.0
2024/07/28 09:47:53 INFO: Env PIP_INDEX_URL=https://mirrors.cloud.aliyuncs.com/pypi/simple
2024/07/28 09:47:53 INFO: Env JUPYTER_PORT=8888
2024/07/28 09:47:53 INFO: Env CUDA_DRIVER_VERSION=530.30.02
2024/07/28 09:47:53 INFO: Env KUBERNETES_PORT_443_TCP_PORT=443
2024/07/28 09:47:53 INFO: Env _CUDA_COMPAT_STATUS=CUDA Driver OK
2024/07/28 09:47:53 INFO: Env KUBERNETES_PORT_443_TCP_PROTO=tcp
2024/07/28 09:47:53 INFO: Env PAI_HPS_LOAD_IN_8BIT=false
2024/07/28 09:47:53 INFO: Env NVIDIA_PRODUCT_NAME=PyTorch
2024/07/28 09:47:53 INFO: Env LANG=C.UTF-8
2024/07/28 09:47:53 INFO: Env PAI_HPS_LEARNING_RATE=5e-5
2024/07/28 09:47:53 INFO: Env NPP_VERSION=12.1.0.4
2024/07/28 09:47:53 INFO: Env TENSORBOARD_PORT=6006
2024/07/28 09:47:53 INFO: Env PAI_TRAINING_USE_ECI=true
2024/07/28 09:47:53 INFO: Env PAI_HPS_GRADIENT_ACCUMULATION_STEPS=8
2024/07/28 09:47:53 INFO: Env CUFFT_VERSION=11.0.2.54
2024/07/28 09:47:53 INFO: Env PAI_HPS_NUM_TRAIN_EPOCHS=1
2024/07/28 09:47:53 INFO: Env CUDNN_VERSION=8.9.1.23
2024/07/28 09:47:53 INFO: Env NSIGHT_COMPUTE_VERSION=2023.1.1.4
2024/07/28 09:47:53 INFO: Env DALI_VERSION=1.25.0
2024/07/28 09:47:53 INFO: Env PAI_HPS_LORA_ALPHA=32
2024/07/28 09:47:53 INFO: Env SHELL=/bin/bash
2024/07/28 09:47:53 INFO: Env OPENMPI_VERSION=4.1.4
2024/07/28 09:47:53 INFO: Env TRTOSS_VERSION=23.05
2024/07/28 09:47:53 INFO: Env KUBERNETES_CONTAINER_RESOURCE_GPU=1
2024/07/28 09:47:53 INFO: Env OMPI_MCA_coll_hcoll_enable=0
2024/07/28 09:47:53 INFO: Env SETUPTOOLS_USE_DISTUTILS=stdlib
2024/07/28 09:47:53 INFO: Env CUSPARSE_VERSION=12.1.0.106
2024/07/28 09:47:53 INFO: Env NVIDIA_REQUIRE_JETPACK_HOST_MOUNTS=
2024/07/28 09:47:53 INFO: Env KUBERNETES_SERVICE_PORT_HTTPS=443
2024/07/28 09:47:53 INFO: Env KUBERNETES_PORT_443_TCP=tcp://10.192.0.1:443
2024/07/28 09:47:53 INFO: Env BASH_ENV=/etc/bash.bashrc
2024/07/28 09:47:53 INFO: Env PWD=/ml/code
2024/07/28 09:47:53 INFO: Env KUBERNETES_SERVICE_HOST=10.224.64.60
2024/07/28 09:47:53 INFO: Env LC_ALL=C.UTF-8
2024/07/28 09:47:53 INFO: Env CUDA_HOME=/usr/local/cuda
2024/07/28 09:47:53 INFO: Env PAI_HPS={"apply_chat_template":"true","gradient_accumulation_steps":"8","learning_rate":"5e-5","load_in_4bit":"true","load_in_8bit":"false","lora_alpha":"32","lora_dim":"32","num_train_epochs":"1","per_device_train_batch_size":"1","seq_length":"128","system_prompt":"You are a helpful assistant"}
2024/07/28 09:47:53 INFO: Env USE_EXPERIMENTAL_CUDNN_V8_API=1
2024/07/28 09:47:53 INFO: Env PYTHONPATH=/ml/code
2024/07/28 09:47:53 INFO: Env _CUDA_COMPAT_PATH=/usr/local/cuda/compat
2024/07/28 09:47:53 INFO: Env NVIDIA_VISIBLE_DEVICES=0
2024/07/28 09:47:53 INFO: Env NCCL_VERSION=2.18.1
2024/07/28 09:47:53 INFO: Env TZ=Asia/Shanghai
2024/07/28 09:47:53 INFO: Env OPENUCX_VERSION=1.14.0
2024/07/28 09:47:53 INFO: Env HPCX_VERSION=2.14
2024/07/28 09:47:53 INFO: Env PAI_ODPS_CREDENTIAL=/ml/input/credential/odps.json
2024/07/28 09:47:53 INFO: launch: launcherType=PythonLauncher, cmd=['/usr/bin/python', '-m', 'train', '--apply_chat_template', 'true', '--gradient_accumulation_steps', '8', '--learning_rate', '5e-5', '--load_in_4bit', 'true', '--load_in_8bit', 'false', '--lora_alpha', '32', '--lora_dim', '32', '--num_train_epochs', '1', '--per_device_train_batch_size', '1', '--seq_length', '128', '--system_prompt', 'You are a helpful assistant']
2024/07/28 09:47:53 INFO: launch: parameters={'apply_chat_template': 'true', 'gradient_accumulation_steps': '8', 'learning_rate': '5e-5', 'load_in_4bit': 'true', 'load_in_8bit': 'false', 'lora_alpha': '32', 'lora_dim': '32', 'num_train_epochs': '1', 'per_device_train_batch_size': '1', 'seq_length': '128', 'system_prompt': 'You are a helpful assistant'}
2024/07/28 09:47:53 INFO: hyper_params: {'apply_chat_template': 'true', 'gradient_accumulation_steps': 8, 'learning_rate': 5e-05, 'load_in_4bit': 'true', 'load_in_8bit': 'false', 'lora_alpha': 32, 'lora_dim': 32, 'num_train_epochs': 1, 'per_device_train_batch_size': 1, 'seq_length': 128, 'system_prompt': 'You are a helpful assistant'}
***** No Validation dataset provided! *****
2024/07/28 09:47:53 INFO: Get hostname train151feo6j89c-master-0 succeed. retry times: 0
2024/07/28 09:47:53 INFO: execute command: mkdir -p /tmp/input_model/
2024/07/28 09:47:53 INFO: execute command succeed
2024/07/28 09:47:53 INFO: execute command: cp -R /ml/input/data/model/* /tmp/input_model/
2024/07/28 09:47:59 INFO: execute command succeed
2024/07/28 09:47:59 INFO: execute command: pip install --no-index --find-links=assets/ transformers==4.37.0 tokenizers==0.15.1
2024/07/28 09:47:59 INFO: Looking in links: assets/
2024/07/28 09:47:59 INFO: Processing ./assets/transformers-4.37.0-py3-none-any.whl
2024/07/28 09:47:59 INFO: Processing ./assets/tokenizers-0.15.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
2024/07/28 09:48:00 INFO: Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (3.12.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: huggingface-hub<1.0,>=0.19.3 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (0.23.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (1.22.2)
2024/07/28 09:48:00 INFO: Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (23.1)
2024/07/28 09:48:00 INFO: Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (6.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (2023.6.3)
2024/07/28 09:48:00 INFO: Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (2.29.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (0.4.3)
2024/07/28 09:48:00 INFO: Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers==4.37.0) (4.65.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: fsspec>=2023.5.0 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.19.3->transformers==4.37.0) (2024.3.1)
2024/07/28 09:48:00 INFO: Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.19.3->transformers==4.37.0) (4.11.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->transformers==4.37.0) (3.1.0)
2024/07/28 09:48:00 INFO: Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers==4.37.0) (3.4)
2024/07/28 09:48:00 INFO: Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers==4.37.0) (1.26.15)
2024/07/28 09:48:00 INFO: Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers==4.37.0) (2022.12.7)
2024/07/28 09:48:02 INFO: Installing collected packages: tokenizers, transformers
2024/07/28 09:48:02 INFO: Attempting uninstall: tokenizers
2024/07/28 09:48:02 INFO: Found existing installation: tokenizers 0.13.3
2024/07/28 09:48:02 INFO: Uninstalling tokenizers-0.13.3:
2024/07/28 09:48:02 INFO: Successfully uninstalled tokenizers-0.13.3
2024/07/28 09:48:02 INFO: Attempting uninstall: transformers
2024/07/28 09:48:02 INFO: Found existing installation: transformers 4.33.0
2024/07/28 09:48:02 INFO: Uninstalling transformers-4.33.0:
2024/07/28 09:48:02 INFO: Successfully uninstalled transformers-4.33.0
2024/07/28 09:48:07 INFO: Successfully installed tokenizers-0.15.1 transformers-4.37.0
2024/07/28 09:48:07 INFO: WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
2024/07/28 09:48:07 INFO: execute command succeed
2024/07/28 09:48:07 INFO: Sft training command: ['accelerate', 'launch', '--num_processes', '1', '--config_file', 'multi_gpu.yaml', 'sft.py', '--model_name', '/tmp/input_model/', '--model_type', 'qwen2', '--train_dataset_name', '/ml/input/data/train/chinese_medical_train_sampled.json', '--num_train_epochs', '1', '--batch_size', '1', '--gradient_accumulation_steps', '8', '--seq_length', '128', '--learning_rate', '5e-05', '--system_prompt', 'You are a helpful assistant', '--apply_chat_template', '--use_peft', '--target_modules', 'k_proj', 'o_proj', 'q_proj', 'v_proj', '--peft_lora_r', '32', '--peft_lora_alpha', '32', '--load_in_4bit', '--output_dir', '/tmp/adapter/']
2024/07/28 09:48:07 INFO: execute command: mkdir -p /tmp/model/
2024/07/28 09:48:07 INFO: execute command succeed
2024/07/28 09:48:07 INFO: execute command: mkdir -p /tmp/adapter/
2024/07/28 09:48:07 INFO: execute command succeed
[2024-07-28 09:48:16,453] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-07-28 09:48:26,068] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-07-28 09:48:28,007] [INFO] [comm.py:637:init_distributed] cdb=None
[2024-07-28 09:48:28,007] [INFO] [comm.py:668:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
Detected kernel version 4.19.24, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Generating train split: 0 examples [00:00, ? examples/s]
Generating train split: 500 examples [00:00, 3515.50 examples/s]
Generating train split: 500 examples [00:00, 3508.18 examples/s]
Map: 0%| | 0/500 [00:00<?, ? examples/s]
Map: 100%|██████████| 500/500 [00:00<00:00, 8432.29 examples/s]
/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py:446: FutureWarning: Passing the following arguments to `Accelerator` is deprecated and will be removed in version 1.0 of Accelerate: dict_keys(['dispatch_batches', 'split_batches']). Please pass an `accelerate.DataLoaderConfiguration` instead:
dataloader_config = DataLoaderConfiguration(dispatch_batches=None, split_batches=False)
warnings.warn(
Detected kernel version 4.19.24, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py310_cu121/cpu_adam...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py310_cu121/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/4] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1016\" -I/usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.10/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_86,code=compute_86 -gencode=arch=compute_86,code=sm_86 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++17 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_86,code=compute_86 -DBF16_AVAILABLE -c /usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
[2/4] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1016\" -I/usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.10/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++17 -O3 -std=c++17 -g -Wno-reorder -L/usr/local/cuda/lib64 -lcudart -lcublas -g -march=native -fopenmp -D__AVX512__ -D__ENABLE_CUDA__ -DBF16_AVAILABLE -c /usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o
[3/4] c++ -MMD -MF cpu_adam_impl.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1016\" -I/usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.10/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.10/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++17 -O3 -std=c++17 -g -Wno-reorder -L/usr/local/cuda/lib64 -lcudart -lcublas -g -march=native -fopenmp -D__AVX512__ -D__ENABLE_CUDA__ -DBF16_AVAILABLE -c /usr/local/lib/python3.10/dist-packages/deepspeed/ops/csrc/adam/cpu_adam_impl.cpp -o cpu_adam_impl.o
[4/4] c++ cpu_adam.o cpu_adam_impl.o custom_cuda_kernel.cuda.o -shared -lcurand -L/usr/local/lib/python3.10/dist-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cpu_adam.so
Loading extension module cpu_adam...
Time to load cpu_adam op: 27.244544744491577 seconds
Rank: 0 partition count [1] and sizes[(4325376, False)]
0%| | 0/62 [00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
{'loss': 3.9352, 'learning_rate': 5e-05, 'epoch': 0.02}
{'loss': 4.0824, 'learning_rate': 4.9966852247120764e-05, 'epoch': 0.03}
{'loss': 4.0303, 'learning_rate': 4.9867496890364726e-05, 'epoch': 0.05}
{'loss': 3.9154, 'learning_rate': 4.970219740227693e-05, 'epoch': 0.06}
{'loss': 3.9716, 'learning_rate': 4.947139212738395e-05, 'epoch': 0.08}
{'loss': 3.6916, 'learning_rate': 4.9175693119783013e-05, 'epoch': 0.1}
{'loss': 3.5972, 'learning_rate': 4.881588452008456e-05, 'epoch': 0.11}
{'loss': 3.3336, 'learning_rate': 4.839292047601234e-05, 'epoch': 0.13}
{'loss': 3.7984, 'learning_rate': 4.790792261217512e-05, 'epoch': 0.14}
{'loss': 3.654, 'learning_rate': 4.736217705571989e-05, 'epoch': 0.16}
{'loss': 3.569, 'learning_rate': 4.6757131025753886e-05, 'epoch': 0.18}
{'loss': 3.3566, 'learning_rate': 4.609438899557964e-05, 'epoch': 0.19}
{'loss': 3.5019, 'learning_rate': 4.5375708437920284e-05, 'epoch': 0.21}
{'loss': 3.2186, 'learning_rate': 4.460299516441777e-05, 'epoch': 0.22}
{'loss': 3.4748, 'learning_rate': 4.3778298271762995e-05, 'epoch': 0.24}
{'loss': 3.1056, 'learning_rate': 4.2903804707859835e-05, 'epoch': 0.26}
{'loss': 3.1264, 'learning_rate': 4.198183347243233e-05, 'epoch': 0.27}
{'loss': 3.149, 'learning_rate': 4.101482946745439e-05, 'epoch': 0.29}
{'loss': 3.2867, 'learning_rate': 4.000535701370921e-05, 'epoch': 0.3}
{'loss': 2.8345, 'learning_rate': 3.895609305067162e-05, 'epoch': 0.32}
{'loss': 2.9539, 'learning_rate': 3.7869820037745776e-05, 'epoch': 0.34}
{'loss': 2.8836, 'learning_rate': 3.6749418575683e-05, 'epoch': 0.35}
{'loss': 2.8869, 'learning_rate': 3.5597859767746524e-05, 'epoch': 0.37}
{'loss': 2.9476, 'learning_rate': 3.4418197340879635e-05, 'epoch': 0.38}
{'loss': 3.2243, 'learning_rate': 3.321355954777087e-05, 'epoch': 0.4}
{'loss': 2.9575, 'learning_rate': 3.1987140871290236e-05, 'epoch': 0.42}
{'loss': 2.782, 'learning_rate': 3.07421935532949e-05, 'epoch': 0.43}
{'loss': 2.9575, 'learning_rate': 2.9482018970268393e-05, 'epoch': 0.45}
{'loss': 2.7949, 'learning_rate': 2.8209958878663778e-05, 'epoch': 0.46}
{'loss': 2.8768, 'learning_rate': 2.6929386553166164e-05, 'epoch': 0.48}
{'loss': 2.8336, 'learning_rate': 2.564369784137472e-05, 'epoch': 0.5}
{'loss': 2.8117, 'learning_rate': 2.4356302158625288e-05, 'epoch': 0.51}
{'loss': 2.4707, 'learning_rate': 2.3070613446833842e-05, 'epoch': 0.53}
{'loss': 2.7951, 'learning_rate': 2.1790041121336225e-05, 'epoch': 0.54}
{'loss': 2.6495, 'learning_rate': 2.0517981029731616e-05, 'epoch': 0.56}
{'loss': 2.5967, 'learning_rate': 1.9257806446705116e-05, 'epoch': 0.58}
{'loss': 2.5633, 'learning_rate': 1.8012859128709766e-05, 'epoch': 0.59}
{'loss': 2.545, 'learning_rate': 1.6786440452229134e-05, 'epoch': 0.61}
{'loss': 2.8035, 'learning_rate': 1.558180265912037e-05, 'epoch': 0.62}
{'loss': 2.4193, 'learning_rate': 1.4402140232253486e-05, 'epoch': 0.64}
{'loss': 2.6712, 'learning_rate': 1.325058142431701e-05, 'epoch': 0.66}
{'loss': 2.5555, 'learning_rate': 1.213017996225424e-05, 'epoch': 0.67}
{'loss': 2.5459, 'learning_rate': 1.1043906949328387e-05, 'epoch': 0.69}
{'loss': 2.6093, 'learning_rate': 9.994642986290797e-06, 'epoch': 0.7}
{'loss': 2.5945, 'learning_rate': 8.985170532545622e-06, 'epoch': 0.72}
{'loss': 2.6244, 'learning_rate': 8.018166527567672e-06, 'epoch': 0.74}
{'loss': 2.547, 'learning_rate': 7.096195292140173e-06, 'epoch': 0.75}
{'loss': 2.7192, 'learning_rate': 6.221701728237009e-06, 'epoch': 0.77}
{'loss': 2.7056, 'learning_rate': 5.397004835582242e-06, 'epoch': 0.78}
{'loss': 2.6607, 'learning_rate': 4.624291562079719e-06, 'epoch': 0.8}
{'loss': 2.4398, 'learning_rate': 3.90561100442036e-06, 'epoch': 0.82}
{'loss': 2.6067, 'learning_rate': 3.2428689742461188e-06, 'epoch': 0.83}
{'loss': 2.3387, 'learning_rate': 2.637822944280116e-06, 'epoch': 0.85}
{'loss': 2.5774, 'learning_rate': 2.092077387824884e-06, 'epoch': 0.86}
{'loss': 2.5503, 'learning_rate': 1.6070795239876618e-06, 'epoch': 0.88}
{'loss': 2.6284, 'learning_rate': 1.1841154799154374e-06, 'epoch': 0.9}
{'loss': 2.6443, 'learning_rate': 8.243068802169906e-07, 'epoch': 0.91}
{'loss': 2.475, 'learning_rate': 5.286078726160549e-07, 'epoch': 0.93}
{'loss': 2.7634, 'learning_rate': 2.978025977230736e-07, 'epoch': 0.94}
{'loss': 2.6926, 'learning_rate': 1.3250310963527358e-07, 'epoch': 0.96}
{'loss': 2.658, 'learning_rate': 3.314775287923677e-08, 'epoch': 0.98}
{'loss': 2.5953, 'learning_rate': 0.0, 'epoch': 0.99}
{'train_runtime': 98.9097, 'train_samples_per_second': 5.055, 'train_steps_per_second': 0.627, 'train_loss': 2.961119524894222, 'epoch': 0.99}
2%|▏ | 1/62 [00:02<02:12, 2.17s/it]
2%|▏ | 1/62 [00:02<02:12, 2.17s/it]
3%|▎ | 2/62 [00:03<01:49, 1.82s/it]
3%|▎ | 2/62 [00:03<01:49, 1.82s/it]
5%|▍ | 3/62 [00:05<01:40, 1.71s/it]
5%|▍ | 3/62 [00:05<01:40, 1.71s/it]
6%|▋ | 4/62 [00:06<01:36, 1.66s/it]
6%|▋ | 4/62 [00:06<01:36, 1.66s/it]
8%|▊ | 5/62 [00:08<01:32, 1.63s/it]
8%|▊ | 5/62 [00:08<01:32, 1.63s/it]
10%|▉ | 6/62 [00:10<01:30, 1.61s/it]
10%|▉ | 6/62 [00:10<01:30, 1.61s/it]
11%|█▏ | 7/62 [00:11<01:28, 1.60s/it]
11%|█▏ | 7/62 [00:11<01:28, 1.60s/it]
13%|█▎ | 8/62 [00:13<01:25, 1.59s/it]
13%|█▎ | 8/62 [00:13<01:25, 1.59s/it]
15%|█▍ | 9/62 [00:14<01:24, 1.59s/it]
15%|█▍ | 9/62 [00:14<01:24, 1.59s/it]
16%|█▌ | 10/62 [00:16<01:22, 1.58s/it]
16%|█▌ | 10/62 [00:16<01:22, 1.58s/it]
18%|█▊ | 11/62 [00:17<01:20, 1.58s/it]
18%|█▊ | 11/62 [00:17<01:20, 1.58s/it]
19%|█▉ | 12/62 [00:19<01:18, 1.58s/it]
19%|█▉ | 12/62 [00:19<01:18, 1.58s/it]
21%|██ | 13/62 [00:21<01:17, 1.58s/it]
21%|██ | 13/62 [00:21<01:17, 1.58s/it]
23%|██▎ | 14/62 [00:22<01:15, 1.58s/it]
23%|██▎ | 14/62 [00:22<01:15, 1.58s/it]
24%|██▍ | 15/62 [00:24<01:14, 1.57s/it]
24%|██▍ | 15/62 [00:24<01:14, 1.57s/it]
26%|██▌ | 16/62 [00:25<01:12, 1.57s/it]
26%|██▌ | 16/62 [00:25<01:12, 1.57s/it]
27%|██▋ | 17/62 [00:27<01:10, 1.57s/it]
27%|██▋ | 17/62 [00:27<01:10, 1.57s/it]
29%|██▉ | 18/62 [00:28<01:09, 1.57s/it]
29%|██▉ | 18/62 [00:28<01:09, 1.57s/it]
31%|███ | 19/62 [00:30<01:07, 1.58s/it]
31%|███ | 19/62 [00:30<01:07, 1.58s/it]
32%|███▏ | 20/62 [00:32<01:06, 1.57s/it]
32%|███▏ | 20/62 [00:32<01:06, 1.57s/it]
34%|███▍ | 21/62 [00:33<01:04, 1.57s/it]
34%|███▍ | 21/62 [00:33<01:04, 1.57s/it]
35%|███▌ | 22/62 [00:35<01:02, 1.57s/it]
35%|███▌ | 22/62 [00:35<01:02, 1.57s/it]
37%|███▋ | 23/62 [00:36<01:01, 1.57s/it]
37%|███▋ | 23/62 [00:36<01:01, 1.57s/it]
39%|███▊ | 24/62 [00:38<00:59, 1.57s/it]
39%|███▊ | 24/62 [00:38<00:59, 1.57s/it]
40%|████ | 25/62 [00:39<00:58, 1.57s/it]
40%|████ | 25/62 [00:39<00:58, 1.57s/it]
42%|████▏ | 26/62 [00:41<00:56, 1.57s/it]
42%|████▏ | 26/62 [00:41<00:56, 1.57s/it]
44%|████▎ | 27/62 [00:43<00:55, 1.58s/it]
44%|████▎ | 27/62 [00:43<00:55, 1.58s/it]
45%|████▌ | 28/62 [00:44<00:53, 1.58s/it]
45%|████▌ | 28/62 [00:44<00:53, 1.58s/it]
47%|████▋ | 29/62 [00:46<00:51, 1.58s/it]
47%|████▋ | 29/62 [00:46<00:51, 1.58s/it]
48%|████▊ | 30/62 [00:47<00:50, 1.57s/it]
48%|████▊ | 30/62 [00:47<00:50, 1.57s/it]
50%|█████ | 31/62 [00:49<00:48, 1.57s/it]
50%|█████ | 31/62 [00:49<00:48, 1.57s/it]
52%|█████▏ | 32/62 [00:50<00:47, 1.57s/it]
52%|█████▏ | 32/62 [00:50<00:47, 1.57s/it]
53%|█████▎ | 33/62 [00:52<00:45, 1.57s/it]
53%|█████▎ | 33/62 [00:52<00:45, 1.57s/it]
55%|█████▍ | 34/62 [00:54<00:44, 1.58s/it]
55%|█████▍ | 34/62 [00:54<00:44, 1.58s/it]
56%|█████▋ | 35/62 [00:55<00:42, 1.59s/it]
56%|█████▋ | 35/62 [00:55<00:42, 1.59s/it]
58%|█████▊ | 36/62 [00:57<00:41, 1.60s/it]
58%|█████▊ | 36/62 [00:57<00:41, 1.60s/it]
60%|█████▉ | 37/62 [00:58<00:40, 1.60s/it]
60%|█████▉ | 37/62 [00:58<00:40, 1.60s/it]
61%|██████▏ | 38/62 [01:00<00:38, 1.60s/it]
61%|██████▏ | 38/62 [01:00<00:38, 1.60s/it]
63%|██████▎ | 39/62 [01:02<00:36, 1.61s/it]
63%|██████▎ | 39/62 [01:02<00:36, 1.61s/it]
65%|██████▍ | 40/62 [01:03<00:35, 1.61s/it]
65%|██████▍ | 40/62 [01:03<00:35, 1.61s/it]
66%|██████▌ | 41/62 [01:05<00:33, 1.61s/it]
66%|██████▌ | 41/62 [01:05<00:33, 1.61s/it]
68%|██████▊ | 42/62 [01:07<00:32, 1.62s/it]
68%|██████▊ | 42/62 [01:07<00:32, 1.62s/it]
69%|██████▉ | 43/62 [01:08<00:30, 1.61s/it]
69%|██████▉ | 43/62 [01:08<00:30, 1.61s/it]
71%|███████ | 44/62 [01:10<00:28, 1.61s/it]
71%|███████ | 44/62 [01:10<00:28, 1.61s/it]
73%|███████▎ | 45/62 [01:11<00:27, 1.60s/it]
73%|███████▎ | 45/62 [01:11<00:27, 1.60s/it]
74%|███████▍ | 46/62 [01:13<00:25, 1.60s/it]
74%|███████▍ | 46/62 [01:13<00:25, 1.60s/it]
76%|███████▌ | 47/62 [01:15<00:23, 1.60s/it]
76%|███████▌ | 47/62 [01:15<00:23, 1.60s/it]
77%|███████▋ | 48/62 [01:16<00:22, 1.59s/it]
77%|███████▋ | 48/62 [01:16<00:22, 1.59s/it]
79%|███████▉ | 49/62 [01:18<00:20, 1.60s/it]
79%|███████▉ | 49/62 [01:18<00:20, 1.60s/it]
81%|████████ | 50/62 [01:19<00:19, 1.59s/it]
81%|████████ | 50/62 [01:19<00:19, 1.59s/it]
82%|████████▏ | 51/62 [01:21<00:17, 1.59s/it]
82%|████████▏ | 51/62 [01:21<00:17, 1.59s/it]
84%|████████▍ | 52/62 [01:22<00:15, 1.59s/it]
84%|████████▍ | 52/62 [01:22<00:15, 1.59s/it]
85%|████████▌ | 53/62 [01:24<00:14, 1.59s/it]
85%|████████▌ | 53/62 [01:24<00:14, 1.59s/it]
87%|████████▋ | 54/62 [01:26<00:12, 1.59s/it]
87%|████████▋ | 54/62 [01:26<00:12, 1.59s/it]
89%|████████▊ | 55/62 [01:27<00:11, 1.59s/it]
89%|████████▊ | 55/62 [01:27<00:11, 1.59s/it]
90%|█████████ | 56/62 [01:29<00:09, 1.59s/it]
90%|█████████ | 56/62 [01:29<00:09, 1.59s/it]
92%|█████████▏| 57/62 [01:30<00:07, 1.59s/it]
92%|█████████▏| 57/62 [01:30<00:07, 1.59s/it]
94%|█████████▎| 58/62 [01:32<00:06, 1.59s/it]
94%|█████████▎| 58/62 [01:32<00:06, 1.59s/it]
95%|█████████▌| 59/62 [01:34<00:04, 1.59s/it]
95%|█████████▌| 59/62 [01:34<00:04, 1.59s/it]
97%|█████████▋| 60/62 [01:35<00:03, 1.59s/it]
97%|█████████▋| 60/62 [01:35<00:03, 1.59s/it]
98%|█████████▊| 61/62 [01:37<00:01, 1.59s/it]
98%|█████████▊| 61/62 [01:37<00:01, 1.59s/it]
100%|██████████| 62/62 [01:38<00:00, 1.59s/it]
100%|██████████| 62/62 [01:38<00:00, 1.59s/it]
100%|██████████| 62/62 [01:38<00:00, 1.59s/it]
100%|██████████| 62/62 [01:38<00:00, 1.60s/it]
/usr/local/lib/python3.10/dist-packages/peft/utils/save_and_load.py:154: UserWarning: Could not find a config file in /tmp/input_model/ - will assume that the vocabulary was not modified.
warnings.warn(
2024/07/28 09:50:43 INFO: Covert command: ['python', 'convert.py', '--model_name', '/tmp/input_model/', '--model_type', 'qwen2', '--output_dir', '/tmp/model/', '--adapter_dir', '/tmp/adapter/']
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
2024/07/28 09:50:59 INFO: execute command: mkdir -p /ml/output/model/adapter/
2024/07/28 09:50:59 INFO: execute command succeed
2024/07/28 09:50:59 INFO: execute command: cp -R /tmp/adapter/* /ml/output/model/adapter/
2024/07/28 09:51:04 INFO: execute command succeed
2024/07/28 09:51:04 INFO: execute command: cp -r /tmp/model/ /ml/output/
2024/07/28 09:51:08 INFO: execute command succeed
https://quickstart-20240728-g32t-1650087321066347.pai-eas.cn-hangzhou.aliyun.com/
编辑器zidong zon
https://pai.console.aliyun.com/?spm=a2c6h.13858378.0.0.5115764a3XjCDb
https://oss.console.aliyun.com/overview?spm=a2c6h.13858378.0.0.5115764a3XjCDb
编辑器总是自动跑道最下边。 也是#bug
监控 shouciyiyangma全面
全面自动总是元 删除
28 快删除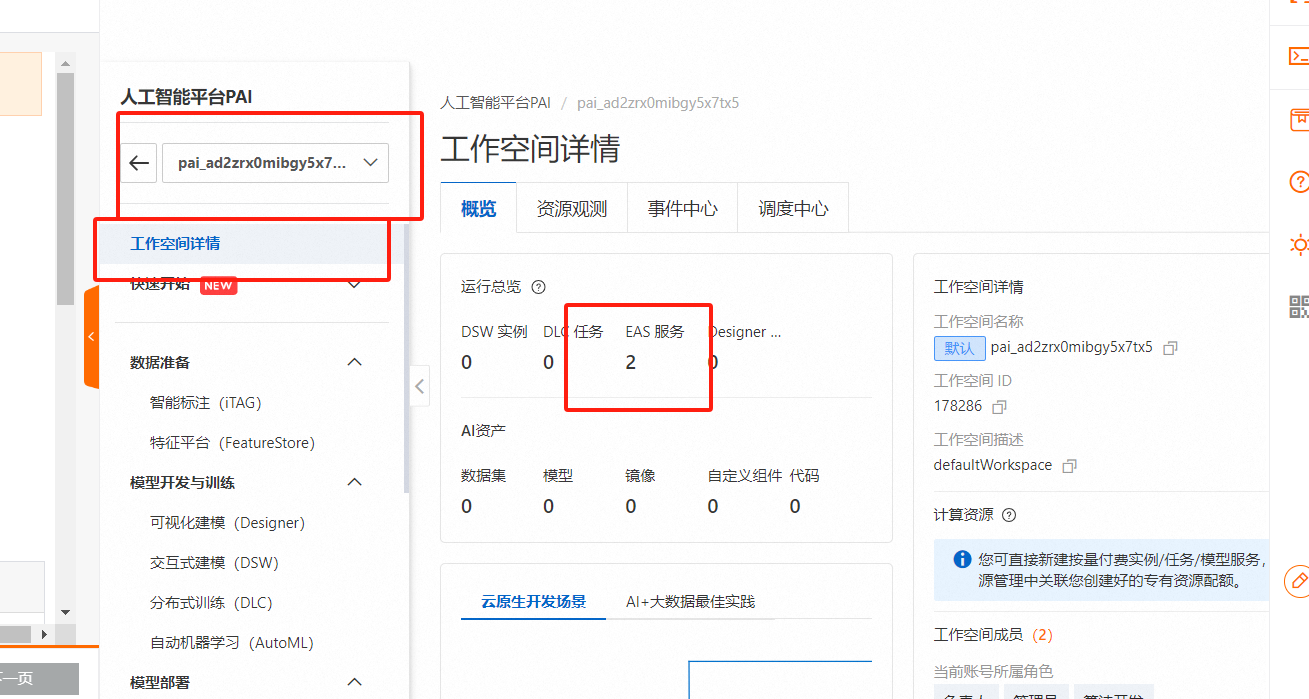
访问PAI-QuickStart平台:
https://developer.aliyun.com/adc/scenario/f2f81c8f883543528140e80f1ced3069
首先,我访问了阿里云PAI-QuickStart的官方页面,并登录了我的阿里云账号。在首页上,我能够清晰地看到各种预训练模型的分类,包括LLM(大语言模型)。
选择大语言模型:
在模型列表中,我选择了适合我需求的大语言模型。PAI-QuickStart提供了多种LLM模型供选择,包括但不限于BERT、GPT等。我根据项目的具体需求,选择了一个基于GPT的预训练模型。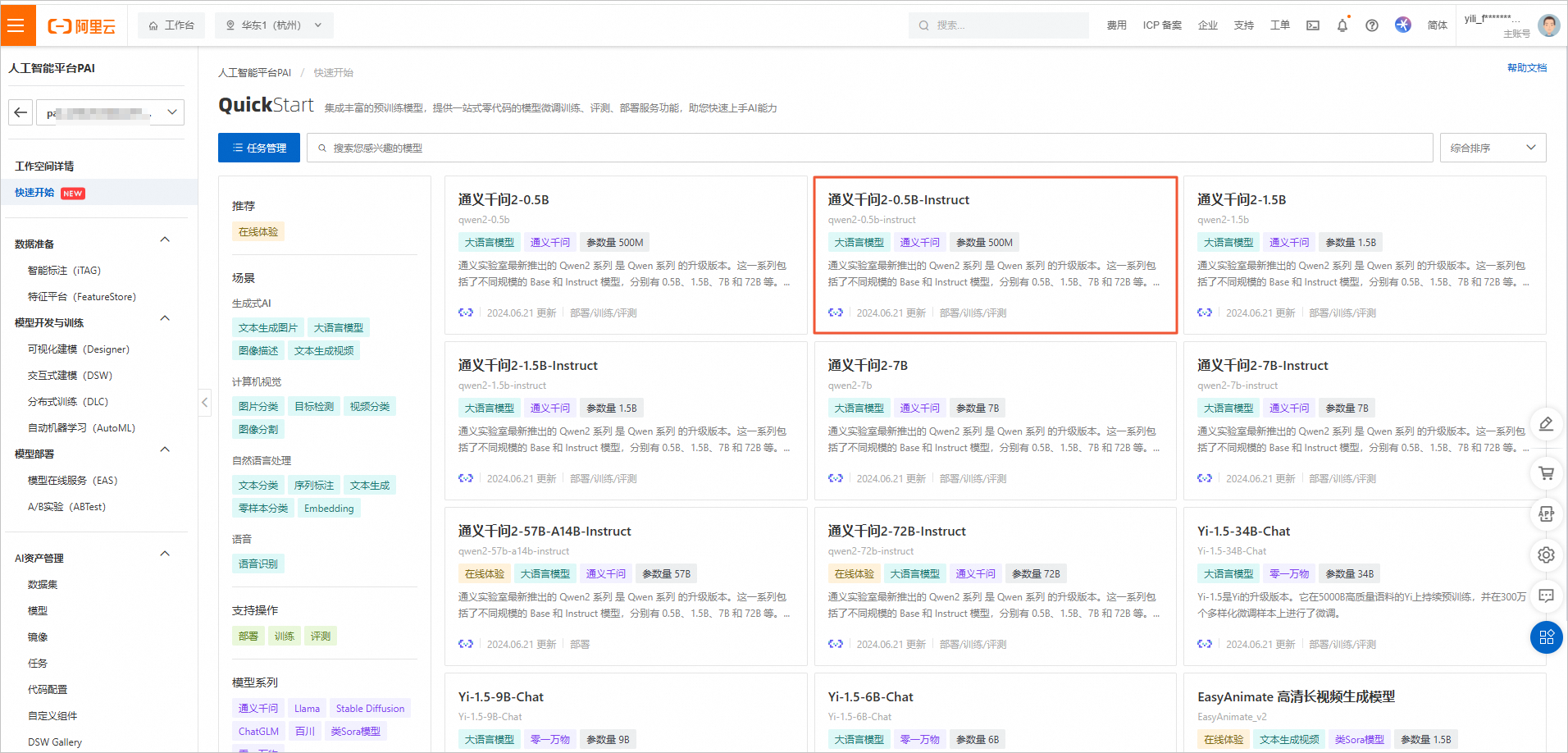
上传数据集:
为了对模型进行微调,我需要上传自己的数据集。PAI-QuickStart支持多种数据格式,我按照要求准备了文本数据集,并通过平台提供的上传功能将其上传至指定位置。
配置微调参数:
在微调前,我需要对一些关键参数进行配置,如学习率、训练轮次、批处理大小等。PAI-QuickStart提供了直观的界面让我可以轻松设置这些参数,无需编写复杂的代码。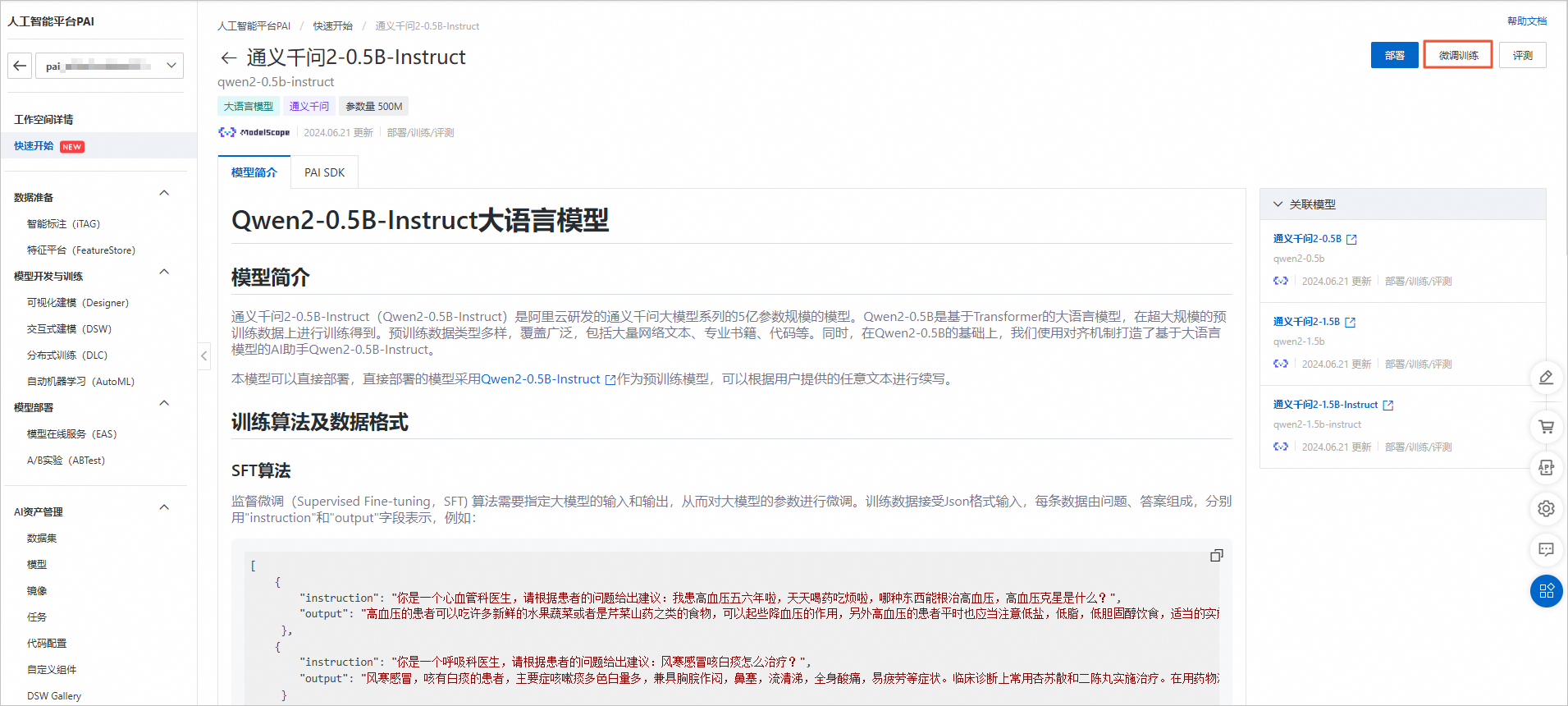
启动微调训练:
配置完成后,我点击了“开始训练”按钮。PAI-QuickStart随即开始利用我的数据集对所选的大语言模型进行微调训练。训练过程中,我可以实时查看训练日志和进度。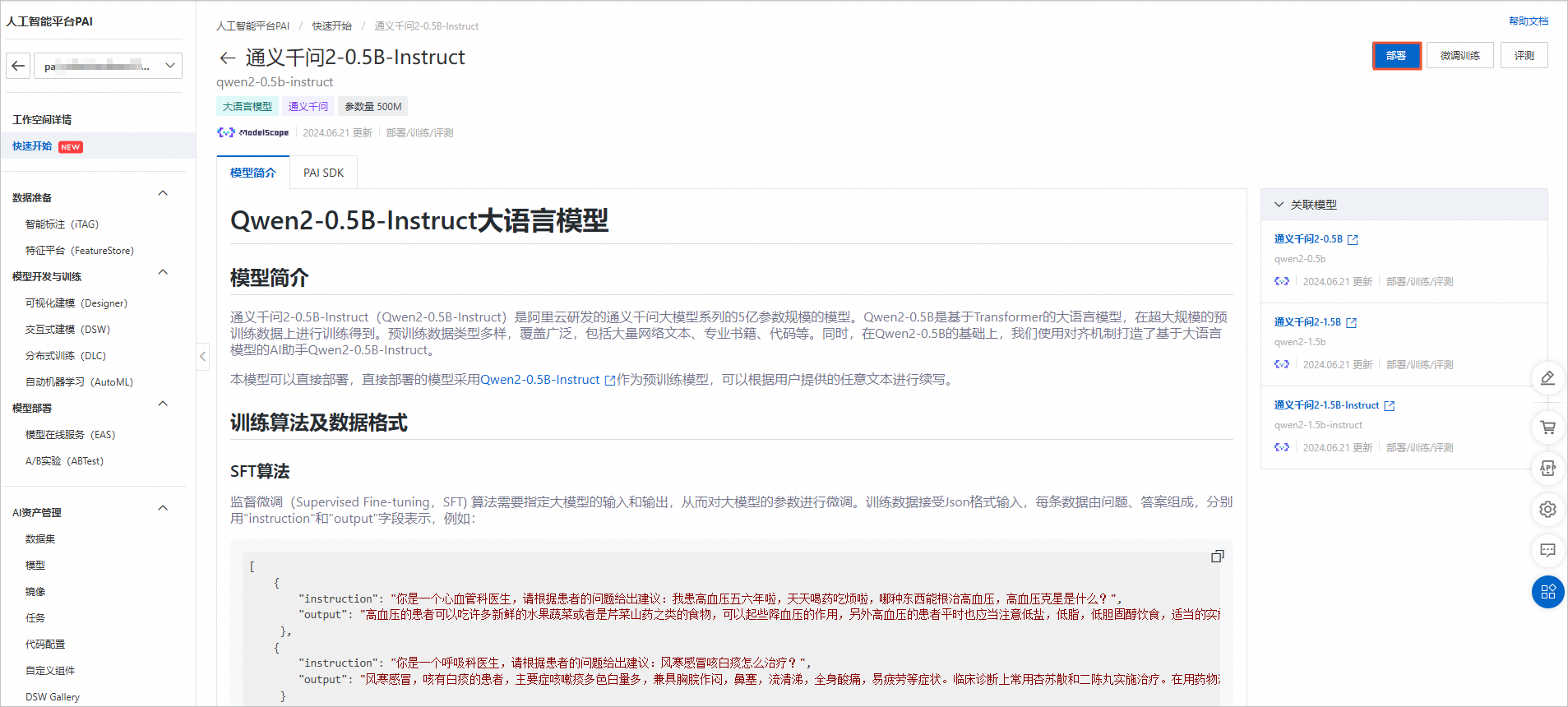
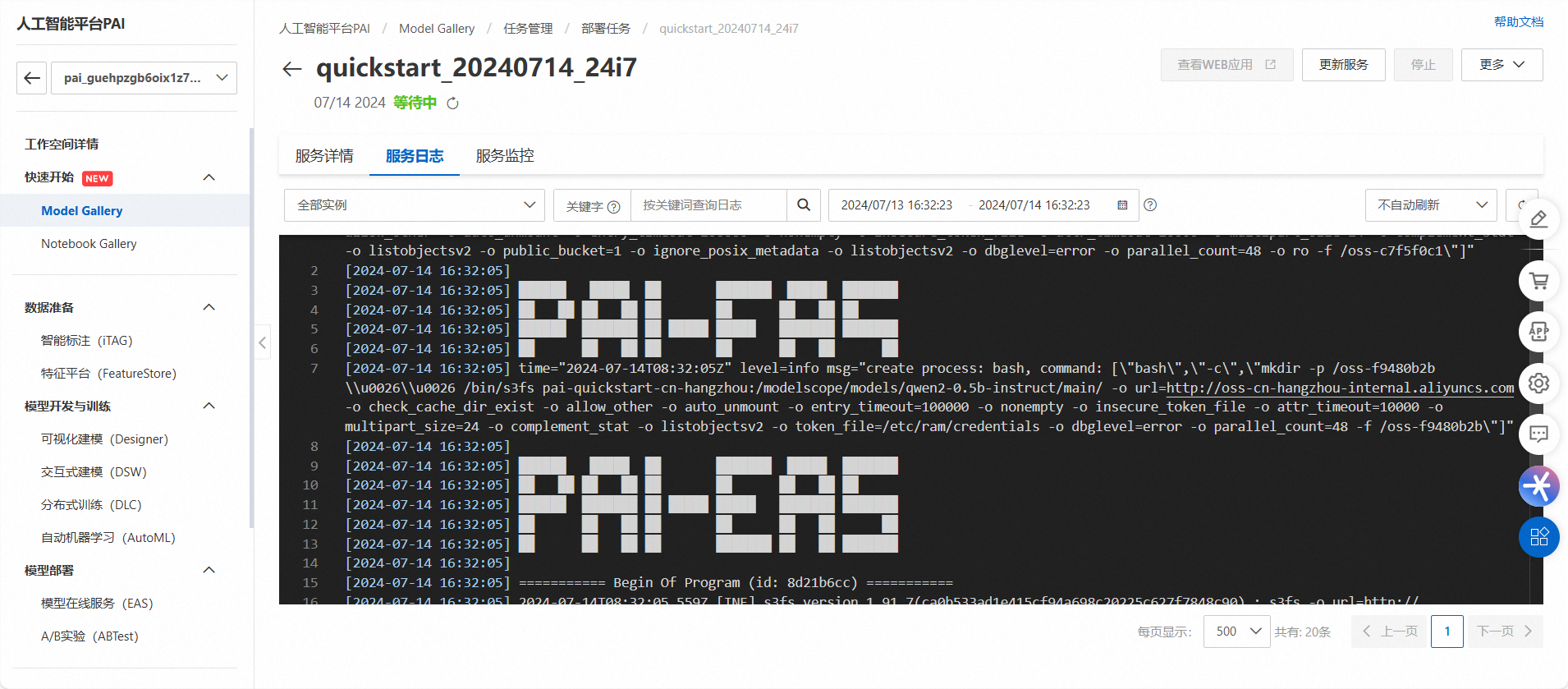
部署模型:
微调训练完成后,我通过PAI-QuickStart提供的一键部署功能,将训练好的模型部署为在线服务。这样,我就可以通过API接口调用该模型进行文本生成、问答等任务了。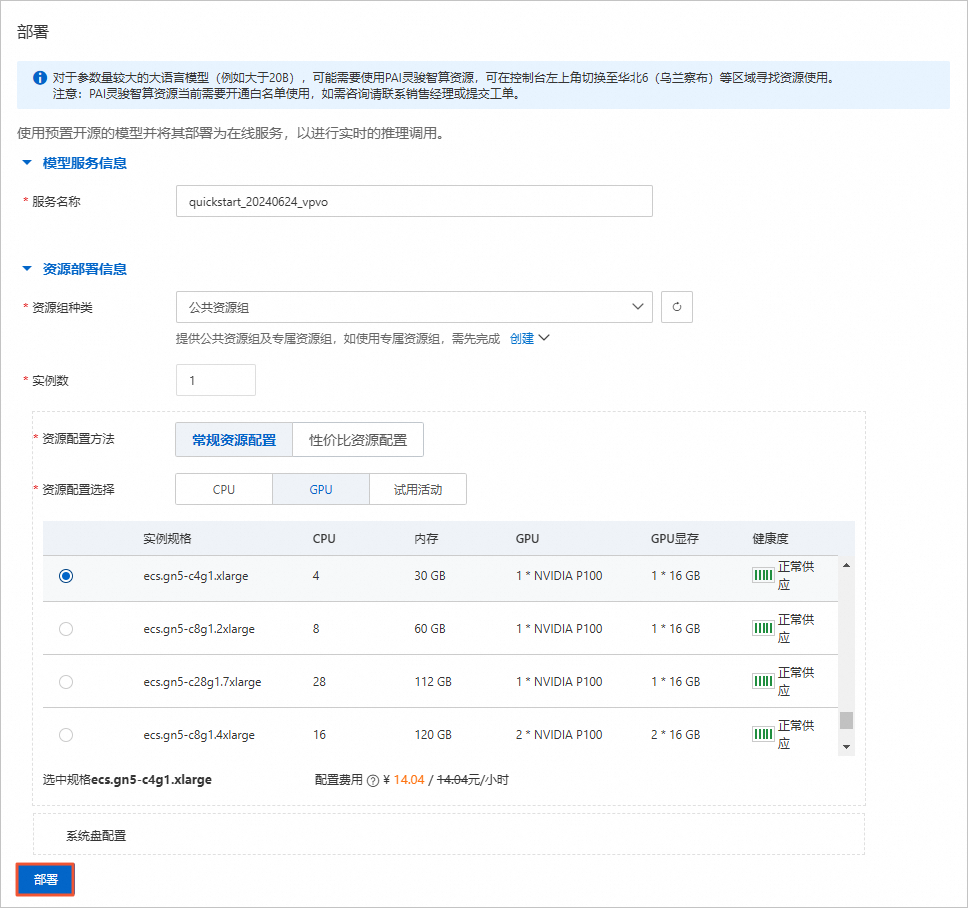
输出结果:
训练日志:在训练过程中,我能够查看到详细的训练日志,包括每轮训练的损失值、准确率等关键指标。
模型评估报告:训练完成后,PAI-QuickStart生成了模型评估报告,展示了模型在测试集上的性能表现。
在线服务:部署成功后,我获得了模型的API接口地址和调用方式。通过调用该接口,我能够实时获取模型处理文本的结果。
使用体验: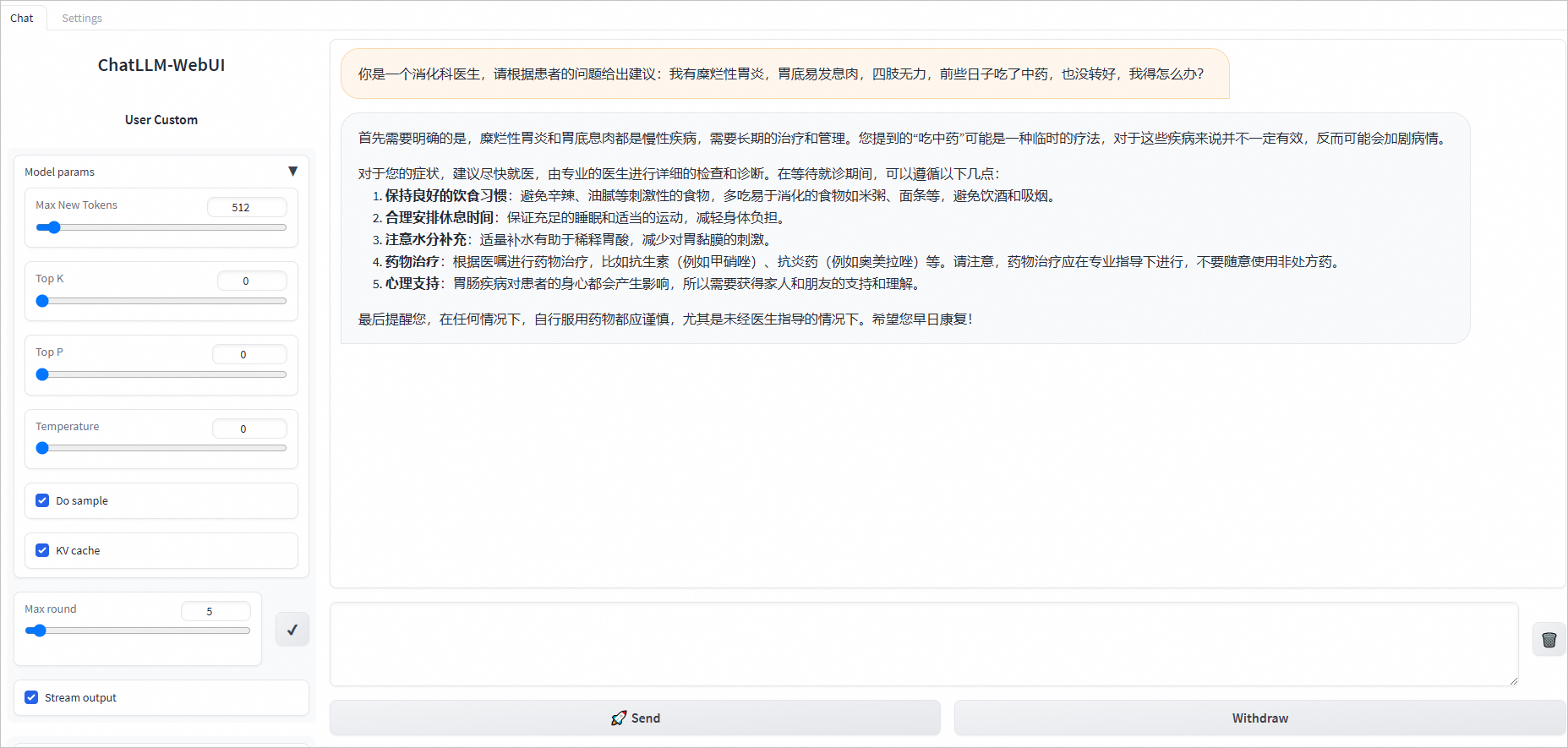


使用PAI-QuickStart进行大语言模型的微调和部署过程非常便捷和高效。平台提供的零代码操作让我无需具备深厚的AI技术背景也能轻松上手。此外,PAI-QuickStart的实时训练日志和模型评估报告功能也让我能够清晰地了解模型的训练情况和性能表现。总的来说,PAI-QuickStart是一款非常适合AI初学者和快速原型开发者的工具,它极大地降低了AI应用的门槛和成本。
其实对于部署来说,阿里云实验室的部署步骤总是很详尽,这样带来的结果就是即使你是PAI平台操作小白,你也可以很轻松的实现你想要部署并达到的效果,这就是阿里云实验室的贴心。下面我们来操作部署一下今天的主角,部署地址:https://developer.aliyun.com/adc/scenario/f2f81c8f883543528140e80f1ced3069?
开始正式部署,我们点击上面提供的实验室部署地址打开操作页面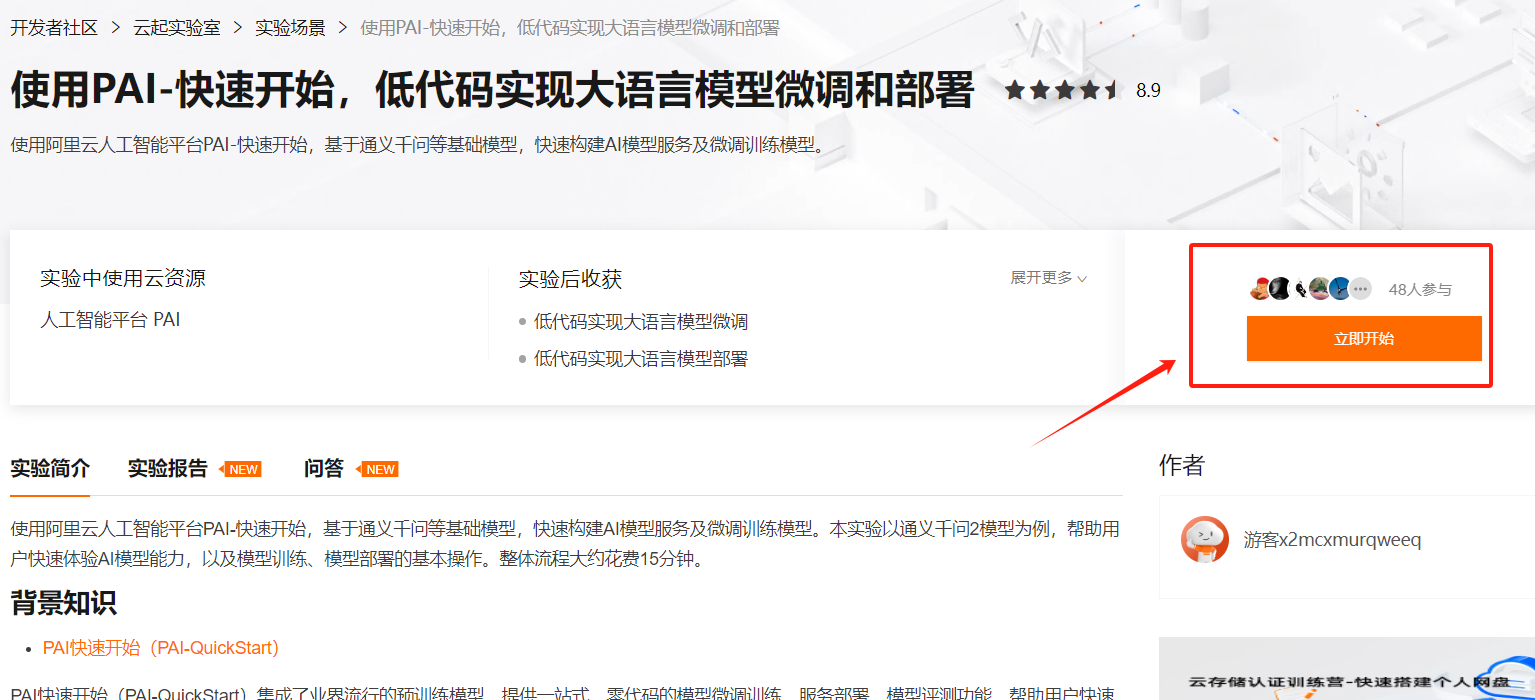
点击【立即开始】,默认选择个人账号资源,点击【确认开启实验】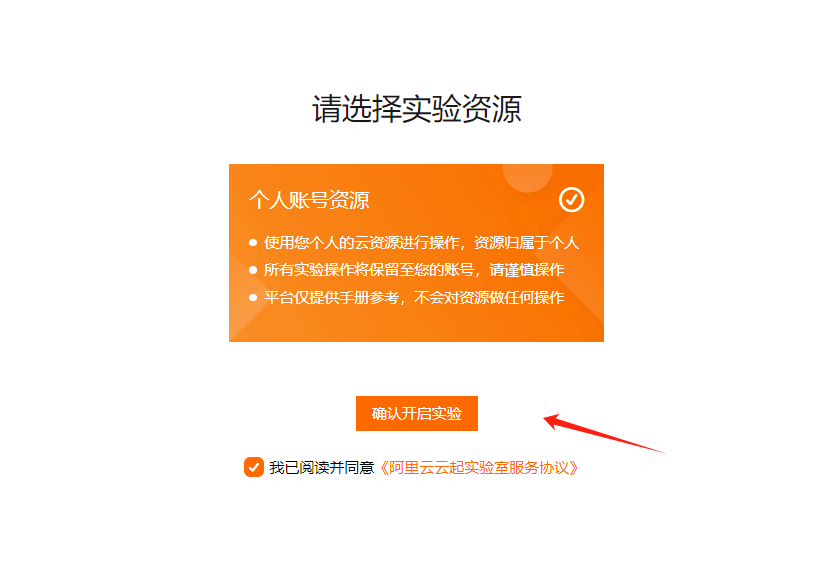
点击【人工智能平台PAI】或者直接打开PAI控制台地址:https://pai.console.aliyun.com/?spm=a2c6h.13858378.0.0.73c8764ajE5TZP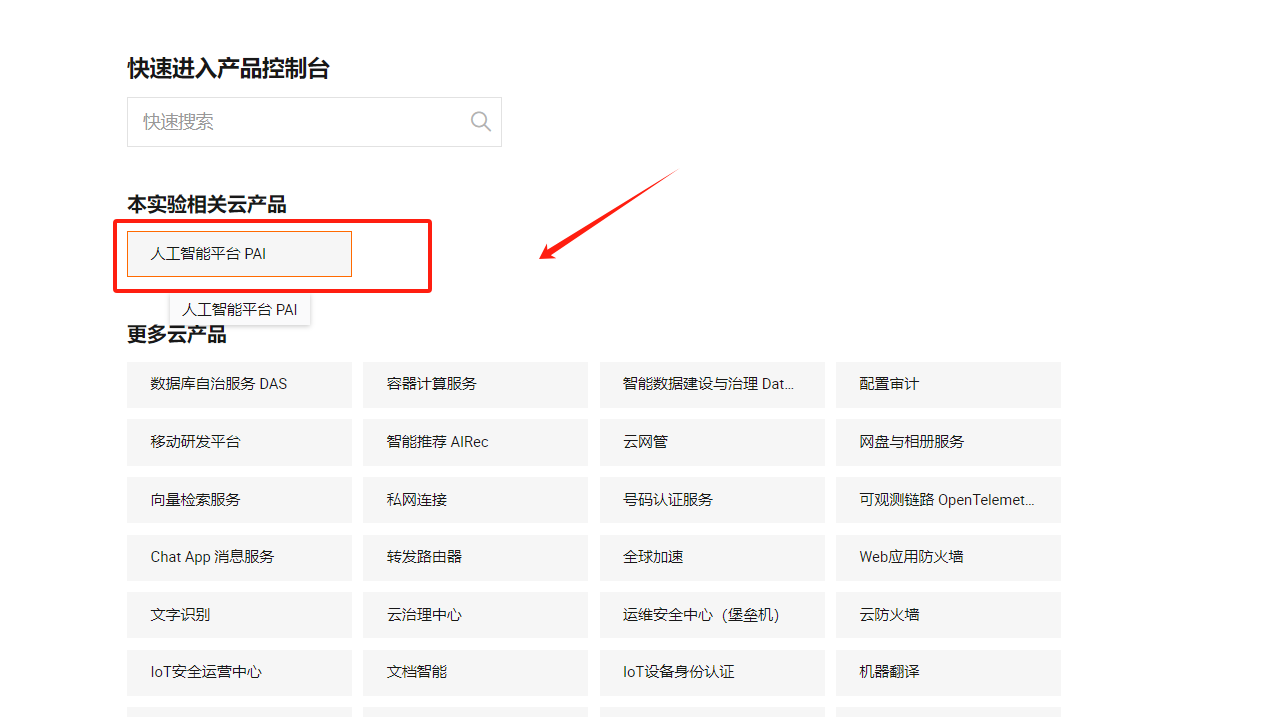
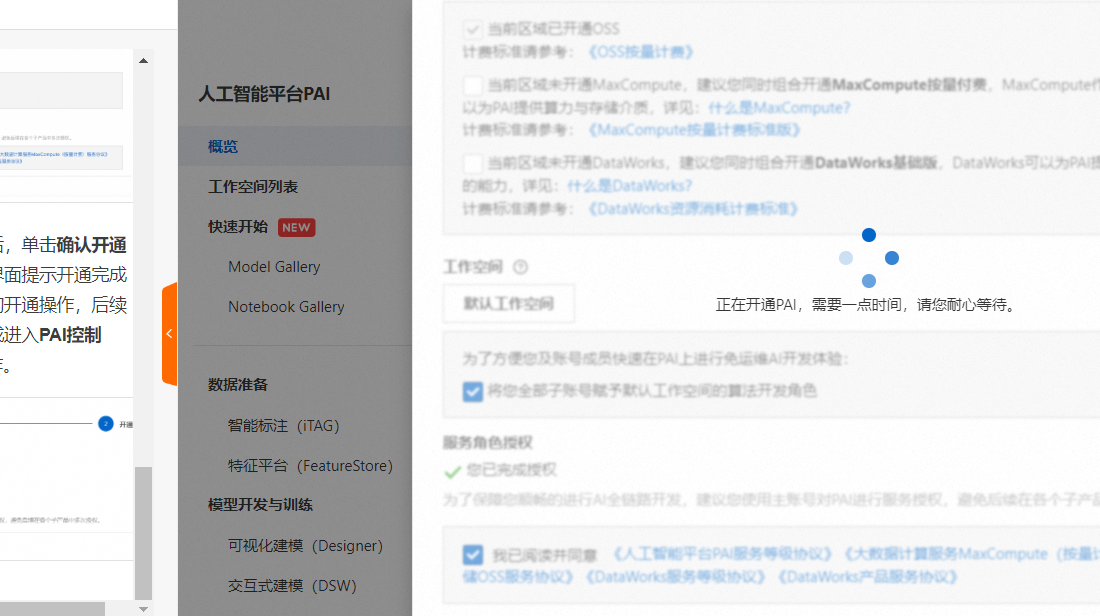
如果没有创建过默认工作空间,是这样的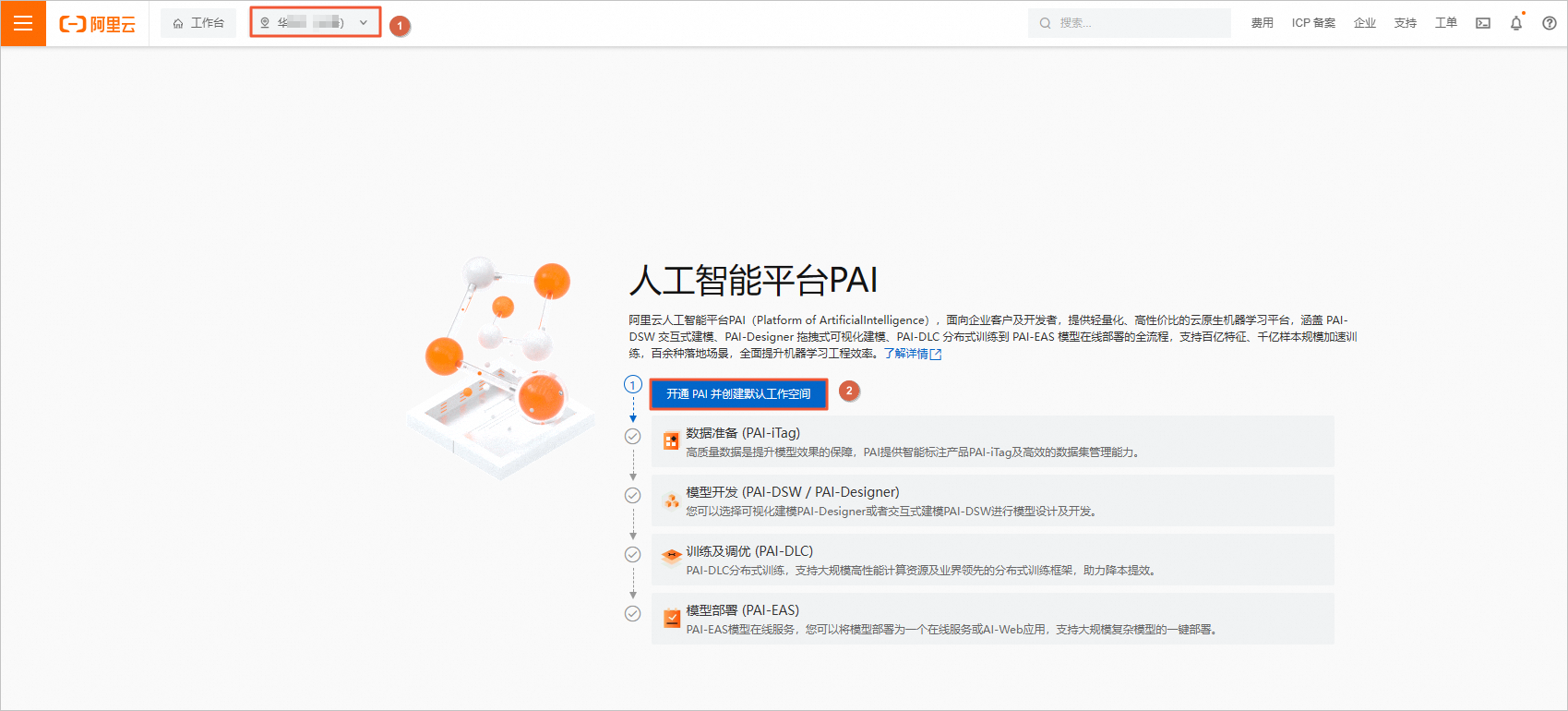
您可以选择需要开通的地域后,单击页面中间的【开通PAI并创建默认工作空间】配置开通参数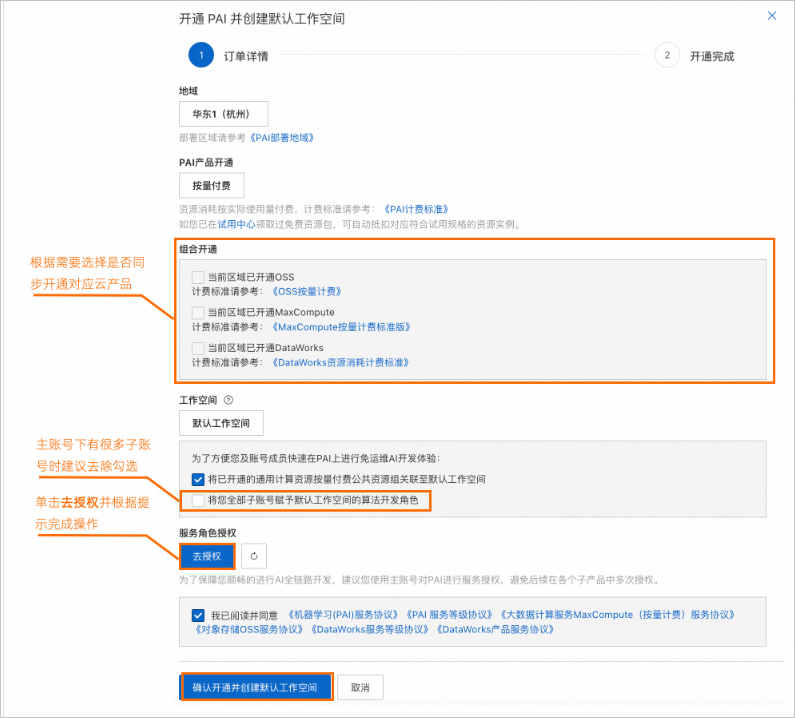
确认相关信息并完成配置后,单击【确认开通并创建默认工作空间】,当界面提示开通完成后,您即完成在当前地域的开通操作。我的账号已经开通过默认工作空间,那么我直接点击【工作空间列表】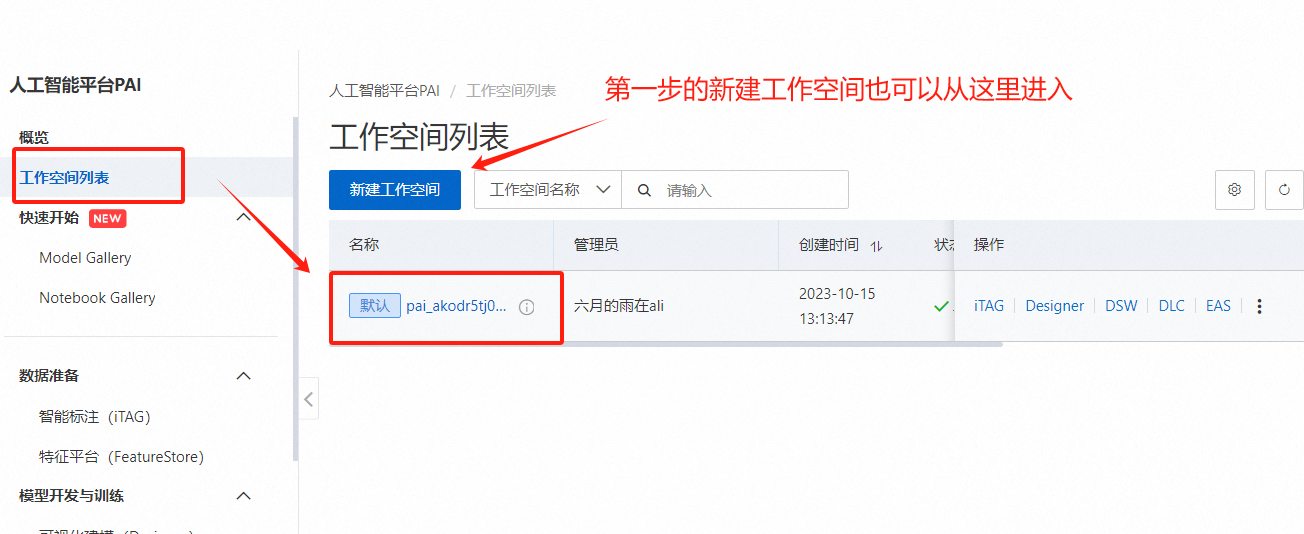
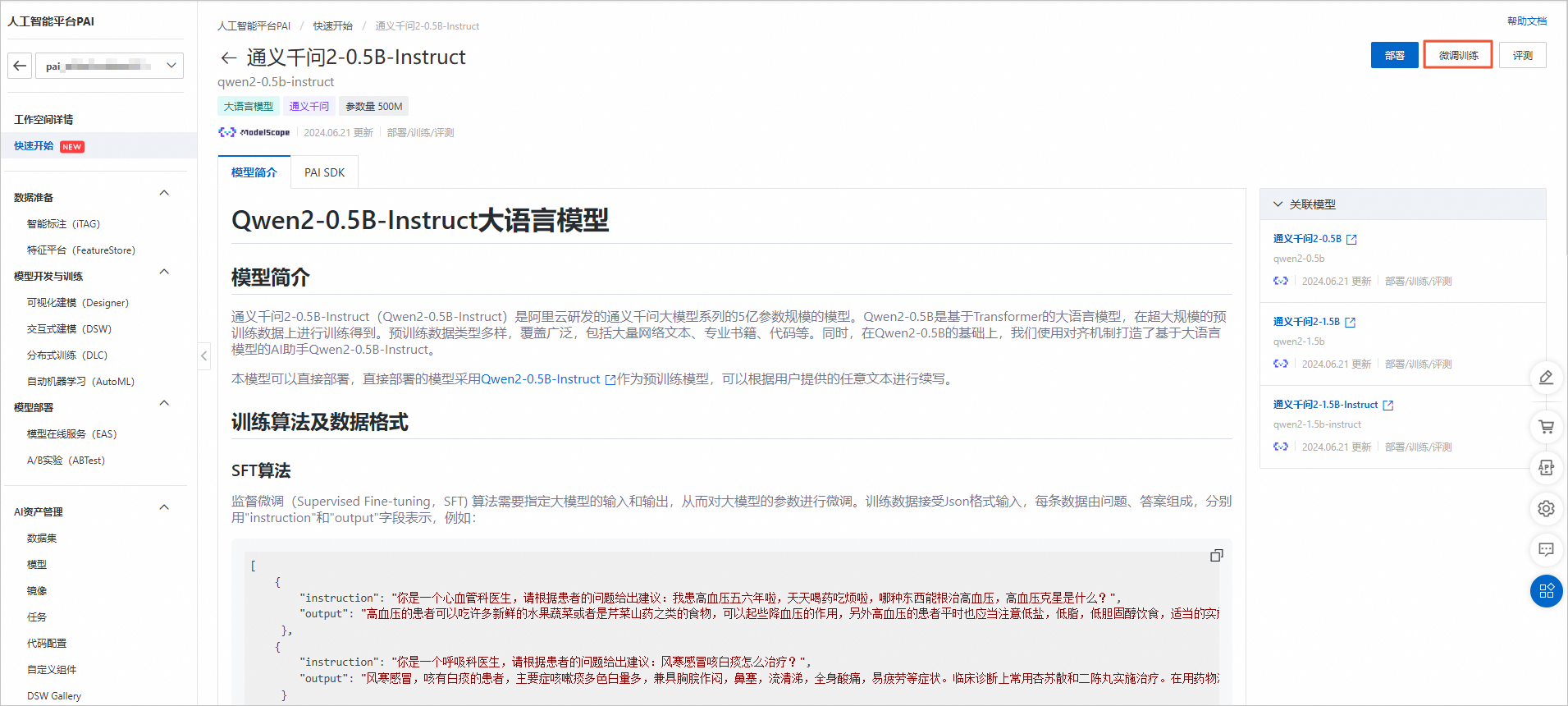
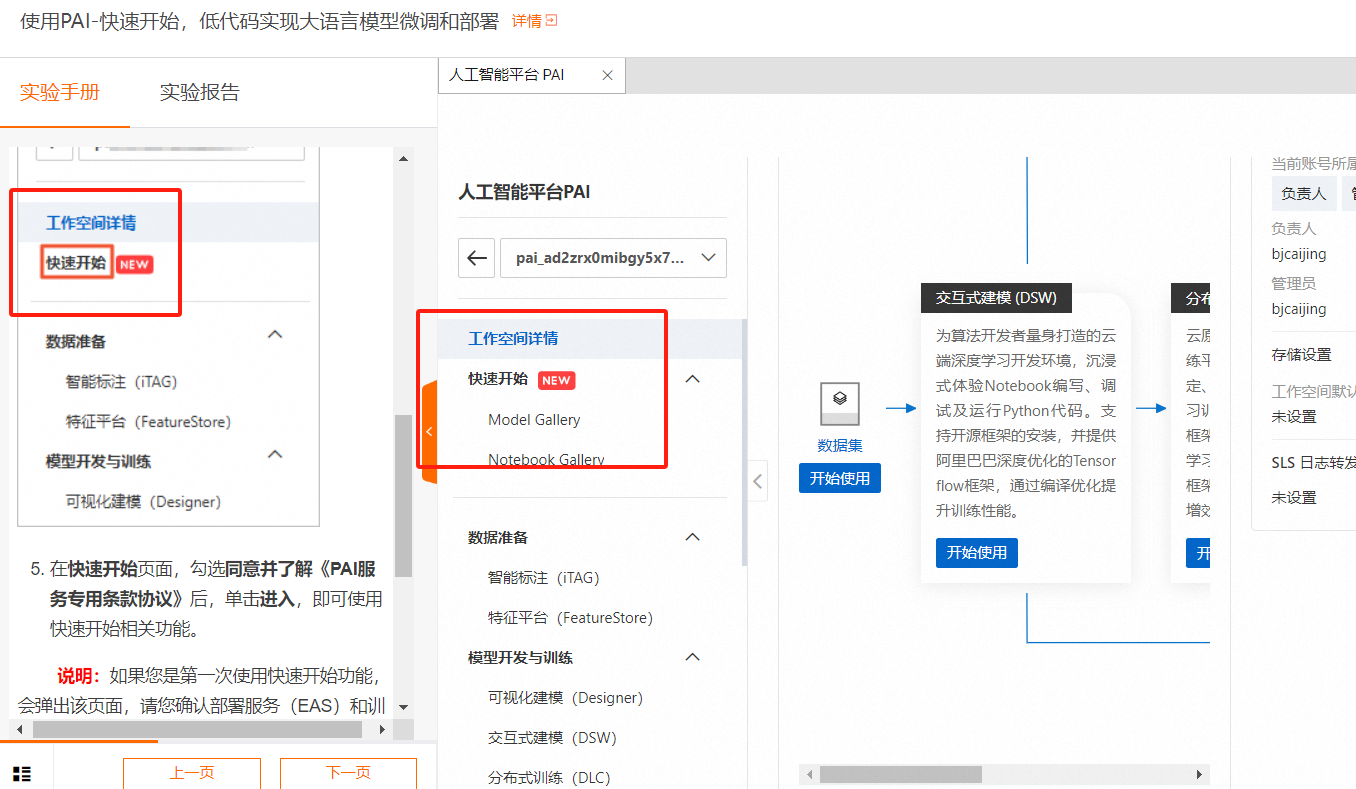
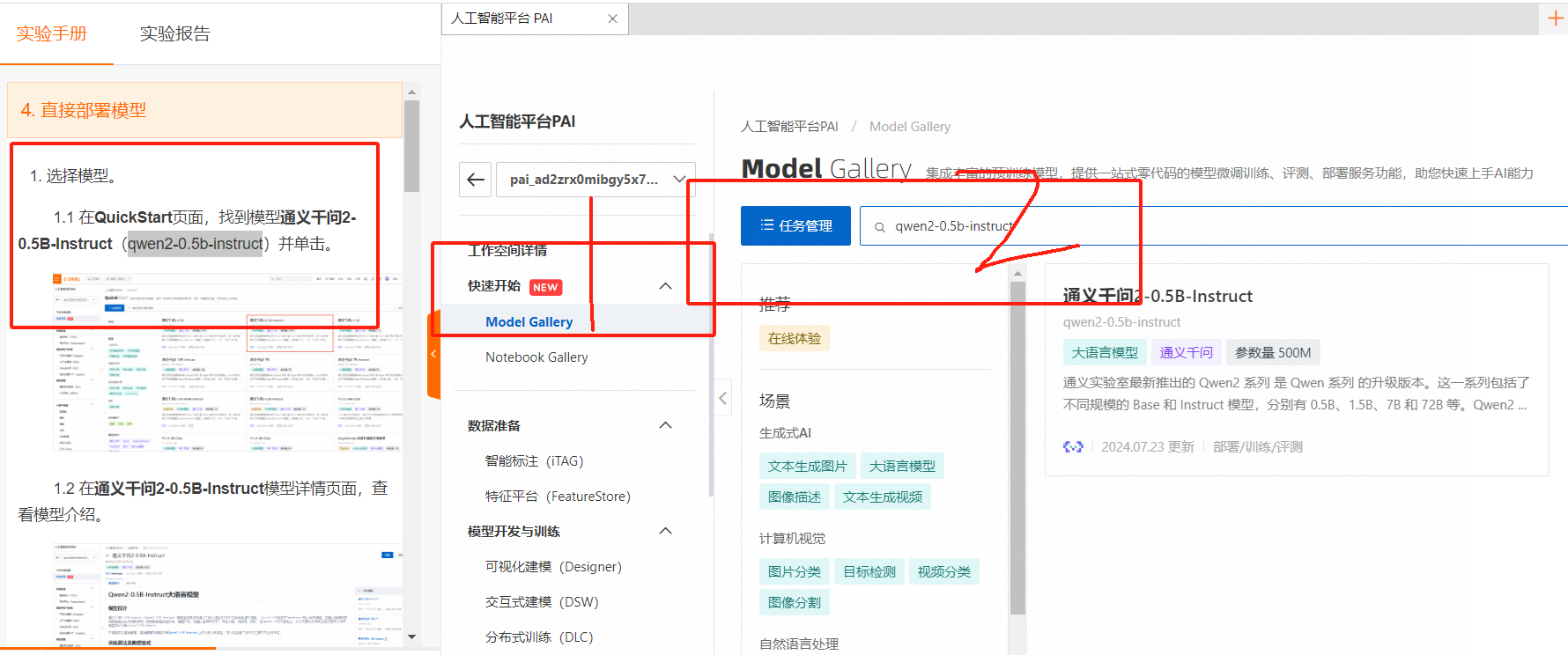
点击工作空间名称,进入工作空间详情,点击【快速开始】-【Model Gallery】在搜索框输入【qwen2-0.5b-instruct】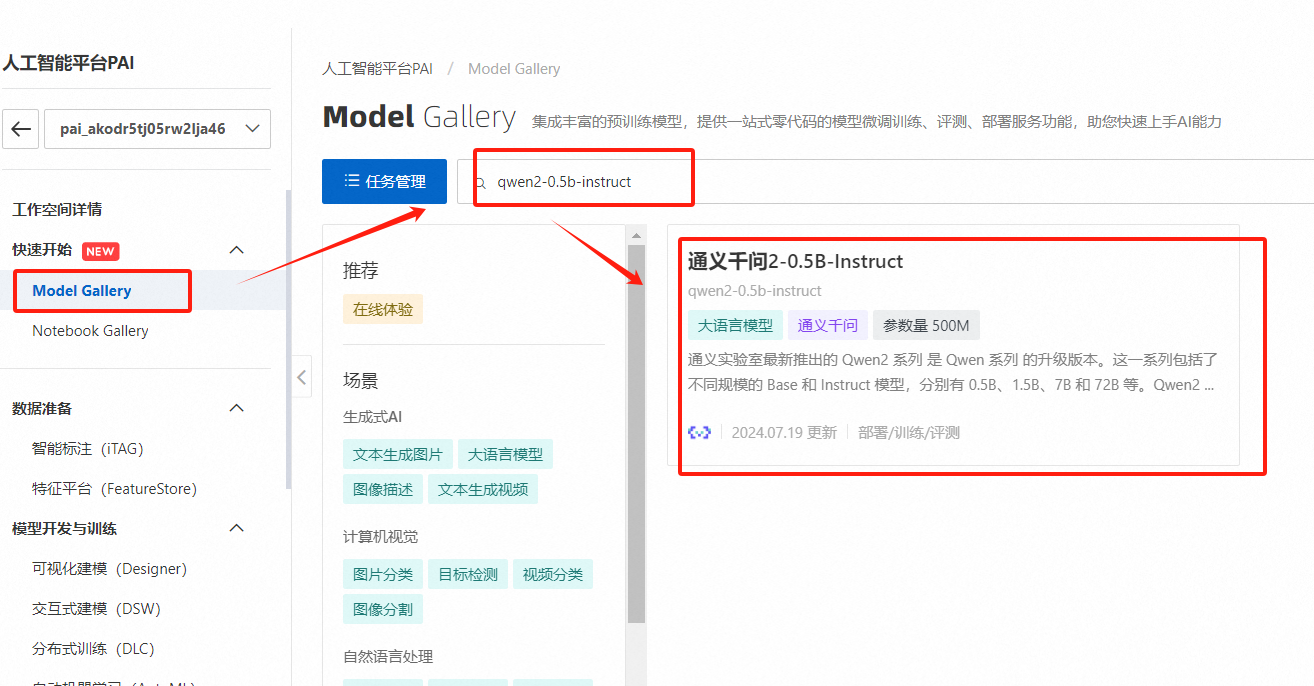
点击模型名称【通义千问2-0.5B-Instruct】进入模型详情页面查看详情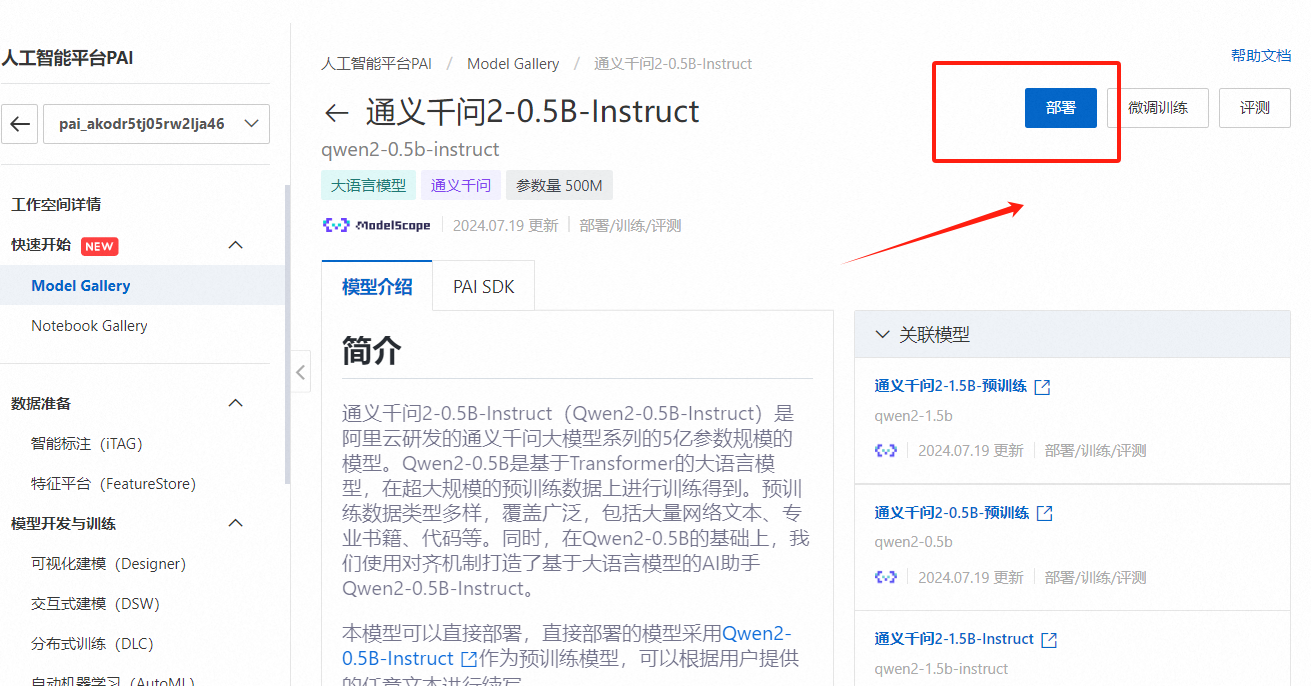
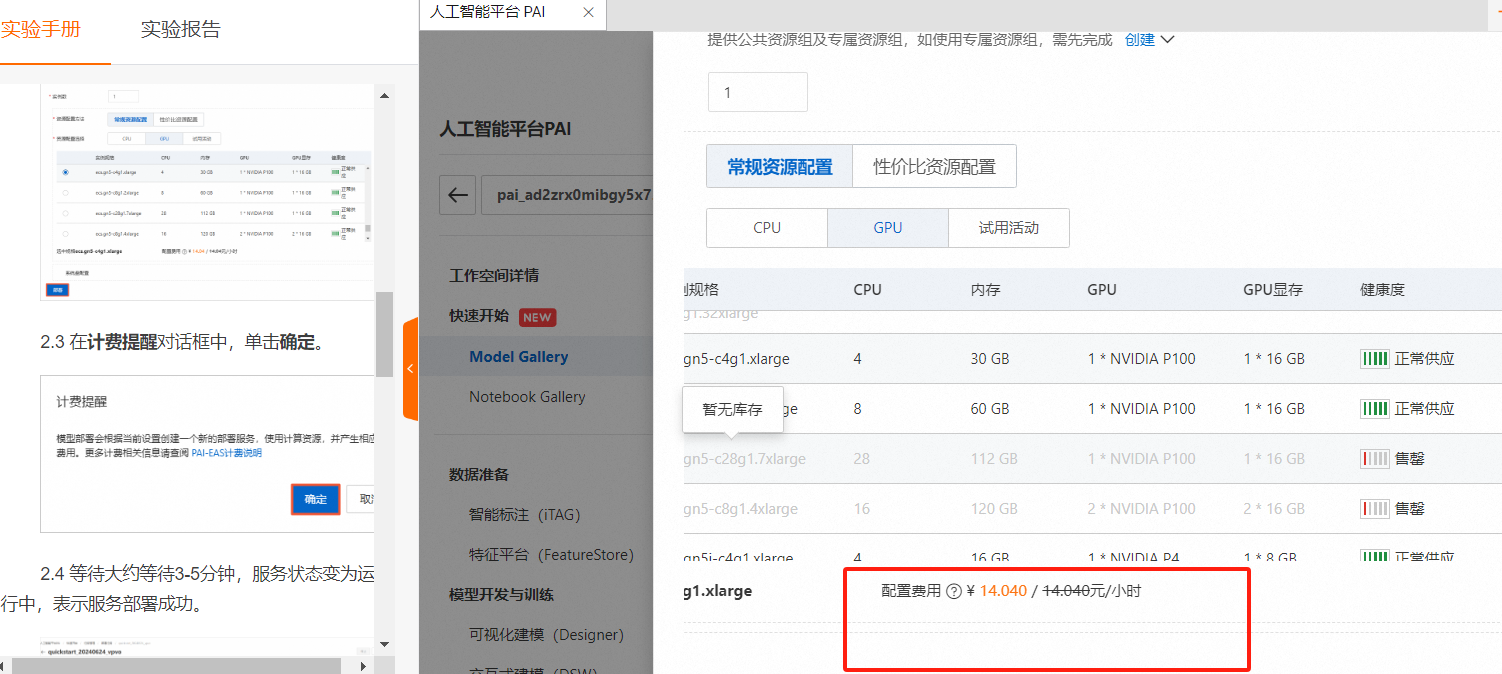
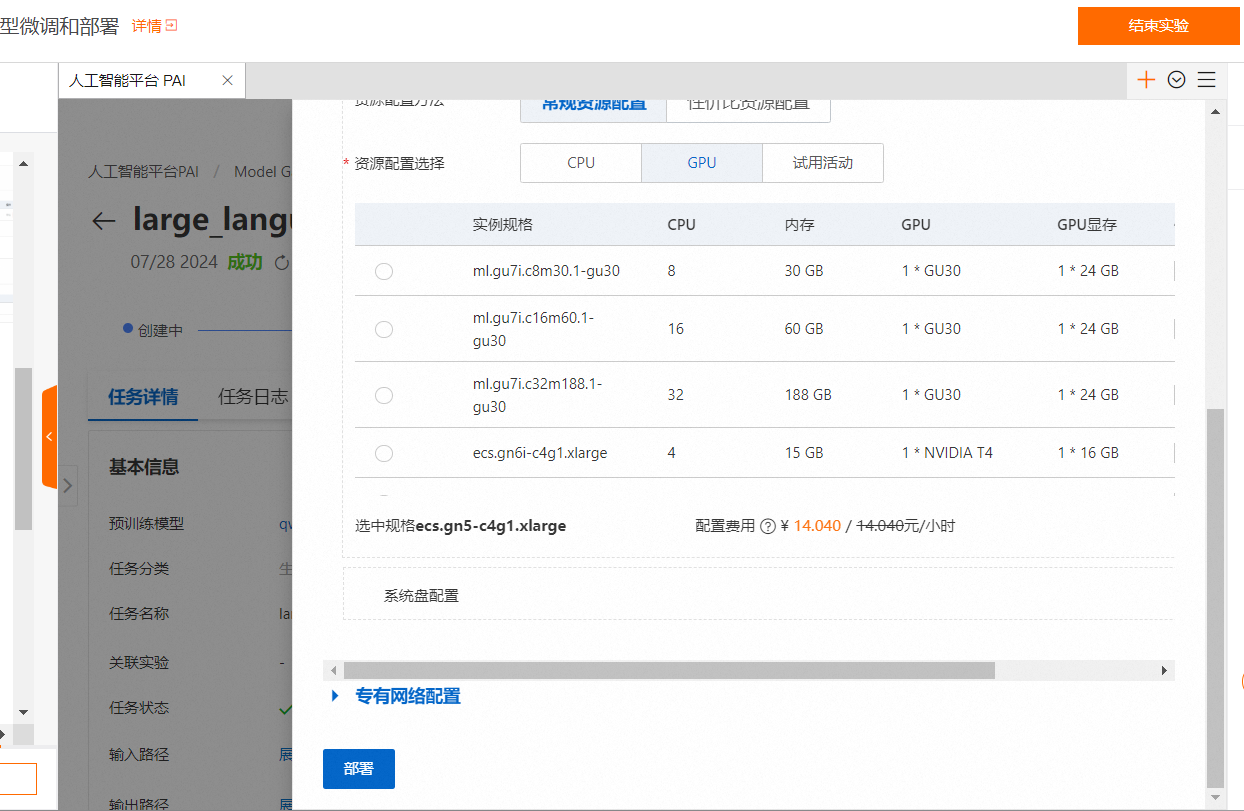
单击右上角的【部署】按钮,在部署面板,配置保持默认即可,单击【部署】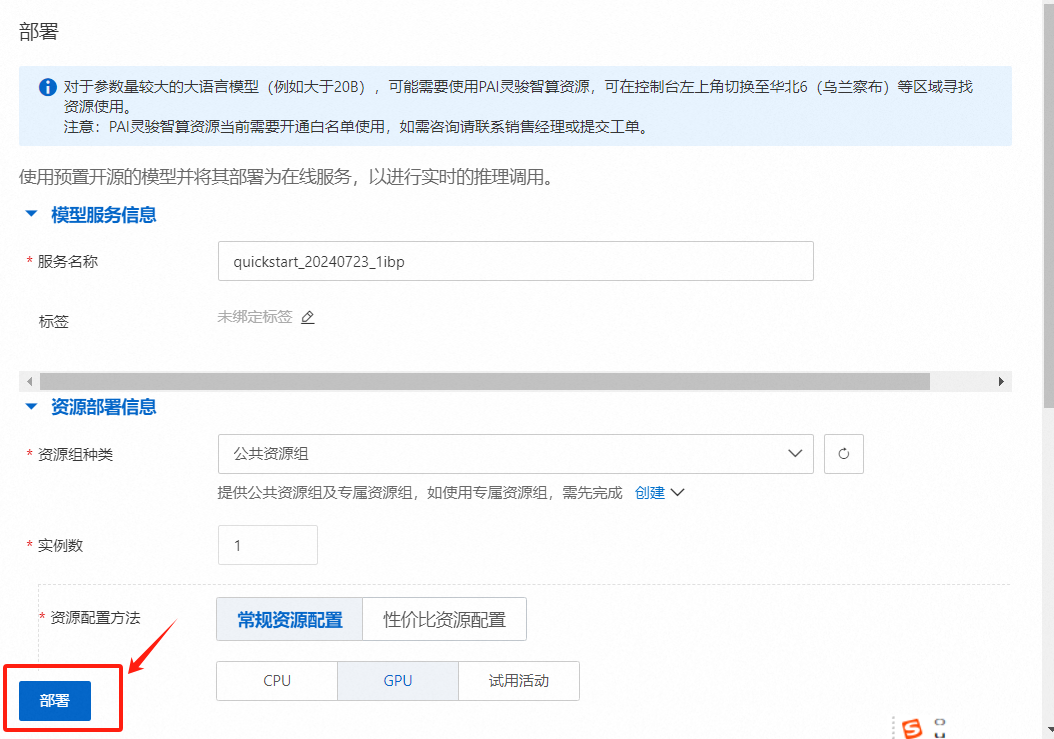
在弹出的计费提醒,点击【确定】
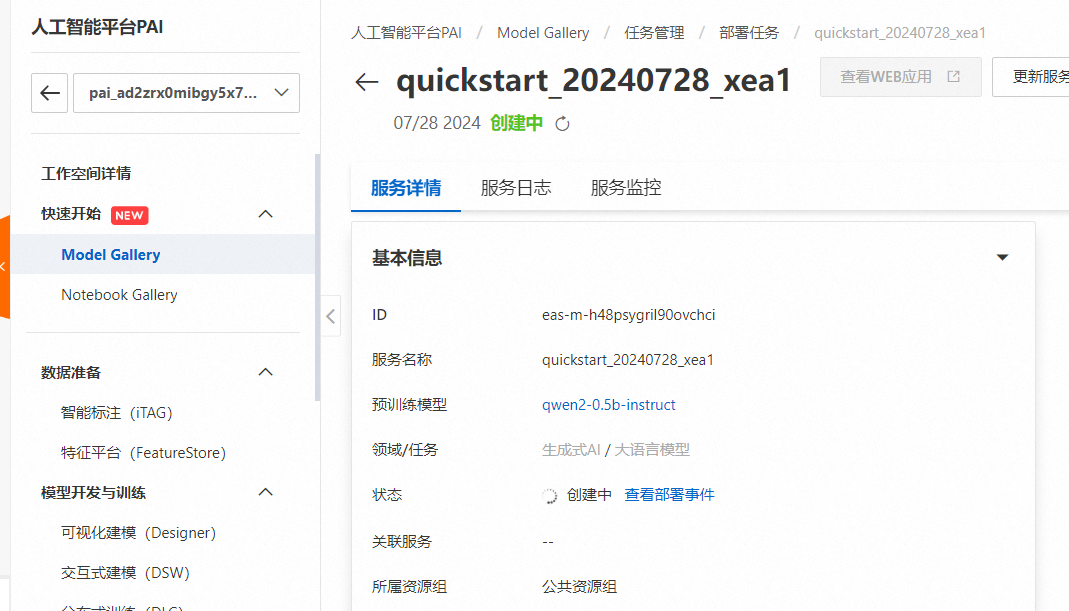
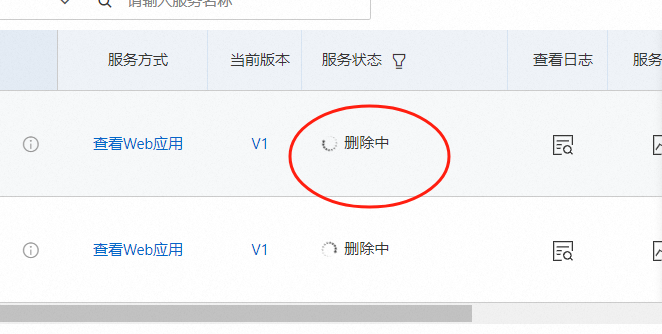
服务创建中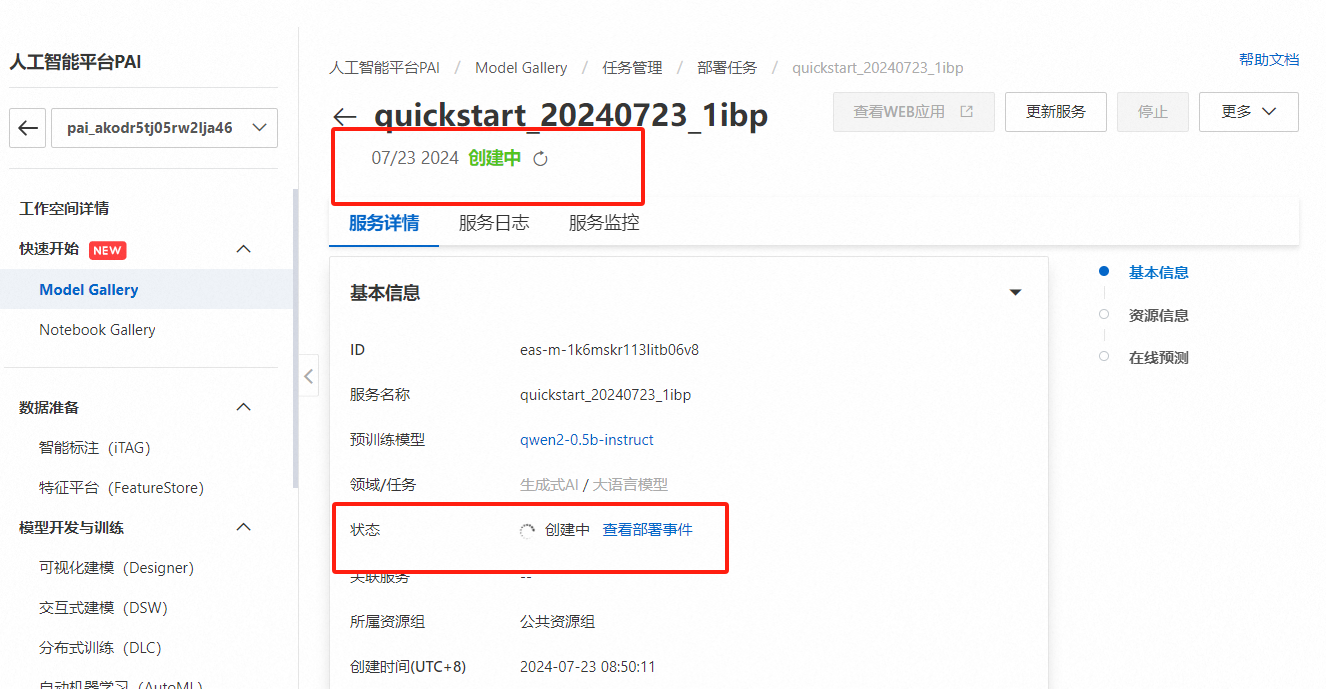
等待大约等待3-5分钟,服务状态变为运行中,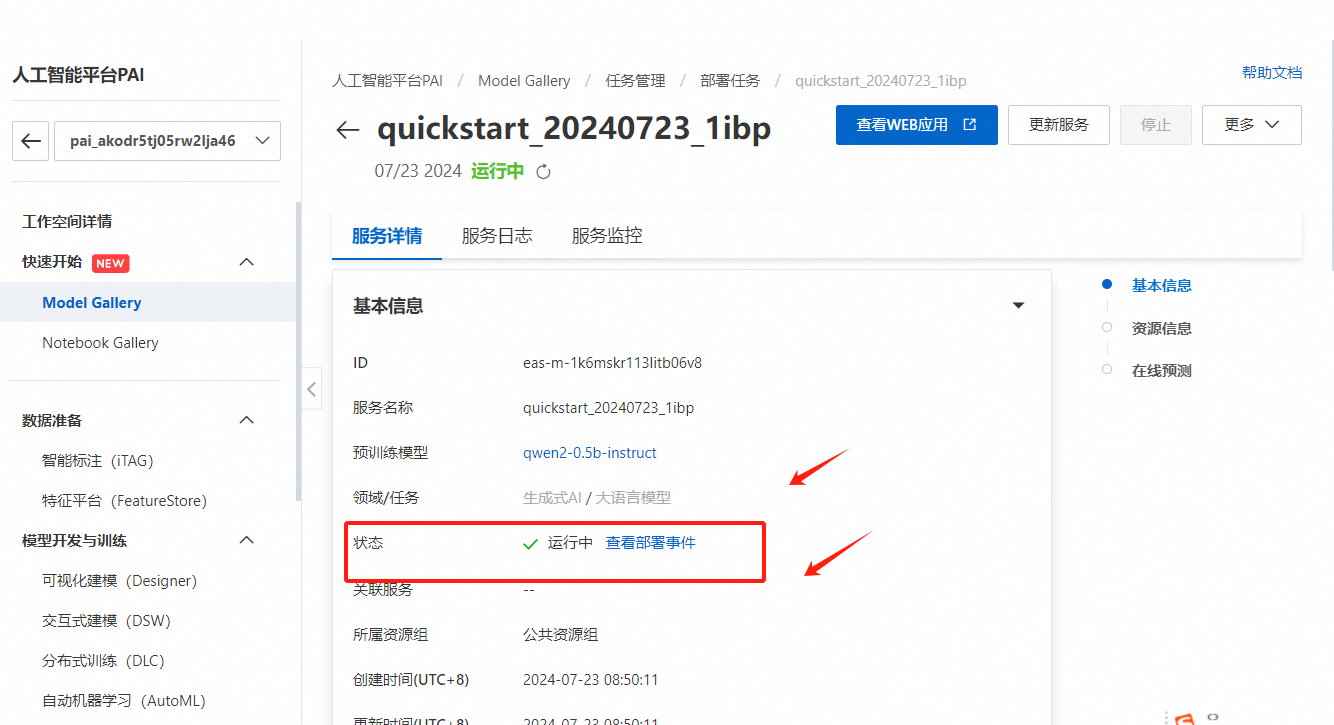
服务部署完成后,单击【查看WEB应用】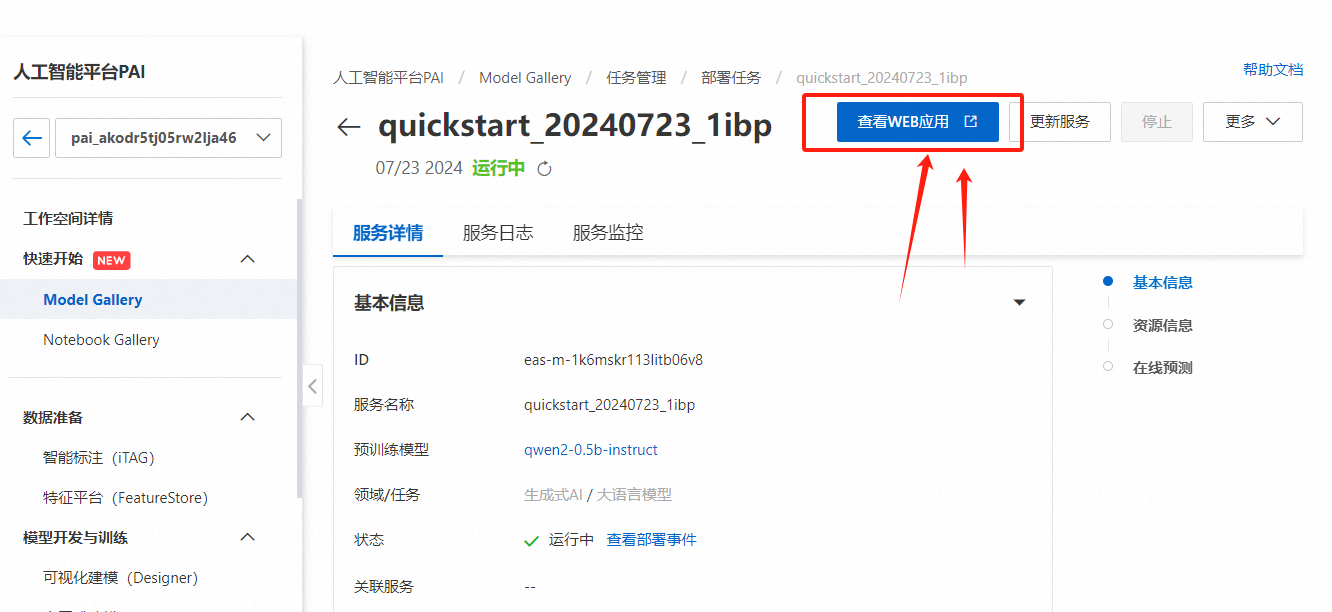
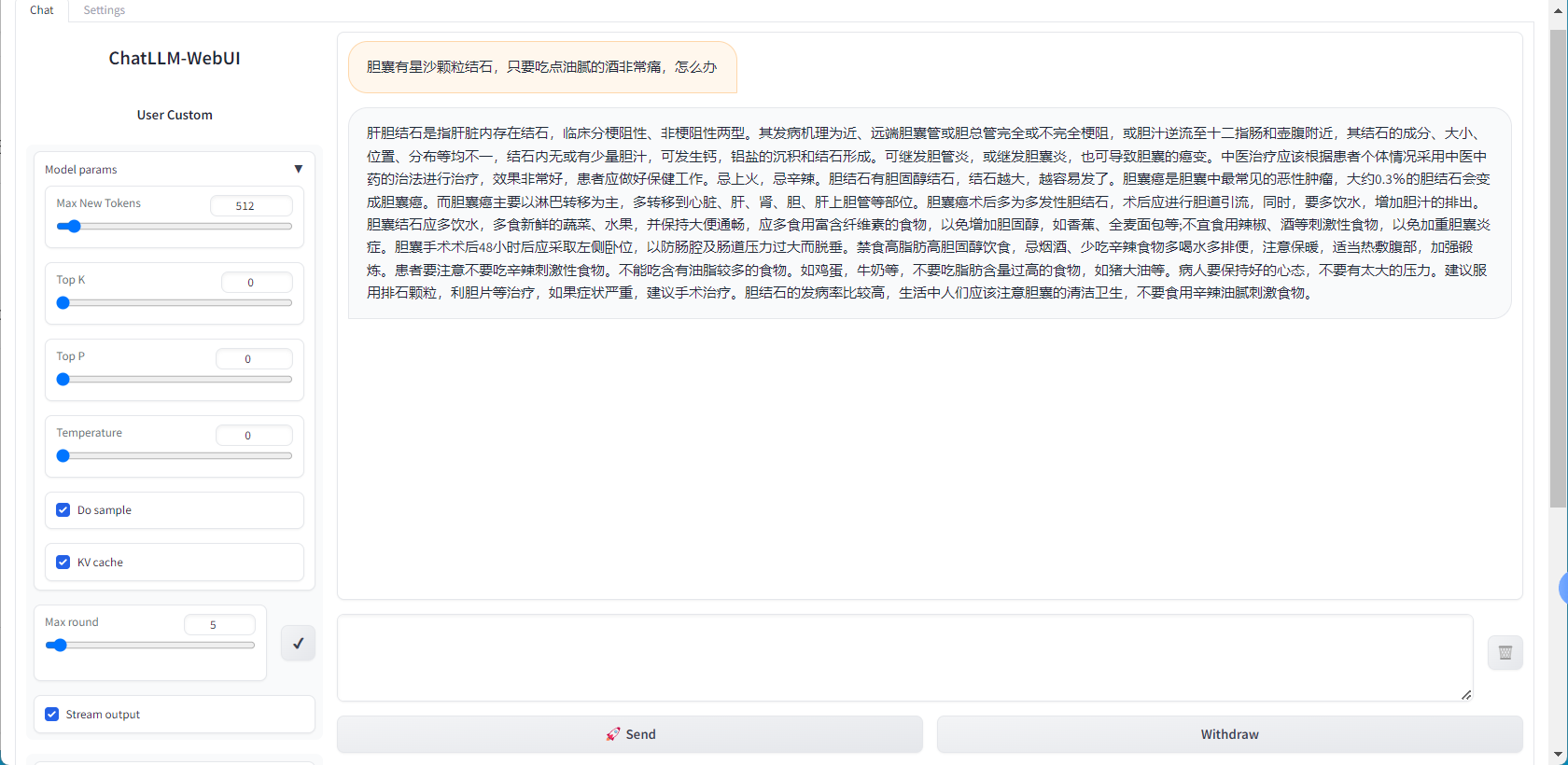
进入在线测试页面,输入关键词信息【从中医角度分析 嗓子疼如何调养呢】
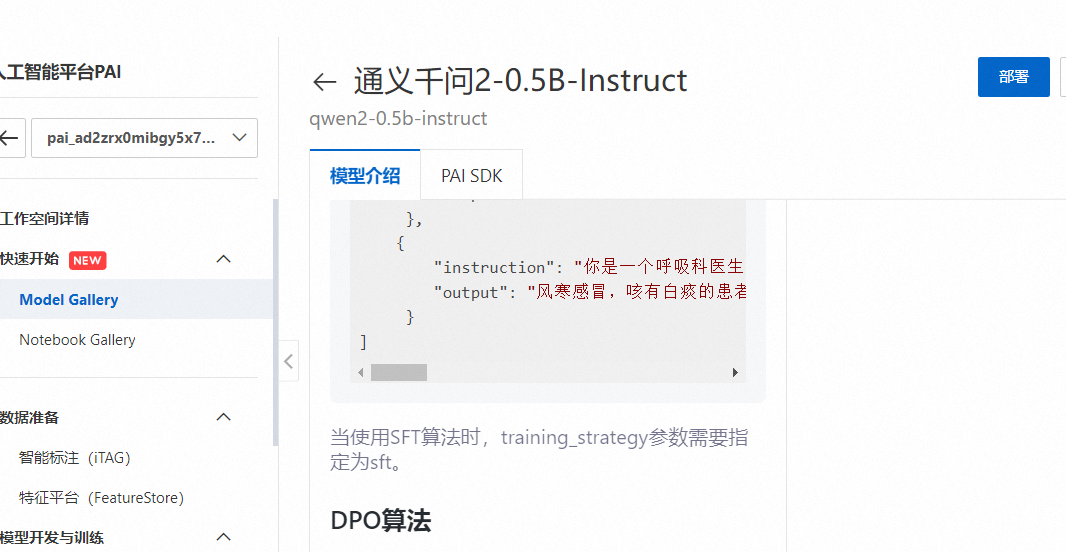
当然如果你有自己的数据,也可以选择【微调训练】,具体的操作按照文档操作就行。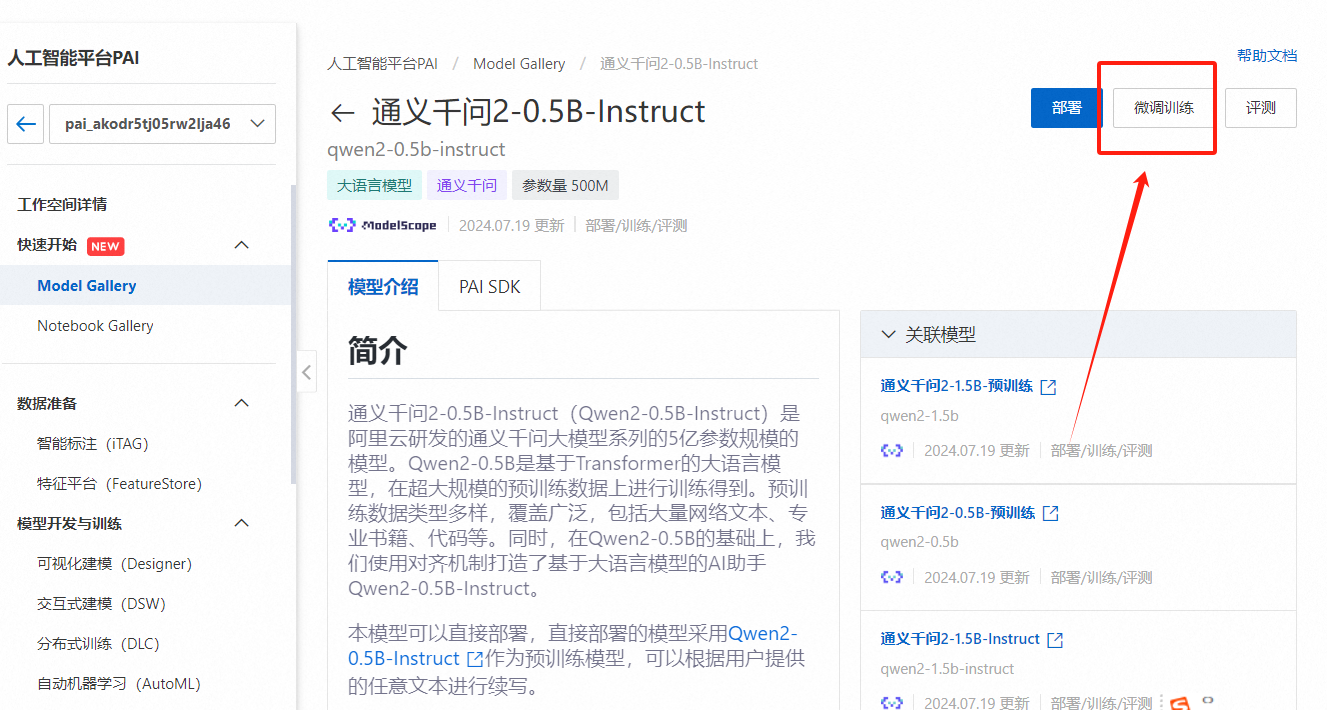
进入工作空间默认工作空间页面,选择【Model Gallery】,点击【任务管理】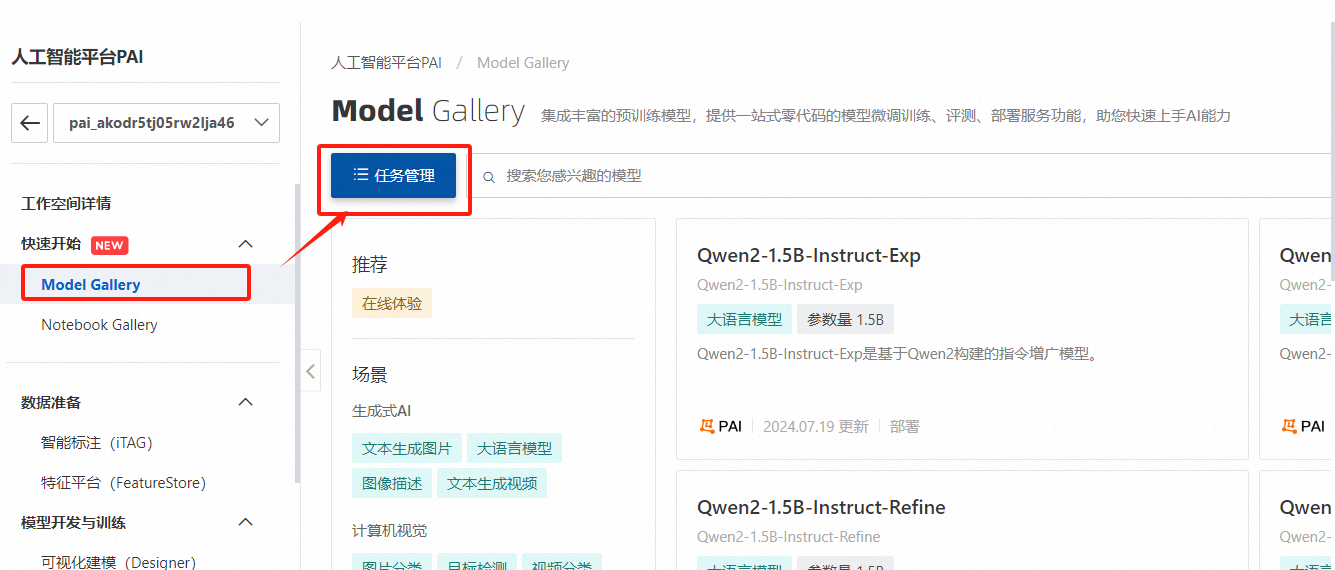
在任务管理页面选择【部署任务】,选择刚才部署的模型点击右侧【删除】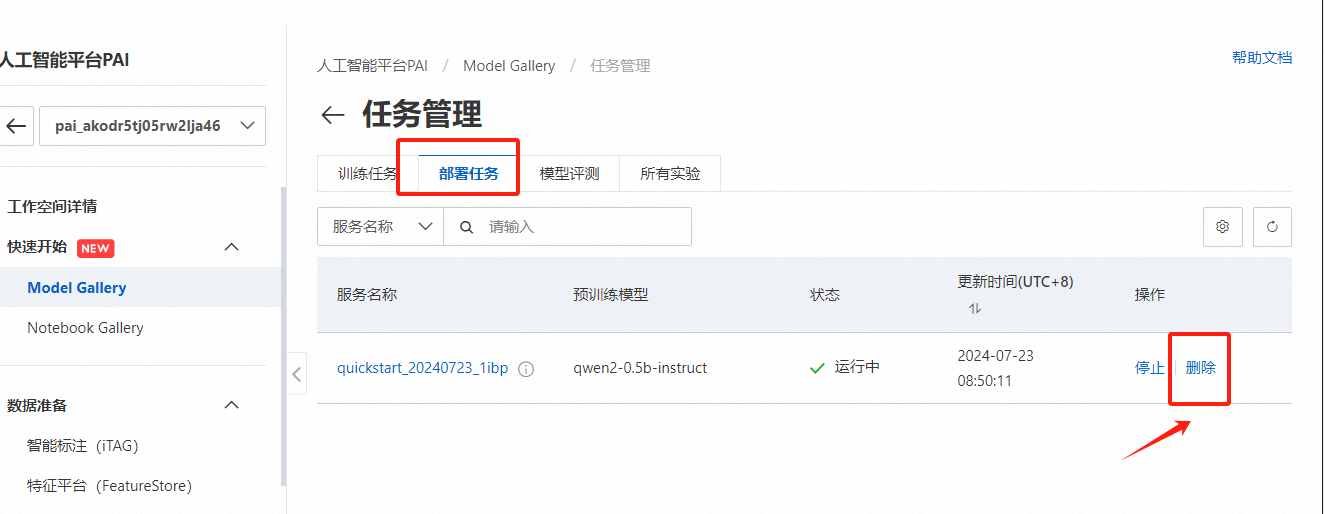
在弹出的提示页面点击【确定】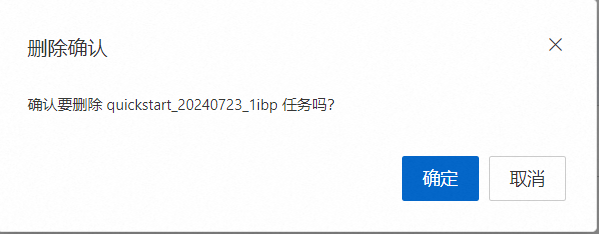
部署的模型任务进入【删除中】状态,整个删除过程大概耗时10分钟左右,耐心等待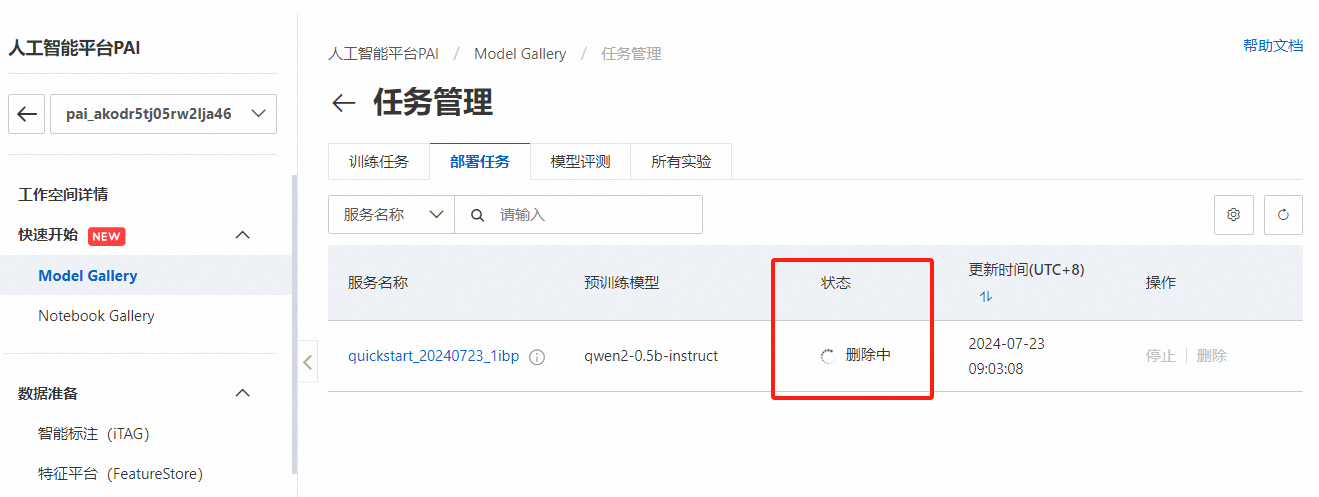
那么到这里整个基于PAI-快速开始,低代码实现大语言模型微调和部署的操作就完成了。这里如果你部署完成之后不使用的话建议释放资源,资源占用是比较费钱且浪费服务资源的。
对于机器学习平台PAI,本次基于PAI 低代码实现大语言模型微调和部署的操作整体上需要个人开发者操作的很少,创建默认工作空间之后找到对应的模型点击【部署】后续就可以等待部署成功在线测试了,整个操作过程没有什么难度,操作流程也是一如既往的顺畅,没有什么学习的成本,对于小白新手也比较友好,有专业的小白部署文档指导。唯一的一点就是对于个人开发者来说,个人体验部署的资费比较贵点,一小时14元左右,后期如果有免费体验资源就更完美了。
要使用阿里云PAI-QuickStart进行大语言模型(LLM)的微调和部署,我们可以遵循以下步骤进行配置、训练和部署,并分享整个过程中的体验。请注意,由于直接访问和操作链接可能因时间或权限问题而有所变化,以下步骤基于一般流程和阿里云PAI服务的常见特性。
1.访问链接:首先,访问提供的链接 https://developer.aliyun.com/adc/scenario/f2f81c8f883543528140e80f1ced3069?,这应该会引导你进入阿里云PAI-QuickStart的页面。如下图所示:
2.登录与创建项目:使用你的阿里云账号登录,并在PAI-QuickStart中创建一个新项目。在创建时,你可能需要选择或搜索大语言模型(LLM)相关的预训练模型。
数据准备:根据你的业务场景准备数据集。大语言模型通常需要大量的文本数据进行微调。数据可以是任何形式的文本,如对话、文章、书籍等。
数据上传:将准备好的数据上传到阿里云的对象存储服务(OSS)中,PAI-QuickStart将支持从OSS读取数据。
选择预训练模型:在PAI-QuickStart中选择一个适合你的业务场景的大语言模型预训练模型。
配置训练参数:设置训练参数,如学习率、批大小、训练轮次等。这些参数将影响模型训练的效果和速度。
启动训练:使用你的数据集启动模型微调过程。PAI-QuickStart将自动处理训练过程中的大部分细节,包括数据预处理、模型加载、训练执行等。
评估指标选择:根据你的需求选择合适的评估指标,如准确率、F1分数、困惑度等。
评估结果查看:训练完成后,PAI-QuickStart将提供模型的评估结果。你可以查看这些结果来评估模型性能。
模型部署:将微调后的模型部署到阿里云的机器学习平台或PAI服务中。
创建API:在部署后,创建一个API接口,以便通过HTTP请求调用模型进行预测。
测试与集成:测试API接口以确保它按预期工作,并将其集成到你的应用程序或业务流程中。
易用性:PAI-QuickStart提供了非常直观和易用的界面,使开发者能够轻松进行模型的选择、配置、训练和部署。低代码特性极大地降低了AI应用的门槛。
灵活性:尽管是低代码平台,但PAI-QuickStart仍提供了足够的灵活性来支持自定义的数据处理、模型配置和评估指标选择。
性能:阿里云强大的计算资源和优化的机器学习算法确保了模型的快速训练和高效部署。
文档与支持:阿里云提供了详尽的文档和强大的技术支持,帮助开发者在使用过程中遇到的问题得到及时解决。
总的来说,使用阿里云PAI-QuickStart进行大语言模型的微调和部署是一种高效、便捷且可靠的方式,对于希望快速将AI能力应用于业务场景的开发者来说是一个不错的选择。
import requests
response = requests.post('http://your-deployed-model-endpoint', json={'input': '你好,世界!'})
print(response.json())
配置过程:
根据流程文档很顺利就完成了: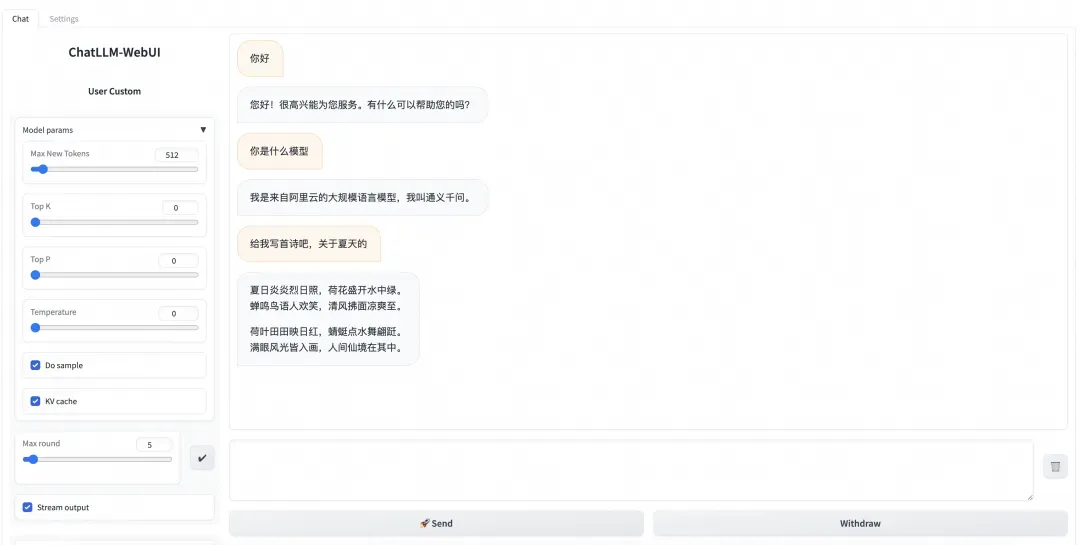
使用体验:
配置过程:
oss://bucketname.oss-cn-beijing-internal.aliyuncs.com。经过几次尝试和调整,最终微调训练成功完成。
使用体验:
使用阿里云的人工智能平台PAI-快速开始(PAI-QuickStart),可以低代码地实现大语言模型的微调和部署。以下是一个基于通义千问2(Qwen2)模型的具体流程,包括配置过程、输出结果及使用体验。
配置过程
访问PAI-QuickStart:
首先,登录阿里云控制台,找到PAI-QuickStart的入口。PAI-QuickStart集成了多种预训练模型,包括大语言模型、文本生成图片、语音识别等。
选择模型:
在PAI-QuickStart的“快速开始”入口,找到Qwen2系列模型。以Qwen2-7B-Instruct为例,点击该模型卡片进行配置。
配置部署信息:
PAI为Qwen2-7B-Instruct预置了模型的部署配置信息。用户需要提供推理服务的名称以及部署配置使用的资源信息(如GPU型号、显存大小等)。选择好资源组后,点击“部署”按钮将模型部署到PAI-EAS推理服务平台。
微调模型(可选):
如果需要微调模型以适应特定业务场景,PAI为Qwen2-7B-Instruct配置了微调算法。用户可以通过上传自定义数据集(Json格式),每条数据包含问题和答案,分别用“instruction”和“output”字段表示。点击“训练”按钮开始微调过程,用户可以查看训练任务状态和训练日志。
输出结果
部署结果:
模型部署完成后,用户可以通过PAI-EAS推理服务平台访问部署的推理服务。推理服务支持使用ChatLLM WebUI进行实时交互,也可以通过OpenAI API兼容的方式调用。
微调结果:
微调训练完成后,用户可以通过评测功能评估微调后模型的性能。PAI提供了自定义数据集评测和公开数据集评测两种方式,用户可以根据需要选择适合的评测方式。评测结果包括模型在各个数据集的得分情况,帮助用户了解模型的性能表现。
使用体验
低代码实现:
PAI-QuickStart提供了零代码和SDK的方式,让用户可以轻松实现从模型训练到部署再到推理的全过程。用户无需深入了解复杂的机器学习算法和深度学习框架,即可快速上手使用AI能力。
一站式服务:
PAI-QuickStart集成了业界流行的预训练模型,并提供了模型微调、服务部署、模型评测等一站式服务。用户可以在同一个平台上完成所有操作,大大提高了开发效率。
丰富的模型选择:
PAI-QuickStart支持多种大语言模型,包括Qwen2系列模型的不同尺寸版本。用户可以根据自身需求选择合适的模型进行部署和微调。
高性能支持:
阿里云提供了强大的计算资源支持,确保模型训练和推理的高性能。用户可以根据模型大小和计算需求选择合适的GPU型号和显存大小。
便捷的交互体验:
推理服务支持实时交互和API调用,用户可以通过多种方式与模型进行交互,获取所需的输出结果。同时,PAI还提供了丰富的文档和教程,帮助用户快速上手使用平台功能。
综上所述,使用PAI-QuickStart低代码实现大语言模型的微调和部署具有操作简便、功能丰富、性能高效等优点。用户可以通过该平台快速构建和部署自己的AI应用,享受AI技术带来的便利和效益。
使用阿里云PAI(Platform of Artificial Intelligence)的“快速开始”功能,可以简化大语言模型的微调和部署过程,尤其对于那些希望利用AI能力但缺乏深入编程知识的用户来说非常友好。下面我将概述如何通过PAI实现这一过程的使用流程:
登录阿里云控制台:首先,访问阿里云官网并使用您的账号登录。
进入PAI平台:在控制台中找到PAI服务,点击进入。
选择快速开始:在PAI页面中寻找“快速开始”或类似的入口,这通常会带你到一个包含预训练模型的列表。
选择模型:从列表中选择你想要微调的大语言模型,比如基于Transformer架构的模型。
准备数据集:上传或链接到你的微调数据集。这应该是一些特定于你业务场景的数据,用于让模型更好地理解你的特定领域。
配置微调参数:设置微调过程中的超参数,如学习率、批次大小、迭代次数等。
启动微调任务:确认配置无误后,提交任务开始微调过程。这可能需要一定的时间,具体取决于数据量和计算资源。
部署模型:微调完成后,你可以选择将模型部署为在线服务,这样就可以通过API调用来使用模型的能力了。
测试服务:在部署完成后,通过API调用测试模型的服务,确保它按预期工作。
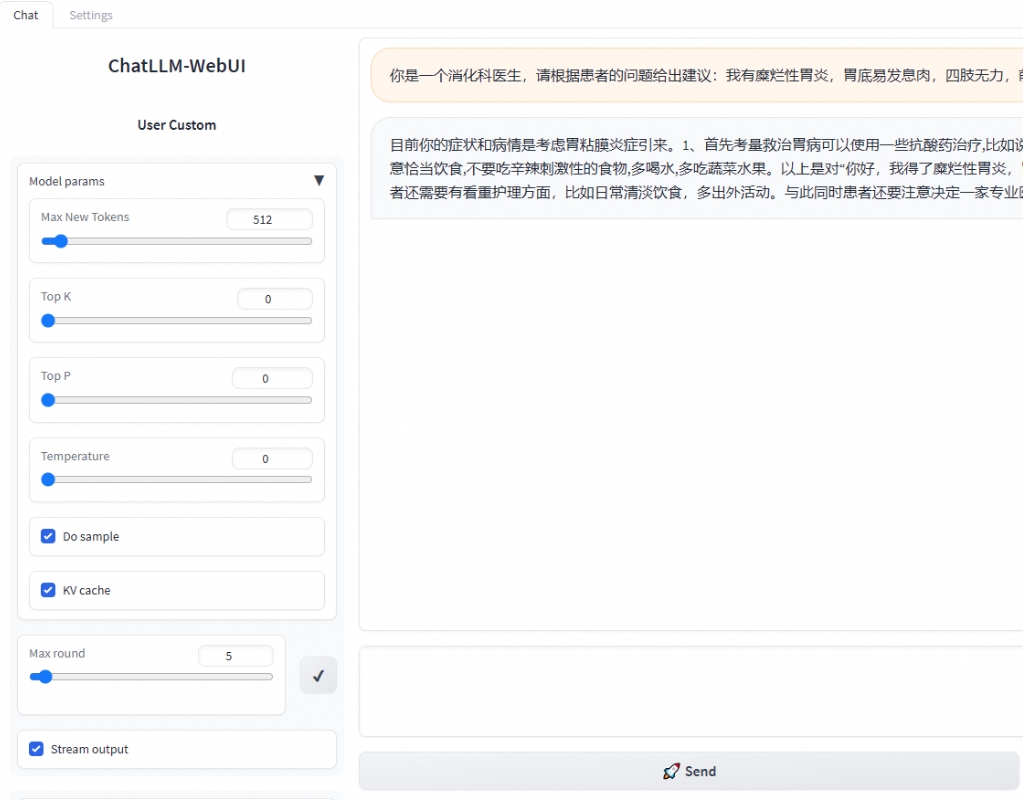
使用PAI的“快速开始”功能进行大语言模型的微调和部署,体验通常是非常直观和用户友好的。平台提供了详细的指引和模板,减少了手动编码的需求。此外,集成的模型评估和部署工具使得整个过程更加流畅,用户可以专注于数据准备和结果分析,而不需要深入了解底层的技术细节。
然而,用户可能需要具备一定的数据处理能力和对模型基本原理的理解,以便更有效地选择数据和配置参数。此外,对于复杂的业务场景,可能需要进一步的定制化开发才能达到最佳效果。
进入PAI产品控制台,开通
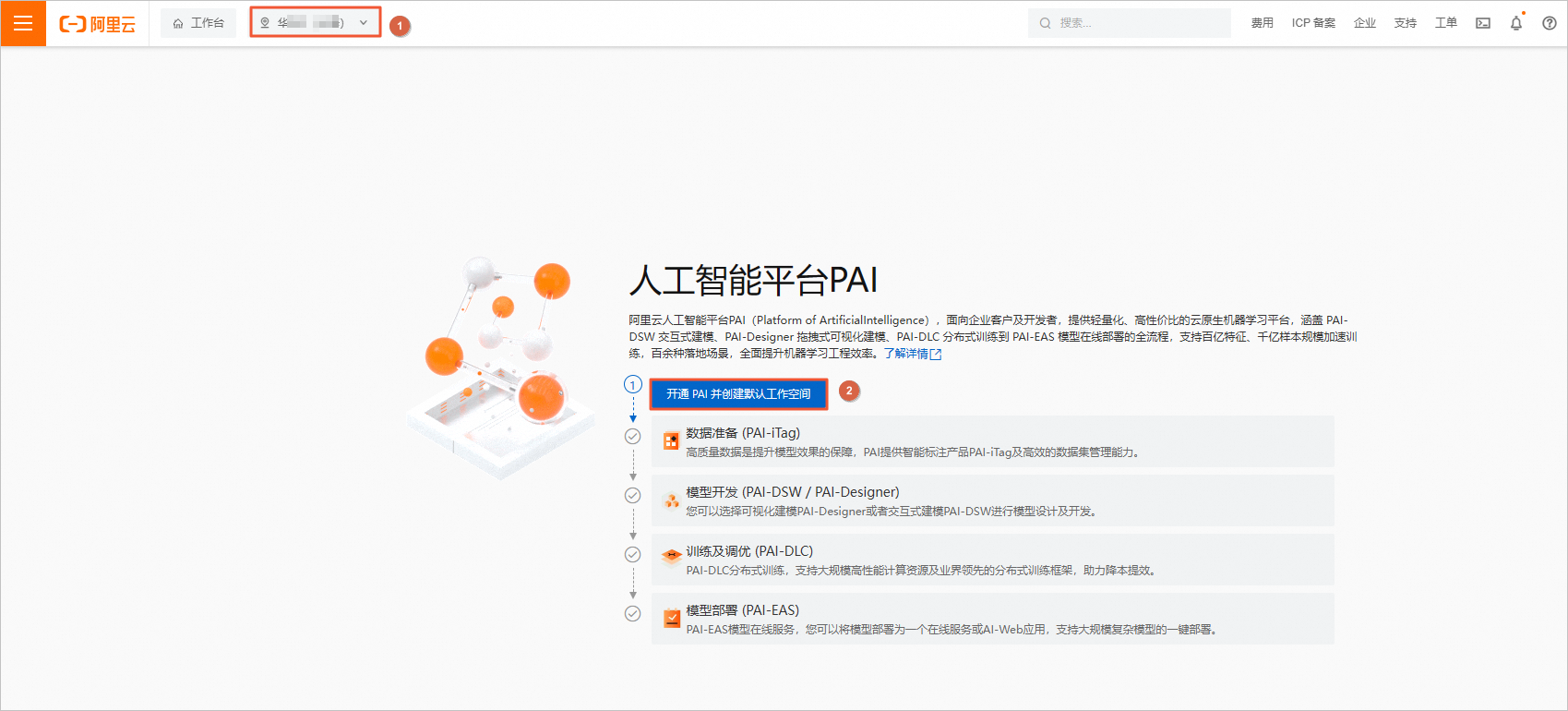
开通之后,默认空间如图所示: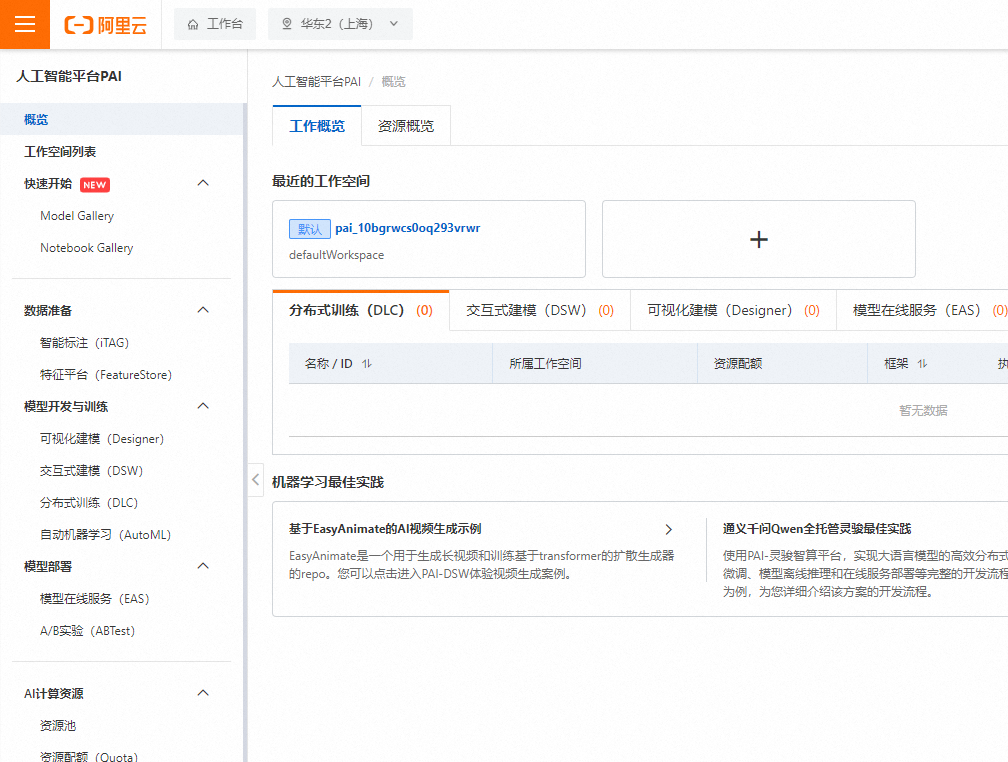
注意:此时不需要担心费用问题
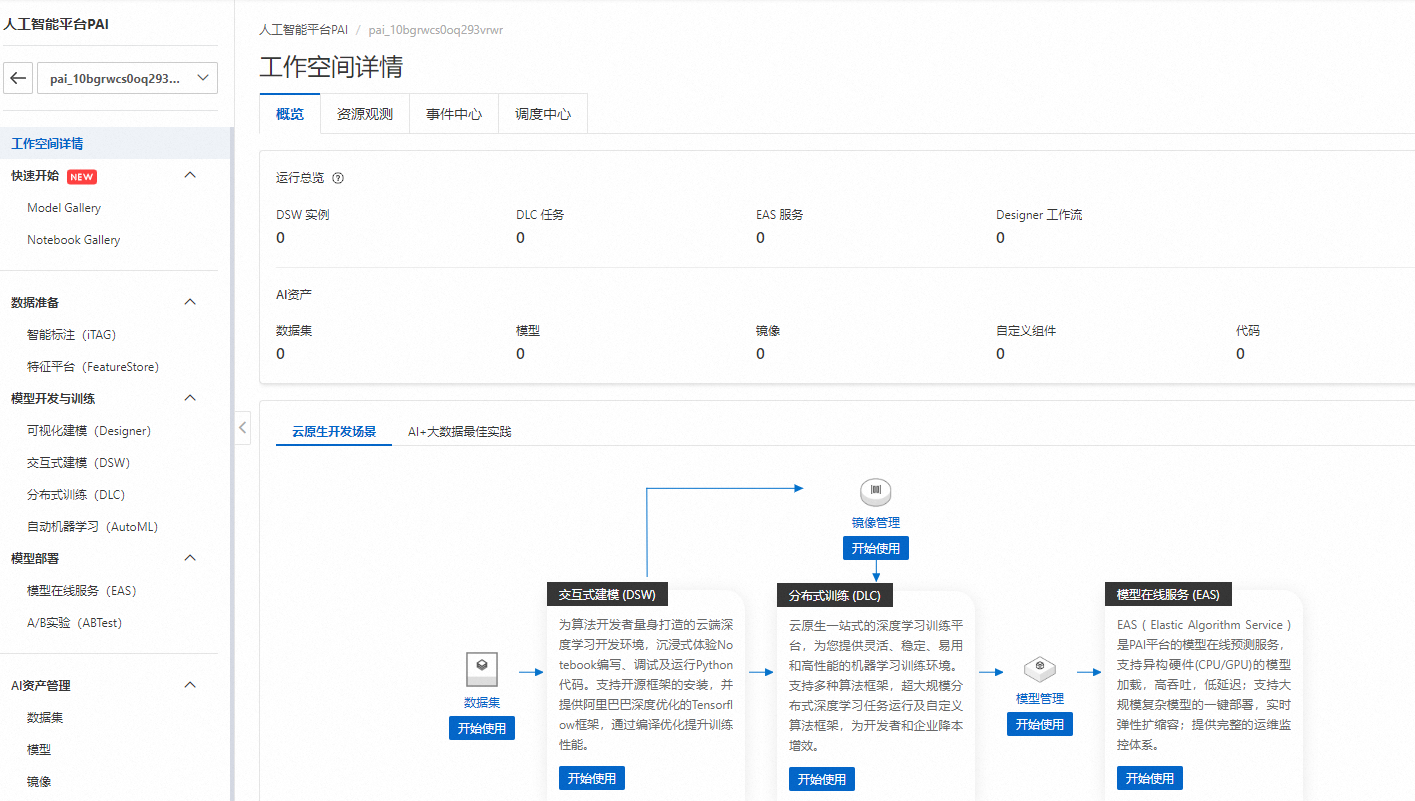
在快速开始页面,勾选同意并了解《PAI服务专用条款协议》后,单击进入,即可使用快速开始相关功能。
说明:如果您是第一次使用快速开始功能,会弹出该页面,请您确认部署服务(EAS)和训练服务(DLC)是否授权,未授权的请在页面中单击授权。
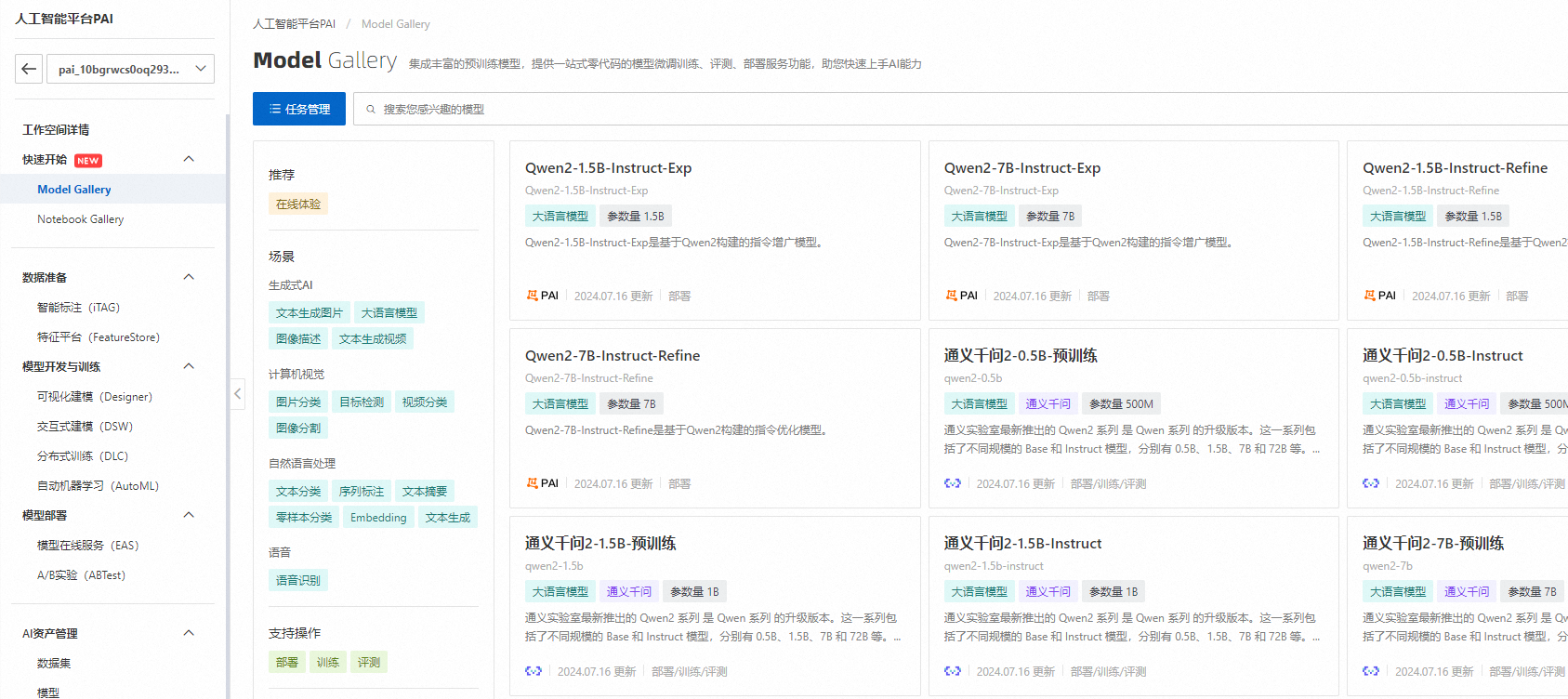
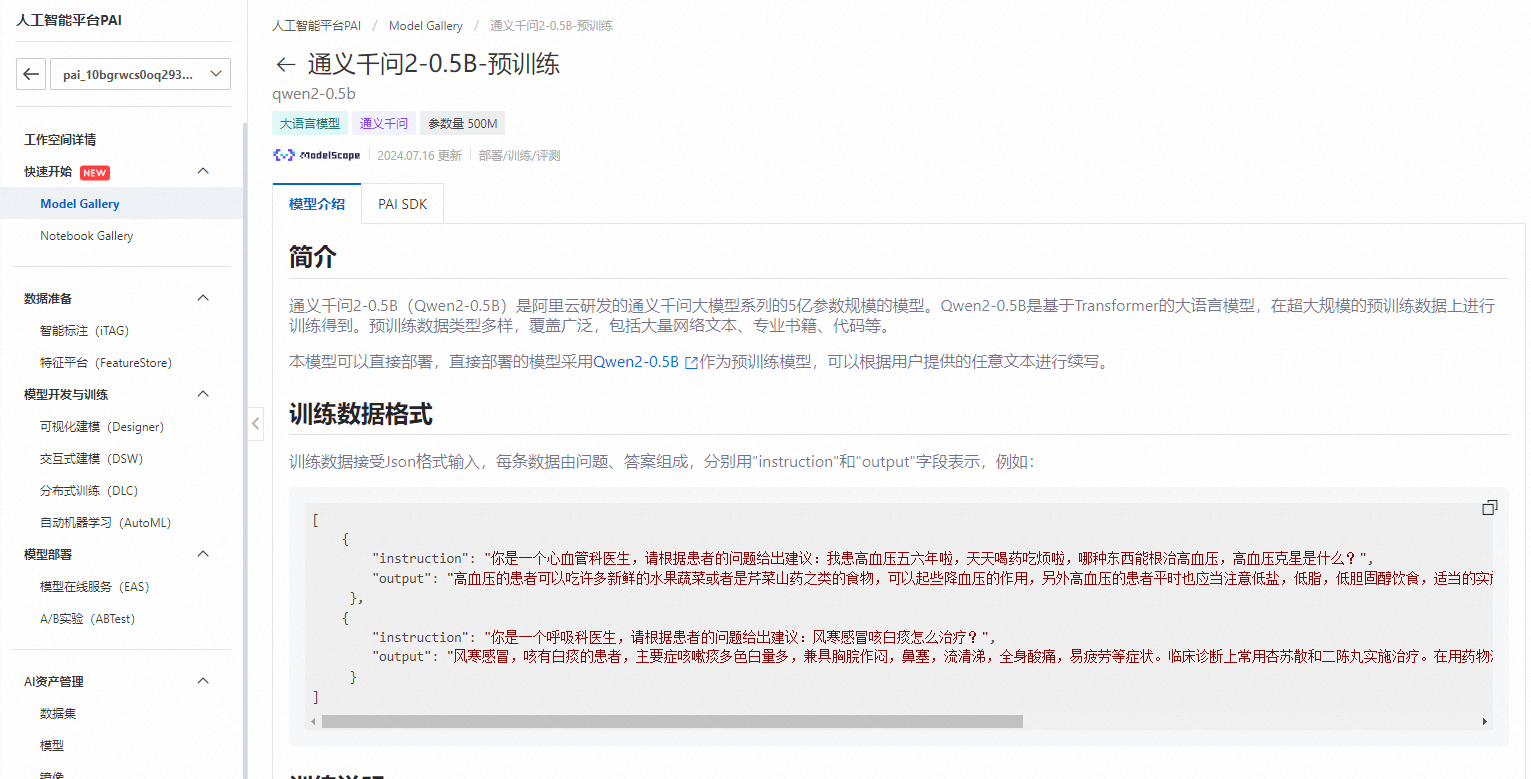
我们选择通义大模型,可以看详情展示
在模型列表看板,可以点击部署按钮,进行模型部署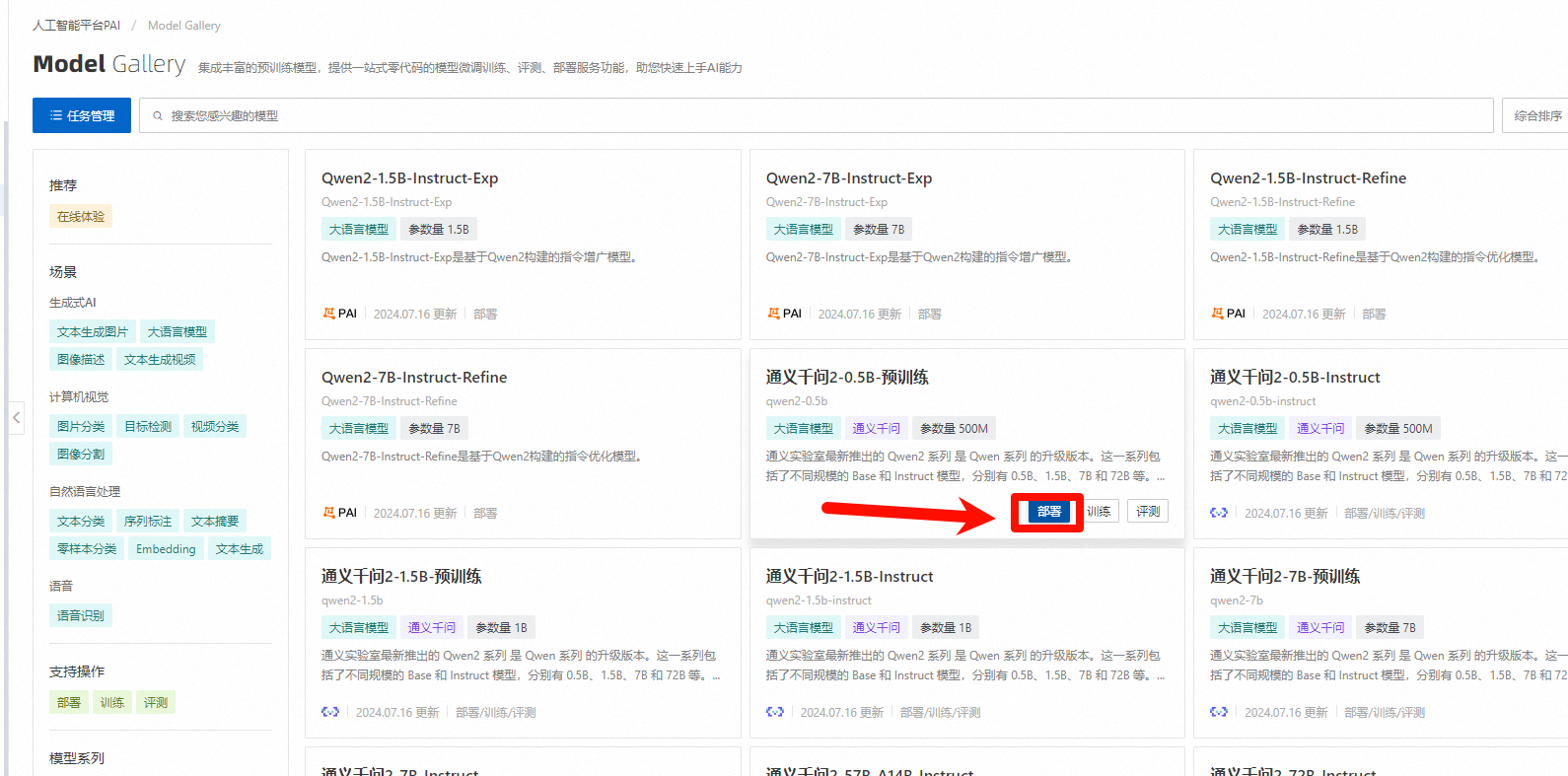
等待几分钟,就部署成功了
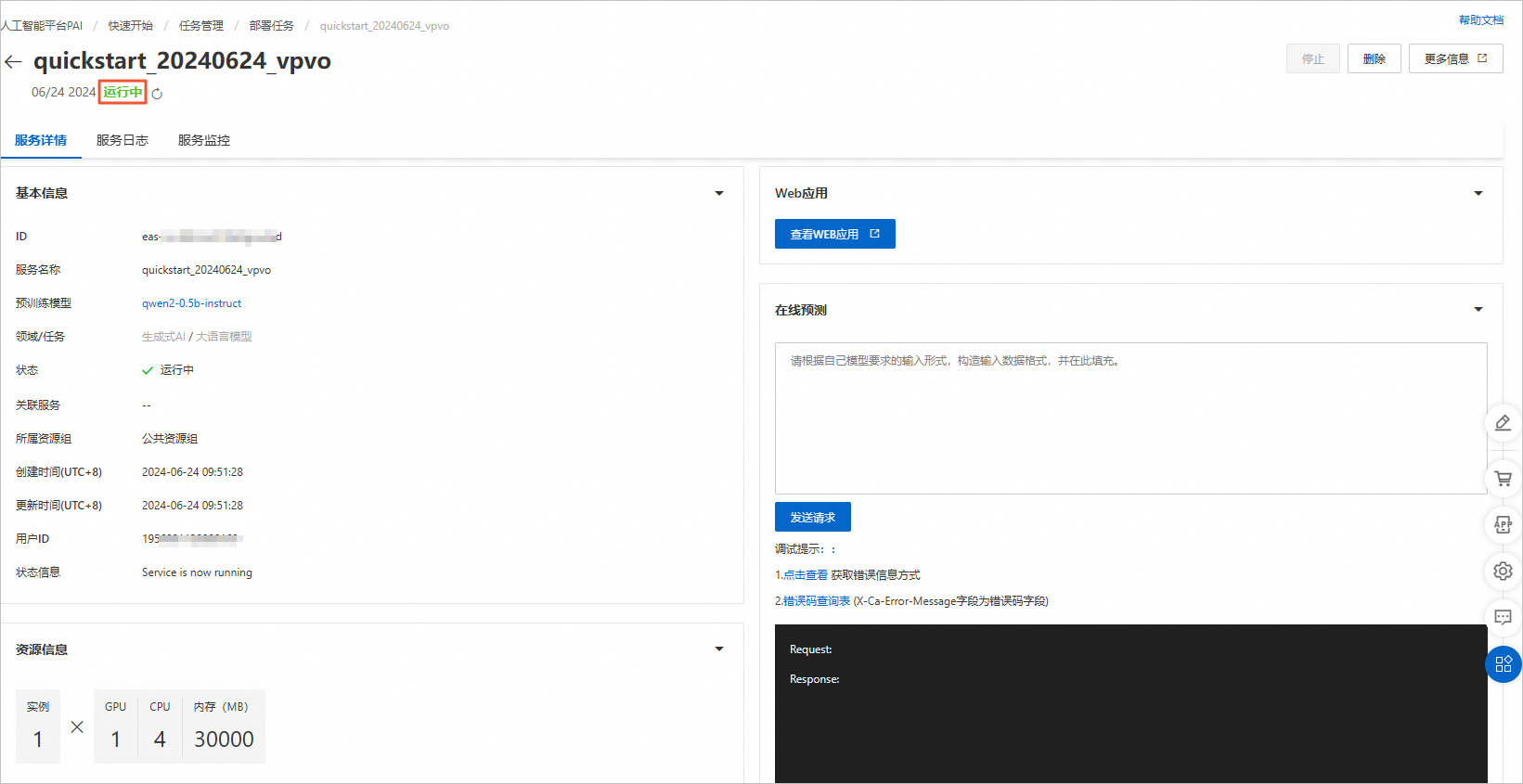
我们可以查看web应用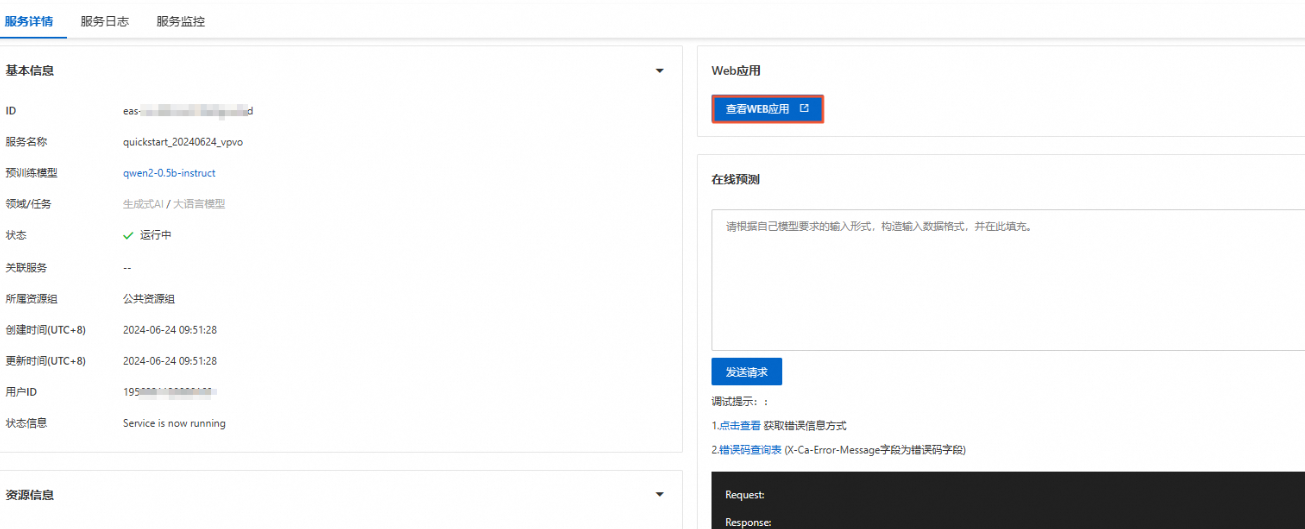
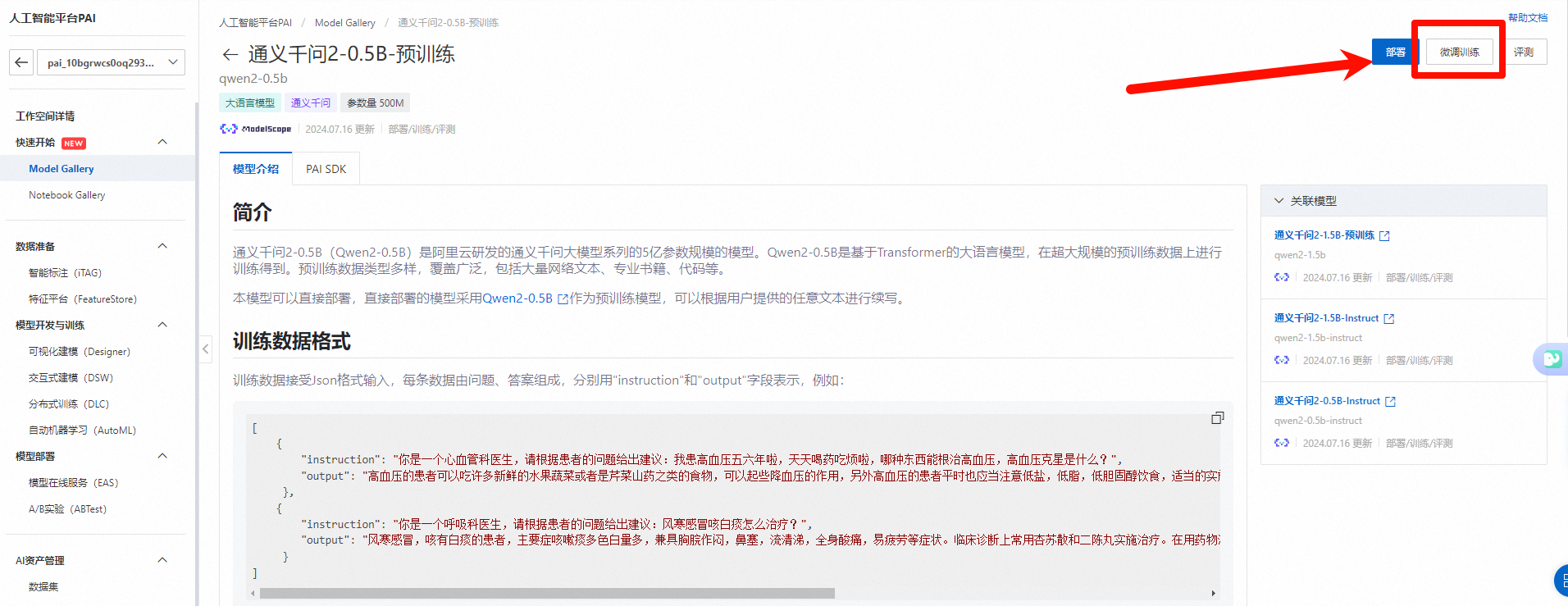
模型详情页,点击微调
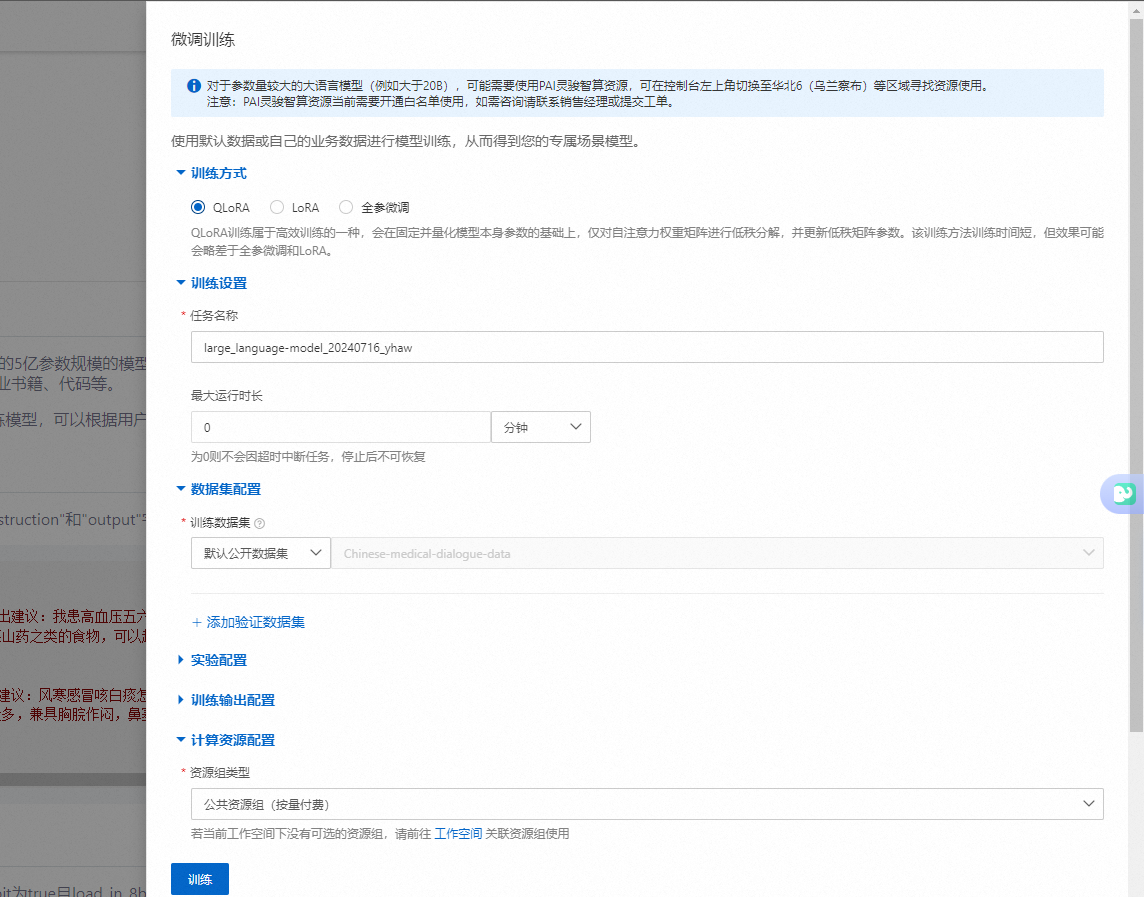
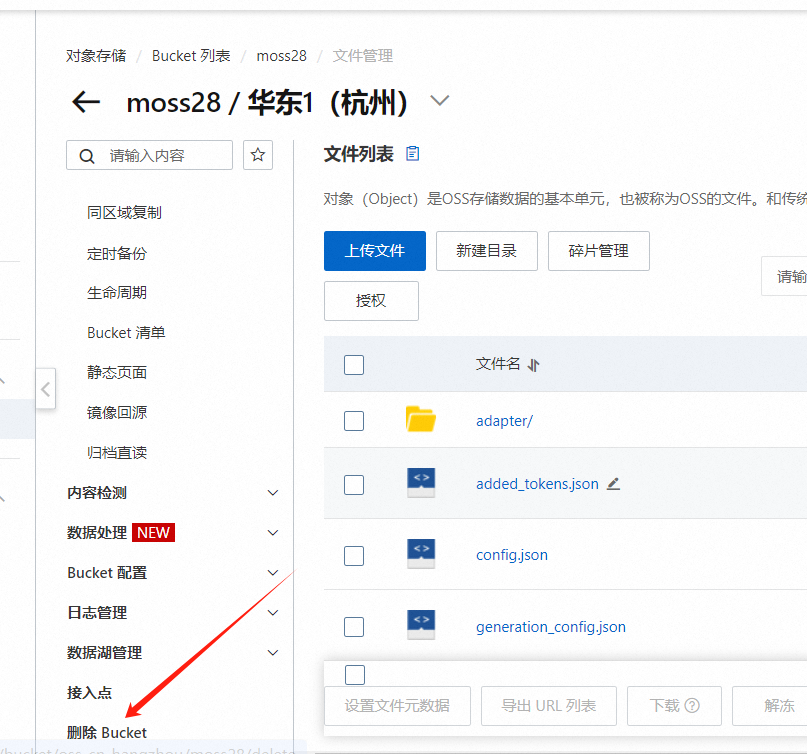
训练输出配置需要使用到OSS
可以提前配置好。使用OSS,进行微调训练。
微调结束后,我们可以再回到部署按钮
,进行再次部署。
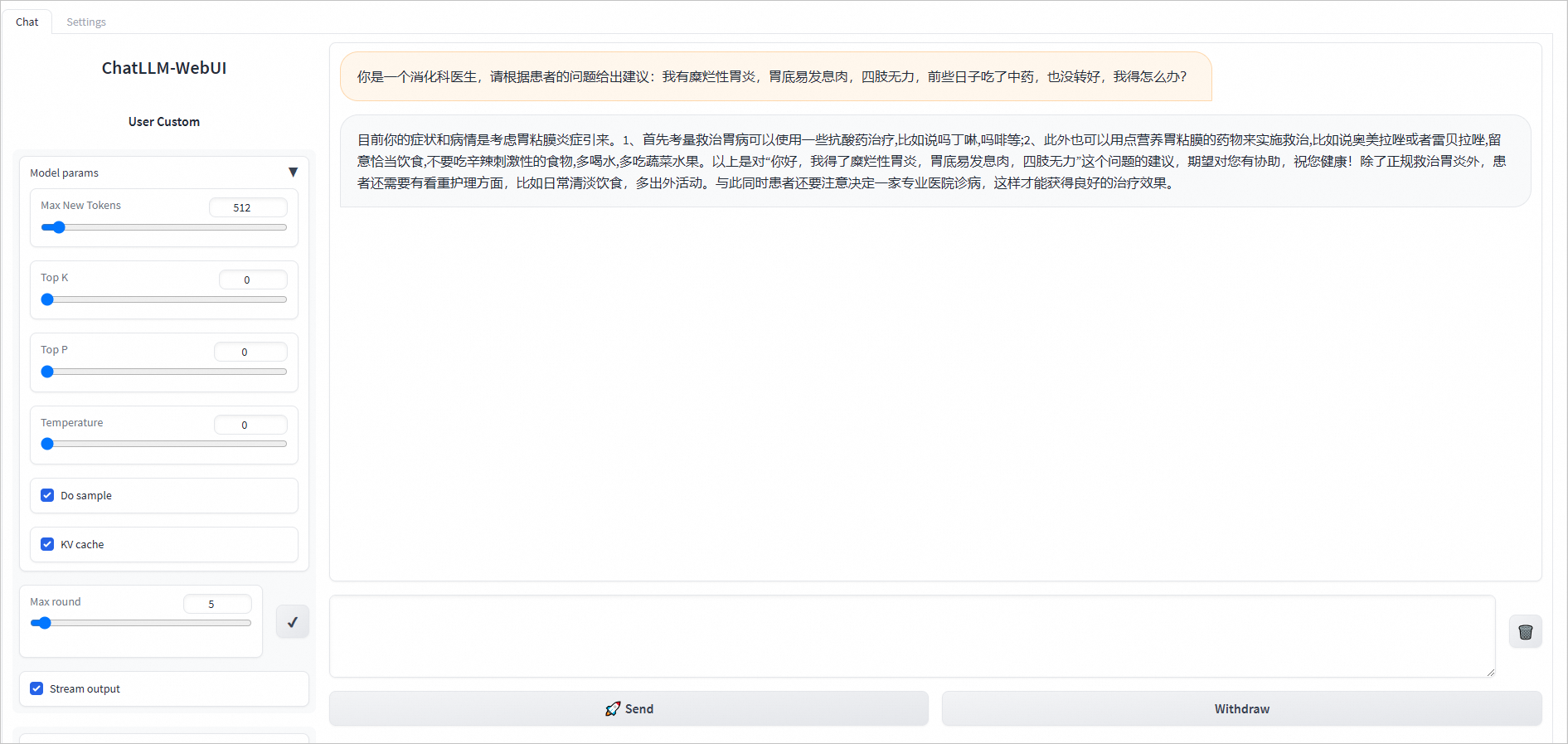
首先,登录阿里云控制台,找到PAI-QuickStart的入口。界面简洁友好,各项功能一目了然。我选择了通义千问2模型作为我的实验对象。
在模型微调环节,我上传了自己准备的数据集。这些数据集涵盖了我希望模型能够更好理解的特定领域知识,比如科技新闻、专业术语等。通过PAI-QuickStart提供的图形化界面,我轻松地完成了数据集的导入和标注工作。整个过程几乎无需编写任何代码,大大节省了我的时间和精力。
接下来,是模型微调的关键步骤。我根据业务需求,设置了合适的微调参数,如学习率、迭代次数等。 然后,点击“开始训练”按钮,PAI-QuickStart便自动开始了模型的微调过程。在这个过程中,我可以实时查看训练进度和各项性能指标,确保模型按照预期进行优化。
经过一段时间的等待,微调终于完成。接下来,是时候将微调后的模型部署到实际应用中了。PAI-QuickStart提供了一键部署功能,只需简单几步操作,我的模型就被成功部署到了阿里云提供的服务器上。
部署完成后,我迫不及待地开始了模型的测试。我通过API接口向模型发送了一系列查询请求,包括简单的问答、复杂的推理等。模型的响应速度非常快,且回答内容准确、全面,完全超出了我的预期。 更令我惊喜的是,由于经过了我的数据微调,模型在特定领域的知识表现尤为出色,这无疑为我后续的业务发展提供了强有力的支持。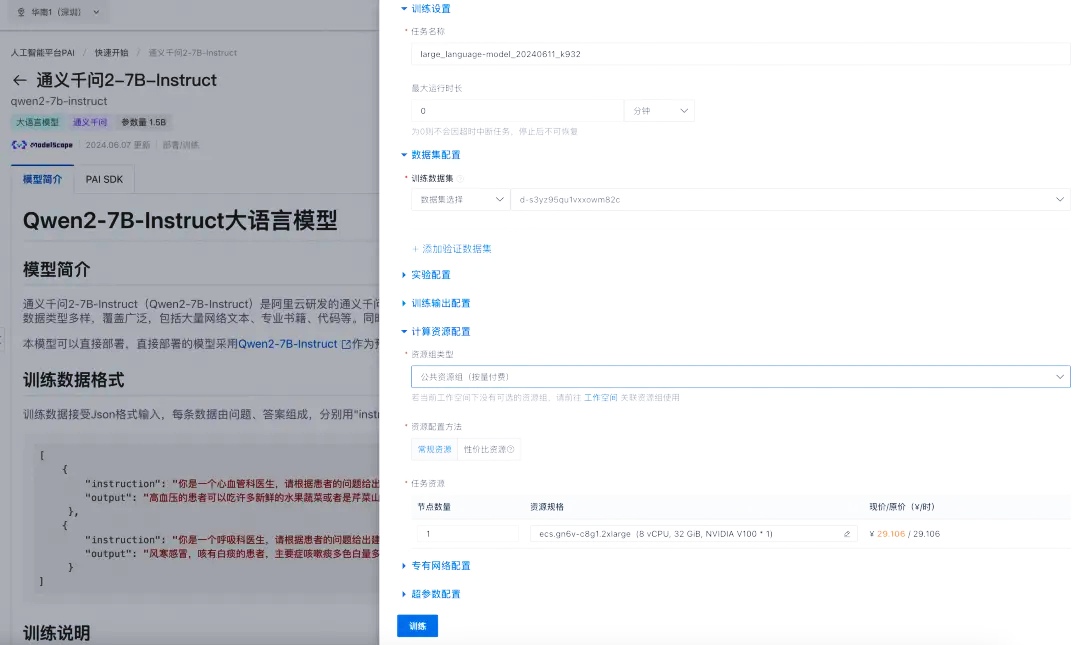
没问题,以下是关于使用PAI-快速开始,低代码实现大语言模型微调和部署,并分享配置过程、输出结果及使用体验的回答:
标题:简化AI实施之旅
在当前的人工智能浪潮中,大语言模型已成为推动多个行业革新的关键力量。然而,对于非专业人士来说,训练和部署这类复杂模型往往显得遥不可及。阿里云的PAI-QuickStart平台为这一难题提供了解决方案,它通过集成业界领先的预训练模型和提供一站式的服务平台,极大地简化了AI的实施过程。
使用PAI-QuickStart配置大语言模型的微调和部署主要包括以下步骤:
选择模型:用户首先需要从提供的模型库中选择一个适合自己业务需求的大语言模型。这些模型覆盖了从自然语言处理到计算机视觉等多个领域。
数据上传与处理:用户可以上传自己的数据集,或利用平台提供的数据预处理工具来准备训练数据。这一步骤是模型微调的基础,确保数据的质量和适用性。
模型微调:通过简单的界面设置,如调整学习率、微调层数等参数,用户可以轻松启动模型的微调训练。PAI-QuickStart会自动进行模型的训练和优化。
模型部署:训练完成后,用户可以一键部署模型为在线服务接口,无需关心底层的服务器和网络配置,即可获取API端点进行模型调用。
评估与优化:平台提供模型评估工具,可以对模型性能进行实时监控和评估,根据反馈继续优化模型配置。
利用PAI-QuickStart,我成功实现了一个基于自己业务数据的大语言模型的微调训练,并将其部署为在线服务。输出的模型显著提升了文本处理的准确性和效率,特别是在文本分类和命名实体识别任务上表现优异。
PAI-QuickStart的体验超出预期,其最大的优点是用户友好和高度自动化。即使对于没有深厚机器学习背景的用户,也能轻松上手,并在短时间内完成模型的训练和部署。平台的文档详尽,社区活跃,使得问题解决更为便捷。
最让人印象深刻的是模型微调后的性能表现以及部署过程的简便性。你不需要管理任何服务器或配置复杂的网络,只需几步点击,就可以将模型部署到云端,并立即投入使用。
总的来说,PAI-QuickStart是一个强大的工具,它通过简化AI模型的训练和部署过程,使AI技术的应用变得更加普及。无论是企业还是个人开发者,都可以通过这个平台快速实现AI项目,从而推动业务的发展和创新。
登录与选择场景
首先,我登录了阿里云开发者平台,并找到了PAI-QuickStart的入口。在场景选择中,我选择了大语言模型微调与部署的场景。
数据准备
接下来,我上传了自己的数据集。PAI-QuickStart支持多种数据格式,我只需要简单地将数据整理成指定的格式并上传即可。
模型选择与微调
在模型选择环节,我浏览了PAI-QuickStart提供的多种预训练模型,并选择了一个适合我业务需求的大语言模型。随后,我使用了平台提供的微调功能,通过调整一些关键参数,使模型更加匹配我的业务场景。
服务部署
微调完成后,我点击了一键部署按钮,将模型部署为在线服务。PAI-QuickStart提供了详细的部署日志和监控信息,让我能够实时了解部署进度和服务状态。
三、输出结果
部署完成后,我通过PAI-QuickStart提供的API接口调用了在线服务,并输入了一些测试数据。模型返回了准确且符合预期的输出结果,证明微调后的模型在我的业务场景中表现良好。
四、使用体验
简单易用
PAI-QuickStart平台提供了直观易用的界面和丰富的功能,让我能够轻松完成模型的微调、训练和部署过程。即使是非专业开发者,也能通过简单的操作实现复杂的AI功能。
功能强大
平台集成了多种业界流行的预训练模型,并提供了丰富的微调选项和部署配置。这使得我能够根据业务需求快速找到合适的模型,并进行个性化的调整和优化。
高效便捷
通过PAI-QuickStart平台,我能够一键部署模型并快速调用在线服务。这大大缩短了从模型开发到实际应用的时间周期,提高了工作效率。
良好的支持与服务
在使用过程中,我遇到了一些问题。但是,通过查阅PAI-QuickStart的官方文档和联系技术支持,我很快就得到了满意的解答和帮助。
现在大模型AI的痛点在于,部署困难、变量过于复杂以及需要GPU的硬件支持,因此推广起来有点难,用户体现效果不佳。PAI就可以很好的解决这种的现象,通过定制化的配置以及云服务器就可以快速的拉起对应的AI资源。整个过程操作简单,无脑根据部署资料就可以拉起想要的模型,使用部署的体验非常好。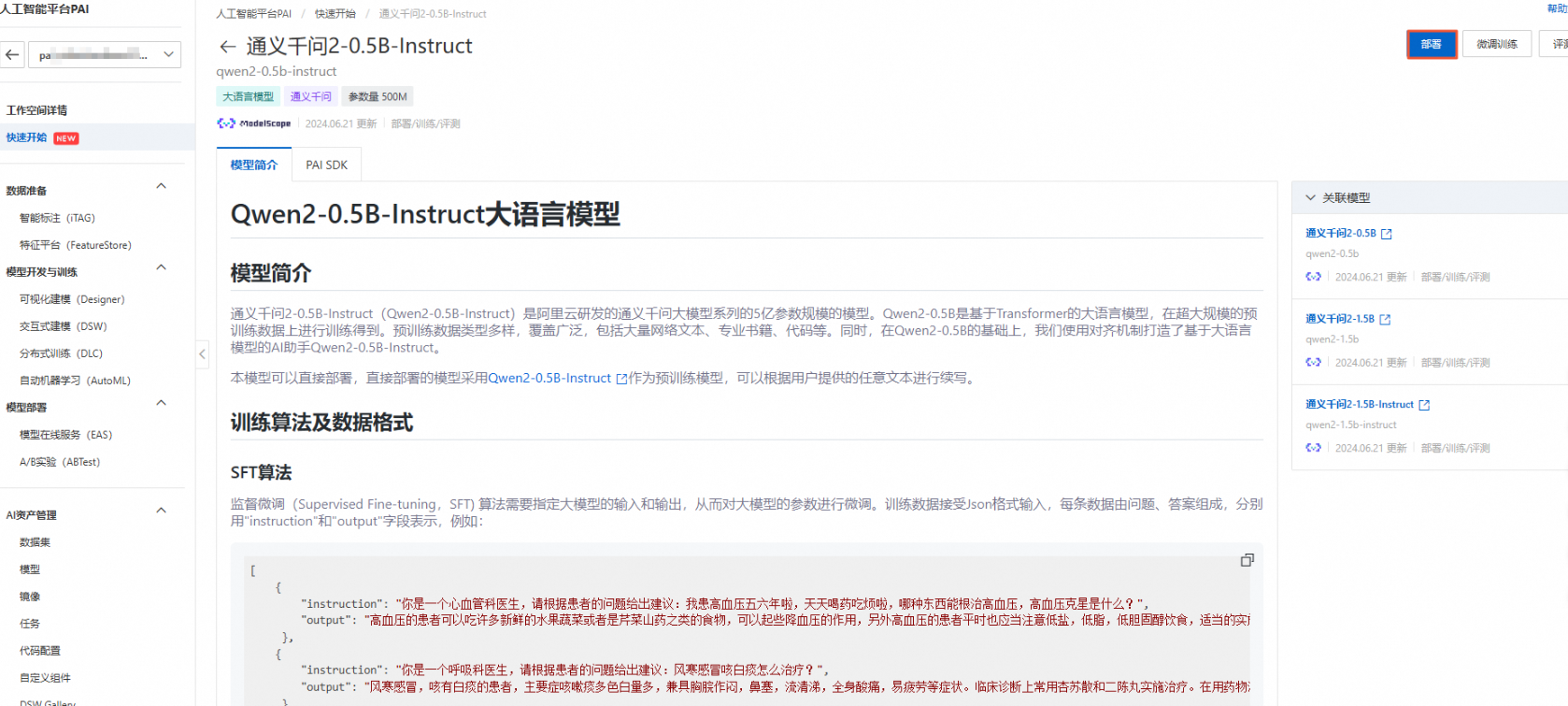
作为服务华为的运营工程师,使用 ODPS 两年,深刻体会其在通信设备运维场景的支撑力。华为基站设备日志日均增量超 TB 级,供应链数据跨 12 个区域节点,ODPS 的湖仓一体架构让分散数据实现统一调度,这是保障 5G 基站稳定运行的关键。 AI 爆发倒逼运维模式升级。过去设备故障分析依赖 T+1 报表,如今需实时预判潜在风险,这要求 ODPS 跳出传统计算框架。 ODPS 有引领数据革命的...
一、遇到的问题 创建应用需改参数并重启集群 修改 wal_level、polar_max_super_conns 会触发集群重启,高峰期操作有风险,新手容易踩坑。 网络配置略繁琐 应用默认不能访问外网,必须手动配 NAT 网关 + SNAT;应用白名单和集群白名单独立,要重复配置。 控制台入口较深 Dashboard 账号密码藏在配置页里,不好找;创建应用等待 3–5 分钟无进度提示。 Qo...
🎁嘿,大家好!👋 ,今天跟大家聊聊AI技术如何助力短剧领域的创新发展。随着AI技术的飞速发展,短剧创作迎来了前所未有的变革。这不仅仅是技术的进步,更是创意和效率的双重提升。🚀 AI助力短剧领域的创新 智能编剧辅助 创意生成:AI可以基于大数据分析,生成多种剧情梗概和创意点子。这对于编剧来说,就像是一个无穷无尽的创意宝库,可以激发更多的灵感。💡 剧本优化:AI还可以帮助编剧优化剧本,检...
P人出游,你是否需要一个懂你更懂规划的AI导游呢? LLaMA Factory是一款低代码大模型微调框架,集成了百余种开源大模型的高效微调能力,使您无需深入理解复杂算法即可轻松进行模型微调。阿里云的人工智能平台PAI提供一站式机器学习服务,覆盖从数据预处理到预测的全流程,并支持多种深度学习框架与自动化建模,大幅降低了使用难度。通过结合PAI与LLaMA Factory,用户能够充分发挥二者优...
建议:将通义灵码直接接入到阿里云函数计算,让更多的普罗大众可以使用自然语言实现自己的编程需求,例如自动获取招考公告等。 在当今数字化时代,编程不再是专业人士的专属技能。随着人工智能技术的发展,越来越多的普通人也开始尝试通过自然语言来实现自己的编程需求。通义灵码作为一种创新的自然语言处理工具,能够帮助用户更加便捷地完成各种编程任务,比如自动获取招考公告等。为了进一步推广这一技术,建议将通义灵码...

